Acompanhar execuções com MLflow e a página de execução de Trabalhos
Visualização
Este recurso está em Pré-visualização Pública.
Cada carga de trabalho que você submete com air run é tanto uma execução de job do Databricks quanto uma execução do MLflow:
- A execução de job (visível na página **Jobs e pipelines** da workspace) acompanha a execução: status, compute, novas tentativas e saída do driver.
- A execução do MLflow rastreia o experimento: parâmetros, métricas, métricas do sistema e artefatos.
Uma submissão cria uma execução de Job e uma execução do MLflow. Uma nova tentativa cria uma nova execução do MLflow.
Experimentos e execuções
Dois campos YAML de carga de trabalho controlam como a execução aparece no MLflow:
experiment_name: my-training # Creates or appends to this MLflow experiment
mlflow_run_name: baseline-lr3e5 # Names the MLflow run for this submission
compute:
num_accelerators: 8
accelerator_type: GPU_8xH100
command: torchrun --nproc_per_node=8 train.py
max_retries: 2
experiment_name(Obrigatório): Cria um experimento MLflow com este nome, se não existir, ou acrescenta uma nova execução ao experimento existente. Um experimento contém muitas execuções.mlflow_run_name(Opcional): Define o nome da execução. Se omitido, o nome da execução terá como padrão o nome do experimento (experiment_name).max_retries(Opcional): Cada nova tentativa é uma nova execução do MLflow no mesmo experimento, para que você possa comparar as tentativas. O envio original e suas novas tentativas compartilham uma única execução de job.
Navegue entre Jobs, MLflow e cargas de trabalho anteriores
É possível acessar uma execução de três lugares:
- Trabalhos : A página de execução de Trabalhos lista as suas execuções, e cada execução se vincula à sua execução do MLflow e a um experiment.
- MLflow : A página de Experimentos lista seus experimentos do MLflow.
- Cargas de trabalho anteriores:
