Automatizar a criação e o gerenciamento de trabalhos
Automatize a criação e o gerenciamento de jobs com ferramentas de desenvolvedor: a CLI da Databricks, os SDKs da Databricks e a API REST.
Os exemplos aqui usam a CLI do Databricks, o SDK do Databricks para Python e a API REST como uma introdução a essas ferramentas. Para gerenciar Jobs programaticamente como parte do CI/CD, use Pacotes de Automação Declarativa ou o provedor Databricks Terraform.
Compare ferramentas
A tabela a seguir compara o Databricks CLI, os SDKs do Databricks e o REST API para criar e gerenciar trabalhos de forma programática. Para saber mais sobre todas as ferramentas de desenvolvimento disponíveis, consulte Ferramentas de desenvolvimento local.
Ferramenta | Descrição |
|---|---|
Acesse a funcionalidade do Databricks usando a interface de linha de comando (CLI) do Databricks, que envolve a API REST. Use o CLI para tarefas pontuais, como experimentação, shell criação de scripts e invocação direta do REST API | |
Desenvolva aplicativos e crie Databricks fluxos de trabalho personalizados usando um Databricks SDK, disponível para Python, Java, Go ou R. Em vez de enviar REST API chamadas diretamente usando curl ou Postman, o senhor pode usar um SDK para interagir com Databricks. | |
Se nenhuma das opções acima funcionar para seu caso de uso específico, o senhor pode usar a API REST da Databricks diretamente. Use a API REST diretamente para casos de uso, como a automação de processos em que um SDK na linguagem de programação de sua preferência não está disponível no momento. |
Começar com o site Databricks CLI
Para instalar e configurar a autenticação para a CLI da Databricks, consulte Instalar ou atualizar a CLI da Databricks e Autenticação para a CLI da Databricks.
O site Databricks CLI tem grupos de comandos para Databricks recurso, incluindo um para Job, que contém um conjunto de comandos relacionados, que também podem conter subcomandos. O grupo de comando jobs permite que o senhor gerencie o trabalho e a execução do trabalho com ações como create, delete e get. Como o CLI envolve o Databricks REST API, a maioria dos CLI comando mapeia para uma solicitação REST API . Por exemplo, databricks jobs get mapeia para GET/api/2.2/jobs/get.
Para gerar informações mais detalhadas sobre o uso e a sintaxe do grupo de comandos do trabalho, de um comando individual ou de um subcomando, use o sinalizador h:
databricks jobs -hdatabricks jobs <command-name> -hdatabricks jobs <command-name> <subcommand-name> -h
Exemplo: Recuperar um trabalho usando o CLI
Para imprimir informações sobre um trabalho individual em um site workspace, execute o seguinte comando:
$ databricks jobs get <job-id>
databricks jobs get 478701692316314
Esse comando retorna JSON:
{
"created_time": 1730983530082,
"creator_user_name": "someone@example.com",
"job_id": 478701692316314,
"run_as_user_name": "someone@example.com",
"settings": {
"email_notifications": {
"no_alert_for_skipped_runs": false
},
"format": "MULTI_TASK",
"max_concurrent_runs": 1,
"name": "job_name",
"tasks": [
{
"email_notifications": {},
"notebook_task": {
"notebook_path": "/Workspace/Users/someone@example.com/directory",
"source": "WORKSPACE"
},
"run_if": "ALL_SUCCESS",
"task_key": "success",
"timeout_seconds": 0,
"webhook_notifications": {}
},
{
"depends_on": [
{
"task_key": "success"
}
],
"disable_auto_optimization": true,
"email_notifications": {},
"max_retries": 3,
"min_retry_interval_millis": 300000,
"notebook_task": {
"notebook_path": "/Workspace/Users/someone@example.com/directory",
"source": "WORKSPACE"
},
"retry_on_timeout": false,
"run_if": "ALL_SUCCESS",
"task_key": "fail",
"timeout_seconds": 0,
"webhook_notifications": {}
}
],
"timeout_seconds": 0,
"webhook_notifications": {}
}
}
Exemplo: Criar um trabalho usando o CLI
O exemplo a seguir usa o site Databricks CLI para criar um trabalho. Esse Job contém uma única tarefa de Job que executa o Notebook especificado. Este Notebook depende de uma versão específica do pacote wheel PyPI . Para executar essa tarefa, o Job cria temporariamente um clustering que exporta uma variável de ambiente chamada PYSPARK_PYTHON. Após a execução do trabalho, o clustering é encerrado.
