Teste de unidade para pipelines
Beta
Esse recurso está em Beta.
Para obter informações gerais sobre testes de unidade Python no Databricks, consulte Teste de unidade Python.
LakeFlow Pipelines oferecem suporte à escrita de testes de unidade Python no Editor de Pipelines do LakeFlow baseado na web. Isso permite que você valide a lógica de transformação Python ou SQL usando dados simulados. Com a estrutura de teste de pipeline, você pode testar casos extremos, validar APIs proprietárias de pipeline (Auto CDC, tabelas de transmissão, expectativas, fluxos de acréscimo) e iterar usando entradas simuladas para operações de identificador de tabela compatíveis. Revise as limitações de isolamento antes de executar testes.
- Execução de teste isolada: O framework fornece uma SparkSession que redireciona operações de tabela para um esquema de teste temporário no catálogo default do pipeline, para que você possa simular dados de entrada e gravar saídas de teste sem afetar as tabelas de produção. O isolamento se aplica a operações que fazem referência a uma tabela pelo nome; consulte Limitações.
- **Escopo de teste flexível**: Execute um subconjunto de um pipeline (tabelas individuais, cadeias de tabelas dependentes ou pipelines inteiros) no compute do pipeline usando o SparkSession de teste.
- Validação de resultados : verifique os resultados de tabelas de saída isoladas criadas em um teste com asserções pytest padrão.
Quando usar o teste de unidade
Casos de uso típicos incluem:
- Validação de nova lógica de transformação : Teste se sua transformação produz o esquema esperado, as contagens de linha, as agregações e a lógica de negócios antes de executar em dados de produção.
- Testando as especificações do Auto CDC : valide se as definições do seu fluxo de Auto CDC processam corretamente os eventos de alteração, lidando com inserções, atualizações, exclusões e tipos de SCD (dimensões que mudam lentamente), usando dados simulados.
- Teste de expectativas e regras de qualidade dos dados : verifique se as expectativas falham quando deveriam e são aprovadas quando os dados são válidos.
- Testes entre tabelas dependentes : Testar cadeias de transformações (por exemplo, Bronze, Silver e ouro) para validar que os dados fluem corretamente através do seu gráfico de pipeline.
Requisitos
-
Permissão de
Ownerpipeline , mais os privilégiosUSE CATALOGeCREATE SCHEMAno catálogo default do pipeline. O framework precisa desses privilégios para criar o esquema de teste temporário onde os testes são executados.Para verificar ou definir a permissão do pipeline, abra o pipeline e clique em Compartilhar . Você deve ser o pipeline
Owner(IS OWNER);CAN RUNeCAN MANAGEnão são suficientes para executar testes. Consulte Configurar permissões de pipeline.Para verificar ou definir os privilégios do catálogo, abra o catálogo no Catalog Explorer, selecione a tab Permissões e confirme se você tem
USE CATALOGeCREATE SCHEMA. Um proprietário de catálogo, um administrador de metastore ou um usuário com o privilégioMANAGEpode concedê-los, inclusive com SQL:SQLGRANT USE CATALOG, CREATE SCHEMA ON CATALOG <catalog_name> TO `<principal>`;Para obter mais informações, consulte referência de privilégios do Unity Catalog.
-
O pipeline deve ser configurado no modo acionado (não contínuo).
-
O pipeline deve estar no canal de **Pré-visualização**. Teste de unidade está em Beta e está disponível apenas em prévia.
-
Spark Connect não é suportado.
Escreva código de teste que permaneça isolado
O isolamento de teste cobre operações de tabela que fazem referência a uma tabela **pelo nome**. As operações que ignoram o isolamento podem ocorrer tanto no seu código de teste quanto em qualquer código de pipeline executado pelas saídas que você selecionar, incluindo suas dependências transitivas. Um arquivo de teste que parece seguro ainda pode executar um fluxo de pipeline que lê ou grava por caminho ou conector, o que age sobre os dados de produção. Para evitar que os testes afetem os dados ou metadados de produção, siga estas regras:
- Faça referência a cada tabela pelo nome (
catalog.schema.table) e simule todas as entradas pelo nome. Não leia nem escreva por caminho (/Volumes/...,dbfs:/...,s3://...,abfss://...) e não leia de conectores como Kafka ou Auto Loader. Eles ignoram o isolamento e agem em sistemas de produção reais. - Não execute declarações de governança ou propriedade, como
GRANT,REVOKE,ALTER ... OWNER TO,SET/UNSET TAGS, ouCREATE/DROP POLICY. Eles são executados no objeto securável de produção real. - Não crie catálogos ou esquemas (
CREATE CATALOG,CREATE SCHEMA). Estes chegam ao seu metastore do Unity Catalog real. - Não execute o pipeline inteiro se o seu gráfico incluir entradas baseadas em caminho, conectores, gravações imperativas ou outros efeitos colaterais externos. Selecione apenas as saídas cujas dependências usam operações de tabela de catálogo compatíveis e que foram substituídas por entradas simuladas.
