Acompanhamento de experimentos e observabilidade
Visualização
Este recurso está em Pré-visualização Pública.
O AI Runtime se integra nativamente ao MLflow para acompanhamento de experimentos e inclui um painel de recursos de GPU integrado para monitoramento de utilização, memória e temperatura. Use o MLflow para fazer log de métricas e execuções, view a saída do treinamento no Notebook e na UI do MLflow, salvar pontos de verificação do modelo em volumes do Unity Catalog e acompanhar a integridade da GPU enquanto seu código é executado.
Integração do MLflow
AI Runtime integra-se nativamente ao MLflow para acompanhamento de experimentos, registro de modelos e visualização de estatísticas.
Recomendações de configuração:
-
Atualize MLflow para a versão 3.7 ou mais recente e siga os padrões de aprendizagem profunda fluxo de trabalho.
-
Ativar registro automático para PyTorch Lightning:
Pythonimport mlflow
mlflow.pytorch.autolog() -
Personalize o nome da sua execução do MLflow encapsulando o código de treinamento do seu modelo dentro do escopo da API
mlflow.start_run(). Isso lhe dá controle sobre o nome da execução e permite que você reinicie a partir de uma execução anterior. Você pode personalizar o nome da execução usando o parâmetrorun_nameemmlflow.start_run(run_name="your-custom-name")ou em bibliotecas de terceiros que suportam MLflow (por exemplo, Hugging Face Transformers). Caso contrário, o nome de execução default éjobTaskRun-xxxxx.Pythonfrom transformers import TrainingArguments
args = TrainingArguments(
report_to="mlflow",
run_name="llama7b-sft-lr3e5", # <-- MLflow run name
logging_steps=50,
) -
Ao usar a API de GPU Serverless, cada chamada para
.distributed()cria automaticamente uma execução de experimento do MLflow. Se chamado dentro de uma execução ativa do MLflow, uma execução filha aninhada é criada sob o pai ativo, em vez disso.Pythonimport mlflow
with mlflow.start_run() as outer_run:
...
run_train.distributed() # creates a nested child run under outer_run -
Para personalizar o experimento usado por
.distributed(), chamemlflow.set_experiment()antes de invocar.distributed(), ou defina a variável de ambienteMLFLOW_EXPERIMENT_NAME. O nome de experimento default é/Users/{WORKSPACE_USER}/{notebook-name}. Sempre use caminhos absolutos.Pythonimport mlflow
mlflow.set_experiment("/Users/<username>/my-experiment")
run_train.distributed()Alternativamente:
Pythonimport os
os.environ["MLFLOW_EXPERIMENT_NAME"] = "/Users/<username>/my-experiment" -
Para retomar uma execução anterior do MLflow, use
mlflow.start_run(run_id="<previous-run-id>"). -
Para retomar uma execução anterior do MLflow com
.distributed(), definaMLFLOW_RUN_IDantes de chamá-lo:Pythonos.environ["MLFLOW_RUN_ID"] = "<previous-run-id>"
run_train.distributed() -
Defina o parâmetro
stepemMLFlowLoggerpara números de lote razoáveis. O MLflow tem um limite de 10 milhões os passos de métricas, então o registro de cada lotes individual em grandes execução de treinamento pode atingir este limite. Consulte limites de recursos.
logsde visualização
- **Saída do Notebook**: A saída padrão e os erros do seu código de treinamento aparecem na saída da célula do notebook.
- **Logs do MLflow**: A interface do usuário do experimento do MLflow exibe métricas de treinamento, parâmetros e artefatos.
