Referência da API de Views de recurso
Visualização
Este recurso está em Prévia Pública. Administradores do Workspace podem controlar o acesso a este recurso na página **Pré-visualizações**. Consulte Gerenciar prévias do Databricks.
Controle de acesso
Recursos são objetos governáveis do Unity Catalog. O acesso a um recurso é controlado pelos privilégios CREATE FEATURE, READ FEATURE e MANAGE do Unity Catalog. Para descrições completas, consulte referência de privilégios do Unity Catalog.
CREATE FEATURE** ** — Necessário para criar um recurso em um esquema.create_featureeregister_featureexigemCREATE FEATUREno esquema pai. Seguindo o princípio do menor privilégio, concedaCREATE FEATUREno nível do esquema; também é possível concedê-lo em um catálogo para permitir a criação de recursos em qualquer esquema nesse catálogo.READ FEATURE— Necessário para ler um recurso e seus dados.get_feature,create_training_set, e a leitura de dados de recurso materializados para treinamento ou disponibilização exigemREAD FEATUREno recurso.READ FEATUREconcedido em um esquema ou catálogo se aplica a todos os recursos atuais e futuros que ele contém.MANAGE— Necessário para gerenciar o ciclo de vida e as concessões de um recurso. Excluir um recurso comdelete_feature, e materializar um recurso commaterialize_featuresoudelete_materialized_feature, exigeMANAGEno recurso.
Todas as operações de recurso também exigem USE CATALOG no catálogo pai e USE SCHEMA no esquema pai. Para saber como MANAGE e READ FEATURE se aplicam à materialização, consulte Permissões.
API de View de recurso
ConstrutorFeature e register_feature()
A abordagem recomendada é construir um objeto Feature localmente e usar register_feature para persistir no Unity Catalog. Este fluxo de trabalho de duas etapas permite experimentar recursos (incluindo create_training_set) antes de registrá-los.
Feature(
source: DataSource, # Required: DeltaTableSource, StreamSource, or RequestSource
function: Union[AggregationFunction, ColumnSelection], # Required: Aggregation or column selection
entity: Optional[List[str]] = None, # Required for all sources except RequestSource: entity columns
timeseries_column: Optional[str] = None, # Required for all sources except RequestSource: timestamp column
name: Optional[str] = None, # Optional: Feature name (auto-generated if omitted)
description: Optional[str] = None, # Optional: Feature description
)
FeatureEngineeringClient.register_feature() registra um Feature construído localmente no Unity Catalog.
FeatureEngineeringClient.register_feature(
feature: Feature, # Required: A Feature instance (not already registered)
catalog_name: str, # Required: UC catalog name
schema_name: str, # Required: UC schema name
) -> Feature
from databricks.feature_engineering.entities import Feature, DeltaTableSource, AggregationFunction, Sum, RollingWindow
from datetime import timedelta
# Step 1: Construct the feature locally
feature = Feature(
source=DeltaTableSource(catalog_name="main", schema_name="store", table_name="transactions"),
entity=["user_id"],
timeseries_column="transaction_time",
function=AggregationFunction(Sum(input="amount"), RollingWindow(window_duration=timedelta(days=7))),
)
# Step 2: Register in Unity Catalog
fe = FeatureEngineeringClient()
registered_feature = fe.register_feature(
feature=feature,
catalog_name="main",
schema_name="store",
)
create_feature()
FeatureEngineeringClient.create_feature() Valida, constrói e registra imediatamente um recurso no Unity Catalog em um único passo. Use isto quando você não precisar experimentar o recurso localmente primeiro.
FeatureEngineeringClient.create_feature(
source: DataSource, # Required: DeltaTableSource, StreamSource, or RequestSource
function: Union[AggregationFunction, ColumnSelection], # Required: Aggregation or column selection
catalog_name: str, # Required: The catalog name for the feature
schema_name: str, # Required: The schema name for the feature
entity: Optional[List[str]] = None, # Required for all sources except RequestSource: entity columns
timeseries_column: Optional[str] = None, # Required for all sources except RequestSource: timestamp column
name: Optional[str] = None, # Optional: Feature name (auto-generated if omitted)
description: Optional[str] = None, # Optional: Feature description
) -> Feature
Parâmetros:
source: a fonte de dados usada no cálculo de recurso (DeltaTableSource,StreamSourceouRequestSource).function: umAggregationFunctionque agrupa o operador (por exemplo,Sum(input="amount")), a coluna de entrada e a janela de tempo. OuColumnSelection("column_name")para recursos pass-through.catalog_name: O nome do catálogo do Unity Catalog para o recurso.schema_name: O nome do esquema do Unity Catalog para o recurso.entity: Lista de nomes de coluna que definem as chaves de agregação ou pesquisa (chaves primárias). Necessário para todos os tipos de origem, excetoRequestSource. Por exemplo,["user_id"]agrega ou pesquisa por usuário.timeseries_columnA coluna Timestamp usada para agregação por janela de tempo ou seleção do último valor. Obrigatório para todos os tipos de origem, excetoRequestSource.name: Nome de recurso opcional. Se omitido, gerado automaticamente a partir da coluna de entrada, função e janela (por exemplo,amount_avg_rolling_7d).description: Descrição opcional do recurso.
