Fase 3: Projetar a arquitetura Unity Catalog
Nesta fase, a infraestrutura do Unity Catalog é projetada para oferecer suporte à governança de dados, controle de acesso e organização de dados.
Unity Catalog é ativado automaticamente em espaços de trabalho em contas Databricks criadas após 8 de novembro de 2023. Para essas contas, um metastore é criado automaticamente e atribuído ao espaço de trabalho.
Para obter orientações completas Unity Catalog incluindo etapas de implementação e recursos avançados, consulte O que é Unity Catalog?
Escolha um modelo operacional de governança
Antes de projetar a arquitetura do seu Unity Catalog , selecione um modelo operacional de governança que esteja alinhado com a sua estrutura organizacional e cultura de dados. O modelo de governança determina como a propriedade dos dados, o controle de acesso e a aplicação de políticas são gerenciados em toda a sua organização.
Opções de modelo de governança
-
Governança centralizada : Cada unidade de negócios ou domínio opera em um limite de negócios diferente, mas todas as unidades estão sujeitas ao mesmo limite operacional que governa todos os dados e AI ativa (multilocação). Uma única plataforma ou equipe de governança de dados controla todos os dados ativos, políticas e acessos.
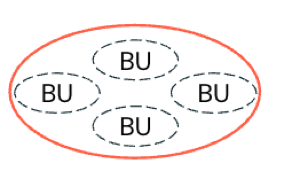
-
Governança descentralizada : Cada unidade de negócio ou domínio possui um limite operacional e de negócios independente (ou seja, tem seu próprio tenant). A governança é delegada a cada unidade de negócios para que esta defina e aplique suas próprias políticas de forma independente, com supervisão central mínima.
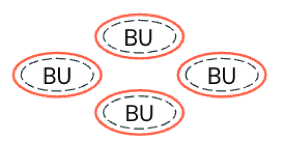
-
Governança federada : Cada unidade de negócios ou domínio possui uma fronteira operacional e de negócios independente. No entanto, as políticas de governança são definidas por um escritório de governança centralizado e aplicadas por cada unidade de negócios. As atividades críticas são regidas pelo escritório de governança (por exemplo, produto de dados compartilhados).
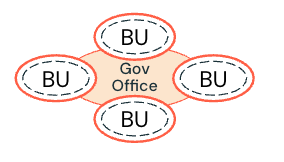
-
Governança híbrida : um modelo entre centralizado e descentralizado, que permite que cada unidade de negócios ou domínio governe seus próprios dados (descentralizado). No entanto, os dados críticos de negócios são coletados e gerenciados em um único local para uso de todos (centralizado).
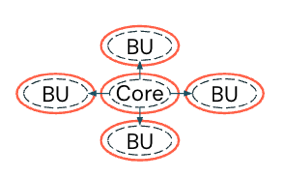
Melhores práticas para modelos de governança
- Comece com a governança federada para a maioria das organizações (equilibra controle e agilidade).
- Utilize governança centralizada para setores altamente regulamentados (por exemplo, finanças, saúde, governo).
- Documente claramente as funções e responsabilidades para cada modelo de governança.
- Alinhar o modelo de governança com as estruturas organizacionais existentes.
- Revise e ajuste o modelo de governança à medida que sua plataforma de dados amadurece.