Consulte Limitações para detalhes.
Limitações
Algumas operações ignoram o isolamento de teste e podem atuar em dados ou metadados de produção reais. Revise as seguintes limitações antes de executar testes.
O isolamento de teste é apenas por nome da tabela
-
Não leia nem escreva por caminho ou conector. O isolamento redireciona apenas as operações que referenciam uma tabela por nome (por exemplo,
spark.read.table("catalog.schema.table")oudf.write.saveAsTable("catalog.schema.table")). As operações endereçadas por um caminho ou por meio de um conector ignoram o isolamento e agem diretamente em sistemas de produção reais:- Gravação por caminho (por exemplo,,
df.write.save("/Volumes/...")umdbfs:/caminho, ou um caminho de cloud ou localização externa, comos3://...abfss://...ou) grava no armazenamento de produção real e pode sobrescrever dados de produção. - Leitura por caminho (por exemplo,
spark.read.load(path)ouspark.read.format("delta").load(path)) retorna dados de produção reais em vez do seu simulado. - **A leitura de um conector** conecta-se à fonte de produção real. Isso inclui Kafka (lê dos brokers reais) e Auto Loader (
cloudFiles, que lê do caminho de armazenamento em nuvem real). Nenhum é redirecionado para seus dados simulados.
- Gravação por caminho (por exemplo,,
-
**Não use a
event_log()função com valor de tabela de um teste de unidade de pipeline.** No modo de teste,event_log()não é redirecionado para o log de eventos da sua execução de teste. Ele pode retornar o log de eventos de produção ou registrado anteriormente, portanto, as asserções contra ele podem ler dados de produção. Em vez disso, use oevent_log_table_nameretornado pela execução e consulte-o por meio detest_spark.event_log_table_namepode serNone(por exemplo, se o nome da tabela do log de eventos não puder ser resolvido), então verifique-o antes de consultar:Pythonstatus = test_pipeline.run(test_spark, set(["catalog.schema.table"]))
assert status.event_log_table_name is not None
events = test_spark.table(status.event_log_table_name)Não declare
status.is_successantes de ler o log de eventos se o objetivo for diagnosticar uma atualização com falha. O log de eventos geralmente é o que se inspeciona para entender por que uma atualização falhou.
Governança e operações DDL
- Mutações de catálogo, esquema, permissão, propriedade, tag e política não são suportadas. Isso inclui
CREATE/DROP/ALTER CATALOG,CREATE/DROP/ALTER SCHEMA(incluindoSET MANAGED LOCATION),GRANT/REVOKE,ALTER ... OWNER TO,SET/UNSET TAGSeCREATE/DROP POLICY. Algumas formas SQL executadas por meio detest_sparksão rejeitadas como defesa em profundidade; outras formas, ou as mesmas operações invocadas por meio de APIs diretas, podem alcançar objetos de produção reais. Não dependa dessas salvaguardas como um limite de isolamento. Mantenha essas instruções fora do seu código de teste e de qualquer código de pipeline executado pelas saídas selecionadas.
Limitações Operacionais
- A execução concorrente não é suportada : Executar um teste e uma pipeline update ao mesmo tempo não é suportado, e o sistema não a impede. Não há coordenação entre os dois, então executá-los concorrentemente pode disputar recursos, degradando severamente o desempenho da sua atualização de produção ou fazendo com que o teste falhe ao começar. Não começar um teste enquanto o pipeline estiver executando uma atualização (ou começar uma atualização enquanto um teste estiver em execução); aguarde a conclusão de qualquer atualização em andamento antes de executar os testes.
- Esquemas temporários após término anormal: Cada execução de teste cria um esquema temporário
redirecting_<id>(nomeado) no catálogo default do pipeline e o descarta automaticamente quando a execução termina. Se uma execução terminar de forma anormal (por exemplo, o compute for perdido no meio da execução), o esquema temporário poderá ser deixado para trás, mantendo as tabelas simuladas e de saída da execução. Não afeta dados de produção. Para recuperar armazenamento, descarte manualmente quaisquer esquemas restantes cujos nomes comecem comredirecting_no catálogo default do pipeline. - **Execuções de teste consomem compute**: As execuções de teste são executadas no compute do pipeline e são cobradas como atualizações normais de pipeline. Não há medição separada para execuções de teste.
- Refresh completo não é suportado : Somente o refresh seletivo está disponível.
test_pipeline.run()atualiza os resultados que você seleciona (ou todos os resultados quando você não passa nenhuma seleção); o full refresh e a seleção de full refresh não são implementados.
