Criar um endpoint de modelo de serviço personalizado
Este artigo descreve como criar um endpoint servindo modelo que serve modelos personalizados usando Databricks servindo modelo.
O servindo modelo oferece as seguintes opções para servir a criação do endpoint:
- A interface de usuário de serviço
- API REST
- SDK de implantações do MLflow
Para criar um endpoint que atenda aos modelos generativos do AI, consulte Criar um endpoint que atenda ao modelo.
Requisitos
- Seu workspace deve estar em uma região compatível.
- Se o senhor usar uma biblioteca personalizada ou uma biblioteca de um servidor espelho privado com seu modelo, consulte Usar uma biblioteca personalizada Python com o modelo de serviço antes de criar o modelo endpoint.
- Para criar um endpoint usando o MLflow Deployments SDK, o senhor deve instalar o cliente MLflow Deployment. Para instalá-lo, execute:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Identidade e acesso
Para criar ou atualizar um endpoint de servindo modelo, tanto o chamador quanto o criador registrado do endpoint devem:
- Seja membro do workspace.
- Mantenha o direito
workspace-access.
Identidade do criador
Ao criar um endpoint, o Databricks registra a identidade de chamada como o criador do endpoint. Essa identidade — normalmente uma entidade de serviço — é usada para acessar recursos do Unity Catalog em nome do endpoint e não pode ser alterada após a criação.
Se o criador registrado não tiver as permissões necessárias do Unity Catalog ou tiver sido removido do workspace, você deverá excluir o endpoint e recriá-lo em uma entidade de serviço que tenha as permissões necessárias e seja um membro atual do workspace.
As atualizações de configuração e de entidades atendidas reavaliam a participação e as permissões do criador registrado no workspace. As atualizações falham com PERMISSION_DENIED se o criador registrado não for mais membro do workspace, mesmo quando o chamador tiver permissões válidas.
Subvenções da entidade atendida
O criador registrado deve possuir as seguintes autorizações para cada entidade atendida. As concessões validadas na criação ou atualização do endpoint fazem com que a solicitação falhe com PERMISSION_DENIED se estiverem ausentes. As permissões necessárias no momento da consulta não são validadas antecipadamente — a falta de permissões causa erros de tempo de execução quando o endpoint atende ao tráfego.
Tipo de recurso | Subsídio necessário | Quando validado |
|---|---|---|
Unity Catalog model |
| Criação ou atualização de endpoint |
Se um modelo do Unity Catalog declarar dependências de função transitivas, o criador registrado também precisará de EXECUTE nessas funções upstream.
Gerenciar o acesso ao endpoint
Para entender as opções de controle de acesso para endpoints de serviço de modelos, consulte Gerenciar permissões em um endpoint de serviço de modelos.
Criar um endpoint
- Serving UI
- REST API
- MLflow Deployments SDK
- Workspace Client
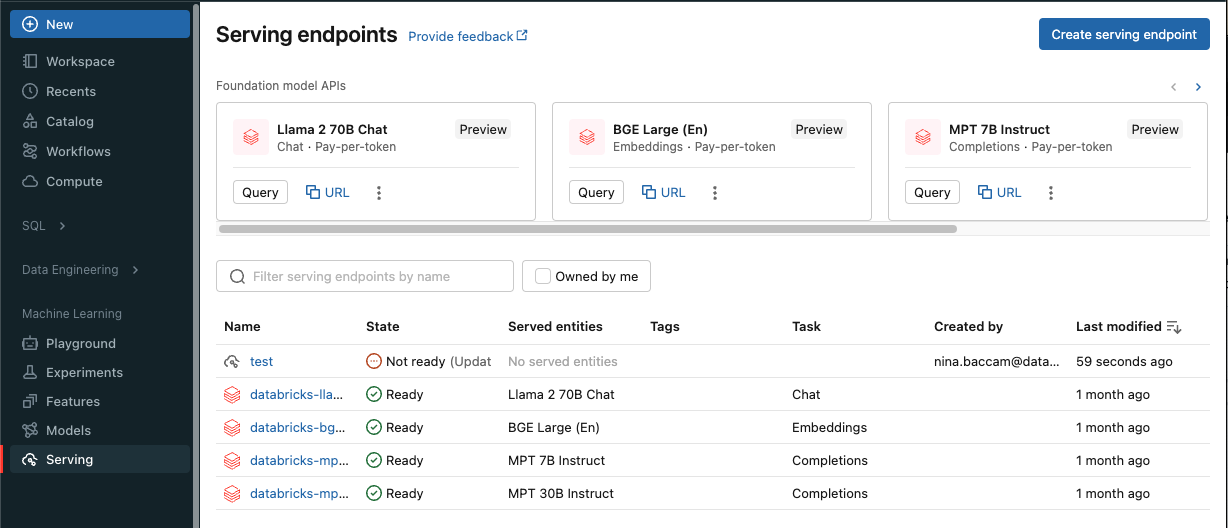
O senhor pode criar um endpoint para servir o modelo com a Serving UI.