Retorna: Uma instância de recurso validada
Gera: ValueError se alguma validação falhar
delete_feature()
Exclui um recurso do Unity Catalog pelo seu nome totalmente qualificado.
FeatureEngineeringClient.delete_feature(
full_name: str, # Required: '<catalog>.<schema>.<feature_name>'
) -> None
fe.delete_feature(full_name="main.store.amount_sum_rolling_7d")
Antes de excluir um recurso, remova ou atualize quaisquer modelos ou especificações de recurso que o referenciem. Se o recurso foi materializado, exclua o recurso materializado primeiro. Consulte Como excluir um recurso materializado.
Nomes gerados automaticamente
Quando name é omitido, um nome é gerado automaticamente. Os nomes gerados seguem o padrão: {column}_{function}_{window}. Por exemplo:
price_avg_rolling_1h(preço médio de 1 hora)transaction_count_rolling_30d_1d(Contagem de 30 dias de transação com atraso de 1 dia do timestamp do evento)
Funções suportadas
Funções de agregação
As funções de agregação são encapsuladas em um AggregationFunction junto com uma janela de tempo, conforme descrito em janelas de tempo. Cada função recebe um parâmetro input que especifica a coluna de origem a ser agregada.
Função | Descrição | Exemplo de caso de uso |
|---|---|---|
| Total de valores | Uso diário do aplicativo por usuário em minutos |
| Média de valores | Valor médio da transação |
| Número de registros | Número de logins por usuário |
| Valor mínimo | Menor frequência cardíaca registrada por um dispositivo wearable |
| Valor máximo | Maior valor de transação por sessão. |
| Desvio padrão populacional | Variabilidade diária do valor da transação entre todos os clientes |
| Desvio padrão de amostra | Variabilidade das taxas de cliques de campanhas de anúncios |
| Variância populacional | Dispersão das leituras do sensor para dispositivos IoT em uma fábrica. |
| Variância de amostra | Distribuição de avaliações de filmes em um grupo amostrado |
| Contagem única aproximada | Contagem distinta de itens comprados |
| Percentil aproximado | Latência de resposta p95 |
| Primeiro valor | Primeiro login Timestamp |
| Último valor | Valor de compra mais recente |
First e Last incluem valores nulos por default. Para ignorar nulos, adicione um filter_condition que exclua explicitamente colunas de entrada que são nulas.
ColumnSelection (pass-through)
ColumnSelection seleciona uma única coluna de uma fonte sem aplicar nenhuma agregação. É encapsulado diretamente no parâmetro function (não dentro de AggregationFunction). O tipo de retorno é inferido do esquema de origem.
Função | Descrição | Exemplo de caso de uso |
|---|---|---|
| Último valor de uma coluna (sem agregação) | Categoria de fornecedor mais recente, pass-through de um campo de solicitação |
ColumnSelection pode ser usado com qualquer fonte de dados:
DeltaTableSource: Retorna o valor mais recente por chave de entidade via um join pontual (sem agregação de janela de retrospectiva).StreamSource: Retorna o valor mais recente por key de entidade da transmissão (sem agregação de janela de retrospectiva).RequestSource: Passa o valor fornecido no momento da inferência (ou extraído do DataFrame rotulado no momento do treinamento).
from databricks.feature_engineering.entities import (
ColumnSelection, DeltaTableSource, Feature, FieldDefinition,
RequestSource, ScalarDataType,
)
delta_source = DeltaTableSource(
catalog_name="main", schema_name="feature_store", table_name="transactions",
)
request_source = RequestSource(
schema=[
FieldDefinition(name="session_duration", data_type=ScalarDataType.DOUBLE),
]
)
# ColumnSelection from a Delta table
latest_amount = Feature(
source=delta_source,
function=ColumnSelection("amount"),
entity=["user_id"],
timeseries_column="transaction_time",
name="latest_transaction_amount",
)
# ColumnSelection from a RequestSource
session_feature = Feature(
source=request_source,
function=ColumnSelection("session_duration"),
name="session_duration",
)
Exemplo: recursos de agregação e seleção de colunas
O exemplo a seguir mostra recursos definidos sobre a mesma fonte de dados.
from databricks.feature_engineering.entities import (
AggregationFunction, Feature, Sum, Avg, ApproxCountDistinct,
ColumnSelection, RollingWindow,
)
from datetime import timedelta
window = RollingWindow(window_duration=timedelta(days=7))
sum_feature = Feature(
source=source,
entity=["user_id"],
timeseries_column="event_time",
function=AggregationFunction(Sum(input="amount"), window),
)
avg_feature = Feature(
source=source,
entity=["user_id"],
timeseries_column="event_time",
function=AggregationFunction(Avg(input="amount"), window),
)
distinct_count = Feature(
source=source,
entity=["user_id"],
timeseries_column="event_time",
function=AggregationFunction(ApproxCountDistinct(input="product_id", relativeSD=0.01), window),
)
# Column selection (no aggregation, no time window)
latest_amount = Feature(
source=source,
function=ColumnSelection("amount"),
entity=["user_id"],
timeseries_column="event_time",
name="latest_amount",
)
Recursos com condições de filtro
O filter_condition parâmetro permite filtrar linhas da tabela de origem **antes** de computar agregações. Isso funciona como uma cláusula SQL WHERE que é aplicada antes de agrupar e agregar dados.
filter_condition filtra linhas antes da agregação, como uma cláusula WHERE SQL aplicada antes de GROUP BY. Isso não altera a granularidade, que é sempre definida por entity na definição do recurso.