Limitações de autoria e fidelidade
- Execução exclusiva do Editor : Testes devem ser executados a partir do Editor de Lakeflow Pipelines baseado na web.
- Somente testes em Python : os testes devem ser escritos em Python. Você pode testar pipelines SQL, mas os próprios testes devem ser escritos em Python.
- Fidelidade da governança : Os dados simulados não herdam os filtros de linha ou as máscaras de coluna definidos nas tabelas de produção que substituem. Os resultados do teste refletem as entradas simuladas exatamente como são fornecidas e podem diferir de como a mesma query se comporta em dados de produção governados.
O passo 1: Atualizar as configurações do pipeline
Configure o pipeline para ser executado no canal **PRÉ-VISUALIZAÇÃO** no modo triggered.
- Na interface do usuário, abra seu pipeline e clique em Configurações > Configurações Avançadas > Canal > Visualização
- Selecione **Acionado** para **Modo Pipeline** (não utilize Contínuo).
Alternativamente, edite as definições de JSON do pipeline diretamente:
"continuous": false,
"channel": "PREVIEW"
Etapa 2: Criar um arquivo de teste
No Editor de Lakeflow Pipelines, clique no botão **+** (adicionar) e selecione **Testar**. Isso cria um arquivo de teste (e a pasta tests, se ela ainda não existir) que não está incluído no código-fonte do pipeline. Não é necessário criar a pasta tests.
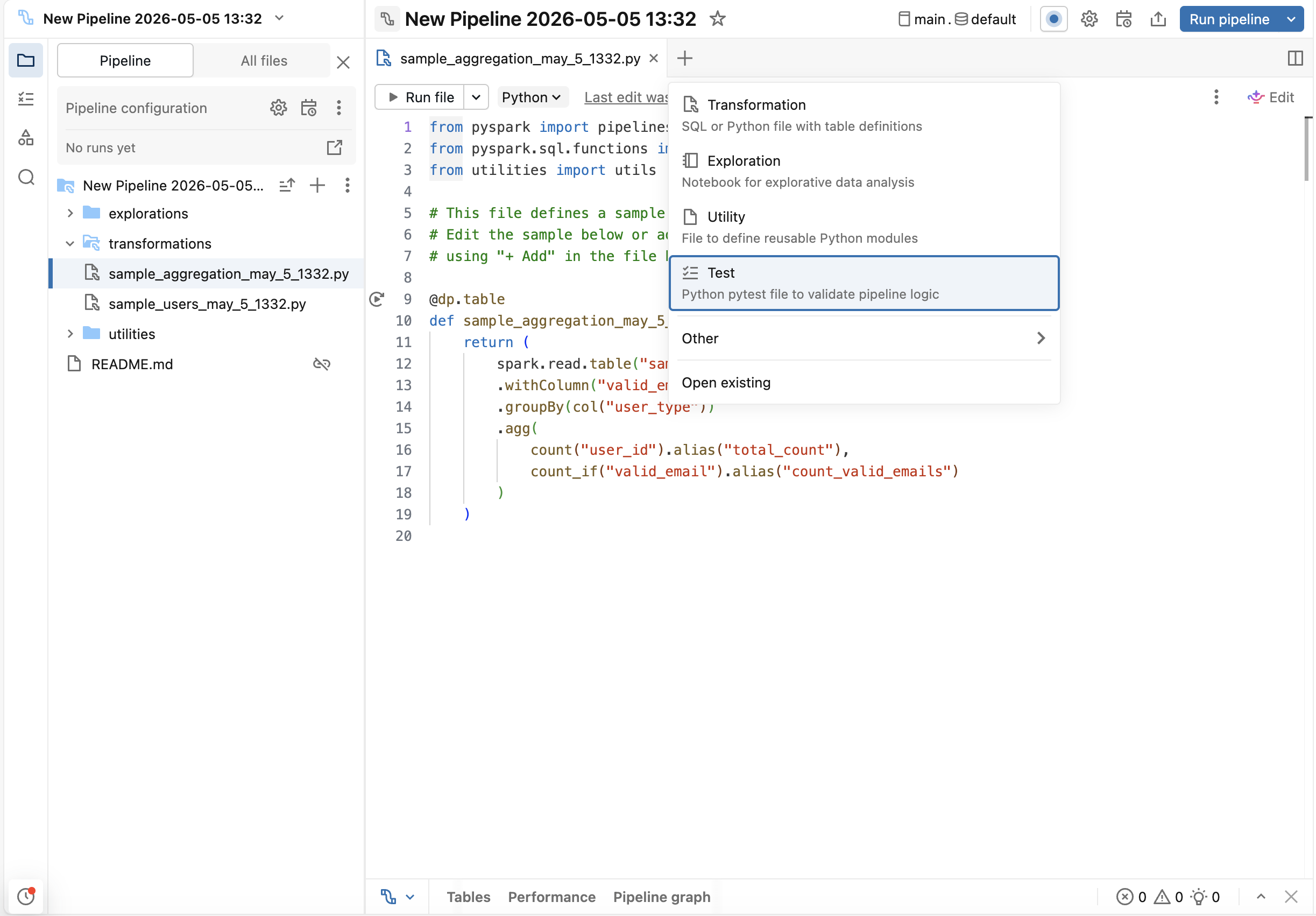
Passo 3: Gerar testes
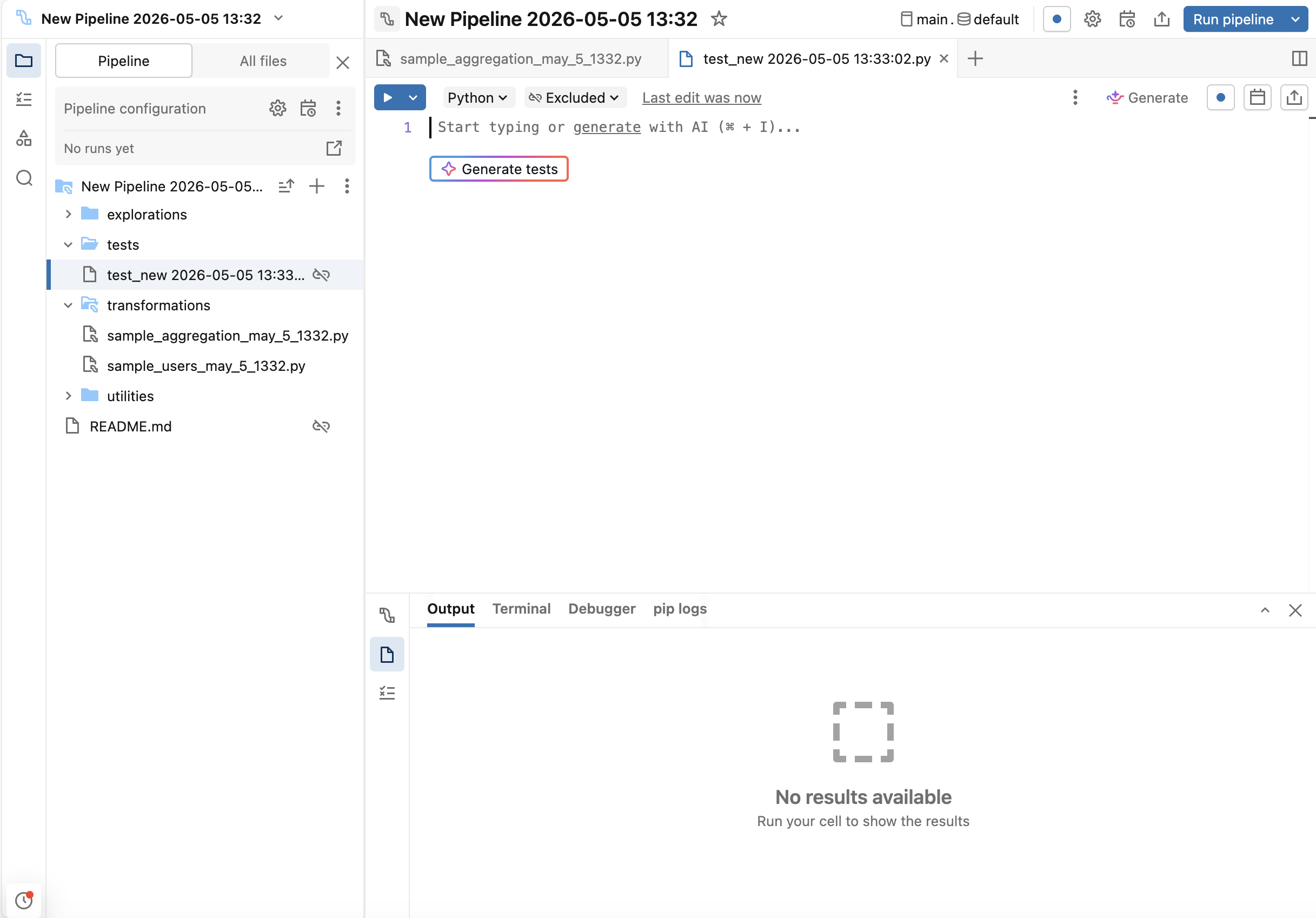
O Genie Code pode gerar um esqueleto de teste:
-
Dentro do arquivo de teste, clique no botão Gerar testes .