Ponto de verificação do modelo
Para treinamento distribuído, salve e carregue pontos de verificação do modelo assincronamente em volumes do Unity Catalog, que fornecem a mesma governança que outros objetos do Unity Catalog. Use UCVolumeWriter e UCVolumeReader do pacote serverless_gpu.data com a API Torch Distributed Checkpoint (DCP). Esses backends de armazenamento preparam todas as operações de E/S por meio de um diretório local rápido (/tmp, que é compatível com NVMe em nós de GPU serverless) e realizam upload para ou download do volume do Unity Catalog, o que é mais rápido do que escrever fragmentos de ponto de verificação diretamente no ponto de montagem FUSE. A atomicidade dos metadados é preservada: o gravador publica o arquivo .metadata somente depois que seus fragmentos de dados concluem o upload.
UCVolumeWriter, UCVolumeReader e UCVolumeDataset exigem ambiente de GPU 5 ou acima (API Python de GPU serverless 0.5.16+).
Faça pontos de verificação com frequência suficiente para limitar o trabalho perdido após uma interrupção, mas não com tanta frequência que a sobrecarga de E/S atrase o treinamento. Procure ter um ponto de verificação a cada 30 minutos a uma hora, e ajuste o intervalo com base no tempo de passo e no tamanho do ponto de verificação.
Para fazer upload de pontos de verificação em segundo plano enquanto o treinamento continua, passe um UCVolumeWriter como storage_writer para dcp.async_save. Salvamentos assíncronos exigem um backend de CPU no grupo de processos; portanto, inicialize-o com torch.distributed.init_process_group(backend="cpu:gloo,cuda:nccl", ...):
import torch.distributed.checkpoint as dcp
from serverless_gpu.data import UCVolumeWriter
checkpoint_path = "/Volumes/my_catalog/my_schema/model/checkpoints"
writer = UCVolumeWriter(checkpoint_path)
future = dcp.async_save(state_dict, storage_writer=writer)
# ...continue training...
future.result() # blocks until the upload lands on the UC volume
Carregar um ponto de verificação com UCVolumeReader:
from serverless_gpu.data import UCVolumeReader
reader = UCVolumeReader(checkpoint_path)
dcp.load(state_dict, storage_reader=reader)
Pontos de verificação da pipeline de dados
