Ingerir dados do PostgreSQL
Visualização
O conector PostgreSQL para LakeFlow Connect está em versão prévia pública. Entre em contato com a equipe da sua account Databricks para se inscrever na Prévia Pública.
Esta página descreve como ingerir dados do PostgreSQL e carregá-los no Databricks usando LakeFlow Connect. O conector PostgreSQL oferece suporte AWS RDS PostgreSQL, Aurora PostgreSQL, Amazon EC2, Banco de Dados Azure para PostgreSQL, máquinas virtuais Azure , Cloud SQL para PostgreSQL GCP e bancos de dados PostgreSQL on-premises usando Azure ExpressRoute, AWS Direct Connect ou redes VPN.
Antes de começar
-
Para criar um gateway de ingestão e um pipeline de ingestão, você deve atender aos seguintes requisitos:
-
Seu workspace está habilitado para Unity Catalog.
-
compute sem servidor está habilitado para seu workspace. Consulte os requisitos compute sem servidor.
-
Se você planeja criar uma conexão: Você tem privilégios
CREATE CONNECTIONno metastore. Consulte a seção sobre privilégios de gerenciamento no Unity Catalog.Se o seu conector suportar a criação pipeline baseada em interface de usuário, você poderá criar a conexão e o pipeline simultaneamente, concluindo os passos desta página. No entanto, se você usar a criação pipeline baseada em API, deverá criar a conexão no Catalog Explorer antes de concluir os passos desta página. Consulte Conectar para gerenciar fontes de ingestão.
-
Se você planeja usar uma conexão existente: Você tem privilégios
USE CONNECTIONouALL PRIVILEGESna conexão. -
Você tem privilégios
USE CATALOGno catálogo de destino. -
Você tem privilégios
USE SCHEMA,CREATE TABLEeCREATE VOLUMEem um esquema existente ou privilégiosCREATE SCHEMAno catálogo de destino. -
Você tem acesso a uma instância primária do PostgreSQL. A replicação lógica só é suportada em instâncias primárias e não em réplicas de leitura.
-
Permissões irrestritas para criar clusters ou uma política personalizada (somente API). Uma política personalizada para o gateway deve atender aos seguintes requisitos:
-
Família: Computação Job
-
Substituições de família de políticas:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
}- Databricks recomenda especificar os menores nós worker possíveis para os gateways de ingestão, pois isso não afeta o desempenho do gateway. A seguinte política compute permite que Databricks aumente a capacidade do gateway de ingestão para atender às necessidades da sua carga de trabalho. O requisito mínimo é de 8 núcleos para permitir a extração de dados eficiente e de alto desempenho do seu banco de dados de origem.
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "r5n.16xlarge"
},
"node_type_id": {
"type": "fixed",
"value": "m5n.large"
}
}Para obter mais informações sobre política de cluster, consulte Selecionar uma política compute.
-
-
-
Para importar dados do PostgreSQL, você também precisa concluir a configuração da fonte.
Crie um gateway e um pipeline de ingestão.
Interface do usuário do Databricks
-
Na barra lateral do workspace do Databricks , clique em ingestão de dados .
-
Na página Adicionar dados , em Conectores do Databricks , clique em PostgreSQL .
-
Na página **Conexão** do assistente de ingestão, selecione a conexão que armazena suas credenciais de acesso do PostgreSQL. Se você tiver o privilégio
CREATE CONNECTIONno metastore, poderá clicar em Criar conexão para criar uma nova conexão com os detalhes de autenticação em Criar uma Conexão PostgreSQL.
Criar conexão para criar uma nova conexão com os detalhes de autenticação em Criar uma Conexão PostgreSQL. -
Clique em Avançar .
-
Na página de configuração de ingestão , insira um nome exclusivo para o pipeline de ingestão. Este pipeline move dados do local de armazenamento temporário para o destino.
-
Selecione um catálogo e um esquema para gravar logs de eventos. O log de eventos contém logs de auditoria, verificações de qualidade de dados, progresso pipeline e erros. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
(Opcional) Defina a refresh automática completa para todas as tabelas como Ativada . Quando refresh automática está ativada, o pipeline tenta corrigir automaticamente problemas como eventos de limpeza log e certos tipos de evolução do esquema, atualizando completamente a tabela afetada. Se a história acompanhamento estiver habilitada, uma refresh completa apagará essa história.