-
Alternativamente, utilize
/testsno modo de agente do Genie Code.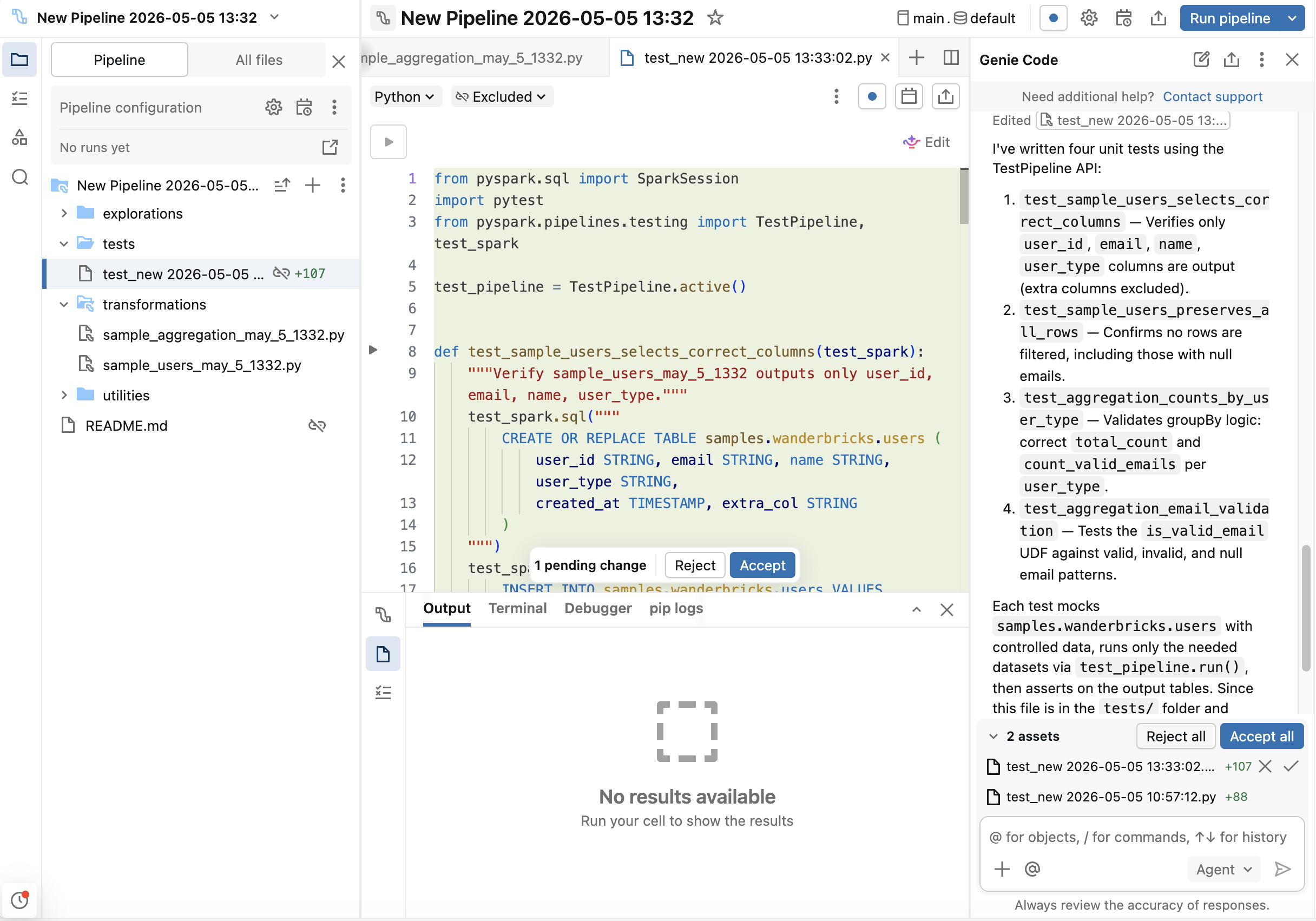
Utilize o Genie Code para gerar código padrão e, em seguida, personalize para os casos de borda.
Alternativamente, pode-se escrever o código de teste. Adicione as seguintes importações na parte superior de cada arquivo de teste:
import pytest
from pyspark.pipelines.testing import TestPipeline, test_spark
test_pipeline = TestPipeline.active()
Passo 4: executar testes
Executar testes no Editor de Lakeflow Pipelines:
- Clique no botão
 (play) na medianiz ao lado de uma função de teste para executar um teste individual.
(play) na medianiz ao lado de uma função de teste para executar um teste individual. - Clique em Executar testes no arquivo na parte superior do arquivo de teste para executar todos os testes naquele arquivo.