Governança centralizada | Governança descentralizada | Governança federada | Governança híbrida | |
|---|---|---|---|---|
Definição | Uma única autoridade central controla todos os dados e políticas AI em toda a organização. | Cada unidade de negócio gerencia de forma independente suas próprias políticas de dados e AI . | As equipes centrais definem as diretrizes e os padrões, enquanto as equipes locais têm autonomia para implementá-los. | Os dados e políticas principais são gerenciados centralmente, enquanto as unidades de negócio controlam seus dados e políticas específicos de cada domínio. |
Tomando uma decisão | Todas as decisões são tomadas por uma equipe central, utilizando uma abordagem de cima para baixo. | As unidades de negócio tomam decisões de forma independente, sem coordenação central. | As equipes centrais estabelecem diretrizes, e as equipes locais tomam decisões dentro desses limites. | As equipes centrais tomam decisões relativas aos dados e à infraestrutura essenciais. As unidades de negócio tomam as suas próprias decisões de acordo com as necessidades específicas de cada área. |
Propriedade dos dados | Uma equipe central possui e gerencia todos os dados ativos. | As equipes ou unidades de negócios individuais detêm seus próprios dados, sem governança compartilhada. | Diversas equipes compartilham responsabilidades de propriedade em toda a organização. | As equipes centrais detêm os principais dados compartilhados. As unidades de negócio detêm os seus próprios dados específicos do domínio. |
Escalabilidade | A escalabilidade depende da capacidade da equipe central e pode se tornar um gargalo à medida que a organização cresce. | As unidades de negócio podem escalar problemas de forma independente, mas a coordenação entre as equipes pode ser difícil. | As organizações podem intensificar os processos, mantendo a coordenação por meio de estruturas de governança estabelecidas. | Escala de dados principais com recurso central. As unidades de negócio escalam de forma independente para seus respectivos domínios. |
conformidade e segurança | As políticas são aplicadas de forma consistente em toda a organização, com forte supervisão central. | A aplicação das normas varia de equipe para equipe, o que pode levar a falhas de segurança e práticas inconsistentes. | As equipes centrais definem os padrões de segurança e as equipes locais os aplicam em seus respectivos domínios. | Os dados principais seguem regras compliance rigorosas. As unidades de negócio têm flexibilidade para requisitos específicos de cada domínio. |
Eficiência operacional | As operações são eficientes, mas podem ser atrasadas por processos burocráticos e cadeias de aprovação. | As equipes trabalham com rapidez e se adaptam com facilidade, mas os esforços podem ser duplicados e silos podem se formar. | As organizações buscam um equilíbrio entre eficiência e flexibilidade, embora uma coordenação extensa possa tornar a tomada de decisões mais lenta. | As operações principais podem apresentar gargalos. As unidades de negócio operam de forma eficiente dentro de seus respectivos domínios. |
Adequação do caso de uso | Ideal para setores altamente regulamentados, como o financeiro e o da saúde, que exigem supervisão rigorosa. | Ideal para empresas ágeis, startups e organizações orientadas para a inovação que priorizam a velocidade. | Ideal para grandes empresas e corporações multinacionais que necessitam tanto de padrões centrais quanto de flexibilidade local. | Ideal para organizações com necessidades mistas, como empresas de tecnologia financeira (fintechs) que precisam equilibrar requisitos compliance com inovação. |
A sua escolha de modelo operacional de governança impacta o design do seu metastore. Em um modelo centralizado, você pode atribuir um único administrador de metastore. Em um modelo descentralizado, gerencie as permissões por meio de um pipeline de implantação automatizado (usando ferramentas CI/CD como Terraform), em vez de delegá-las a administradores individuais de unidades de negócios ou ambientes.
Projetar a arquitetura do metastore
Um metastore do Unity Catalog é o contêiner regional de nível superior para metadados e governança. Cada metastore armazena metadados para objetos protegíveis (por exemplo, tabelas, visualizações, volumes, locais externos, compartilhamentos) e as permissões que regem o acesso a eles. O metastore é hospedado como um serviço multi-tenant no plano de controle Databricks .
O Unity Catalog permite um único metastore por região e só permite que você use esse metastore na região atribuída a ele. Cada workspace deve ser atribuído a exatamente um metastore.
Função de administrador do Metastore
Um metastore pode ser configurado opcionalmente com um administrador de metastore, dependendo do seu modelo de governança. Essa função não é definida quando se utiliza a ativação automática do Unity Catalog. A função de administrador do metastore é necessária se você quiser gerenciar o armazenamento de objetos do Unity Catalog no nível do metastore e é conveniente se você quiser gerenciar dados centralmente em vários espaços de trabalho em uma região.
