Depurar timeouts do modelo de serviço
Este artigo descreve os diferentes tempos limite que o senhor pode encontrar ao usar o endpoint do modelo servindo e como lidar com eles. Ele abrange os tempos limite de implantação do modelo, os tempos limite do lado do servidor e os tempos limite do lado do cliente.
Tempos limite de implantação do modelo
Ao implantar um modelo ou atualizar uma implantação existente usando o Servindo Modelo, o processo pode expirar por diversos motivos. A tab Eventos da página endpoint do modelo de serviço registra mensagens de tempo limite. Pesquise por "tempo limite excedido" para encontrá-los.
O processo de implementação atinge o tempo limite se a construção do contêiner e a implementação do modelo excederem uma determinada duração que depende da configuração da carga de trabalho do endpoint. Verifique sua configuração antes da implantação e compare-a com implantações anteriores bem-sucedidas.
A construção do contêiner não tem limite rígido, mas tenta novamente até 3 vezes. A implantação após a criação do contêiner aguardará até 30 minutos para cargas de trabalho de CPU, 60 minutos para cargas de trabalho pequenas ou médias de GPU e 120 minutos para cargas de trabalho grandes de GPU antes de expirar.
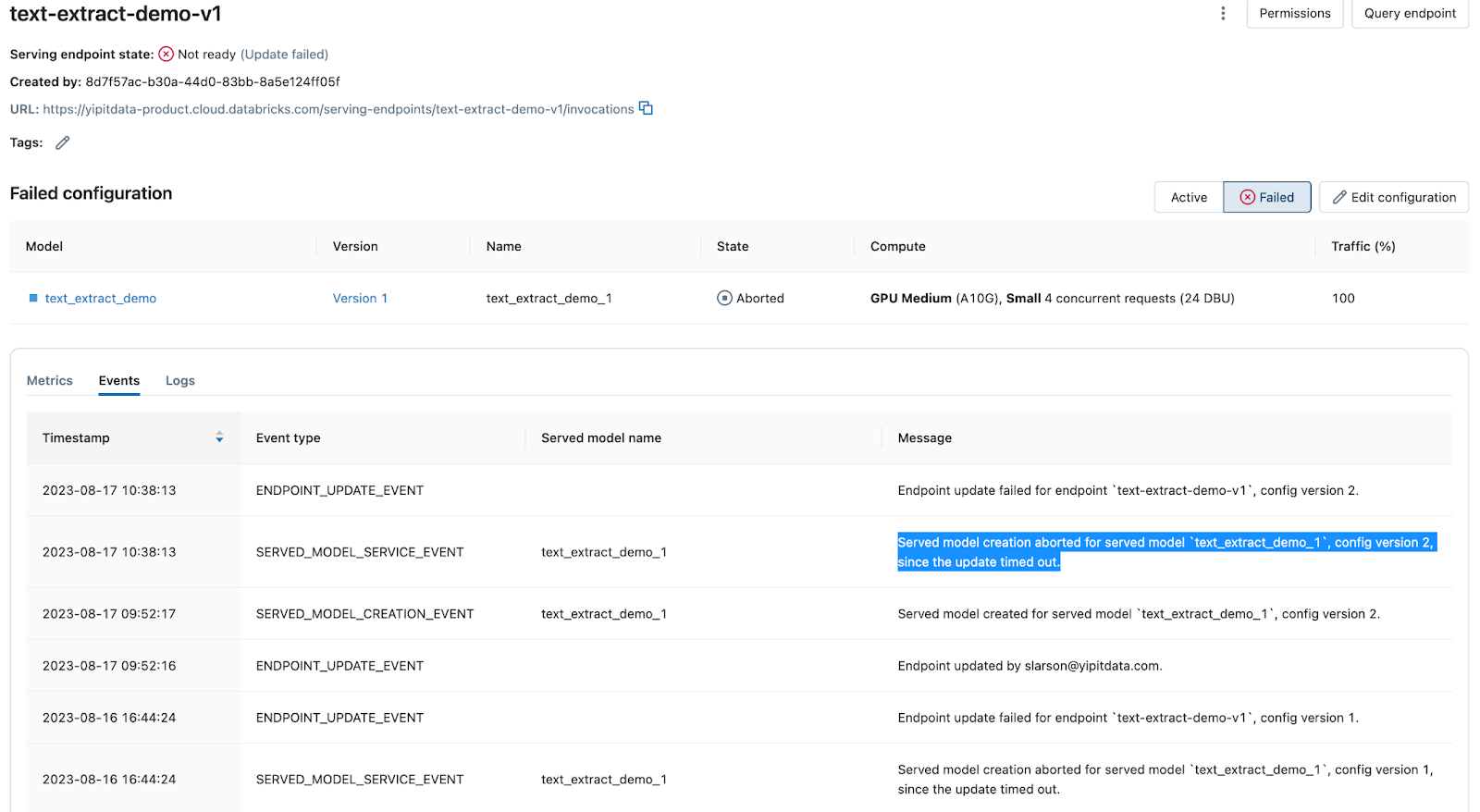
Se o senhor encontrar uma mensagem "timed out" , navegue até os logs tab e examine a compilação logs para determinar a causa. Os exemplos incluem problemas de dependência de biblioteca, restrições de recurso, problemas de configuração e assim por diante.
