Habilitar o acompanhamento da história (SCD type 2)
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados ![]() Conectores baseados em consultas
Conectores baseados em consultas
A configuração história acompanhamento, também conhecida como a configuração dimensões que mudam lentamente (SCD) (SCD), determina como lidar com as alterações nos dados ao longo do tempo. Desative o acompanhamento da história (SCD type 1) para sobrescrever registros desatualizados à medida que são atualizados e excluídos na fonte. Ative o acompanhamento do histórico (SCD type 2) para manter um histórico dessas alterações. A exclusão de uma tabela ou coluna na origem não exclui esses dados do destino, mesmo quando o SCD tipo 1 está selecionado.
Nem todos os conectores suportam SCD tipo 2. Para obter detalhes sobre a compatibilidade, consulte a seção de disponibilidade de recursos na página de visão geral do seu conector.
história envio comportamento
Por exemplo, digamos que você ingere a tabela a seguir:
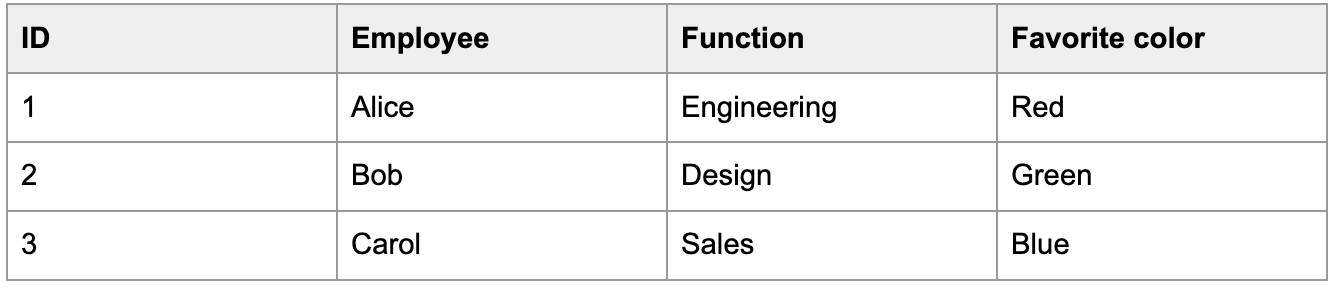
Digamos também que a cor favorita de Alice mude para roxo em 2 de janeiro.
Se o acompanhamento da história estiver desativado (SCD type 1), a próxima execução da ingestão pipeline atualiza essa linha na tabela de destino.
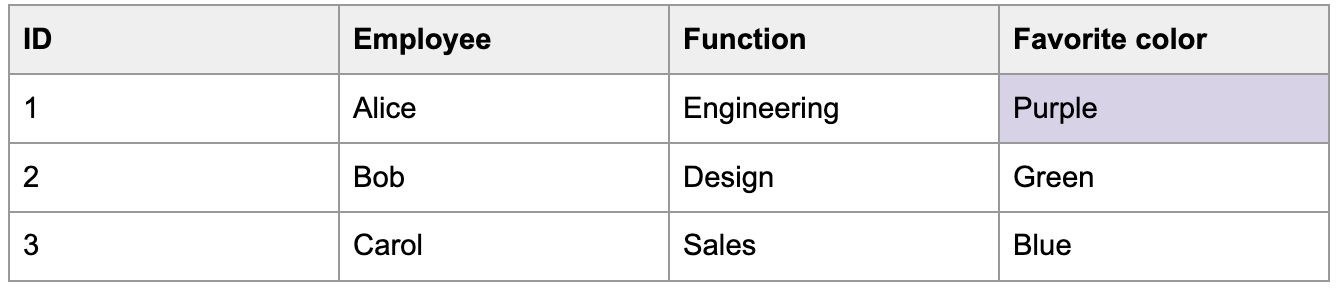
Se o acompanhamento da história estiver ativado (SCD type 2), a ingestão pipeline mantém a linha antiga e adiciona a atualização como uma nova linha. Ele marca a linha antiga como inativa para que você saiba qual linha está atualizada.

Habilite o envio da história na UI
Você pode habilitar o acompanhamento da história ao criar ou editar o pipeline de ingestão de gerenciamento na interface do usuário Databricks .
Na página Fonte do assistente de aquisição de dados, selecione Ativado no menu suspenso história acompanhamento (SCD tipo 2).
![]()
Habilite o envio da história usando a API
Você pode habilitar o acompanhamento de história ao criar ou editar o pipeline de ingestão de gerenciamento usando Declarative Automation Bundles, Notebook ou Databricks CLI , especificando o parâmetro scd_type .
SCD_TYPE_1: história envio offSCD_TYPE_2: Ótimo em
Exemplos: Google Analytics
O SCD tipo 2 é compatível com as tabelas users e pseudonymous_users usando last_updated_date como a coluna do cursor. Não há suporte para tabelas em nível de evento, que são somente para anexos.