Um ponto de verificação de modelo captura o estado do modelo e do otimizador, mas não a posição de sua pipeline de dados dentro do dataset, então uma execução retomada não pode avançar rapidamente para a amostra exata onde parou. Leve isso em consideração na forma como se retoma: reiniciar a partir de um limite de época, ou acompanhar amostras ou fragmentos processados no próprio estado de treinamento para que possam ser ignorados na retomada.
Monitorar recurso de GPU
Use o painel de recursos da GPU para monitorar a integridade e a utilização da GPU durante a execução do seu código no AI Runtime. O painel suporta cargas de trabalho de nó único e de vários nós.
Para abrir o painel, conecte seu Notebook ao AI Runtime e clique em ![]() Recurso de GPU no painel lateral direito.
Recurso de GPU no painel lateral direito.
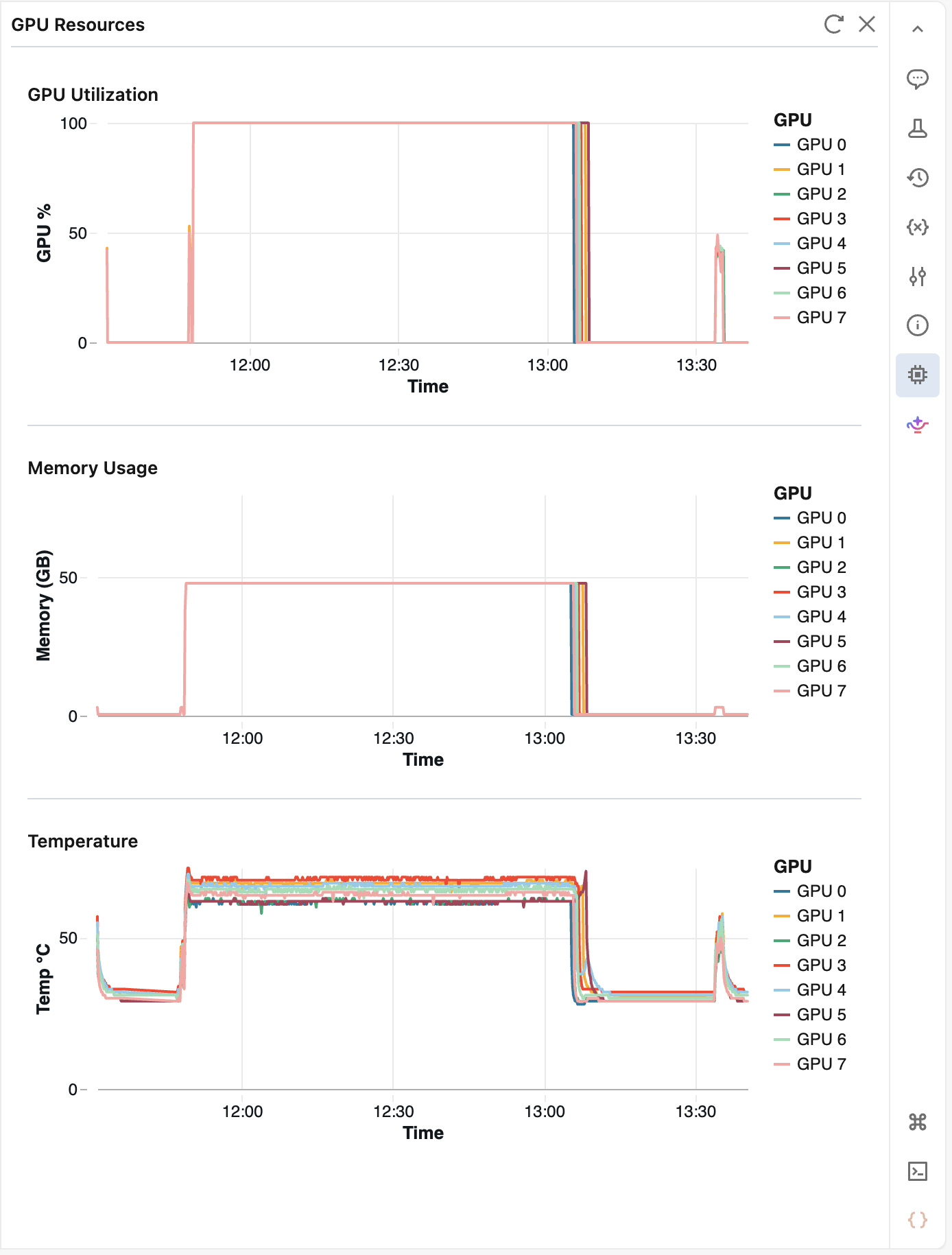
O painel exibe as seguintes métricas para cada GPU:
- porcentagem de utilização da GPU
- uso de memória da GPU
- Temperatura
O painel consulta dados a cada 10 segundos e armazena até 2 horas de histórico. Clique ![]() Atualize a página para obter os valores mais recentes imediatamente. Após 5 minutos de inatividade, o painel pausa; abra-o novamente para retomar o monitoramento.
Atualize a página para obter os valores mais recentes imediatamente. Após 5 minutos de inatividade, o painel pausa; abra-o novamente para retomar o monitoramento.
Colaboração multiusuário
- Para garantir que todos os usuários possam acessar o código compartilhado (por exemplo, módulos auxiliares ou arquivos YAML de ambiente), armazene-os em
/Workspace/Sharedem vez de pastas específicas do usuário como/Workspace/Users/<your_email>/. - Para código que está em desenvolvimento ativo, use pastas Git em pastas específicas do usuário
/Workspace/Users/<your_email>/e envie para repositórios Git remotos. Isso permite que vários usuários tenham um clone e um branch específicos para cada usuário, enquanto ainda utilizam um repo Git remoto para controle de versão. Consulte as melhores práticas para usar o Git no Databricks. - Os colaboradores podem compartilhar e comentar no Notebook.
Limites globais no Databricks
Consulte os limites de recursos.