- Em um modelo centralizado , atribua um único administrador de metastore ou um grupo designado.
- Em um modelo descentralizado , as permissões são gerenciadas por meio de um pipeline de implantação automatizado, em vez de serem delegadas a administradores individuais.
Se você utiliza um administrador de metastore, é altamente recomendável atribuir a função a um grupo específico em vez de a um único usuário.
Mecanismos de isolamento
Para oferecer suporte à segregação de nível empresarial por motivos de segurança ou organização, o Unity Catalog suporta isolamento em vários níveis:
-
Isolamento administrativo (delegação de gestão) : Os dados devem ser gerenciados por pessoas ou equipes designadas, com base na finalidade ou na propriedade desses dados.
-
Vinculação de espaço de trabalho : Os dados só devem ser acessados em ambientes designados, com base na finalidade desses dados.
- Um catálogo (ou outro objeto Unity Catalog ) pode ser vinculado a vários espaços de trabalho.
- Um workspace pode ser vinculado a vários catálogos, credenciais e locais externos do mesmo metastore.
-
Isolamento de armazenamento : Os dados devem ser fisicamente separados no armazenamento.
-
Controle de acessoUnity Catalog : os usuários só devem ter acesso a dados ou metadados com base em regras de acesso previamente acordadas.
Utilize esses mecanismos de isolamento para segregar cargas de trabalho, equipes ou unidades de negócios em um único metastore por região.
Padrões de projeto do Metastore
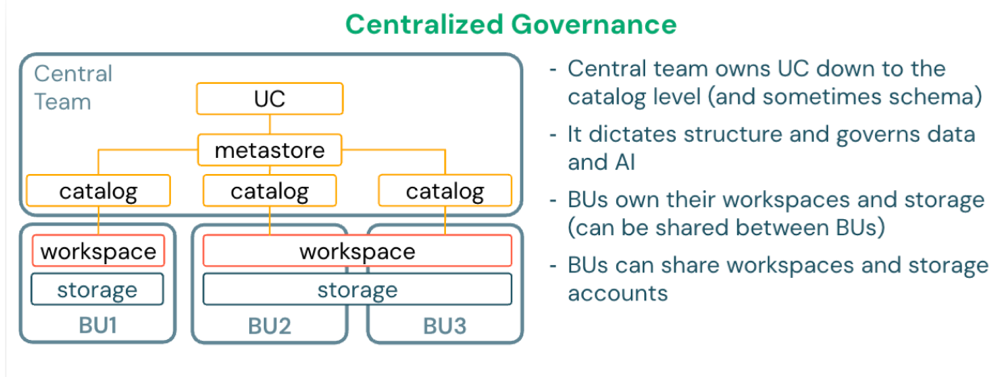
Implantação em cloud única e região única
Para organizações que operam em uma única região cloud , implante um único metastore nessa região. Todos os espaços de trabalho na região estão atribuídos a este metastore.