Filtros são úteis ao trabalhar com grandes tabelas de origem que incluem um superconjunto de dados necessários para o compute de recursos, e minimizam a necessidade de criar views separadas sobre essas tabelas.
from databricks.feature_engineering.entities import AggregationFunction, Sum, Count, RollingWindow, DeltaTableSource
from datetime import timedelta
# Source with filter applied at the source level
high_value_transactions = DeltaTableSource(
catalog_name="main",
schema_name="ecommerce",
table_name="transactions",
filter_condition="amount > 100", # Only transactions over $100
)
high_value_sales = Feature(
source=high_value_transactions,
entity=["user_id"],
timeseries_column="transaction_time",
function=AggregationFunction(Sum(input="amount"), RollingWindow(window_duration=timedelta(days=30))),
)
# Multiple conditions
completed_orders_source = DeltaTableSource(
catalog_name="main",
schema_name="ecommerce",
table_name="orders",
filter_condition="status = 'completed' AND payment_method = 'credit_card'",
)
completed_orders = Feature(
source=completed_orders_source,
entity=["user_id"],
timeseries_column="order_time",
function=AggregationFunction(Count(input="order_id"), RollingWindow(window_duration=timedelta(days=7))),
)
# Filter on a StreamSource
from databricks.feature_engineering.entities import StreamSource
purchase_stream = StreamSource(
full_name="main.ecommerce.transactions_stream",
filter_condition="value.event_type = 'purchase'",
)
purchase_total = Feature(
source=purchase_stream,
entity=["value.user_id"],
timeseries_column="value.event_time",
function=AggregationFunction(Sum(input="value.amount"), RollingWindow(window_duration=timedelta(hours=1))),
)
fonte de dados
DeltaTableSource
DeltaTableSource é um objeto Python efêmero usado para definir como os recursos são computados a partir de uma tabela de origem. Não cria uma nova tabela. Ele especifica a configuração para ler dados e agregar recursos.
DeltaTableSource(
catalog_name: str, # Required: Catalog name
schema_name: str, # Required: Schema name
table_name: str, # Required: Table name
filter_condition: Optional[str] = None, # Optional: SQL WHERE clause to filter source data
transformation_sql: Optional[str] = None, # Optional: SQL SELECT expression for column transformations
dataframe_schema: Optional[str] = None, # Required if transformation_sql is set: schema of the resulting DataFrame
)
Parâmetros:
catalog_name,schema_name,table_name: Identifique a tabela Delta de origem no Unity Catalog.filter_condition: Uma cláusula SQLWHEREaplicada antes da agregação. Exemplo:"status = 'completed'".transformation_sql: Uma expressão SQLSELECTaplicada à tabela de origem. Use isso para renomear colunas, converter tipos ou calcular colunas derivadas antes da agregação. Se omitido, todas as colunas são selecionadas (*). Exemplo:"user_id, CAST(amount AS DOUBLE) AS amount, event_time".dataframe_schema: o esquema do DataFrame resultante após as transformações, no formato JSON Spark StructType (dedf.schema.json()). Obrigatório setransformation_sqlfor fornecido. Isso informa ao sistema os nomes e tipos de coluna que resultam da sua transformação.
Quando filter_condition e transformation_sql estão definidos, a query resultante é: SELECT {transformation_sql} FROM {table} WHERE {filter_condition}.
O timeseries_column (especificado na definição do recurso, não em DeltaTableSource) deve ser do tipo TimestampType ou DateType. Integer types podem funcionar, mas causam perda de precisão para agregações de janela de tempo.
Exemplo: Usando transformation_sql para transformações de coluna
source = DeltaTableSource(
catalog_name="main",
schema_name="analytics",
table_name="raw_events",
transformation_sql="user_id, CAST(price_cents AS DOUBLE) / 100 AS price, event_time",
filter_condition="event_type = 'purchase'",
dataframe_schema=spark.sql(
"SELECT user_id, CAST(price_cents AS DOUBLE) / 100 AS price, event_time FROM main.analytics.raw_events LIMIT 0"
).schema.json(),
)
Exemplo: Derivando transformation_sql e dataframe_schema de um PySpark DataFrame
É possível escrever a transformação como uma query PySpark e, então, extrair o esquema do DataFrame resultante:
df = spark.sql(f"""
SELECT user_id, CAST(amount AS DOUBLE) / 100 AS amount_dollars, event_time
FROM main.analytics.events
WHERE event_date >= date_sub(current_date(), 7)
LIMIT 0
""")
# Use df.schema.json() as the dataframe_schema
source = DeltaTableSource(
catalog_name="main",
schema_name="analytics",
table_name="events",
transformation_sql="user_id, CAST(amount AS DOUBLE) / 100 AS amount_dollars, event_time",
filter_condition="event_date >= date_sub(current_date(), 7)",
dataframe_schema=df.schema.json(),
)
transformation_sql suporta apenas expressões linha a linha (renomeações de coluna, conversões de tipo, aritméticas). Funções de agregação como COUNT(*) ou SUM() não são compatíveis. Use AggregationFunction na definição do recurso em vez disso.