-
Insira um nome exclusivo para o gateway de ingestão. O gateway é um pipeline que extrai as alterações da origem e as prepara para que o pipeline de ingestão as carregue.
-
Selecione um catálogo e um esquema para o local de preparação . Neste local é criado um volume para estágio de remoção de dados. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
Clique em Criar pipeline e continue .
-
Na página Origem , selecione as tabelas que deseja importar. Se você selecionar tabelas específicas, poderá configurar as definições da tabela:
a. (Opcional) Na tab Configurações , especifique um nome de destino para cada tabela ingerida. Isso é útil para diferenciar entre tabelas de destino quando você ingere um objeto no mesmo esquema várias vezes. Consulte Nomear uma tabela de destino.
um. (Opcional) Altere a configuração default da história acompanhamento . Consulte Habilitar história envio (SCD tipo 2).
-
Clique em Avançar e, em seguida, clique em Salvar e continuar .
-
Na página Destino , selecione um catálogo e um esquema para carregar os dados. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
Clique em Salvar e continuar .
-
Na página de configuração do banco de dados , insira o nome do slot de replicação e o nome da publicação para cada banco de dados do qual você deseja ingerir dados.
-
(Opcional) Na página de programação e notificações , clique em
Criar programar . Defina a frequência de refresh das tabelas de destino. -
(Opcional) Clique
Adicione uma notificação para configurar notificações email para operações pipeline bem-sucedidas ou com falha e, em seguida, clique em Salvar e execute pipeline .
Antes de ingerir usando Declarative Automation Bundles, APIs do Databricks, SDKs do Databricks, a CLI do Databricks ou Terraform, você deve ter acesso a uma conexão Unity Catalog existente. Para obter instruções, consulte Criar uma conexão PostgreSQL.
Crie o catálogo e o esquema de preparação.
O catálogo e o esquema de preparação podem ser os mesmos que o catálogo e o esquema de destino. O catálogo de encenação não pode ser um catálogo estrangeiro.
- CLI
export CONNECTION_NAME="my_postgresql_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_postgresql_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="postgresql-instance.example.com"
export DB_PORT="5432"
export DB_DATABASE="your_database"
export DB_USER="databricks_replication"
export DB_PASSWORD="your_secure_password"
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "POSTGRESQL",
"options": {
"host": "'"$DB_HOST"'",
"port": "'"$DB_PORT"'",
"database": "'"$DB_DATABASE"'",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
O gateway de ingestão extrai dados de snapshot e de alterações do banco de dados de origem e os armazena no volume de preparação Unity Catalog . Você deve executar o gateway como um pipeline contínuo. Isso é fundamental para PostgreSQL evitar o inchaço do log de escrita antecipada (WAL) e garantir que os slots de replicação não acumulem alterações não consumidas.
O pipeline de ingestão aplica os dados de snapshot e de alteração do volume de preparação às tabelas de transmissão de destino.
Pacotes de Automação Declarativa
Você pode implantar um pipeline de ingestão usando Declarative Automation Bundles. Os pacotes podem conter definições YAML de Job e tarefa, são gerenciados usando a CLI Databricks e podem ser compartilhados e executados em diferentes espaços de trabalho de destino (como desenvolvimento, teste e produção). Para obter mais informações, consulte Pacotes de automação declarativa.
-
Crie um pacote usando a CLI do Databricks:
Bashdatabricks bundle init -
Adicione dois novos arquivos de recursos ao pacote:
- Um arquivo de definição de pipeline (por exemplo,
resources/postgresql_pipeline.yml). - Um arquivo de definição de trabalho que controla a frequência de ingestão de dados (por exemplo,
resources/postgresql_job.yml).