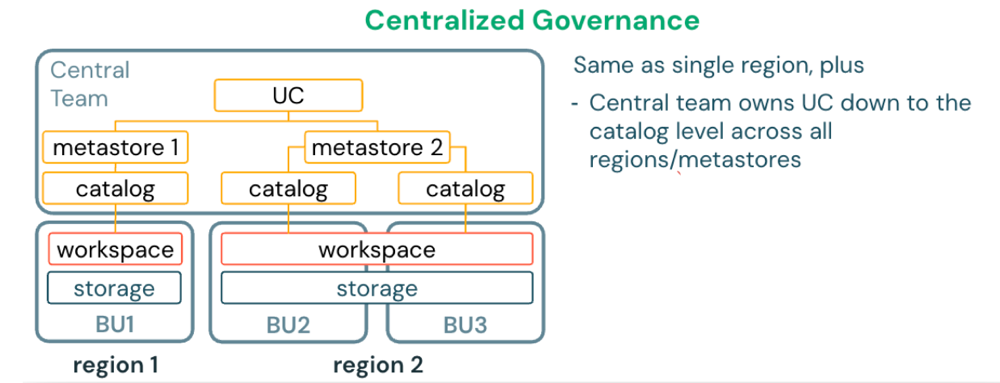
Implantação em cloud única e multirregional
Para organizações que operam em várias regiões da mesma cloud, deve-se implantar um metastore por região. Cada workspace é atribuído ao metastore em sua região. Use o OpenSharing gerenciado pela Databricks (D2D) para compartilhar dados entre metastores entre regiões.
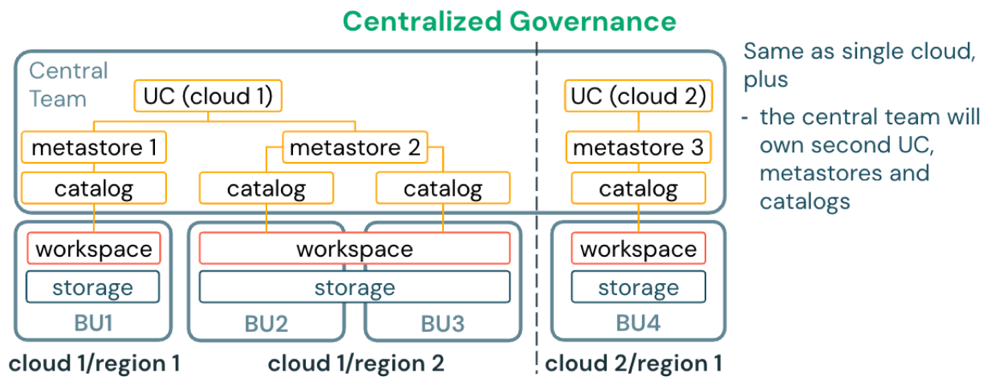
Implantação em váriascloud e várias regiões
Para organizações que operam em múltiplos provedores de nuvem e regiões, implante um metastore por região em cada nuvem. Use o OpenSharing gerenciado pela Databricks (D2D) para compartilhar dados entre metastores em clouds e regiões.
Padrões alternativos
- Um metastore por unidade de negócio : Adequado quando as unidades de negócio requerem isolamento completo, sem compartilhamento de dados.
- Um metastore por ambiente : Padrão menos comum em que os ambientes de desenvolvimento, teste e produção usam metastores separados para um isolamento estrito do ambiente.
Considerações de projeto multirregionais
Se várias regiões usarem Databricks, um único metastore do Unity Catalog deve ser implantado em cada região. Os usuários podem interagir com o metastore na mesma região do workspace onde estão logados. Para acessar os dados definidos em um metastore de outra região, o OpenSharing (D2D) gerenciado pelo Databricks é recomendado.
Não registre tabelas compartilhadas como tabelas externas em mais de um metastore. O risco é que quaisquer alterações no esquema, propriedades da tabela e comentários que ocorram como resultado de gravações no metastore A não serão registradas de forma alguma no metastore B. As tabelas no metastore B teriam que ser recriadas para ter o esquema correto, e as propriedades da tabela e os comentários estariam inteiramente desconectados. Isso também pode causar problemas de consistência com o serviço de commit do Delta. Use o D2D OpenSharing para o compartilhamento de dados entre metastores.
Melhores práticas para projetos multirregionais
- Implantar um metastore por região como default .
- Use o OpenSharing gerenciado pelo Databricks para compartilhar tabelas entre regiões.
- Avalie a frequência e o volume de acesso a dados em diferentes regiões cloud . Se o custo ficar muito alto, considere configurar um pipeline para sincronizar as tabelas entre regiões.