DeltaTableSource.from_sql()
Por conveniência, você pode criar um DeltaTableSource a partir de uma query SQL. O método analisa a query para extrair automaticamente o nome da tabela, transformation_sql e filter_condition.
DeltaTableSource.from_sql(
sql: str, # Required: SQL SELECT query
spark: SparkSession, # Required: active SparkSession (for schema inference)
) -> DeltaTableSource
Apenas SELECT ... FROM ... [WHERE ...] queries simples são compatíveis. SQL complexo (JOINs, subqueries, CTEs, UNIONs) é rejeitado. Para queries complexas, construa DeltaTableSource diretamente com transformation_sql e filter_condition.
from databricks.feature_engineering.entities import (
AggregationFunction,
DeltaTableSource,
Feature,
Sum,
TumblingWindow,
)
source = DeltaTableSource.from_sql(
spark=spark,
sql=f"SELECT customer_id, event_ts, amount * 2 AS doubled_amount, amount FROM {CATALOG}.{SCHEMA}.{TABLE}",
)
feature = Feature(
source=source,
function=AggregationFunction(Sum(input="doubled_amount"), time_window=TumblingWindow(window_duration=timedelta(days=7))),
entity=["customer_id"], timeseries_column="event_ts",
)
Iterar com to_dataframe()
Use source.to_dataframe() para visualizar os dados que serão usados para o compute de recursos. Isso é útil para iterar em filter_condition e transformation_sql até que produzam os resultados esperados.
source = DeltaTableSource(
catalog_name="main",
schema_name="analytics",
table_name="events",
filter_condition="event_type = 'purchase'",
)
# Preview the filtered source data
source.to_dataframe().display()
Compreendendo as entidades
As colunas de entidade definem o nível de agregação para seus recursos. Elas são especificadas na definição de Feature, e não em DeltaTableSource. As entidades determinam:
- Como os dados são agrupados : Os recursos são agregados por combinação única de valores de entidade (semelhante a
GROUP BYem SQL) - A estrutura da key primária : Cada combinação de entidade exclusiva resulta em uma linha de recursos de compute
Exemplo: Recursos em nível de cliente.
O código a seguir agrega recursos no nível do cliente (uma linha por cliente):
from databricks.feature_engineering.entities import DeltaTableSource
source = DeltaTableSource(
catalog_name="main",
schema_name="analytics",
table_name="user_events",
)
Feature(
source=source,
entity=["user_id"], # Features aggregated per user
timeseries_column="event_time", # Timestamp for time windows
function=AggregationFunction(Sum(input="amount"), RollingWindow(window_duration=timedelta(days=7))),
)
Exemplo: Recursos no nível do cliente-loja
Para agregar recursos em um nível mais detalhado (uma linha por combinação cliente-loja), use múltiplas colunas de entidade:
source = DeltaTableSource(
catalog_name="main",
schema_name="retail",
table_name="transactions",
)
Feature(
source=source,
entity=["user_id", "store_id"], # Features aggregated per user-store pair
timeseries_column="transaction_time",
function=AggregationFunction(Sum(input="amount"), RollingWindow(window_duration=timedelta(days=7))),
)
Quando precisar de recursos em diferentes níveis de agregação (por exemplo, nível de cliente e nível de cliente-loja), use valores de entity diferentes em suas definições de recursos. O mesmo DeltaTableSource pode ser compartilhado entre recursos com diferentes configurações de entidade.
StreamSource
StreamSource referencia uma Transmissão. A Transmissão contém conexão, autenticação, esquema e configuração de ingestão para a fonte de transmissão. Para Kafka, as referências de coluna nas definições de recurso devem ser prefixadas com value. ou key. para indicar qual parte da mensagem ler.
StreamSource(
full_name: str, # Required: Three-part Stream name (catalog.schema.stream)
filter_condition: Optional[str], # Optional: SQL WHERE clause applied before aggregation
)
Parâmetros:
full_name: O nome completo de três partes de uma transmissão (por exemplo,"my_catalog.my_schema.my_stream").filter_condition(opcional): Uma cláusula SQLWHEREaplicada a dados de transmissão antes da agregação, usando referências de coluna com prefixo de ponto (por exemplo,"value.event_type = 'purchase'").
from databricks.feature_engineering.entities import StreamSource
stream_source = StreamSource(
full_name="my_catalog.my_schema.my_stream",
filter_condition="value.event_type = 'purchase'",
)
RequestSource
RequestSource define um esquema para dados que são fornecidos no momento da inferência na carga útil da solicitação, em vez de pesquisados em uma tabela pré-materializada. Durante o treinamento, estas colunas são extraídas do DataFrame rotulado passado para create_training_set. Durante o servindo modelo, o chamador deve incluí-los na carga útil da solicitação HTTP.
