tabelas de transmissão
Uma tabela Delta é uma tabela Delta com suporte adicional para processamento de dados incrementais ou de transmissão. Uma tabela de transmissão pode ser alvo de um ou mais fluxos em um pipeline.
tabelas de transmissão são uma boa opção para aquisição de dados pelos seguintes motivos:
- Cada linha de entrada é manipulada apenas uma vez, o que modela a grande maioria das cargas de trabalho de ingestão (ou seja, anexando ou inserindo linhas em uma tabela).
- Eles podem lidar com grandes volumes de dados somente de acréscimo.
As tabelas de transmissão também são uma boa opção para transformações de transmissão de baixa latência, pois podem raciocinar sobre linhas e janelas de tempo, lidar com grandes volumes de dados e fornecer processamento de baixa latência.
O diagrama a seguir mostra como os fluxos leem de fontes de transmissão e gravam incrementalmente em uma tabela de transmissão dentro de um pipeline.
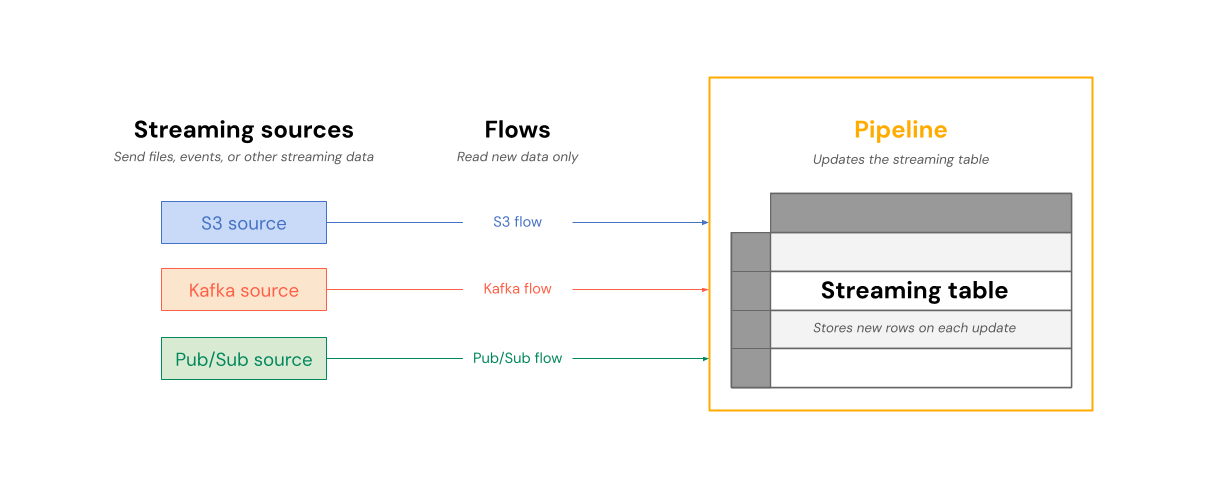
Em cada atualização, os fluxos associados a uma tabela de transmissão leem a informação alterada numa fonte de transmissão e acrescentam nova informação a essa tabela.
As tabelas de transmissão são de propriedade e atualizadas por um único pipeline. Você define explicitamente as tabelas de transmissão no código-fonte do pipeline. As tabelas definidas por um pipeline não podem ser alteradas ou atualizadas por nenhum outro pipeline. Você pode definir vários fluxos para adicionar a uma única tabela de transmissão.
Databricks cria tabelas internas para dar suporte ao processamento de tabelas de transmissão. Essas tabelas aparecem em system.information_schema.tables mas não são visíveis no Explorador de Catálogo ou em outras páginas da interface do usuário workspace .