-
Clique em Serving na barra lateral para exibir a Serving UI.
-
Clique em Criar endpoint de serviço .
Para modelos no Unity Catalog (recomendado) ou o legado Workspace Model Registry:
-
No campo Name (Nome ), forneça um nome para seu endpoint.
- Os nomes de endpoints não podem usar o prefixo
databricks-. Este prefixo é reservado para endpoints pré-configurados Databricks .
- Os nomes de endpoints não podem usar o prefixo
-
Na seção Entidades atendidas
-
Clique no campo Entidade para abrir o formulário Selecionar entidade servida .
-
Selecione " Meus modelos Unity Catalog ou "Meus modelos Model Registry dependendo de onde seu modelo está registrado. O formulário é atualizado dinamicamente com base na sua seleção.
- Nem todos os modelos são modelos personalizados. Os modelos podem ser modelos de base ou recursos para Feature Serving.
-
Selecione qual modelo e versão do modelo você deseja servir.
-
Selecione a porcentagem de tráfego a ser direcionada para seu modelo atendido.
-
Selecione qual tamanho de compute usar. É possível usar computes de CPU ou GPU para suas cargas de trabalho. Consulte tipo de compute para tipos de carga de trabalho disponíveis, incluindo as opções
CPU_MEDIUMeCPU_LARGEpara modelos que precisam de mais memória do que o tipo padrãoCPU. Para exemplos de código GPU, consulte tipos de carga de trabalho de GPU. -
Em "Compute Escalate Out" , selecione o tamanho do compute Escalate Out" que corresponde ao número de solicitações que este modelo de serviço pode processar simultaneamente. Esse número deve ser aproximadamente igual a QPS x tempo de execução do modelo. Para configurações compute definidas pelo cliente, consulte limites do modelo de serviço.
- Os tamanhos disponíveis são pequeno para 0 a 4 solicitações, médio para 8 a 16 solicitações e grande para 16 a 64 solicitações.
-
Especifique se o endpoint deve ser zerado quando não estiver em uso. A escalabilidade para zero não é recomendada para endpoints de produção, pois a capacidade não é garantida quando reduzida a zero. Quando um endpoint escala para zero, há uma latência adicional, também conhecida como inicialização a frio, enquanto o endpoint volta a escalar para atender às solicitações.
-
Em Configuração avançada, você pode:
- Renomeie a entidade servida para personalizar a forma como ela aparece no endpoint.
- Adicione um instance profile para se conectar ao AWS recurso de seu endpoint.
- Adicione variável de ambiente para se conectar ao recurso de seu endpoint ou log seu recurso procure DataFrame na tabela de inferência do endpoint. O registro da pesquisa de recurso DataFrame requer MLflow 2.14.0 ou acima.