- Para configurações entre regiões, armazene o armazenamento raiz do metastore na mesma região que o metastore para obter melhor desempenho.
Melhores práticas para o design de um metastore
- Para simplificar a operação, utilize um metastore por região como default .
- Atribua o espaço de trabalho na mesma região ao mesmo metastore.
- Utilize catálogos dentro de um metastore para separar dados por ambiente ou domínio.
- Crie um workspace administrativo por região para gerenciar os recursos Unity Catalog .
- Documente as atribuições do metastore e os limites regionais em seu manual de procedimentos.
Para novas contas criadas após 8 de novembro de 2023, os metastores são criados e atribuídos automaticamente.
Para obter informações detalhadas sobre a arquitetura de armazenamento Unity Catalog incluindo gerenciamento, objetos externos e objetos estrangeiros, consulte a Fase 4: Projetar a arquitetura de armazenamento.
Estrutura do catálogo de design
Os catálogos são a primeira camada organizacional dentro de um metastore. Eles contêm esquemas, que por sua vez contêm tabelas, visualizações, volumes e funções. O design do seu catálogo determina como os dados ativos são organizados e acessados.
Padrões de design de catálogo
Catálogos baseados no ambiente
Catálogos separados para ambientes do ciclo de vida de desenvolvimento de software (SDLC), como desenvolvimento, teste e produção (por exemplo, dev, staging, prod). Este padrão favorece a promoção do fluxo de trabalho e previne alterações acidentais na produção.
Isole os ambientes no nível de catálogo do namespace de 3 níveis fornecido pelo Unity Catalog:
devO catálogo abrange a localização dos dados de desenvolvimento.prodO catálogo abrange a localização dos dados de produção.- Os catálogos podem ser combinações de SDLC e nomes de unidades de negócios ou organizacionais, por exemplo:
sales_dev,sales_prod,engineering_dev
Catálogos baseados em domínio
Catálogos separados para domínios de negócios ou unidades organizacionais (por exemplo, sales, marketing, finance, engineering). Esse padrão está alinhado com arquiteturas de malha de dados e propriedade de domínio.
Catálogos híbridos
Combina padrões de ambiente e domínio (por exemplo, sales_prod, sales_dev, finance_prod, finance_dev). Isso proporciona tanto isolamento quanto clareza quanto propriedade.
Catálogos do ciclo de vida dos dados
Catálogos separados para diferentes estágios de maturidade de dados (por exemplo, raw, curated, analytics). Este padrão segue os princípios da arquitetura de medalhão no nível do catálogo.
áreas de teste e desenvolvimento
Muitas equipes precisam de ambientes sandbox para criar conjuntos de dados temporários para uso interno. Forneça a indivíduos ou equipes seus próprios esquemas isolados (sandboxed) onde possam adicionar tabelas, mas não possam compartilhá-los com ninguém fora de sua equipe, já que não são proprietários do esquema e catálogo que os contêm.
Convenções de nomenclatura de catálogos
Escolha uma convenção de nomenclatura para seus catálogos que esteja alinhada com determinadas configurações, por exemplo, por ambiente do ciclo de vida de desenvolvimento software (Dev, Test, Prod), nível de certificação (Bronze, Silver, Ouro) ou unidade de negócios (Faturamento, Cliente, Vendas). As convenções de nomenclatura exatas devem ser definidas pela sua equipe de arquitetura.
Melhores práticas para design de catálogos
- Utilize catálogos baseados em ambiente como default para a maioria das organizações.
- Utilize catálogos baseados em domínio para malhas de dados ou modelos de governança federada.
- Limite o número de catálogos para reduzir a sobrecarga administrativa (normalmente de 3 a 10 por metastore).
- Utilize convenções de nomenclatura consistentes em todos os catálogos.
- Finalidades do catálogo de documentos e propriedade dos dados nos comentários do catálogo.
