Avaliar e monitorar agentes AI
MLflow fornece recursos abrangentes de avaliação de agentes e avaliação LLM para ajudar você a medir, melhorar e manter a qualidade de seus aplicativos AI . O MLflow oferece suporte a todo o ciclo de vida de desenvolvimento, desde os testes até o monitoramento da produção para LLMs, agentes, sistemas RAG ou outros aplicativos GenAI.
Avaliar agentes AI e LLMs é mais complexo do que a avaliação de modelos ML tradicionais. Essas aplicações envolvem múltiplos componentes, conversas multifacetadas e critérios de qualidade diferenciados. Tanto as métricas qualitativas quanto as quantitativas exigem abordagens de avaliação especializadas para avaliar o desempenho com precisão.
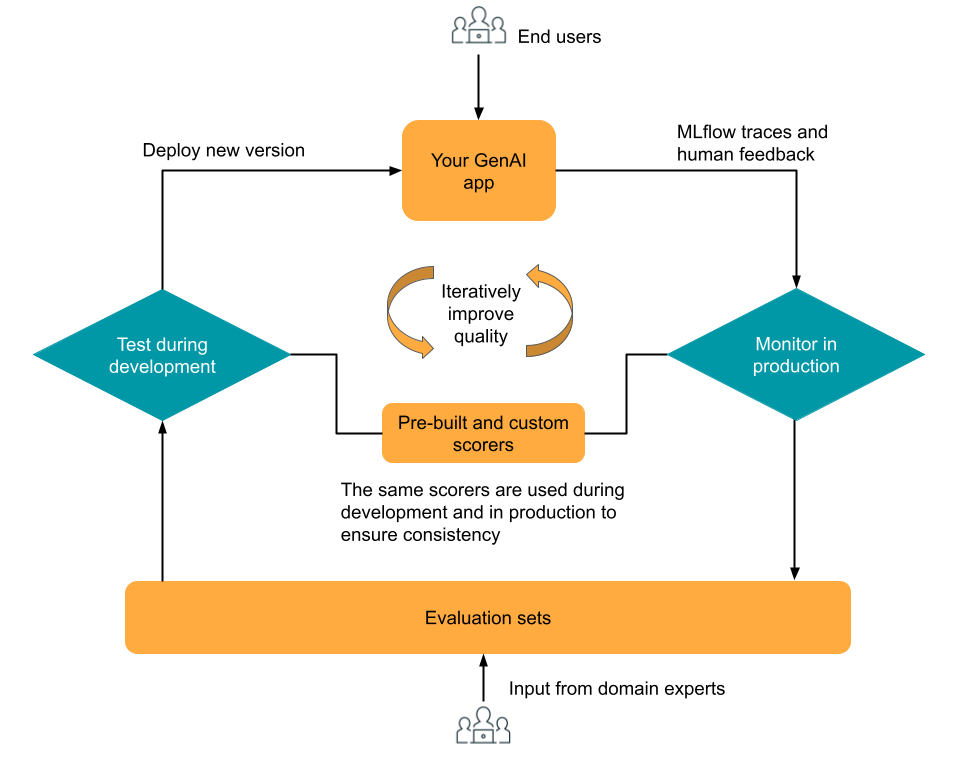
O componente de avaliação e monitoramento do MLflow 3 foi projetado para ajudá-lo a otimizar iterativamente a qualidade do seu aplicativo GenAI. A avaliação e o monitoramento são baseados no MLflow Tracing, que fornece registro de rastreamento em tempo real nas fases de desenvolvimento, teste e produção. Os rastreamentos podem ser avaliados durante o desenvolvimento usando avaliadores e pontuadoresLLM integrados ou personalizados, e o monitoramento de produção pode reutilizar os mesmos avaliadores e pontuadores, garantindo uma avaliação consistente ao longo do ciclo de vida do aplicativo. Especialistas da área podem fornecer feedback usando um aplicativo de revisão integrado para coletar opiniões de pessoas, gerando dados de avaliação para iterações futuras.
O diagrama mostra esse fluxo de trabalho iterativo de alto nível.
Recurso | Descrição |
|---|---|
Execução: um notebook de demonstração rápida que apresenta a avaliação MLflow usando um aplicativo GenAI simples. | |
o passo por um tutorial do fluxo de trabalho de avaliação completo, utilizando um aplicativo RAG simulado. Utilize o conjunto de dados de avaliação e os juízes LLM para avaliar a qualidade, identificar problemas e aprimorar seu aplicativo de forma iterativa. | |
Defina métricas de qualidade para seu aplicativo usando juízes LLM integrados, juízes LLM personalizados e avaliadores personalizados. Utilize as mesmas métricas tanto para o desenvolvimento quanto para a produção. | |
Teste sua aplicação GenAI no conjunto de dados de avaliação, utilizando avaliadores e juízes LLM . Compare versões de aplicativos, acompanhe melhorias e compartilhe resultados. | |
Avalie a qualidade de conversas com múltiplas interações utilizando ferramentas especializadas para avaliar a completude da conversa, a frustração do usuário e a coerência do diálogo. | |
Gere conversas sintéticas com múltiplas interações para testar agentes AI conversacionais em diversos cenários e comportamentos de usuários. | |
Avaliadores de execução e juízes LLM automáticos em seus rastreamentos de aplicativos GenAI de produção para monitorar continuamente a qualidade. | |
Use o aplicativo Review para coletar feedback de especialistas e criar um conjunto de dados de avaliação. | |
Use linguagem natural para revisar as pontuações das avaliações, inspecionar o conjunto de dados de avaliação, verificar os avaliadores agendados e obter ajuda para configurar |
A Avaliação do Agente é integrada ao gerenciar MLflow 3. Os métodos SDK de Avaliação do Agente agora estão disponíveis usando o mlflow[databricks]>=3.1 SDK. Consulte Migrar para o MLflow 3 da Avaliação do Agente para atualizar seu código de Avaliação do Agente do MLflow 2 para usar o MLflow 3.