-
(Opcional) Para adicionar entidades adicionais ao seu endpoint, clique em Adicionar entidade e repita os passos de configuração acima. Você pode disponibilizar vários modelos ou versões de modelos a partir de um único endpoint e controlar a divisão do tráfego entre eles. Consulte servir vários modelos para obter mais informações.
-
-
Na seção Otimização de rotas , você pode habilitar a otimização de rotas para seu endpoint. Recomenda-se a otimização de rotas para endpoints com alta demanda de QPS e Taxa de transferência. Consulte Otimização de rotas no ponto de extremidade de serviço.
-
Na seção **AI Gateway**, é possível selecionar quais recursos de governança habilitar em seu endpoint. Consulte Governança de AI com o Unity AI Gateway.
-
Clique em Criar . A página Serving endpoint é exibida com o estado Serving endpoint mostrado como Not Ready.
O senhor pode criar um endpoint usando o site REST API. Consulte POST /api/2.0/serving-endpoint para os parâmetros de configuração do endpoint.
O exemplo a seguir cria um endpoint que serve a terceira versão do modelo my-ads-model que está registrado no registro de modelo do Unity Catalog . Para especificar um modelo do Unity Catalog, forneça o nome completo do modelo, incluindo o catálogo pai e o esquema, como, catalog.schema.example-model. Este exemplo usa concorrência definida pelo usuário com min_provisioned_concurrency e max_provisioned_concurrency. Os valores de concorrência devem ser múltiplos de 4.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
Veja a seguir um exemplo de resposta. O estado config_update do endpoint é NOT_UPDATING e o modelo servido está em um estado READY.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow O Deployments fornece um API para tarefas de criação, atualização e exclusão. O APIs para essas tarefas aceita os mesmos parâmetros que o REST API para atender ao endpoint. Consulte POST /api/2.0/serving-endpoint para os parâmetros de configuração do endpoint.
O exemplo a seguir cria um endpoint que serve a terceira versão do modelo my-ads-model que está registrado no registro de modelo do Unity Catalog . Você deve fornecer o nome completo do modelo, incluindo o catálogo pai e o esquema, como, catalog.schema.example-model. Este exemplo usa concorrência definida pelo usuário com min_provisioned_concurrency e max_provisioned_concurrency. Os valores de concorrência devem ser múltiplos de 4.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
O exemplo a seguir mostra como criar um endpoint usando o SDK do cliente do Databricks Workspace.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
Você também pode:
- Ative as tabelas de inferência para capturar automaticamente as solicitações de entrada e as respostas de saída para seu endpoint de modelo de serviço.
- Se as tabelas de inferência estiverem ativadas no seu endpoint, o senhor poderá log a pesquisa de recurso DataFrame para a tabela de inferência.
Você também pode:
- Adicionar um perfil de instância a um endpoint de serviço de modelo
- Configure o acesso aos recursos de endpoints de serviço de modelo
Tipos de carga de trabalho de GPU
A implementação da GPU é compatível com as seguintes versões do pacote:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 e acima
Os exemplos a seguir mostram como criar um endpoint de GPU usando diferentes métodos.
- Serving UI
- REST API
- MLflow Deployments SDK
- Workspace Client
Para configurar seu endpoint para cargas de trabalho de GPU com a interface de usuário Serving , selecione o tipo de GPU desejado na dropdown Tipo de computação ao criar seu endpoint. Siga os mesmos passos descritos em Criar um endpoint, mas selecione um tipo de carga de trabalho de GPU em vez de CPU.
Para implantar seus modelos usando GPUs, inclua o campo workload_type na configuração do seu endpoint .
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
O exemplo a seguir mostra como criar um endpoint de GPU usando o SDK de Implantações do MLflow.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
O exemplo a seguir mostra como criar um endpoint de GPU usando o SDK do cliente Databricks Workspace.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
Os tipos de carga de trabalho de GPU disponíveis dependem do seu provedor de cloud, conforme resumido na tabela a seguir.