Consulte a seção Depurar após falha na criação do contêiner.
Tempos limite do lado do servidor
Se o seu endpoint estiver íntegro de acordo com a guia Events and logs do seu servidor endpoint, mas o senhor tiver timeouts quando fizer chamadas para o endpoint, o timeout pode estar no lado do servidor. O tempo limite do default varia de acordo com o tipo de modelo de serviço endpoint. A tabela a seguir mostra os tempos limite do servidor default para solicitações enviadas ao endpoint servindo modelo.
Tipo de endpoint | Limite de tempo limite da solicitação (segundos) | Notas |
|---|---|---|
Ponto de extremidade de serviço de CPU ou GPU | padrão 597 | Esse limite não pode ser aumentado. |
Foundation servindo modelo endpoint | padrão 597 | Esse limite não pode ser aumentado. |
Para determinar se o senhor teve um tempo limite do lado do servidor, verifique se as solicitações estão atingindo o tempo limite antes ou depois dos limites listados acima.
- Se sua solicitação falhar consistentemente no limite, é provável que seja um tempo limite do lado do servidor.
- Se sua solicitação falhar antes do limite, pode ser devido a problemas de configuração.
- Verifique o serviço logs para determinar se há outros erros.
- Confirme se o modelo funcionou localmente, como em um Notebook, ou em solicitações anteriores em versões anteriores.
Tempo limite do lado do cliente: Configuração do MLflow
Os tempos limite do lado do cliente normalmente retornam mensagens de erro que dizem que " expirou " ou 4xx Bad Request. As causas comuns desses tempos limite são as configurações de MLflow variável de ambiente. A seguir, os mais comuns MLflow variável de ambiente para timeouts. Para ver a lista completa de variáveis de tempo limite, consulte a documentação mlflow.environment_variables.
- MLFLOW_HTTP_REQUEST_TIMEOUT : Especifica o tempo limite em segundos para as solicitações HTTP do MLflow. tempo limite padrão de 120 segundos.
- MLFLOW_HTTP_REQUEST_MAX_RETRIES : Especifica o número máximo de novas tentativas com backoff exponencial para solicitações HTTP do MLflow. O padrão é 7 segundos.
Os tempos limite das solicitações HTTP no lado do cliente estão definidos para 120 segundos, o que difere do tempo limite default do lado do servidor, de 597 segundos, para o endpoint de atendimento de CPU e GPU. Ajuste a variável de ambiente MLflow de acordo com a sua previsão de que a carga de trabalho excederá o tempo limite de 120 segundos do lado do cliente.
Execute uma das seguintes ações para determinar se o tempo limite é causado por uma configuração de variável de ambiente do MLflow:
-
Teste o modelo localmente usando entradas de amostra, como em um Notebook, para confirmar que ele funciona conforme o esperado antes de registrar o modelo e implantá-lo.
- Examine o tempo necessário para processar as solicitações.
- Se as solicitações demorarem mais do que o tempo limite default para MLflow variável de ambiente ou se o senhor receber uma mensagem de "timed out" no Notebook. O exemplo " atingiu o tempo limite da mensagem " :
Timed out while evaluating the model. Verify that the model evaluates within the timeout.
- Examine o tempo necessário para processar as solicitações.
-
Teste o modelo de serviço endpoint usando solicitações POST.
- Verifique os logs de serviço do seu endpoint ou as tabelas de inferência, se o senhor as tiver ativado.
- Para obter detalhes sobre o esquema da tabela de inferência, consulte Esquema da tabela de inferência habilitado para Unity AI Gateway.
- Verifique os logs de serviço do seu endpoint ou as tabelas de inferência, se o senhor as tiver ativado.
Configurar MLflow variável de ambiente
Configure o MLflow variável de ambiente usando a UI do Serving ou programaticamente usando o Python.
- Serving UI
- Python
O senhor pode configurar a variável de ambiente para uma implantação de modelo
- Selecione o endpoint para o qual o senhor deseja configurar uma variável de ambiente.
- Na página do endpoint, selecione Edit (Editar ) no canto superior direito.
- Em "Entity Details" , expanda Advanced configuration (Configuração avançada ) para adicionar a variável de ambiente de tempo limite do MLflow relevante.
O senhor pode configurar programaticamente um modelo de serviço endpoint e incluir MLflow variável de ambiente ajustado usando Python. O exemplo a seguir ajusta o tempo limite máximo para 300 segundos e o número máximo de tentativas para três.