Os resultados dos testes (sucesso ou falha) são exibidos no painel inferior do Editor. Analise erros de asserção para depurar falhas.
Testar APIs
API | Descrição |
|---|---|
| Retorna um objeto |
| Executa sincronicamente uma atualização do pipeline, realizando um refresh seletivo caso nomes de tabelas sejam especificados. Retorna após a execução do pipeline ser bem-sucedida ou ser encerrada com uma exceção. |
| Cria uma SparkSession de teste com redirecionamento de catálogo-tabela que redireciona automaticamente leituras e gravações de tabela que referenciam uma tabela pelo nome (por exemplo, |
Criar dados simulados
Você pode simular dados de entrada usando SQL ou createDataFrame:
# Option 1: Using SQL
test_spark.sql("""
CREATE TABLE catalog.schema.table_name AS
SELECT * FROM VALUES
(1, 'value1'),
(2, 'value2')
AS t(id, name)
""")
# Option 2: Using createDataFrame
df = test_spark.createDataFrame(
[(1, 'value1'), (2, 'value2')],
schema=["id", "name"]
)
df.write.saveAsTable("catalog.schema.table_name")
Para gerar volumes maiores de dados sintéticos realistas, é possível usar a biblioteca Faker. Execute %pip install faker primeiro em seu pipeline e, depois, crie um DataFrame a partir de UDFs Faker-backed.
# Option 3: Using Faker for synthetic data
from pyspark.sql import functions as F
from faker import Faker
fake = Faker()
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
df = (
test_spark.range(0, 100)
.withColumn("firstname", fake_firstname())
.withColumn("lastname", fake_lastname())
.withColumn("email", fake_email())
)
df.write.saveAsTable("catalog.schema.table_name")
Execute o pipeline ou tabelas específicas
# Run specific tables
test_pipeline.run(test_spark, set(["catalog.schema.table1", "catalog.schema.table2"]))
# Run all tables in the pipeline
test_pipeline.run(test_spark)
Exemplos
Exemplo 1: Teste de Agregações com Contagem de Linhas, Esquema e Tratamento de Nulos
Objetivo: Validar se a agregação de usuários conta corretamente os usuários por tipo, lida com emails nulos e produz o esquema esperado.
Transformações de pipeline:
Essas transformações criam um pipeline simples de duas tabelas: users seleciona dados do usuário, e counts agrupa usuários por tipo e contabiliza o total de usuários e emails válidos.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, count, count_if
@dp.table
def users():
return (
spark.read.table("catalog.schema.wanderbricks_users")
.select("user_id", "email", "name", "user_type")
)
@dp.table
def counts():
return (
spark.read.table("catalog.schema.users")
.withColumn("valid_email", col("email").isNotNull())
.groupBy("user_type")
.agg(
count("user_id").alias("total_count"),
count_if("valid_email").alias("count_valid_emails")
)
)
Testes :
Esses testes validam contagens de linhas, estrutura de esquema, tratamento de nulos e lógica de agregação, criando dados de usuário simulados com nulos intencionais e executando o pipeline isoladamente.
import pytest
from pyspark.pipelines.testing import TestPipeline, test_spark
from pyspark.testing import assertDataFrameEqual
test_pipeline = TestPipeline.active()
# Mock data fixture
def mock_users(session):
session.sql("""
CREATE TABLE catalog.schema.wanderbricks_users AS
SELECT * FROM VALUES
(1, 'alice@example.com', 'Alice', 'admin'),
(2, NULL, 'Bob', 'user'),
(3, 'charlie@example.com', 'Charlie', 'user'),
(4, NULL, 'Dana', 'admin')
AS t(user_id, email, name, user_type)
""")
# Test 1: Row count
def test_users_row_count(test_spark):
mock_users(test_spark)
test_pipeline.run(test_spark, set(["catalog.schema.users"]))
result = test_spark.table("catalog.schema.users")
assert result.count() == 4
# Test 2: Schema validation
def test_users_schema(test_spark):
mock_users(test_spark)
test_pipeline.run(test_spark, set(["catalog.schema.users"]))
result = test_spark.table("catalog.schema.users")
expected_fields = {"user_id", "email", "name", "user_type"}
actual_fields = set(f.name for f in result.schema.fields)
assert expected_fields == actual_fields
# Test 3: Null handling
def test_users_null_handling(test_spark):
mock_users(test_spark)
test_pipeline.run(test_spark, set(["catalog.schema.users"]))
result = test_spark.table("catalog.schema.users")
null_emails = result.filter("email IS NULL").count()
assert null_emails == 2
# Test 4: Aggregation
def test_counts(test_spark):
mock_users(test_spark)
# Run both tables since counts depends on users
test_pipeline.run(test_spark, set(["catalog.schema.users", "catalog.schema.counts"]))
result = test_spark.table("catalog.schema.counts")
# Check counts for each user_type
admin_row = result.filter("user_type = 'admin'").collect()[0]
user_row = result.filter("user_type = 'user'").collect()[0]
assert admin_row["total_count"] == 2
assert admin_row["count_valid_emails"] == 1
assert user_row["total_count"] == 2
assert user_row["count_valid_emails"] == 1
# Test 5: Full DataFrame comparison with assertDataFrameEqual
def test_counts_full_dataframe(test_spark):
mock_users(test_spark)
test_pipeline.run(test_spark, set(["catalog.schema.users", "catalog.schema.counts"]))
result = test_spark.table("catalog.schema.counts")
expected = test_spark.createDataFrame(
[("admin", 2, 1), ("user", 2, 1)],
schema=["user_type", "total_count", "count_valid_emails"]
)
assertDataFrameEqual(result, expected)
Exemplo 2: Teste do Auto CDC
Objetivo: validar que o Auto CDC processa corretamente o feed de alterações com inserções e atualizações.