Ao criar uma tabela de transmissão fora de um pipeline usando Databricks SQL, Databricks cria um pipeline que é usado para atualizar a tabela. Você pode visualizar o pipeline selecionando "Tarefas e pipeline" na navegação à esquerda do seu workspace. Você pode adicionar a coluna do tipo de pipeline à sua view. As tabelas de transmissão definidas em um pipeline têm um tipo de ETL. As tabelas de transmissão criadas no Databricks SQL têm um tipo de MV/ST.
Para obter mais informações sobre fluxos, consulte Carregar e processar dados incrementalmente com fluxos de pipeline declarativos LakeFlow Spark.
tabelas de transmissão para ingestão
As tabelas de transmissão são projetadas para fontes de dados somente de acréscimo e processam as entradas apenas uma vez. Isso os torna ideais para cargas de trabalho de ingestão em que os dados chegam continuamente e devem ser capturados de forma confiável, sem reprocessar os registros existentes. Databricks suporta a ingestão de dados de armazenamento cloud e barramentos de mensagens de transmissão.
Ingerir arquivos do armazenamento cloud
Você pode usar uma tabela de transmissão para ingerir novos arquivos do armazenamento cloud . Esses exemplos usam o Auto Loader para processar novos arquivos incrementalmente à medida que chegam.
- Python
- SQL
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Para criar uma tabela de transmissão, a definição do conjunto de dados deve ser do tipo transmissão. Quando você usa a função spark.readStream em uma definição de conjunto de dados, ela retorna um dataset de transmissão.
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
tabelas de transmissão requerem conjunto de dados de transmissão. A palavra-chave STREAM antes de read_files indica à consulta que o conjunto de dados deve ser tratado como uma transmissão.
Ingerir mensagens
Você também pode usar tabelas de transmissão para ingerir dados de barramentos de mensagens. O exemplo a seguir demonstra como criar uma tabela de transmissão que lê de um tópico do Pub/Sub.
- Python
- SQL
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
A Databricks recomenda o uso de segredos ao fornecer opções de autorização. Consulte Configurar o acesso ao Pub/Sub para obter todas as opções de autenticação.
Para obter mais detalhes sobre como carregar dados na tabela de transmissão, consulte Carregar dados no pipeline.
O diagrama a seguir ilustra como funcionam as tabelas de transmissão somente de acréscimo.
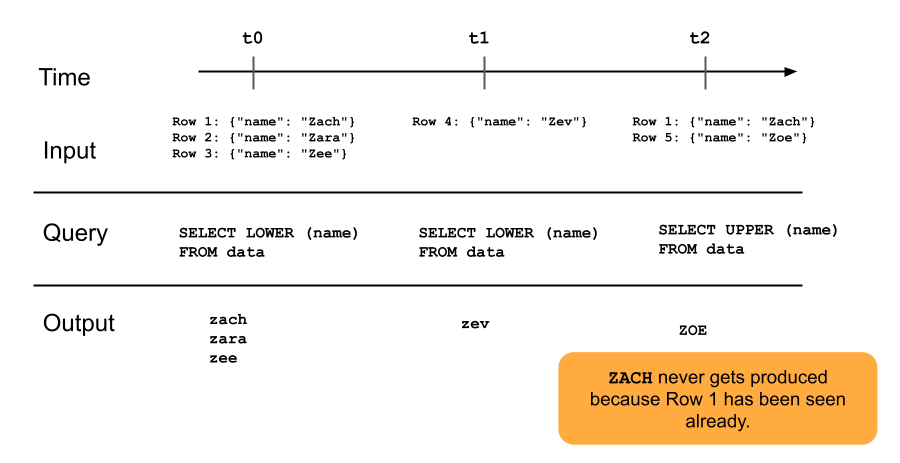
Uma linha que já foi adicionada a uma tabela de transmissão não será consultada novamente em atualizações posteriores do pipeline. Se você modificar a consulta (por exemplo, de SELECT LOWER (name) para SELECT UPPER (name)), as linhas existentes não serão atualizadas para maiúsculas, mas as novas linhas serão. Você pode acionar uma refresh completa para buscar novamente todos os dados anteriores da tabela de origem e atualizar todas as linhas da tabela de transmissão.
tabelas de transmissão e transmissão de baixa latência
tabelas de transmissão são projetadas para transmissão de baixa latência em estado limitado. As tabelas de transmissão usam gerenciamento de ponto de verificação, o que as torna adequadas para transmissão de baixa latência. No entanto, eles esperam transmissões que sejam naturalmente delimitadas ou delimitadas com uma marca d'água.