Para obter mais detalhes sobre a carga útil para configurar isso, consulte a página da API do Databricks.
import mlflow.deployments
# Get the deployment client
client = mlflow.deployments.get_deploy_client("databricks")
# Define the configuration with environment variables
config = {
"served_entities": [
{
"name": "sklearn_example-1",
"entity_name": "catalog.schema.model_name",
"entity_version": "1",
"workload_size": "Small",
"workload_type": "CPU",
"scale_to_zero_enabled": True,
"environment_vars": {
"MLFLOW_HTTP_REQUEST_MAX_RETRIES": 3,
"MLFLOW_HTTP_REQUEST_TIMEOUT": 300
}
},
],
"traffic_config": {
"routes": [
{
"served_model_name": "model_name-1",
"traffic_percentage": 100
}
]
}
}
# Create the endpoint with the specified configuration
endpoint = client.create_endpoint(
name="model_name-1",
config=config
)
Tempo limite no lado do cliente: APIs de clientes de terceiros
Os tempos limite do lado do cliente normalmente retornam mensagens de erro que dizem que " expirou " ou 4xx Bad Request. Semelhante às configurações do MLflow, as APIs de clientes de terceiros podem causar timeouts no lado do cliente, dependendo de sua configuração. Isso pode afetar o endpoint do modelo de serviço que consiste em um pipeline que usa esse cliente de terceiros APIs. Veja modelos personalizados do PyFunc e agentes de esquema personalizados do PyFunc.
Semelhante às instruções de depuração da configuração do MLflow, faça o seguinte para determinar se o tempo limite é causado por APIs de clientes de terceiros usadas no pipeline do modelo:
-
Teste o modelo localmente com entradas de amostra em um Notebook.
- Se o senhor vir uma mensagem "timed out" no Notebook, ajuste todos os parâmetros relevantes para a janela de tempo limite do cliente de terceiros.
- O exemplo " atingiu o tempo limite da mensagem " :
APITimeoutError: Request timed out.
-
Teste o modelo de serviço endpoint usando solicitações POST.
- Verifique os logs de serviço do seu endpoint ou as tabelas de inferência, se o senhor as tiver ativado.
- Para obter detalhes sobre o esquema da tabela de inferência, consulte Esquema da tabela de inferência habilitado para Unity AI Gateway.
- Verifique os logs de serviço do seu endpoint ou as tabelas de inferência, se o senhor as tiver ativado.
Exemplo de cliente OpenAI
Ao estabelecer um cliente OpenAI, você pode configurar o parâmetro timeout para alterar o tempo máximo antes que uma solicitação expire no lado do cliente. O default e o tempo limite máximo para um cliente OpenAI é de 10 minutos.
O exemplo a seguir mostra como configurar um tempo limite de APIs de clientes de terceiros.
%pip install openai==1.54.0
dbutils.library.restartPython()
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
client = OpenAI(
timeout=10, # Number of seconds before client times out
api_key=DATABRICKS_TOKEN,
base_url="<WORKSPACE_URL>/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Tell me about Large Language Models."
}
],
model="model_name",
max_tokens=256
)
Para o cliente OpenAI, o senhor pode contornar a janela de tempo limite máximo ativando a transmissão.
Outros tempos limite
aquecimento do ponto final parado
Se um endpoint for reduzido a zero e receber uma solicitação para inicializá-lo, poderá levar a um tempo limite do lado do cliente se a inicialização demorar muito. Isso pode causar timeouts em pipelines que utilizam etapas como chamadas para endpoints de taxa de transferência provisionada ou índices de pesquisa de AI, conforme mencionado acima.
Tempo limite de conexão
Os tempos limite de conexão estão relacionados ao tempo que um cliente espera para estabelecer uma conexão com o servidor. Se a conexão não for estabelecida dentro desse período, o cliente cancela a tentativa. É importante estar ciente dos clientes usados em seu modelo pipeline e verificar o serviço logs e as tabelas de inferência do modelo de serviço endpoint para verificar se há algum tempo limite de conexão. As mensagens variam de acordo com o serviço.
-
Por exemplo, um SocketTimeout (para um serviço de leitura/gravação em um SQL endpoint por meio de uma conexão JDBC ) pode ter a seguinte aparência:
jdbc:spark://<server-hostname>:443;HttpPath=<http-path>;TransportMode=http;SSL=1[;property=value[;property=value]];SocketTimeout=300
-
Para encontrá-las, procure mensagens de erro contendo o termo " timed out " ou *** " timeout " ***.
Limites de taxa
Várias solicitações feitas acima do limite de taxa de um endpoint podem levar à falha de solicitações adicionais. Consulte limites de recurso e de carga útil para ver os limites de taxa com base nos tipos de endpoint. Para clientes de terceiros, a Databricks recomenda que o senhor examine a documentação do cliente de terceiros que estiver usando.