- Declarative Automation Bundles
- Databricks notebook
- Databricks CLI
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte configuração YAML mostra como alterar essa configuração em um pacote:
resources:
pipelines:
pipeline_ga4:
name: <pipeline-name>
catalog: <destination-catalog>
schema: <destination-schema>
ingestion_definition:
connection_name: <connection-name>
objects:
- table:
source_url: <project-id>
source_schema: <property-name>
destination_catalog: <destination-catalog>
destination_schema: <destination-schema>
table_configuration:
scd_type: SCD_TYPE_2
Por default, a história acompanhamento está desligada (SCD tipo 1). O código Python a seguir mostra como alterar essa configuração em um Notebook:
pipeline_spec = """
{
"name": "<pipeline-name>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_url": "<project-id>",
"source_schema": "<property-name>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2",
}
}
}
]
}
}
"""
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte especificação JSON mostra como alterar essa configuração usando a CLI:
{
"resources": {
"pipelines": {
"pipeline_ga4": {
"name": "<pipeline-name>",
"catalog": "<destination-catalog>",
"schema": "<destination-schema>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_url": "<project-id>",
"source_schema": "<property-name>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2"
}
}
}
]
}
}
}
}
}
Exemplos: Salesforce
- Declarative Automation Bundles
- Databricks notebook
- Databricks CLI
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte configuração YAML mostra como alterar essa configuração em um pacote:
resources:
pipelines:
pipeline_sfdc:
name: <pipeline-name>
catalog: <destination-catalog>
schema: <destination-schema>
ingestion_definition:
connection_name: <connection-name>
objects:
- table:
source_schema: <source-schema>
source_table: <source-table>
destination_catalog: <destination-catalog>
destination_schema: <destination-schema>
table_configuration:
scd_type: SCD_TYPE_2
Por default, a história acompanhamento está desligada (SCD tipo 1). O código Python a seguir mostra como alterar essa configuração em um Notebook:
pipeline_spec = """
{
"name": "<pipeline-name>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_catalog": "<source-catalog>",
"source_schema": "<source-schema>",
"source_table": "<source-table>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2",
}
}
}
]
}
}
"""
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte especificação JSON mostra como alterar essa configuração usando a CLI:
{
"resources": {
"pipelines": {
"pipeline_sfdc": {
"name": "<pipeline-name>",
"catalog": "<destination-catalog>",
"schema": "<destination-schema>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_schema": "<source-schema>",
"source_table": "<source-table>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2"
}
}
}
]
}
}
}
}
}
Exemplos: SQL Server
A coluna de sequência que o senhor especifica na configuração do pipeline (por exemplo, last_updated, modified_at ou version_number) determina o intervalo de tempo em que cada versão de linha estava ativa (registrada nas colunas __START_AT e __END_AT na tabela de destino).
Os seguintes tipos de coluna sequence_by são suportados:
- Carimbo de data/hora
- Data
- Integer
- Long
- String
- Declarative Automation Bundles
- Databricks notebook
- Databricks CLI
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte configuração YAML mostra como alterar essa configuração em um pacote:
resources:
pipelines:
pipeline_sqlserver:
name: <pipeline-name>
catalog: <destination-catalog>
schema: <destination-schema>
ingestion_definition:
connection_name: <connection-name>
objects:
- table:
source_catalog: <source-catalog>
source_schema: <source-schema>
source_table: <source-table>
destination_catalog: <destination-catalog>
destination_schema: <destination-schema>
table_configuration:
scd_type: SCD_TYPE_2
sequence_by: <sequence-column>
Por default, a história acompanhamento está desligada (SCD tipo 1). O código Python a seguir mostra como alterar essa configuração em um Notebook:
pipeline_spec = """
{
"name": "<pipeline-name>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_catalog": "<source-catalog>",
"source_schema": "<source-schema>",
"source_table": "<source-table>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2",
"sequence_by": "<version-number>"
}
}
}
]
}
}
"""
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte especificação JSON mostra como alterar essa configuração usando a CLI:
{
"resources": {
"pipelines": {
"pipeline_sqlserver": {
"name": "<pipeline-name>",
"catalog": "<destination-catalog>",
"schema": "<destination-schema>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"table": {
"source_catalog": "<source-catalog>",
"source_schema": "<source-schema>",
"source_table": "<source-table>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2",
"sequence_by": "<version-number>"
}
}
}
]
}
}
}
}
}
Exemplos: Relatórios do Workday
- Declarative Automation Bundles
- Databricks notebook
- Databricks CLI
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte configuração YAML mostra como alterar essa configuração em um pacote:
resources:
pipelines:
pipeline_workday:
name: <pipeline-name>
catalog: <destination-catalog>
schema: <destination-schema>
ingestion_definition:
connection_name: <connection-name>
objects:
- report:
source_url: <report-url>
destination_catalog: <destination-catalog>
destination_schema: <destination-schema>
table_configuration:
scd_type: SCD_TYPE_2
Por default, a história acompanhamento está desligada (SCD tipo 1). O código Python a seguir mostra como alterar essa configuração em um Notebook:
pipeline_spec = """
{
"name": "<pipeline-name>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"report": {
"source_url": "<report-url>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2",
}
}
}
]
}
}
"""
Por default, a história acompanhamento está desligada (SCD tipo 1). A seguinte especificação JSON mostra como alterar essa configuração usando a CLI:
{
"resources": {
"pipelines": {
"pipeline_workday": {
"name": "<pipeline-name>",
"catalog": "<destination-catalog>",
"schema": "<destination-schema>",
"ingestion_definition": {
"connection_name": "<connection-name>",
"objects": [
{
"report": {
"source_url": "<report-url>",
"destination_catalog": "<destination-catalog>",
"destination_schema": "<destination-schema>",
"table_configuration": {
"scd_type": "SCD_TYPE_2"
}
}
}
]
}
}
}
}
}
Limitações
A execução de um refresh completo substitui a tabela inteira. Isso remove todas as versões anteriores da linha. A nova história é rastreada a partir do ponto refresh.