air get run <job-run-id>imprime links clicáveis para o Job, o experiment e a execução do MLflow.air list runslista suas execuções anteriores e permite filtrar para encontrar uma execução específica.
air get run <job-run-id> # Links to the job, experiment, and MLflow run
air list runs # List previous runs; filter to find a specific run
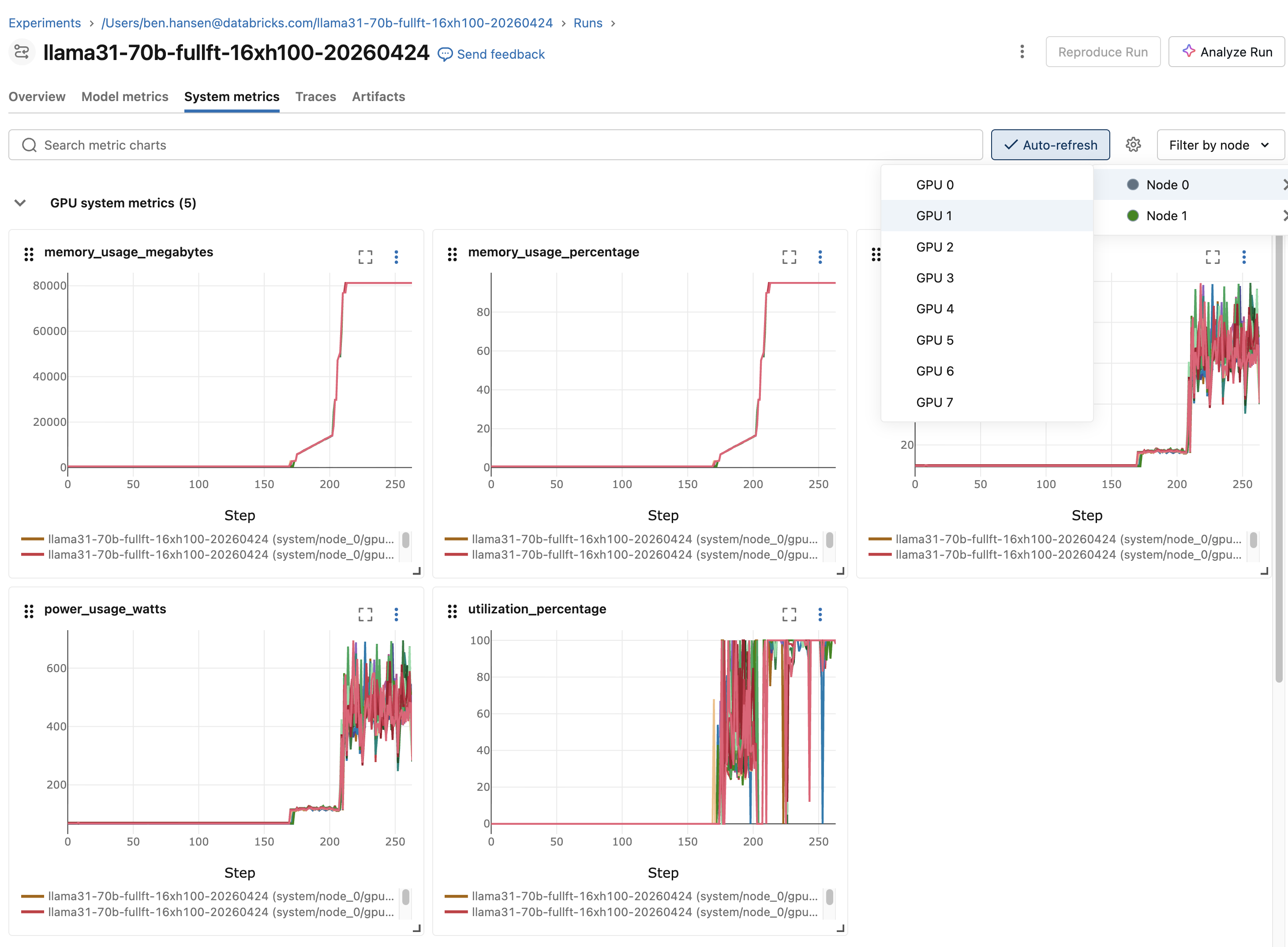
Métricas do sistema
Métricas de sistema de GPU, CPU e memória são capturadas automaticamente para cada execução. Nenhuma configuração é obrigatória. Visualize-os na tab **Métricas do sistema** da execução do MLflow.
Fazer o log de métricas personalizadas
A plataforma cria a execução do MLflow e expõe seu ID ao seu processo de treinamento por meio da variável de ambiente MLFLOW_RUN_ID. Use a API de acompanhamento do MLflow para registrar seus próprios parâmetros, métricas e artefatos nessa execução.
Em cargas de trabalho distribuídas (de vários nós), cada nó compartilha a mesma execução do MLflow. Log do processo rank-0 apenas, para que cada métrica seja registrada uma vez:
import os
import mlflow
# Log from rank 0 only; all nodes share the same MLFLOW_RUN_ID.
if os.environ.get("RANK", "0") == "0":
with mlflow.start_run(run_id=os.environ["MLFLOW_RUN_ID"]):
mlflow.log_param("learning_rate", 3e-4)
for step, loss in enumerate(training_losses):
mlflow.log_metric("train_loss", loss, step=step)
Logs e artefatos
Transmitir ou fazer download dos logs de uma execução com air logs:
air logs <job-run-id> # Stream logs from node 0
air logs <job-run-id> --node 2 # Logs from a specific node
air logs <job-run-id> --download-to ./logs/ # Download instead of streaming
Os logs também estão disponíveis como artefatos na execução do MLflow. Para persistir pontos de verificação do modelo, grave-os em um volume do Unity Catalog. Para padrões de ponto de verificação e gerenciamento de volumes, consulte Acompanhamento de experimentos e observabilidade.