Transformação de pipeline :
Esta transformação configura o Auto CDC a partir de um feed de alterações, que lê alterações em transmissão e as aplica à tabela de destino como SCD Tipo 1 (mantém apenas a versão mais recente).
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.view
def users():
return spark.readStream.table("catalog.schema.change_feed")
dp.create_streaming_table("target_autocdc")
dp.create_auto_cdc_flow(
target="target_autocdc",
source="users",
keys=["userId"],
sequence_by=col("ts"),
stored_as_scd_type=1
)
Testes :
O primeiro teste cria um feed de alterações simulado com vários registros para o mesmo userId (simulando uma atualização) e verifica se somente o registro mais recente é retido no destino. O segundo teste simula eventos com chegada tardia e fora de ordem, executando o pipeline, anexando mais eventos ao feed de alterações e executando o pipeline novamente.
import pytest
from pyspark.pipelines.testing import TestPipeline, test_spark
test_pipeline = TestPipeline.active()
# Test 1: Standard inserts and updates
def test_auto_cdc_flow(test_spark):
# Create a mock change feed table
test_spark.sql("""
CREATE TABLE catalog.schema.change_feed AS
SELECT * FROM VALUES
(1, 'Alice', 1000),
(2, 'Bob', 1001),
(1, 'Alice Updated', 1002)
AS t(userId, name, ts)
""")
# Run the pipeline
test_pipeline.run(test_spark, set(["catalog.schema.target_autocdc"]))
# Read the output
result = test_spark.table("catalog.schema.target_autocdc")
# Verify two users exist
user_ids = set(row["userId"] for row in result.collect())
assert user_ids == {1, 2}
# Verify latest record for userId=1 has ts=1002
latest_user1 = result.filter("userId = 1").collect()[0]
assert latest_user1["ts"] == 1002
assert latest_user1["name"] == "Alice Updated"
# Verify userId=2 has ts=1001
user2 = result.filter("userId = 2").collect()[0]
assert user2["ts"] == 1001
# Test 2: Late-arriving and out-of-order events
def test_auto_cdc_late_arriving(test_spark):
# First batch of change events
test_spark.sql("""
CREATE TABLE catalog.schema.change_feed AS
SELECT * FROM VALUES
(1, 'Alice', 1000),
(2, 'Bob', 1001)
AS t(userId, name, ts)
""")
# Run the pipeline with the initial batch
test_pipeline.run(test_spark, set(["catalog.schema.target_autocdc"]))
# Append late-arriving events to the change feed:
# - A newer event for userId=1 (ts=1003) that arrived after the first run
# - A stale event for userId=2 (ts=999) with a timestamp older than what is already applied
test_spark.sql("""
INSERT INTO catalog.schema.change_feed VALUES
(1, 'Alice Updated', 1003),
(2, 'Bob (stale)', 999)
""")
# Re-run the pipeline. sequence_by=ts ensures stale events do not overwrite newer state.
test_pipeline.run(test_spark, set(["catalog.schema.target_autocdc"]))
result = test_spark.table("catalog.schema.target_autocdc")
# userId=1 should reflect the newer late-arriving event
alice = result.filter("userId = 1").collect()[0]
assert alice["ts"] == 1003
assert alice["name"] == "Alice Updated"
# userId=2 should be unchanged: the stale event with an older ts is ignored
bob = result.filter("userId = 2").collect()[0]
assert bob["ts"] == 1001
assert bob["name"] == "Bob"
Exemplo 3: Teste de Auto CDC a partir de Snapshot
Objetivo: Validar que a CDC processa corretamente as alterações do Snapshot, incluindo inserções, atualizações e exclusões.