- Utilize concessões de catálogo para controlar quem pode criar esquemas e tabelas dentro de cada catálogo.
- Evite criar catálogos separados para equipes ou projetos individuais (use esquemas em vez disso).
Estratégia de armazenamento de credenciais de design
As credenciais de armazenamento são objetos de autenticação que permitem ao Unity Catalog acessar o armazenamento cloud em nome dos usuários. Eles fornecem uma maneira segura de conceder Databricks acesso ao armazenamento cloud gerencial do cliente sem compartilhar credenciais de longo prazo com os usuários finais.
Quando as credenciais de armazenamento são necessárias
- Criar locais externos que apontem para armazenamento cloud (por exemplo, S3, ADLS Gen2, GCS).
- Acessando o armazenamento de dados do cliente para tabelas e volumes externos.
- Leitura de dados de armazenamento cloud que não são gerenciados pelo Unity Catalog.
Quando as credenciais de armazenamento não são necessárias
- Acessando Unity Catalog gerencia tabelas e volumes (armazenamento gerenciado pelo Databricks).
- Utilizando o armazenamento default em um espaço de trabalho serverless .
Arquitetura de credenciais de armazenamento da AWS
As credenciais de armazenamento AWS usam uma função IAM entreaccount com políticas de confiança que permitem que Databricks assuma a função. A IAM role deve ter políticas que concedam permissões S3 (por exemplo, s3:GetObject, s3:PutObject, s3:ListBucket) a buckets ou prefixos S3 específicos.
O fluxo de autenticação:
- Unity Catalog assume a IAM role usando a relação de confiança.
- A AWS valida a política de confiança e retorna credenciais temporárias.
- O Unity Catalog usa credenciais temporárias para acessar o S3 em nome do usuário.
- O acesso é concedido ou negado com base nas políticas de IAM associadas à função.
Padrões de design de credenciais de armazenamento
- Use funções IAM separadas para diferentes buckets de armazenamento ou domínios de dados (por exemplo,
uc-prod-sales-role,uc-dev-engineering-role). - Aplicar permissões de privilégio mínimo (conceder acesso apenas a prefixos S3 específicos).
- Crie uma credencial de armazenamento por ambiente (por exemplo, desenvolvimento, teste, produção).
- Crie uma credencial de armazenamento por unidade de negócios quando a segregação de dados for necessária.
Melhores práticas para credenciais de armazenamento da AWS
- Utilize funções IAM separadas para diferentes buckets de armazenamento ou domínios de dados.
- Aplicar permissões de privilégio mínimo (conceder acesso apenas a prefixos S3 específicos).
- Habilite o AWS CloudTrail para auditar o acesso aos buckets do S3.
- Utilize políticas de bucket como uma camada adicional de segurança.
Desenhar uma estratégia de localização externa
Os locais externos mapeiam as credenciais de armazenamento para caminhos específicos de armazenamento cloud , permitindo que Unity Catalog controle o acesso aos dados armazenados fora do armazenamento do Unity Catalog . Cada localização externa combina uma credencial de armazenamento com um prefixo de URL de armazenamento cloud .
casos de uso de localização externa
- Acesso a dados existentes em armazenamento cloud que são anteriores à adoção Unity Catalog .
- Criação de tabelas externas que fazem referência a arquivos de dados gerenciados por outros sistemas.
- Compartilhar dados com sistemas externos que exigem acesso direto aos arquivos.
- Armazenar grandes volumes de dados não estruturados (por exemplo, vídeos, imagens, PDFs) em volumes do Unity Catalog.
Padrões de design de localização externa
- Crie locais externos no prefixo de caminho comum mais alto para minimizar o número de locais.
- Utilize locais externos que estejam alinhados com os limites do catálogo ou do esquema (por exemplo, um local externo por catálogo).
- Separe os locais externos por ambiente (por exemplo, desenvolvimento, teste, produção).