Uma transmissão naturalmente delimitada é produzida por uma fonte de dados que tem início e fim bem definidos. Um exemplo de transmissão naturalmente limitada é a leitura de dados de um diretório de arquivos onde nenhum arquivo novo é adicionado após a inserção de um lote inicial de arquivos. A transmissão é considerada limitada porque o número de arquivos é finito e a transmissão termina depois que todos os arquivos forem processados.
Você também pode usar uma marca d'água para delimitar uma transmissão. Uma marca d'água em transmissão estruturada é um mecanismo que ajuda a lidar com dados atrasados, especificando quanto tempo o sistema deve esperar por eventos atrasados antes de considerar a janela de tempo como completa. Uma transmissão ilimitada e sem marca d'água pode causar falha no pipeline devido à pressão na memória.
Para obter mais informações sobre o processamento de transmissões com estado, consulte Otimizar o processamento com estado usando marcas d'água.
transmissão-Junção instantânea
transmissão-Snapshot join conecta um dataset de transmissão a uma tabela de dimensões que é capturada no início da transmissão. Como a tabela de dimensões é tratada como fixa naquele momento, quaisquer alterações feitas nela após o início da transmissão não são refletidas na join. Isso é aceitável quando pequenas discrepâncias não importam — por exemplo, quando o número de transações é muitas ordens de grandeza maior do que o número de clientes.
O exemplo de código a seguir une uma tabela de dimensão com duas linhas chamadas customers com um conjunto de dados sempre crescente, transactions. Ele materializa uma join entre esses dois conjuntos de dados em uma tabela chamada sales_report. Se um processo externo atualizar a tabela de clientes adicionando uma nova linha (customer_id=3, name=Zoya), esta nova linha não estará presente na join porque a tabela de dimensão estática foi capturada quando as transmissões foram iniciadas.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
limitações da tabela de transmissão
As tabelas de transmissão têm as seguintes limitações:
- Evolução limitada: você pode alterar a consulta sem recalcular todo o conjunto de dados. Sem uma refresh completa, uma tabela de transmissão vê cada linha apenas uma vez, portanto, consultas diferentes processarão linhas diferentes. Por exemplo, se você adicionar
UPPER()a um campo na consulta, somente as linhas processadas após a alteração estarão em maiúsculas. Isso significa que você precisa estar ciente de todas as versões anteriores da consulta que estão sendo executadas em seu conjunto de dados. Para reprocessar linhas existentes que foram processadas antes da alteração, é necessário realizar uma refresh completa. - Gerenciamento de estado: as tabelas de transmissão têm baixa latência e exigem transmissões que sejam naturalmente limitadas ou limitadas com uma marca d'água. Para obter mais informações, consulte Otimizar o processamento com estado usando marcas d'água.
- A junção não recalcula: as junções em tabelas de transação não são recalculadas quando as dimensões mudam. Essa característica pode ser útil em cenários de "ação rápida, porém incorreta". Se você deseja que sua view esteja sempre correta, talvez queira usar uma view materializada. As visões materializadas estão sempre corretas porque recalculam automaticamente a junção quando as dimensões mudam. Para obter mais informações, consulte Visualização materializada.
- **Sem
CLONEsuporte para:** As tabelas de transmissão não podem ser usadas como origem ou destino de um clone profundo ou raso. Para outros comandos não compatíveis, consulte Limitações.