Tipo de carga de trabalho da GPU | Instância de GPU | Memória GPU |
|---|---|---|
| 1xT4 | 16GB |
| 1 x A10g | 24 GB |
| 4xA10G | 96 GB |
| 8xA10g | 192 GB |
Em endpoints de GPU, o valor de concorrência determina o número de réplicas alocadas para servir o seu modelo. O número de réplicas é igual ao valor de concorrência dividido por 4. Por exemplo, definir min_provisioned_concurrency como 12 provisiona 3 réplicas.
Modificar um endpoint de modelo personalizado
Depois de ativar um modelo personalizado endpoint, o senhor pode atualizar a configuração do compute conforme desejar. Essa configuração é particularmente útil se o senhor precisar de recurso adicional para o seu modelo. O tamanho da carga de trabalho e a compute configuração key do site desempenham um papel importante em quais recursos são alocados para atender ao seu modelo.
As atualizações de configuração e de entidades atendidas revalidam a associação ao workspace do criador registrada no endpoint e as concessões por entidade atendida. Confirme se ambas as opções ainda são válidas antes de enviar uma atualização; consulte Identidade e acesso.
Para evitar falhas na atualização:
- Utilize uma entidade de serviço de longa duração, pertencente à sua equipe, como criadora do endpoint.
- Não utilize uma user account pessoal que possa ser desativada ou removida do workspace posteriormente.
- O criador registrado deve permanecer um membro do workspace durante toda a vida útil do endpoint.
As atualizações na configuração do endpoint podem falhar. Quando ocorrem falhas, a configuração ativa existente permanece efetiva como se a atualização não tivesse ocorrido.
Verifique se a atualização foi aplicada com sucesso, revisando o status do seu endpoint.
Até que a nova configuração esteja pronta, a configuração antiga continua fornecendo tráfego de previsão. Enquanto houver uma atualização em andamento, outra atualização não poderá ser feita. No entanto, você pode cancelar uma atualização em andamento na Serving UI.
- Serving UI
- REST API