RequestSource é usado com ColumnSelection (para passar um valor diretamente). Não oferece suporte a funções de agregação ou janelas de tempo.
Definindo o esquema
Defina o esquema como uma lista de objetos FieldDefinition, cada um especificando um nome de coluna e um ScalarDataType:
from databricks.feature_engineering.entities import (
FieldDefinition, RequestSource, ScalarDataType,
)
request_source = RequestSource(
schema=[
FieldDefinition(name="transaction_amount", data_type=ScalarDataType.DOUBLE),
FieldDefinition(name="vendor_id", data_type=ScalarDataType.STRING),
FieldDefinition(name="transaction_id", data_type=ScalarDataType.STRING),
FieldDefinition(name="transaction_time", data_type=ScalarDataType.DATE),
]
)
Tipos de dados compatíveis
RequestSource suporta os tipos escalares definidos em ScalarDataType: INTEGER, FLOAT, BOOLEAN, STRING, DOUBLE, LONG, TIMESTAMP, DATE, SHORT. Tipos complexos como matrizes, mapas e structs não são compatíveis.
Como os dados da solicitação são hidratados
Contexto | Comportamento |
|---|---|
**Treinamento** | Colunas são extraídas do DataFrame rotulado. Os tipos são validados em relação ao esquema declarado. Incompatibilidades geram um erro (sem conversão implícita). |
**Serviço** (Endpoint de modelo) | As colunas são extraídas de |
Assinatura do modelo
Quando um modelo é registrado usando log_model com um conjunto de treinamento que inclui RequestSource recursos, as colunas RequestSource são adicionadas à assinatura do modelo MLflow como entradas obrigatórias. Isso significa que o esquema da API do Endpoint de serviço reflete quais campos os chamadores devem fornecer no momento da inferência.
API de treinamento e inferência
create_training_set e score_batch compute valores de recurso corretos em determinado momento sob demanda a partir dos dados de origem. Para recursos que suportam a materialização offline, como agregações de janela deslizante em fontes de tabela delta, materializar os recursos primeiro em um armazenamento offline melhora o desempenho de ambas as operações. Quando recursos offline materializados estão disponíveis, as operações leem dados offline pré-computados em vez de recalcular os valores de recurso da fonte. Consulte Materializar Views de Recurso para materializar recursos em um armazenamento offline.
create_training_set()
Cria um dataset de treinamento com cálculo de recurso correto pontual. Para obter detalhes, consulte Ensinar modelos com Recurso Views.
FeatureEngineeringClient.create_training_set(
df: DataFrame, # DataFrame with training data
features: Optional[List[Feature]], # List of Feature objects
label: Union[str, List[str], None], # Label column name(s)
exclude_columns: Optional[List[str]] = None, # Optional: columns to exclude
) -> TrainingSet
log_model()
Logs um modelo com metadados de recurso para acompanhamento de linhagem e consulta automática de recursos durante a inferência. Para obter detalhes, consulte Ensinar modelos com Recurso Views.
FeatureEngineeringClient.log_model(
model, # Trained model object
artifact_path: str, # Path to store model artifact
flavor: ModuleType, # MLflow flavor module (e.g., mlflow.sklearn)
training_set: TrainingSet, # TrainingSet used for training
registered_model_name: Optional[str], # Optional: register model in Unity Catalog
)
score_batch()
Executa inferência em lote offline com pesquisa automática de recursos. Utiliza os metadados de recursos armazenados com o modelo para calcular recursos corretos para um ponto no tempo, garantindo consistência com o treinamento.
FeatureEngineeringClient.score_batch(
model_uri: str, # URI of logged model (e.g., "models:/catalog.schema.model/1")
df: DataFrame, # DataFrame with entity keys and timestamps
) -> DataFrame
O DataFrame de entrada deve conter as colunas de entidade e séries temporais usadas durante o treinamento. Recursos são automaticamente computados a partir dos dados de origem.
fe = FeatureEngineeringClient()
# Batch scoring with automatic feature lookup
predictions = fe.score_batch(
model_uri="models:/main.ecommerce.fraud_model/1",
df=inference_df,
)
predictions.display()
Janelas de tempo
As Views de recurso suportam três tipos diferentes de view para controlar o comportamento de retrocesso para agregações baseadas em janelas de tempo: contínua, em cascata e deslizante.
- Janelas contínuas retroagem a partir do tempo do evento. Duração e atraso são explicitamente definidos.
- Janelas em cascata são janelas de tempo fixas e não sobrepostas. Cada ponto de dados pertence a exatamente uma janela.
- As janelas deslizantes são janelas de tempo sobrepostas e contínuas com um intervalo de deslizamento configurável.
A ilustração a seguir mostra como eles funcionam.