- Separe as localizações externas por unidade de negócio ou domínio de dados, quando necessário.
Melhores práticas para locais externos
- Utilize locais externos para dados que precisam permanecer em caminhos específicos de armazenamento cloud .
- Use tabelas de gerenciamento Unity Catalog em vez de locais externos sempre que possível (governança e otimização mais simples).
- Use nomes descritivos que indiquem o caminho de armazenamento e a finalidade (por exemplo,
s3-sales-data-prod,adls-finance-reports-dev). - Conceda acesso a locais externos somente aos usuários que precisam criar tabelas externas.
- Documentar as finalidades da localização externa e a propriedade dos dados.
Modelo de permissão de design
Cada organização tem requisitos diferentes para o controle de acesso a dados. Um modelo de permissões comum envolve a definição de funções claras com privilégios específicos.
Exemplo de modelo de permissão
- Curadores de dados : gerenciam todos os dados ativos (por exemplo, propriedade, permissões de criação, modificação e exclusão).
- Consumidores de dados : Acesso somente leitura à maioria dos dados ativos (privilégios selecionados).
- Engenheiro de dados : Acesso de leitura e gravação aos ambientes de desenvolvimento e teste.
- analista : Acesso somente leitura aos dados analíticos de produção.
Delegação de permissão
O administrador do metastore estabelece e aplica políticas de permissão, atribuindo e delegando direitos de acesso a usuários ou grupos com base em suas responsabilidades. Por exemplo:
- Os curadores de dados podem receber a propriedade ou privilégios de escrita para gerenciar o conjunto de dados.
- Os consumidores recebem permissões de nível de leitura por meio da participação em grupos.
- Essa estrutura garante uma governança consistente, simplifica a manutenção e apoia compliance com as políticas de dados da organização.
Melhores práticas para modelos de permissão
- Conceda privilégios a grupos em vez de usuários individuais para facilitar o gerenciamento.
- Utilize o princípio do menor privilégio (conceda apenas as permissões mínimas necessárias).
- Documente as políticas de controle de acesso e revise-as regularmente com as equipes de segurança.
- Utilize concessões de catálogo e esquema para controle de acesso de granularidade grossa.
- Utilize concessões de tabela e view para um controle de acesso refinado.
- Utilize a visualização dinâmica e filtros de linha/coluna para dados sensíveis.
- Acesso de auditoria usando tabelas do sistema (
system.access.audit).
Padrão de design em forma de cubo e raios
O padrão de design hub-and-spoke é uma arquitetura comum para implantações do Unity Catalog em empresas. Esse padrão centraliza os dados compartilhados em um catálogo central, ao mesmo tempo que permite que os dados específicos de cada domínio sejam armazenados em catálogos periféricos.
Características de hub-and-spoke
- Catálogo central : Contém dados compartilhados e ativos de toda a organização (por exemplo, dados cadastrais de clientes, dados de referência, conjunto de dados centralizado).
- Catálogos de nicho : Contêm dados específicos de domínio, pertencentes e gerenciados por unidades de negócios (por exemplo, análises de vendas, campanhas marketing ).
- Separação de armazenamento : os catálogos de hub e de domínio usam armazenamento dedicado com credenciais de armazenamento separadas.
- Preferência de tabelas : Para dados estruturados no lakehouse, use tabelas.
- Volumes para dados brutos : Utilize volumes para acessar dados de destino, brutos ou não estruturados (que podem estar localizados fora do lakehouse , pois terceiros geralmente exigem acesso direto a esses locais de armazenamento).
- Tabelas Externas para Compartilhamento: Use tabelas externas para compartilhar dados fora do lakehouse (para outros sistemas que não conseguem usar o OpenSharing ou que precisam de acesso direto ao local de armazenamento).