-
Copie e cole o seguinte JSON em um arquivo. O senhor pode acessar o formato JSON de qualquer trabalho existente selecionando a opção view JSON na UI da página do trabalho.
JSON{
"name": "My hello notebook job",
"tasks": [
{
"task_key": "my_hello_notebook_task",
"notebook_task": {
"notebook_path": "/Workspace/Users/someone@example.com/hello",
"source": "WORKSPACE"
}
}
]
} -
execute o seguinte comando, substituindo
<file-path>pelo caminho e nome do arquivo que o senhor acabou de criar.Bashdatabricks jobs create --json @<file-path>
execução de um trabalho usando a CLI
Há três maneiras de executar seu Job ao usar a linha de comando.
-
Agendado . Se a definição do Job (em JSON) inclui uma programação, como o seguinte exemplo, então o Job é executado automaticamente conforme a programação.
JSON"schedule": {
"quartz_cron_expression": "46 0 9 * * ?",
"timezone_id": "America/Los_Angeles",
"pause_status": "UNPAUSED"
},
"max_concurrent_runs": 1, -
Disparar com
run-now. O comando CLIdatabricks jobs run-nowinicia a execução de um Job que você já criou. -
Disparar com
submit. O comando CLIdatabricks jobs submitrecebe uma definição de Job e inicia a execução do Job.Com
submit, o trabalho não é salvo e não fica visível na interface do usuário. A tarefa é executada uma única vez e, quando concluída, deixa de existir como um trabalho.Como não são salvos, os trabalhos submetidos não podem ser otimizados automaticamente para compute serverless em caso de falha. Se a sua tarefa falhar, você pode usar o compute clássico para especificar as necessidades compute da tarefa. Ou use
jobs createejobs run-nowpara criar e executar o Job.
Começar com o site Databricks SDK
A Databricks fornece SDKs que permitem automatizar operações usando linguagens de programação populares, como Python, Java e Go. Esta seção mostra como começar a usar o Python SDK para criar e gerenciar o Job em Databricks.
O senhor pode usar o Databricks SDK do Notebook Databricks ou do computador de desenvolvimento local. Se estiver usando seu computador de desenvolvimento local, certifique-se de concluir primeiro o Get começar com o Databricks SDK para Python.
Se estiver desenvolvendo a partir de um notebook Databricks e estiver usando um clustering que utilize Databricks Runtime 12.2 LTS e abaixo, será necessário instalar primeiro o Databricks SDK para Python. Consulte Instalar ou atualizar o Databricks SDK para Python.
Exemplo: Criar um trabalho usando o site Python SDK
O exemplo de código de Notebook a seguir cria um Job que executa um Notebook existente. Ele recupera o caminho do Notebook existente e as configurações de trabalho relacionadas com prompts.
Primeiro, certifique-se de que a versão correta do SDK tenha sido instalada:
%pip install --upgrade databricks-sdk==0.74.0
%restart_python
Em seguida, para criar um Job com uma tarefa de Notebook, execute o seguinte, respondendo aos prompts:
from databricks.sdk.service.jobs import JobSettings as Job
from databricks.sdk import WorkspaceClient
job_name = input("Provide a short name for the job, for example, my-job: ")
notebook_path = input("Provide the workspace path of the notebook to run, for example, /Users/someone@example.com/my-notebook: ")
task_key = input("Provide a unique key to apply to the job's tasks, for example, my-key: ")
test_sdk = Job.from_dict(
{
"name": job_name ,
"tasks": [
{
"task_key": task_key,
"notebook_task": {
"notebook_path": notebook_path,
"source": "WORKSPACE",
},
},
],
}
)
w = WorkspaceClient()
j = w.jobs.create(**test_sdk.as_shallow_dict())
print(f"View the job at {w.config.host}/#job/{j.job_id}\n")
execução de um trabalho usando o Python SDK
Existem três maneiras de executar um Job ao usar a API.