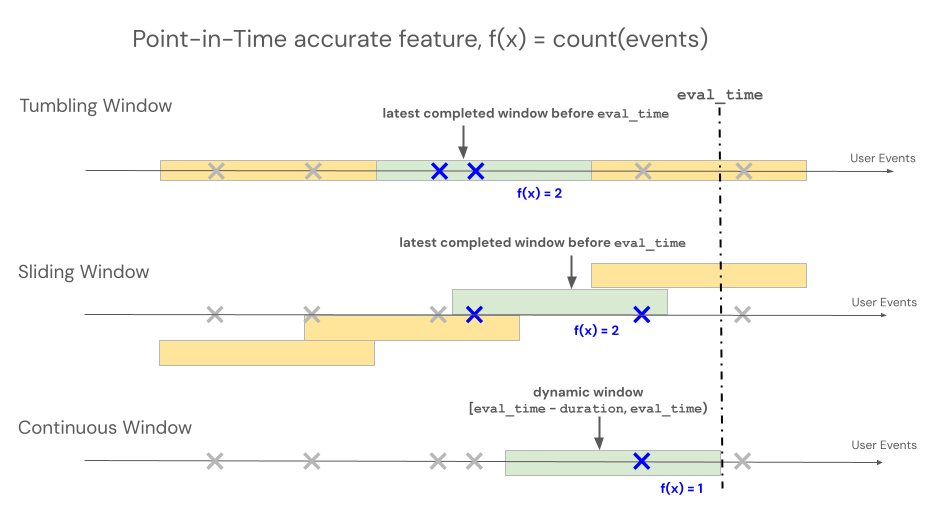
Janela contínua
RollingWindow era anteriormente denominado ContinuousWindow. Se estiver migrando de uma versão anterior do SDK, atualize suas importações de acordo.
Janelas deslizantes são agregados atualizados e em tempo real, tipicamente usados em dados de transmissão. Em pipelines de transmissão, a janela deslizante emite uma nova linha apenas quando o conteúdo da janela de comprimento fixo muda, como quando um evento entra ou sai. Quando um recurso de janela deslizante é usado em pipelines de treinamento, um cálculo preciso de recurso pontual é realizado nos dados de origem usando a duração de janela de comprimento fixo imediatamente anterior ao Timestamp de um evento específico. Isso ajuda a evitar distorções online-offline ou vazamento de dados. Recursos no tempo T agregam eventos de [T − duração, T).
class RollingWindow(TimeWindow):
window_duration: datetime.timedelta
delay: Optional[datetime.timedelta] = None
A tabela a seguir lista os parâmetros para uma janela contínua. Os horários de início e término da janela são baseados nestes parâmetros da seguinte forma:
- Hora de início:
evaluation_time - window_duration - delay(inclusive) - Hora de término:
evaluation_time - delay(exclusiva)
Parâmetro | Restrições |
|---|---|
| Deve ser ≥ 0 (desloca a janela para trás no tempo a partir do timestamp de avaliação). Use |
| Deve ser > 0 |
from databricks.feature_engineering.entities import RollingWindow
from datetime import timedelta
# Look back 7 days from evaluation time
window = RollingWindow(window_duration=timedelta(days=7))
Defina uma janela contínua com atraso usando o código abaixo.
# Look back 7 days, offset by 1 minute to account for data ingestion delay
window = RollingWindow(
window_duration=timedelta(days=7),
delay=timedelta(minutes=1)
)
Exemplos de janela deslizante
-
window_duration=timedelta(days=7): Isso cria uma janela de retrospectiva de 7 dias terminando no tempo de avaliação atual. Para um evento às 14:00 no Dia 7, isto inclui todos os eventos das 14:00 do Dia 0 até (mas sem incluir) as 14:00 do Dia 7. -
window_duration=timedelta(hours=1), delay=timedelta(minutes=30): Isso cria uma janela de retrospectiva de 1 hora terminando 30 minutos antes do tempo de avaliação. Para um evento às 15:00, isso inclui todos os eventos das 13:30 até (mas não incluindo) as 14:30. Isto é útil para considerar atrasos na ingestão de dados.
Janela em cascata
Para recursos definidos usando janelas deslizantes, as agregações são calculadas em uma janela de comprimento fixo pré-determinada que avança por um intervalo de slide, produzindo janelas não sobrepostas que particionam totalmente o tempo. Como resultado, cada evento na origem contribui para exatamente uma janela. Recursos no tempo t agregam dados de janelas terminando em ou antes de t (exclusivo). Windows começam na época Unix.
class TumblingWindow(TimeWindow):
window_duration: datetime.timedelta
A tabela a seguir lista os parâmetros para uma janela em cascata.
Parâmetro | Restrições |
|---|---|
| Deve ser > 0 |
from databricks.feature_engineering.entities import TumblingWindow
from datetime import timedelta
window = TumblingWindow(
window_duration=timedelta(days=7)
)
Exemplo de janela de rolagem
window_duration=timedelta(days=5): Isso cria janelas de comprimento fixo predeterminadas de 5 dias cada. Exemplo: a Janela #1 abrange do Dia 0 ao Dia 4, a Janela #2 abrange do Dia 5 ao Dia 9, a Janela #3 abrange do Dia 10 ao Dia 14 e assim por diante. Especificamente, a Janela #1 inclui todos os eventos com timestamps que começam em00:00:00.00no Dia 0 até (mas não incluindo) quaisquer eventos com timestamp00:00:00.00no Dia 5. Cada evento pertence a exatamente uma janela.