- MLflow Deployments SDK
Depois que o senhor habilitar um modelo endpoint, selecione Edit endpoint para modificar a configuração compute do seu endpoint.
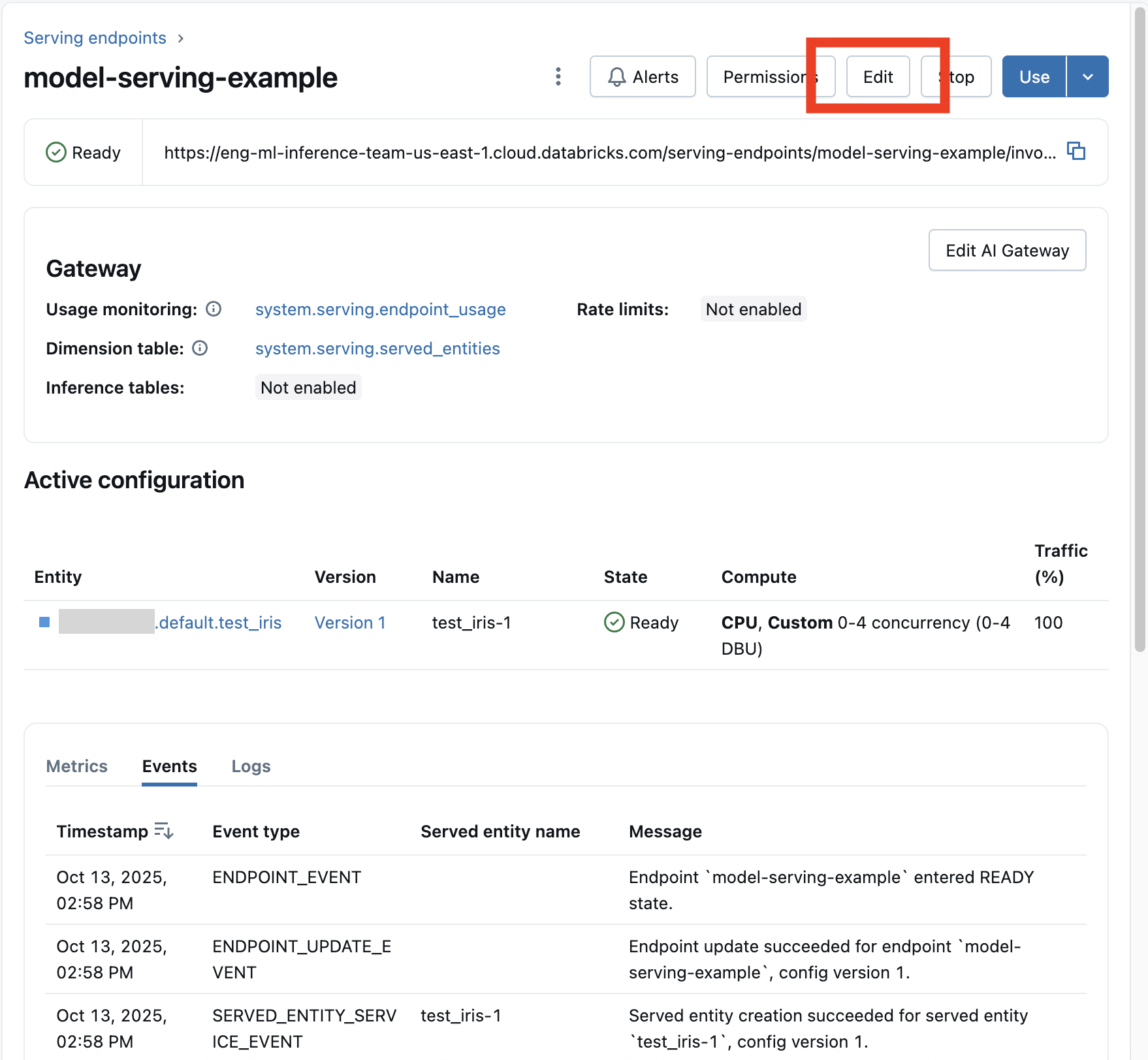
Você pode alterar a maioria dos aspectos da configuração do endpoint, exceto o nome do endpoint e certas propriedades imutáveis.
Você pode cancelar uma atualização de configuração em andamento selecionando "Cancelar atualização" na página de detalhes do endpoint.
A seguir, um exemplo de atualização de configuração de endpoint usando a API REST. Consulte PUT /api/2.0/serving-endpoint/{{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
O MLflow Deployments SDK usa os mesmos parâmetros que o REST API, consulte PUT /api/2.0/serving-endpoint/{name}/config para obter detalhes do esquema de solicitação e resposta.
O exemplo de código a seguir usa um modelo do site Unity Catalog registro de modelo:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.update_endpoint_config(
endpoint=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Pontuação de um modelo endpoint
Para pontuar seu modelo, envie solicitações para o servindo modelo endpoint.
- Consulte Ponto de extremidade de serviço de consulta para modelos personalizados.
- Consulte Usar modelos de base.
Recurso adicional
- gerenciar servindo o modelo endpoint.
- Modelos externos em modelo de atividade.
- Se preferir usar Python, o senhor pode usar o Python SDK de serviço em tempo real da Databricks.
Notebook exemplos
O Notebook a seguir inclui diferentes Databricks modelos registrados que o senhor pode usar para começar a trabalhar com o endpoint modelo servindo. Para obter exemplos adicionais, consulte o tutorial: implantar e consultar um modelo personalizado.
Os exemplos de modelos podem ser importados para o site workspace seguindo as instruções em Import a Notebook. Depois de escolher e criar um modelo a partir de um dos exemplos, registre-o em Unity Catalog e siga as etapas do fluxo de trabalho da interface do usuário para servir o modelo.