Segue abaixo um exemplo de arquivo
resources/postgresql_pipeline.yml:YAMLvariables:
# Common variables used multiple places in the DAB definition.
gateway_name:
default: postgresql-gateway
dest_catalog:
default: main
dest_schema:
default: ingest-destination-schema
resources:
pipelines:
gateway:
name: ${var.gateway_name}
gateway_definition:
connection_name: <postgresql-connection>
gateway_storage_catalog: main
gateway_storage_schema: ${var.dest_schema}
gateway_storage_name: ${var.gateway_name}
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}
pipeline_postgresql:
name: postgresql-ingestion-pipeline
ingestion_definition:
ingestion_gateway_id: ${resources.pipelines.gateway.id}
source_type: POSTGRESQL
objects:
# Modify this with your tables!
- table:
# Ingest the table public.orders to dest_catalog.dest_schema.orders.
source_catalog: your_database
source_schema: public
source_table: orders
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
- schema:
# Ingest all tables in the public schema to dest_catalog.dest_schema. The destination
# table name will be the same as it is on the source.
source_catalog: your_database
source_schema: public
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
source_configurations:
- catalog:
source_catalog: your_database
postgres:
slot_config:
slot_name: databricks_slot
publication_name: databricks_publication
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}Segue abaixo um exemplo de arquivo
resources/postgresql_job.yml:YAMLresources:
jobs:
postgresql_dab_job:
name: postgresql_dab_job
trigger:
# Run this job every day, exactly one day from the last run
# See https://docs.databricks.com/api/workspace/jobs/create#trigger
periodic:
interval: 1
unit: DAYS
email_notifications:
on_failure:
- <email-address>
tasks:
- task_key: refresh_pipeline
pipeline_task:
pipeline_id: ${resources.pipelines.pipeline_postgresql.id} - Um arquivo de definição de pipeline (por exemplo,
-
Implante o pipeline usando a CLI Databricks :
Bashdatabricks bundle deploy
Notebook Databricks
Atualize a célula Configuration no seguinte Notebook com a conexão de origem, catálogo de destino, esquema de destino e tabelas a serem ingeridas da origem.
Create gateway and ingestion pipeline
CLI do Databricks
Para criar o gateway:
gateway_json=$(cat <<EOF
{
"name": "$GATEWAY_PIPELINE_NAME",
"catalog": "$STAGING_CATALOG",
"schema": "$STAGING_SCHEMA",
"gateway_definition": {
"connection_name": "$CONNECTION_NAME",
"gateway_storage_catalog": "$STAGING_CATALOG",
"gateway_storage_schema": "$STAGING_SCHEMA",
"gateway_storage_name": "$GATEWAY_PIPELINE_NAME"
}
}
EOF
)
output=$(databricks pipelines create --json "$gateway_json")
echo $output
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
Para criar o pipeline de ingestão:
pipeline_json=$(cat <<EOF
{
"name": "$INGESTION_PIPELINE_NAME",
"catalog": "$TARGET_CATALOG",
"schema": "$TARGET_SCHEMA",
"ingestion_definition": {
"ingestion_gateway_id": "$GATEWAY_PIPELINE_ID",
"source_type": "POSTGRESQL",
"objects": [
{
"table": {
"source_catalog": "your_database",
"source_schema": "public",
"source_table": "orders",
"destination_catalog": "$TARGET_CATALOG",
"destination_schema": "$TARGET_SCHEMA",
"destination_table": "orders"
}
},
{
"schema": {
"source_catalog": "your_database",
"source_schema": "public",
"destination_catalog": "$TARGET_CATALOG",
"destination_schema": "$TARGET_SCHEMA"
}
}
],
"source_configurations": [
{
"catalog": {
"source_catalog": "your_database",
"postgres": {
"slot_config": {
"slot_name": "databricks_slot",
"publication_name": "databricks_publication"
}
}
}
}
]
}
}
EOF
)
databricks pipelines create --json "$pipeline_json"
Requer o Databricks CLI versão 0.276.0 ou posterior.
Terraform
Você pode usar Terraform para implantar e gerenciar um pipeline de ingestão PostgreSQL . Para um framework de exemplo completo, incluindo configurações Terraform para criação de gateways e pipeline de ingestão, consulte os exemplos Terraform LakeFlow Connect catalogados no GitHub.
começar, programar e definir alerta em seu pipeline
Para obter informações sobre como iniciar, programar e configurar alertas em seu pipeline, consulte Tarefa comum de manutenção pipeline.
Verificar se a ingestão de dados foi bem-sucedida
A view em lista na página de detalhes pipeline mostra o número de registros processados à medida que os dados são ingeridos. Esses números refresh automaticamente.
