Usar uma tabela de pesquisa para matrizes de parâmetros grandes em uma tarefa For each
For each A tarefa passa matrizes de parâmetros para a tarefa aninhada de forma iterativa, para fornecer a cada tarefa aninhada informações para sua execução. As matrizes de parâmetros são limitadas a 10.000 caracteres ou 48 KB se o senhor usar referências de valor de tarefa para passá-las. Quando o senhor tem uma quantidade maior de dados para passar para a tarefa aninhada, não é possível usar diretamente os parâmetros de entrada, valores da tarefa ou Job para passar esses dados.
Uma alternativa para passar os dados completos é armazenar os dados da tarefa como um arquivo JSON e passar uma pesquisa key (nos dados JSON ) por meio da entrada da tarefa em vez dos dados completos. A tarefa aninhada pode usar o site key para recuperar os dados específicos necessários para cada iteração.
O exemplo a seguir mostra um arquivo de configuração JSON de amostra e como passar parâmetros para uma tarefa aninhada que procura os valores na configuração JSON.
Exemplo de configuração JSON
Esse exemplo de configuração é uma lista de etapas, com parâmetros (args) para cada iteração (somente três etapas são mostradas neste exemplo). Suponha que esse arquivo JSON seja salvo como /Workspace/Users/<user>/copy-filtered-table-config.json. Fazemos referência a isso na tarefa aninhada.
{
"steps": [
{
"key": "table_1",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_1",
"destination_table": "filtered_table_1",
"filter_column": "col_a",
"filter_value": "value_1"
}
},
{
"key": "table_2",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_2",
"destination_table": "filtered_table_2",
"filter_column": "col_b",
"filter_value": "value_2"
}
},
{
"key": "table_3",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_3",
"destination_table": "filtered_table_3",
"filter_column": "col_c",
"filter_value": "value_3"
}
}
]
}
Amostra For each tarefa
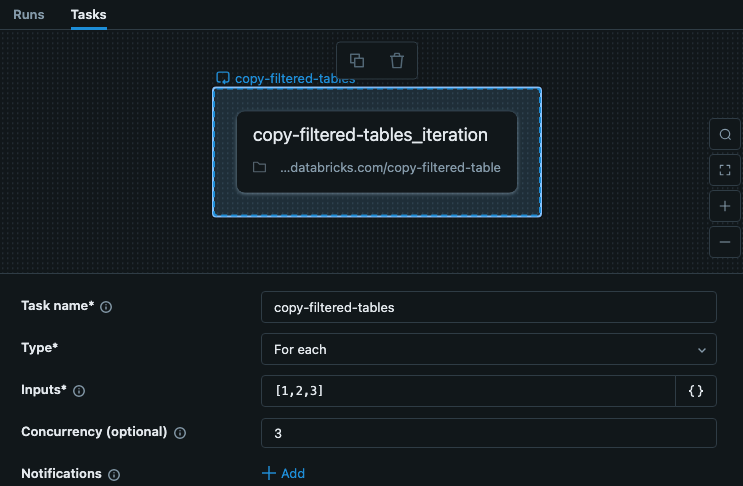
A tarefa For each em seu trabalho inclui a entrada com a chave para cada iteração. Este exemplo mostra uma tarefa chamada copy-filtered-tables com as Entradas definidas como ["table_1","table_2","table_3"]. Essa lista é limitada a 10.000 caracteres, mas como o senhor está apenas passando a chave, ela é muito menor do que os dados completos.
Neste exemplo, as etapas não dependem de outras etapas ou tarefas, portanto, podemos definir uma simultaneidade maior que 1 para tornar a execução da tarefa mais rápida.
Exemplo de tarefa aninhada
A tarefa aninhada recebe a entrada da tarefa pai For each. Nesse caso, configuramos a entrada para ser usada como Key para o arquivo de configuração. A imagem a seguir mostra a tarefa aninhada, incluindo a configuração de um parâmetro chamado key com o valor {{input}}.
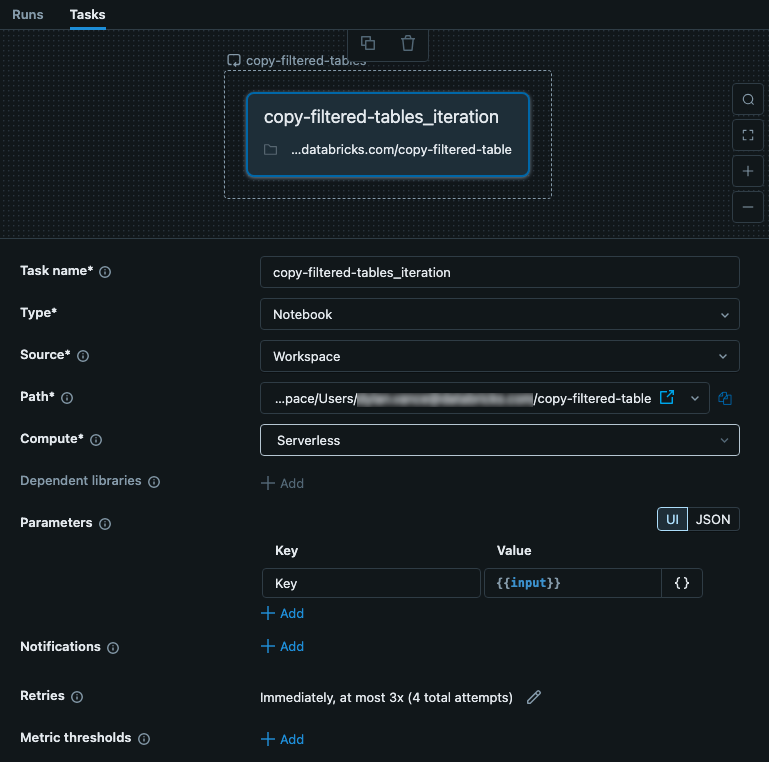
Essa tarefa é um Notebook que contém código. No Notebook, o senhor pode usar o seguinte código Python para ler a entrada e usá-la como key no arquivo de configuração JSON. Os dados do arquivo JSON são usados para ler, filtrar e gravar dados de uma tabela.
Para ver um exemplo de como controlar uma tarefa For each a partir de uma tabela Delta ativa em vez de um arquivo JSON estático, consulte Usar uma tabela de controle para controlar um Job For each.
# copy-filtered-table (iteratable task code to read a table, filter by a value, and write as a new table)
from pyspark.sql.functions import expr
from types import SimpleNamespace
import json
# If the notebook is run outside of a job with a key parameter, this provides
# a default. This allows testing outside of a For each task
dbutils.widgets.text("key", "table_1", "key")
# load configuration (note that the path must be set to valid configuration file)
config_path = "/Workspace/Users/<user>/copy-filtered-table-config.json"
with open(config_path, "r") as file:
config = json.loads(file.read())
# look up step and arguments
key = dbutils.widgets.get("key")
current_step = next((step for step in config['steps'] if step['key'] == key), None)
if current_step is None:
raise ValueError(f"Could not find step '{key}' in the configuration")
args = SimpleNamespace(**current_step["args"])
# read the source table defined for the step, and filter it
df = spark.read.table(f"{args.catalog}.{args.schema}.{args.source_table}") \
.filter(expr(f"{args.filter_column} like '%{args.filter_value}%'"))
# write the filtered table to the destination
df.write.mode("overwrite").saveAsTable(f"{args.catalog}.{args.schema}.{args.destination_table}")