memória do agente deAI
A memória permite que agentes AI se lembrem de informações do início da conversa ou de conversas anteriores. Isso permite que os agentes forneçam respostas contextuais e criem experiências personalizadas ao longo do tempo. Use Databricks Lakebase, um banco de dados Postgres OLTP totalmente gerenciado, para gerenciar o estado e a história da conversa.
Requisitos
- Habilite Databricks Apps em seu workspace. Consulte Configurar seu workspace e ambiente de desenvolvimento Databricks Apps.
- Uma instância do Lakebase, consulte Obtenha um banco de dados Postgres.
Memória de curto prazo versus memória de longo prazo
A memória de curto prazo captura o contexto de uma única sessão de conversa, enquanto a memória de longo prazo extrai e armazena informações key ao longo de várias conversas. Você pode construir seu agente com um ou ambos os tipos de memória.
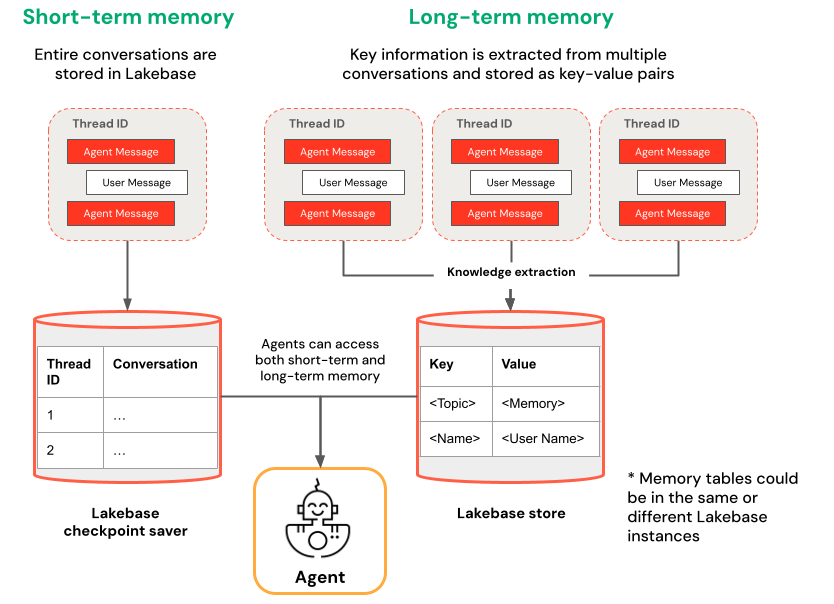
memória de curto prazo | memória de longo prazo |
|---|---|
Capture o contexto em uma única sessão de conversa usando IDs de tópicos e pontos de verificação. Mantenha o contexto para perguntas de acompanhamento durante a sessão. | Extrair e armazenar automaticamente key em várias sessões. Personalize as interações com base em preferências anteriores. Construa uma base de conhecimento sobre os usuários que melhore as respostas ao longo do tempo. |
Comece agora
Para criar um agente com memória no Databricks Apps, clone um aplicativo padrão pré-construído e siga o fluxo de trabalho de desenvolvimento descrito em Criar um agente AI e implantá-lo no Apps. O padrão a seguir demonstra como adicionar memória de curto e longo prazo a agentes usando frameworks populares.
LangGraph
Clone o padrão agent-langgraph-advanced para construir um agente LangGraph com memória de curto e longo prazo. O padrão utiliza o checkpointing integrado do LangGraph com Lakebase para gerenciamento de estado durável, incluindo contexto de conversa baseado em threads e visão persistente do usuário entre sessões.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
SDK de Agentes OpenAI
Clone o padrão agent-openai-advanced para criar um agente usando o SDK de Agentes OpenAI com memória de curto prazo. O padrão utiliza Lakebase para gerenciamento de estado durável, permitindo conversas com estado e múltiplas interações, com gerenciamento automático do histórico da conversa.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
Execução em segundo plano para agentes de longa duração
O Databricks Apps impõe um tempo limite de conexão HTTP de aproximadamente 300 segundos. A execução em segundo plano permite que as tarefas do agente que excedam esse limite continuem em execução após o fechamento da conexão; o cliente recupera os resultados de um endpoint separado ou se reconecta para retomar a transmissão.
O padrão avançado — agent-langgraph-advanced e agent-openai-advanced — estende o padrão base com memória de curto prazo e execução em segundo plano de longa duração via LongRunningAgentServer de databricks-ai-bridge, que fornece:
- Modo em segundo plano : Defina
background=trueno corpo da solicitação para retornar um ID de resposta imediatamente e executar o agente de forma assíncrona. - Recuperar endpoint : Envie
GET /responses/{id}para buscar o resultado final, ou para abrir uma conexão de transmissão para uma execução em andamento. - Transmissão retomável : Cada evento enviado pelo servidor inclui um
sequence_number. Se a conexão cair, reconecte comstarting_after=Npara continuar do próximo evento. - TASK_TIMEOUT_SECONDS variável de ambiente que limita a duração da tarefa de fundo. Isso é independente do tempo limite de conexão HTTP de 120 segundos do Databricks Apps, que se aplica apenas a uma única solicitação HTTP. (default: 1 hora)
O arquivo README avançado mostra exemplos de requisições para cinco modos de cliente:
- Invoke : Um POST padrão de não transmissão.
- transmissão : Uma transmissão padrão POST.
- Em segundo plano, depois faça uma pesquisa : POST com
background=true, depois faça uma pesquisaGET /responses/{id}até terminar. - Transmissão em segundo plano, retomar via transmissão : POST com
background=trueestream=true; se a conexão cair, reconectar aGET /responses/{id}comstream=true. - Transmissão em segundo plano, retomada via poll : mesmo kickoff; se a conexão cair, poll
GET /responses/{id}para o resultado final.
implantar e consultar seu agente
Após configurar seu agente com memória, siga os passos descritos em Criar um agente AI e implantá-lo no Databricks Apps para executar seu agente localmente, avaliá-lo e implantá-lo no Databricks Apps.