Exemplo de design em estrela (hub-and-spoke)
Metastore (region: us-east-1)
├── Hub Catalog (prod_hub)
│ ├── Storage credential: hub-prod-credential
│ ├── External location: s3://company-hub-prod/
│ └── Schemas: customers, products, reference_data
│
├── Sales Domain Catalog (sales_prod)
│ ├── Storage credential: sales-prod-credential
│ ├── External location: s3://company-sales-prod/
│ └── Schemas: transactions, forecasts, reports
│
└── Engineering Domain Catalog (engineering_prod)
├── Storage credential: engineering-prod-credential
├── External location: s3://company-engineering-prod/
└── Schemas: telemetry, monitoring, logs
Melhores práticas para o design de hub e spoke
- Utilize o catálogo central para dados compartilhados em toda a organização, que são consumidos por vários domínios.
- Utilize catálogos de dados específicos de domínio pertencentes a unidades de negócios.
- Separe as credenciais de armazenamento e os locais externos para o hub e para cada spoke.
- Use o OpenSharing gerenciado pelo Databricks para compartilhar dados do hub para os spokes.
- Documentar a propriedade e a linhagem dos dados para catálogos em modelo hub and spoke.
- Nota: O armazenamento do metastore agora é opcional e não é recomendado o seu uso.
Recomendações de arquitetura do Unity Catalog
Recomendado
- Segregar ambientes SDLC no metastore Unity Catalog no nível de catálogo do namespace de 3 níveis.
- Utilize os níveis de isolamento do Unity Catalog para segregar cargas de trabalho, equipes e unidades de negócios.
- Use o OpenSharing gerenciado pela Databricks para compartilhar tabelas em nuvens e regiões.
- Para configurações entre regiões, avalie a frequência e o volume de acesso a dados em diferentes regiões cloud . Se o custo ficar muito alto, considere configurar um pipeline para sincronizar as tabelas entre regiões.
- Use tabelas Unity Catalog e não forneça acesso em nível de armazenamento aos buckets.
- Utilize volumes para caminhos de arquivo no estilo POSIX (Portable Operating System Interface) protegidos pelo Unity Catalog.
- Evite, sempre que possível, padrões legados de acesso a dados, como a montagem de armazenamento cloud e perfis de instância.
- Avalie se a chave de criptografia gerenciada pelo cliente (tanto para o serviço gerenciado quanto para o armazenamento) é necessária para aumentar o controle sobre os dados em repouso.
Evitar
- Não utilize modos de acesso diferentes de padrão ou dedicado para espaços de trabalho com o Catálogo Unity habilitado.
- Não armazene dados de produção no DBFS (Databricks File System).
- Não registre tabelas externas entre regiões (metastores).
- Não utilize o bucket raiz (DBFS) para armazenamento de dados do cliente. Certifique-se de compreender os riscos e as soluções alternativas para o bucket raiz.
Resultados da Fase 3
Após concluir a Fase 3, você deverá ter:
- Modelo de governança selecionado com base na estrutura organizacional (centralizada, descentralizada, federada ou híbrida).
- Arquitetura de metastore projetada (normalmente uma por região).
- Arquitetura de armazenamento Unity Catalog projetada (objetos de gerenciamento vs externos vs objetos estrangeiros).
- Estrutura do catálogo definida usando padrões baseados em ambiente, em domínio ou híbridos.
- Estratégia de credenciais de armazenamento projetada com credenciais separadas para diferentes ambientes ou domínios.
- Estratégia de localização externa projetada para armazenamento cloud existente que requer governança Unity Catalog .
- Modelo de permissões concebido com funções claras (por exemplo, curadores, consumidores, engenheiros, analistas).
- O modelo de arquitetura em estrela (hub-and-spoke) foi avaliado para implantações corporativas com dados compartilhados e específicos de domínio.
Próxima fase : Fase 4: Projetar a arquitetura de rede
Orientações de implementação : Para obter instruções passo a passo sobre como implementar seu design do Unity Catalog, consulte O que é o Unity Catalog?.