Protocolo de Contexto de Modelo (MCP) no Databricks
MCP é um padrão de código aberto que conecta agentes a ferramentas, recursos, prompts e outras informações contextuais. No Databricks, o Unity AI Gateway, o plano de controle corporativo, governa o acesso e monitora a atividade em servidores MCP e Endpoint LLM.
- Controle de acesso: Servidores MCP gerenciados e externos usam permissões do Unity Catalog para gerenciar quais usuários e entidades de serviço podem acessar cada servidor e seus dados subjacentes.
- Gerenciamento de credenciais : Os servidores MCP externos usam conexões do Unity Catalog com OAuth gerenciado para gerenciar a autenticação com segurança sem expor credenciais aos usuários finais.
- Visibilidade centralizada : View e gerencie todos os servidores MCP em seu workspace pelo Unity AI Gateway.
MCP é uma forma de fornecer ferramentas a agentes. Para todas as abordagens — incluindo dados estruturados e não estruturados, execução de código e ferramentas de função do Unity Catalog — consulte Conectar agentes a ferramentas.
Configurar um servidor MCP
-
- Serviços MCP no Unity Catalog
- Conecte-se a servidores MCP hospedados fora do Databricks usando conexões gerenciadas e faça o registro deles como itens protegíveis do Unity Catalog para governar o acesso, filtrar ferramentas e aplicar políticas de serviço.
-
- Hospede seu próprio servidor MCP
- Hospede seu próprio servidor MCP como um aplicativo Databricks.
Usar servidores MCP
-
- Use servidores MCP em agentes
- Chame servidores MCP gerenciados, externos e personalizados a partir do código do agente usando a biblioteca
databricks-mcpe os frameworks de agente.
-
- Servidores MCP gerenciados da Databricks
- Servidores Databricks pré-configurados para AI Search, Genie Agents, Databricks SQL e funções do Unity Catalog. Nenhuma configuração necessária.
-
- Conecte MCPs a assistentes de AI e agentes de codificação
- Conecte o Claude, o Cursor, o MCP Inspector e outras ferramentas aos seus MCPs do Databricks.
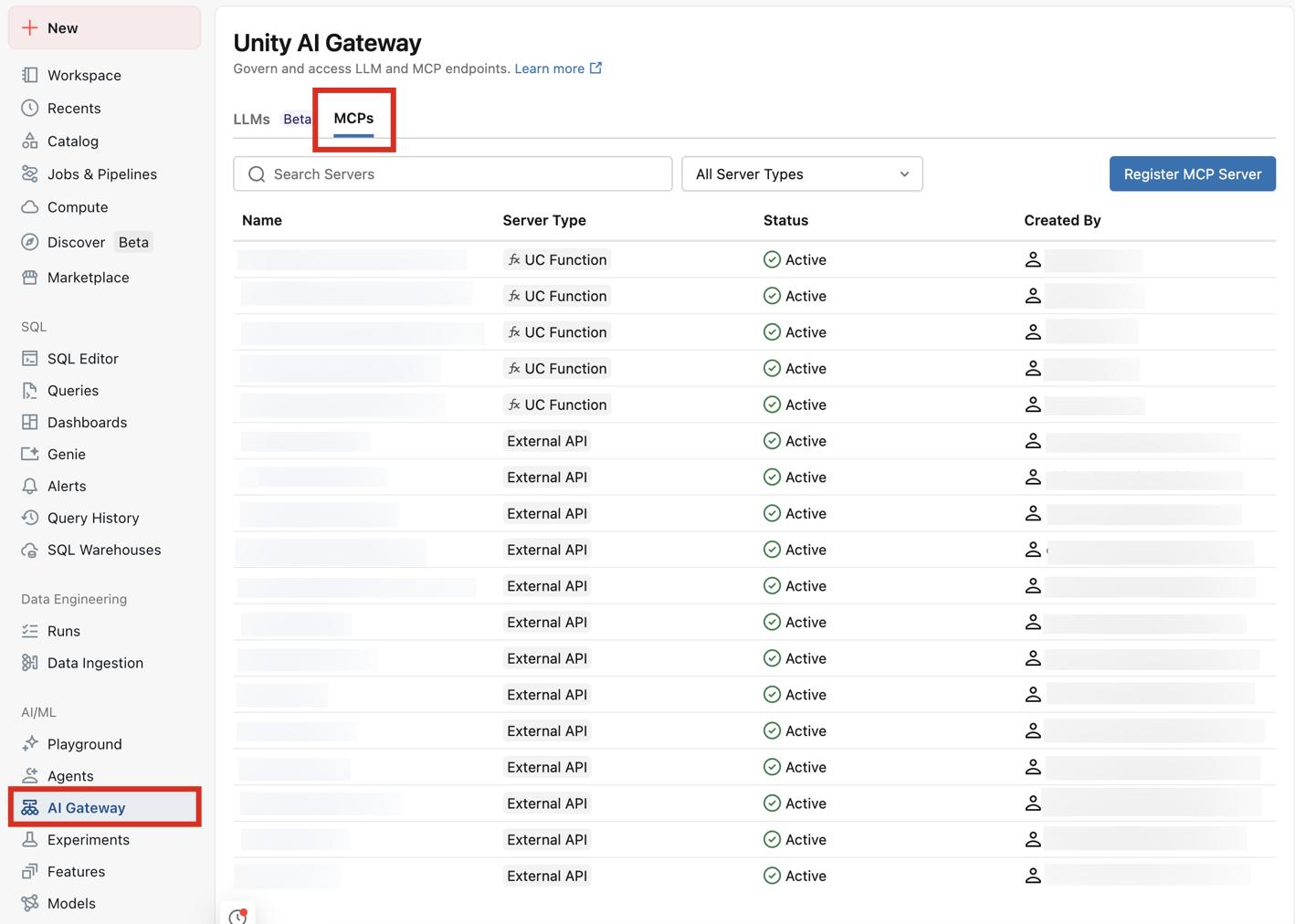
Para ver seus servidores MCP disponíveis, vá para seu workspace > AI Gateway > MCPs :
Preços de compute
Servidores MCP personalizados estão sujeitos aos preços do Databricks Apps.
O preço do servidor MCP gerenciado depende do tipo de recurso:
-
As funções do Unity Catalog usam preços de compute geral serverless.
-
Genie Agents usam preços de compute SQL serverless.
-
Os servidores Databricks SQL usam preços do Databricks SQL.
-
Os índices de Pesquisa AI usam preços de Pesquisa AI.