-
Agendado . Se a definição do Job (em JSON) inclui uma programação, como o seguinte exemplo, então o Job é executado automaticamente conforme a programação.
JSON"schedule": {
"quartz_cron_expression": "46 0 9 * * ?",
"timezone_id": "America/Los_Angeles",
"pause_status": "UNPAUSED"
},
"max_concurrent_runs": 1, -
Disparar com
run-now. A APIjobs.run_nowaciona a execução de um Job que você já criou. -
Disparar com
submit. A APIjobs.runs.submitrecebe uma definição de Job e aciona uma execução para o Job.Com
submit, o trabalho não é salvo e não fica visível na interface do usuário. A tarefa é executada uma única vez e, quando concluída, deixa de existir como um trabalho.Como não são salvos, os trabalhos submetidos não podem ser otimizados automaticamente para compute serverless em caso de falha. Se a sua tarefa falhar, você pode usar o compute clássico para especificar as necessidades compute da tarefa. Ou use
jobs.createejobs.run_nowpara criar e executar o Job.
Comece a trabalhar com o Databricks REST API
A Databricks recomenda usar o Databricks CLI e um Databricks SDK, a menos que o senhor esteja usando uma linguagem de programação que não tenha um Databricks SDK correspondente.
O exemplo a seguir faz uma solicitação à API REST Databricks para recuperar detalhes de um único trabalho. Ele assume que as variáveis de ambiente DATABRICKS_HOST e DATABRICKS_TOKEN foram definidas conforme descrito em Executar autenticação access token pessoal.
$ curl --request GET "https://${DATABRICKS_HOST}/api/2.2/jobs/get" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}" \
--data '{ "job": "11223344" }'
Para obter informações sobre o uso do site Databricks REST API , consulte a documentação de referênciaDatabricks REST API.
visualizar o trabalho como código
No site Databricks workspace , o senhor pode view a representação JSON, YAML ou Python de um trabalho.
-
Na barra lateral do site Databricks workspace, clique em Jobs & pipeline e selecione um Job.
-
Clique no botão à esquerda do botão executar agora e, em seguida, clique em visualizar como código :
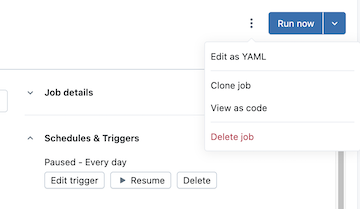
-
Clique em YAML , Python ou JSON para view o trabalho como código nessa linguagem.
-
Para YAML, clique em Copiar e cole o código diretamente nos arquivos de configuração do Declarative Automation Bundles
*.yamlpara incluir o Job existente em um pacote. Você também pode clicar em Editar para modificar a configuração da tarefa em YAML em vez da interface do usuário. -
Para Python, escolha Databricks SDK ou Pacotes de Automação Declarativa e clique em Copiar .
- O código Python para o SDK pode ser usado para criar o trabalho no Notebook ou localmente ao usar o Databricks Python SDK. Consulte Criar um trabalho usando o site Python SDK .
- O código Python para pacotes pode ser usado para incluir o Job em um pacote usando Python. Consulte Configuração do pacote em Python.
-
Para JSON, clique em Copy e use o código para criar, atualizar ou obter o trabalho usando o Databricks CLIo Databricks SDKs ou o Databricks REST API.
-
Limpe
Para excluir um trabalho que o senhor acabou de criar, execute databricks jobs delete <job-id> no site Databricks CLI ou exclua o trabalho diretamente da interface do usuário Databricks workspace .
Recursos adicionais
- Para saber mais sobre o Databricks CLI, consulte What is the Databricks CLI? e Databricks CLI comando para saber mais sobre outros grupos de comando.
- Para saber mais sobre o SDK da Databricks, consulte SDKs da Databricks.
- Para saber mais sobre CI/CD usando Databricks consulte Pacotes de Automação Declarativa e Databricks Terraform do Databricks.
- Para uma visão geral abrangente de todas as ferramentas para desenvolvedores, consulte Ferramentas de desenvolvimento local.