Transformação de pipeline :
Esta transformação configura o Auto CDC de Snapshot, que lê de uma tabela de Snapshot e rastreia as alterações ao longo do tempo como SCD Tipo 2 (mantém história completa).
from pyspark import pipelines as dp
@dp.view(name="source")
def source():
return spark.read.table("catalog.schema.snapshot")
dp.create_streaming_table("catalog.schema.target")
dp.create_auto_cdc_from_snapshot_flow(
target="target",
source="source",
keys=["userId"],
stored_as_scd_type=2
)
Teste :
Este teste cria um Snapshot inicial, executa o pipeline, então simula uma atualização de Snapshot truncando e inserindo novos dados para verificar se o CDC captura todas as alterações.
import pytest
from pyspark.pipelines.testing import TestPipeline, test_spark
test_pipeline = TestPipeline.active()
def test_auto_cdc_from_snapshot_flow(test_spark):
# Create initial snapshot
test_spark.sql("""
CREATE TABLE catalog.schema.snapshot AS
SELECT * FROM VALUES
(1, 'Alice', '2024-01-01'),
(2, 'Bob', '2024-01-02')
AS t(userId, name, created_at)
""")
# Run the pipeline
test_pipeline.run(test_spark, set(["catalog.schema.target"]))
# Simulate a new snapshot by truncating and inserting updated data
test_spark.sql("TRUNCATE TABLE catalog.schema.snapshot")
test_spark.sql("INSERT INTO catalog.schema.snapshot VALUES (2, 'Bob', '2024-01-03')")
test_pipeline.run(test_spark, set(["catalog.schema.target"]))
# Verify SCD Type 2: should have 3 rows (original Alice, original Bob, updated Bob)
result = test_spark.table("catalog.schema.target")
assert result.count() == 3
user_ids = [row["userId"] for row in result.collect()]
assert set(user_ids) == {1, 2}
Exemplo 4: Testando joins e expectativas
Objetivo: Validar que as junções funcionam corretamente e as expectativas filtram dados inválidos.
Transformação de pipeline :
Esta transformação join imagens de propriedades com comodidades e aplica uma expectativa para filtrar imagens com upload feito antes de janeiro de 2024.
from pyspark import pipelines as dp
@dp.table
@dp.expect_or_drop("uploaded after Jan 2024", "uploaded_at > '2024-01-01'")
def property_images_amenities_join():
return (
spark.read.table("catalog.schema.property_images")
.join(
spark.read.table("catalog.schema.property_amenities"),
on="property_id",
how="inner"
)
)
Testes :
Esses testes verificam que a join produz o número correto de linhas e que a expectativa filtra com sucesso os registros com datas de upload inválidas.
import pytest
from pyspark.pipelines.testing import TestPipeline, test_spark
test_pipeline = TestPipeline.active()
# Mock property datasets
def mock_properties(session):
session.sql("""
CREATE TABLE catalog.schema.property_images AS
SELECT * FROM VALUES
(101, 'img1.jpg', '2024-02-01'),
(102, 'img2.jpg', '2024-01-15'),
(103, 'img3.jpg', '2024-12-20')
AS t(property_id, image_url, uploaded_at)
""")
session.sql("""
CREATE TABLE catalog.schema.property_amenities AS
SELECT * FROM VALUES
(101, 'wifi'),
(102, 'pool'),
(103, 'parking')
AS t(property_id, amenity)
""")
# Test 1: Join
def test_property_join(test_spark):
mock_properties(test_spark)
test_pipeline.run(test_spark, set(["catalog.schema.property_images_amenities_join"]))
result = test_spark.table("catalog.schema.property_images_amenities_join")
# Should have 3 rows after join
assert result.count() == 3
# Check all property_ids are present
property_ids = set(row["property_id"] for row in result.collect())
assert property_ids == {101, 102, 103}
# Test 2: Expectation
def test_property_expectation(test_spark):
mock_properties(test_spark)
# Add a row with uploaded_at before Jan 2024
test_spark.sql("""
INSERT INTO catalog.schema.property_images VALUES (104, 'img4.jpg', '2023-12-31')
""")
# Add a matching row in the amenities table for the join
test_spark.sql("""
INSERT INTO catalog.schema.property_amenities VALUES (104, 'gym')
""")
test_pipeline.run(test_spark, set(["catalog.schema.property_images_amenities_join"]))
result = test_spark.table("catalog.schema.property_images_amenities_join")
# Only property_ids with uploaded_at > '2024-01-01' should be present
valid_ids = set(row["property_id"] for row in result.collect())
assert 104 not in valid_ids
assert valid_ids == {101, 102, 103}