Janela deslizante
Para recursos definidos usando janelas deslizantes, as agregações são computadas em uma janela de comprimento fixo pré-determinada que avança por um intervalo de deslizamento, produzindo janelas sobrepostas. Cada evento na fonte pode contribuir para a agregação de recursos para várias janelas. Os recursos no tempo t agregam dados de janelas que terminam em ou antes de t (exclusivo). Windows começam na época Unix.
class SlidingWindow(TimeWindow):
window_duration: datetime.timedelta
slide_duration: datetime.timedelta
A tabela a seguir lista os parâmetros para uma janela deslizante.
Parâmetro | Restrições |
|---|---|
| Deve ser > 0 |
| Deve ser > 0 e < |
from databricks.feature_engineering.entities import SlidingWindow
from datetime import timedelta
window = SlidingWindow(
window_duration=timedelta(days=7),
slide_duration=timedelta(days=1)
)
Exemplo de janela deslizante
window_duration=timedelta(days=5), slide_duration=timedelta(days=1): Isso cria janelas sobrepostas de 5 dias que avançam em 1 dia a cada vez. Exemplo: A janela nº 1 abrange do Dia 0 ao Dia 4, a janela nº 2 abrange do Dia 1 ao Dia 5, a janela nº 3 abrange do Dia 2 ao Dia 6, e assim por diante. Cada janela inclui eventos de00:00:00.00no dia de início até (mas sem incluir)00:00:00.00no dia de término. Como as janelas se sobrepõem, um único evento pode pertencer a várias janelas (neste exemplo, cada evento pertence a até 5 janelas diferentes).
Trigger de materialização
Triggers controlam quando um pipeline de materialização é executado. O tipo de trigger depende do tipo de recurso.
CronSchedule
Use CronSchedule para recursos de agregação (AggregationFunction). O pipeline é executado em um agendamento fixo definido por uma expressão cron Quartz.
from databricks.feature_engineering.entities import CronSchedule
trigger = CronSchedule(
quartz_cron_expression="0 0 * * * ?", # Hourly
timezone_id="UTC",
)
TableTrigger
Use TableTrigger para recursos ColumnSelection apoiados por um DeltaTableSource. O pipeline é executado sempre que a tabela Delta upstream recebe um novo commit.
from databricks.feature_engineering.entities import TableTrigger
trigger = TableTrigger()
StreamingMode
Use StreamingMode para recursos apoiados por um StreamSource. O pipeline é executado como um pipeline de transmissão contínua.
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering.entities import (
StreamSource, Feature, AggregationFunction, Sum,
RollingWindow, OnlineStoreConfig, StreamingMode,
)
from datetime import timedelta
fe = FeatureEngineeringClient()
stream_source = StreamSource(full_name="my_catalog.my_schema.my_stream")
streaming_feature = fe.create_feature(
source=stream_source,
entity=["value.user_id"],
timeseries_column="value.event_time",
function=AggregationFunction(
operator=Sum(input="value.amount"),
time_window=RollingWindow(window_duration=timedelta(hours=1)),
),
catalog_name="my_catalog",
schema_name="my_schema",
name="user_purchase_sum",
)
fe.materialize_features(
features=[streaming_feature],
online_config=OnlineStoreConfig(
catalog_name="my_catalog",
schema_name="my_schema",
table_name_prefix="streaming_features_serving",
online_store_name="feature_store_online",
),
trigger=StreamingMode(),
)
Escolhendo um Trigger
Tipo de recurso | Trigger | Quando é executado |
|---|---|---|
Agregação ( |
| Em uma programação cron fixa |
|
| Em cada commit da tabela de origem |
Recursos de |
| Transmissão contínua |
Não é possível materializar recursos que exigem tipos de trigger diferentes em uma única chamada materialize_features. Faça chamadas separadas em vez disso.
Migre recursos beta para a Prévia Pública
A Prévia Pública de Visualizações de Recursos apresenta entidades de Recurso de primeira classe no Unity Catalog, governadas pelos privilégios CREATE FEATURE e READ FEATURE, e requer a versão databricks-feature-engineering 0.16.0 ou posterior. Recursos criados durante a versão beta (com a versão 0.15.0) são armazenados como funções do Unity Catalog e não são compatíveis com todas as funcionalidades da Prévia Pública. Para obter suporte de longo prazo para a Prévia Pública, recrie seus recursos beta com a versão 0.16.0. Os recursos devem ser excluídos e recriados, e não apenas rematerializados.
Para obter mais informações sobre recursos, consulte Feature Views.
O que precisa ser feito
- Fazer upgrade para 0.16.0. Esta é a versão de cliente exigida para recursos em Public Preview (lotes e transmissão).
- Recrie seus recursos. As Visualizações de Recursos Beta devem ser excluídas e recriadas, e não rematerializadas, porque não são compatíveis com todas as funcionalidades da Prévia Pública.
- Migre antes que a janela se feche. Os recursos beta existentes devem ser migrados antes de 22 de julho de 2026.