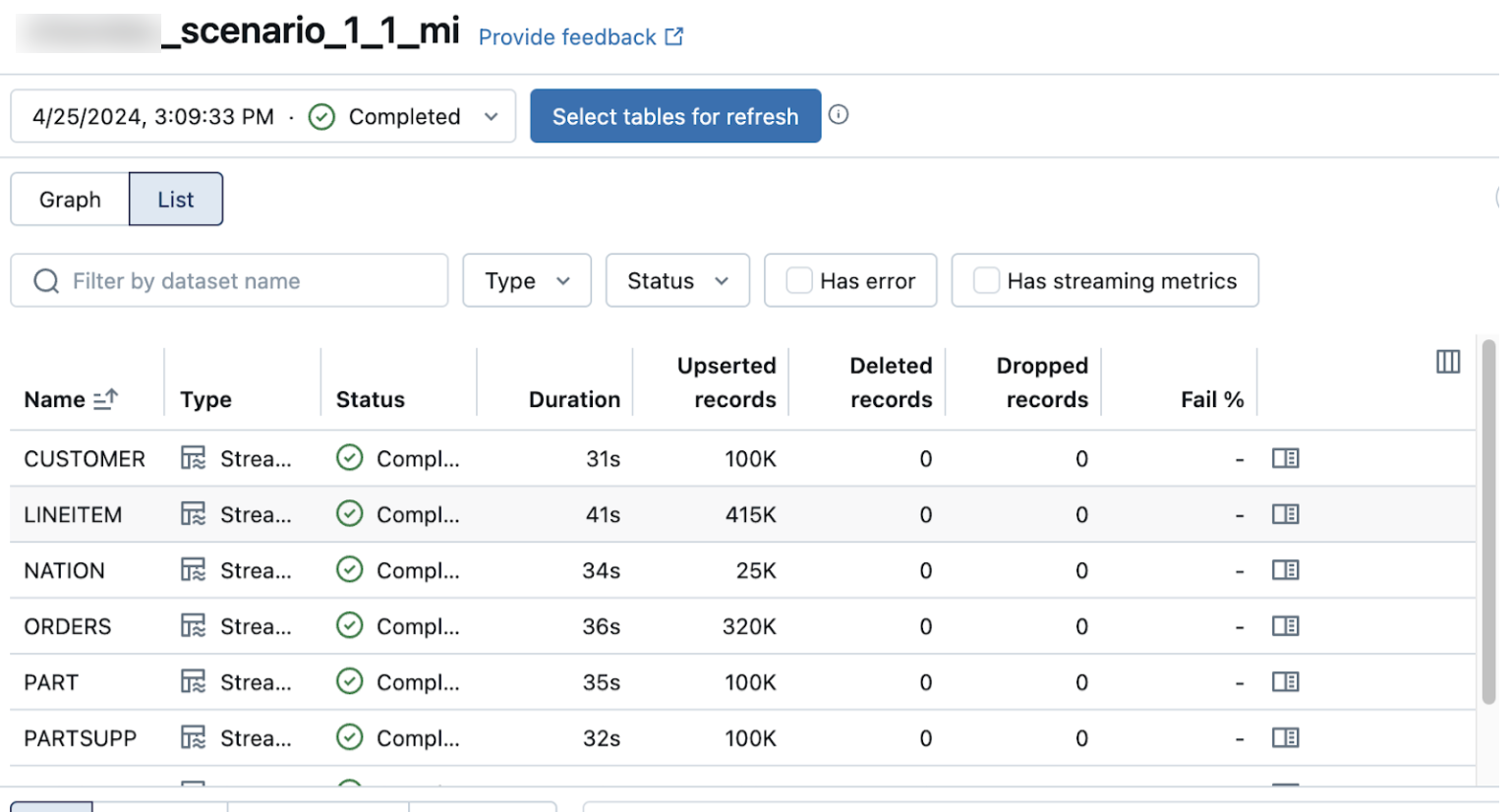
As colunas Upserted records e Deleted records não são exibidas por default. Você pode habilitá-las clicando na configuração das colunas.![]() botão e selecionando-os.
botão e selecionando-os.