Identificar recursos beta e de Pré-lançamento Público
Recursos em Prévia Pública aparecem como um objeto **Recurso** no Unity Catalog, por exemplo, no Catalog Explorer. Recursos beta aparecem como uma função com uma definição YAML. Qualquer recurso representado como uma função é um recurso beta que precisa ser migrado.
Migrar recursos beta
Migrar um recurso beta tem três partes:
- Recrie o recurso como um recurso de Prévia Pública.
- Rematerialize o recurso, para que suas tabelas offline e online sejam reconstruídas sob o novo recurso.
- Depois de verificar os recursos migrados, exclua os recursos beta e suas materializações.
Recriar os recursos
Use list_beta_feature_views para encontrar seus recursos beta, Feature.clone() para criar uma cópia não registrada e register_feature para registrar novamente cada cópia como um recurso de Prévia Pública. A clonagem limpa o registro, o catálogo e o esquema para que o recurso possa ser registrado novamente.
Para evitar colisões de nomes, registre recursos migrados com um nome diferente ou em um esquema diferente dos recursos beta. O exemplo a seguir registra novamente cada recurso em seu esquema original com um sufixo de nome _migrated.
# Update this to the catalog whose beta Feature Views you want to migrate.
CATALOG_TO_MIGRATE = "main"
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# 1. Find every beta Feature View in the catalog. Returns Feature objects,
# scanned across all schemas in the catalog.
beta_features = fe.list_beta_feature_views(catalog_name=CATALOG_TO_MIGRATE)
# Keep each beta feature paired with its migrated counterpart for the next steps.
migrations = []
for beta_feature in beta_features:
catalog_name, schema_name, leaf_name = beta_feature.full_name.split(".")
# 2. Clone the feature as an unregistered copy, renamed with a "_migrated" suffix.
cloned = beta_feature.clone(new_name=f"{leaf_name}_migrated")
# 3. Re-register the clone as a Public Preview feature.
migrated = fe.register_feature(
feature=cloned,
catalog_name=catalog_name,
schema_name=schema_name,
)
migrations.append((beta_feature, migrated))
Rematerializar os recursos migrados
Se um recurso beta foi materializado, rematerialize sua contraparte da Prévia Pública para que suas tabelas offline e online sejam reconstruídas sob o novo recurso. Forneça as configurações de armazenamento offline e online para o recurso migrado e reconstrua o Trigger da materialização existente do recurso beta.
from databricks.feature_engineering.entities import (
CronSchedule,
OfflineStoreConfig,
OnlineStoreConfig,
TableTrigger,
)
for beta_feature, migrated in migrations:
# Inspect the beta feature's existing materializations to see what to rebuild and
# to reconstruct the same trigger.
trigger = None
needs_offline = needs_online = False
for mf in fe.list_materialized_features(feature_name=beta_feature.full_name):
needs_online = needs_online or bool(mf.is_online)
needs_offline = needs_offline or not mf.is_online
# Rebuild the trigger from the materialized feature.
if mf.cron_schedule_trigger is not None:
trigger = CronSchedule(
quartz_cron_expression=mf.cron_schedule_trigger.cron_expression,
timezone_id="UTC", # Materialized schedules run in UTC.
)
elif mf.table_trigger is not None:
trigger = TableTrigger()
elif mf.streaming_mode is not None:
# Streaming features use StreamingMode, which can be reused as-is.
trigger = mf.streaming_mode
if not (needs_offline or needs_online):
continue # The beta feature was never materialized.
catalog_name, schema_name, _ = migrated.full_name.split(".")
fe.materialize_features(
features=[migrated],
offline_config=OfflineStoreConfig(
catalog_name=catalog_name,
schema_name=schema_name,
table_name_prefix="migrated_features",
)
if needs_offline
else None,
online_config=OnlineStoreConfig(
catalog_name=catalog_name,
schema_name=schema_name,
table_name_prefix="migrated_features",
online_store_name="my_online_store",
)
if needs_online
else None,
trigger=trigger,
)
Materializar cada recurso em sua própria chamada materialize_features cria um pipeline separado. Para reduzir o custo de compute, agrupe os recursos que compartilham um destino offline e online e trigger em uma única chamada materialize_features, passando-os juntos em features.
Excluir os recursos beta
Exclua recursos beta e suas materializações somente depois que você verificar se os recursos migrados e seus dados materializados estão corretos. A exclusão é irreversível.
Após verificar os recursos migrados, exclua as materializações de cada recurso beta e, em seguida, o próprio recurso beta.
for beta_feature, _ in migrations:
# Delete the beta feature's materializations first.
mfs = list(fe.list_materialized_features(feature_name=beta_feature.full_name))
offline_mfs = [mf for mf in mfs if not mf.is_online]
if offline_mfs:
# Aggregation features pair an offline and online table; deleting the offline
# materialized feature removes its paired online table too.
for mf in offline_mfs:
fe.delete_materialized_feature(materialized_feature=mf)
else:
# Online-only features (ColumnSelection, streaming) have no offline pair; delete
# the online materialized feature directly.
for mf in mfs:
fe.delete_materialized_feature(materialized_feature=mf)
# Then delete the beta feature definition.
fe.delete_feature(full_name=beta_feature.full_name)