Construindo o conjunto de dados de avaliação MLflow
Para testar e melhorar sistematicamente um aplicativo de GenAI, use um dataset de avaliação. Um dataset de avaliação é um conjunto selecionado de entradas de exemplo, rotuladas (com saídas esperadas conhecidas) ou não rotuladas (sem respostas de verdade fundamental). Os datasets de avaliação ajudam a melhorar o desempenho do seu aplicativo das seguintes maneiras:
- Melhore a qualidade testando as correções em exemplos problemáticos conhecidos da produção.
- Evitar regressões. Crie um "conjunto de ouro" de exemplos que devem sempre funcionar corretamente.
- Comparar versões de aplicativos. Teste diferentes prompts, modelos ou lógicas de aplicativos com os mesmos dados.
- Direcione o recurso específico. Criar conjuntos de dados especializados para segurança, conhecimento do domínio ou casos extremos.
- Validar o aplicativo em diferentes ambientes como parte do LLMOps.
Os conjuntos de dados de avaliação MLflow são armazenados no Unity Catalog, que oferece controle de versão, linhagem, compartilhamento e governança integrados.
Requisitos
- Para criar um dataset de avaliação, você deve ter permissões
CREATE TABLEem um esquema Unity Catalog . - Um dataset de avaliação está anexado a um experimento MLflow . Se você ainda não tem um experimento, consulte Criar um experimento do MLflow para criar um.
fonte de dados para conjunto de dados de avaliação
Você pode usar qualquer uma das seguintes opções para criar um dataset de avaliação:
- Vestígios existentes. Se você já capturou rastros de um aplicativo GenAI, pode usá-los para criar um dataset de avaliação baseado em cenários do mundo real.
- Um dataset existente ou exemplos inseridos diretamente. Essa opção é útil para prototipagem rápida ou para testes direcionados de recursos específicos.
- Dados sintéticos. O Databricks pode gerar automaticamente um conjunto de avaliação representativo a partir de seus documentos, permitindo que você avalie rapidamente seu agente com uma boa cobertura de casos de teste.
Esta página descreve como criar um dataset de avaliação MLflow . Você também pode usar outros tipos de conjuntos de dados, como DataFrames Pandas ou uma lista de dicionários. Veja exemplos de avaliação do MLflow para GenAI .
Crie um dataset usando a interface do usuário.
Siga estes passos para usar a interface do usuário para criar um dataset a partir de rastreamentos existentes. Para obter informações de referência, consulte UI dataset de avaliação MLflow.
-
Clique em Experimentos na barra lateral para exibir a página de Experimentos.
-
Clique no nome do seu experimento para abri-lo.
-
Na barra lateral esquerda, clique em Vestígios .
-
Use as caixas de seleção no lado esquerdo da lista de rastreamento para selecionar os rastreamentos que deseja adicionar. Para selecionar todos os rastreamentos na página atual, clique na caixa de seleção ao lado de ID do rastreamento no cabeçalho da coluna.
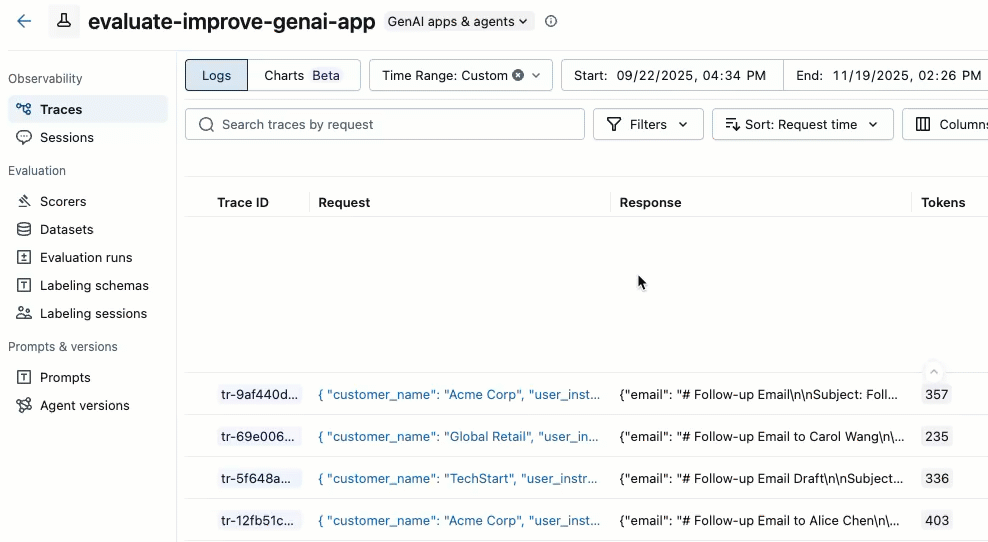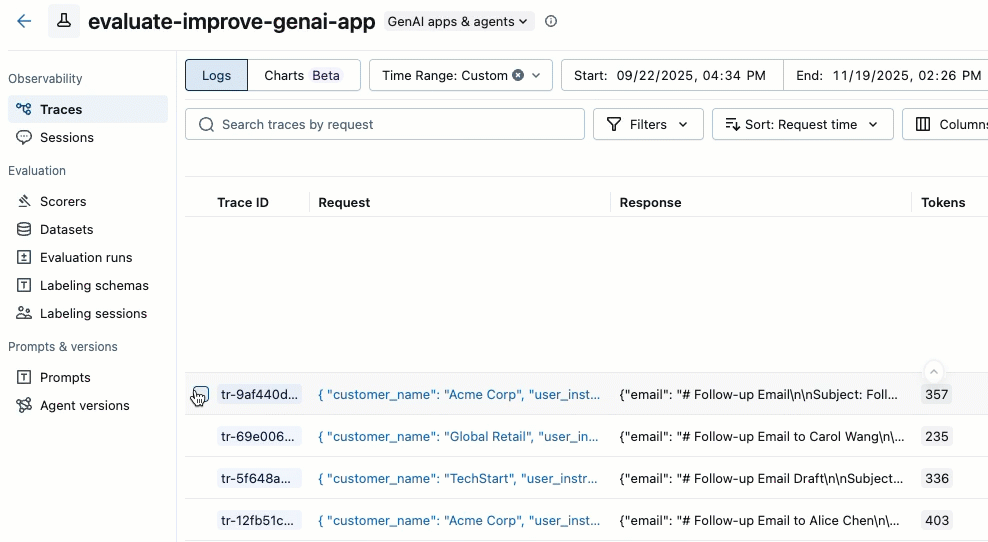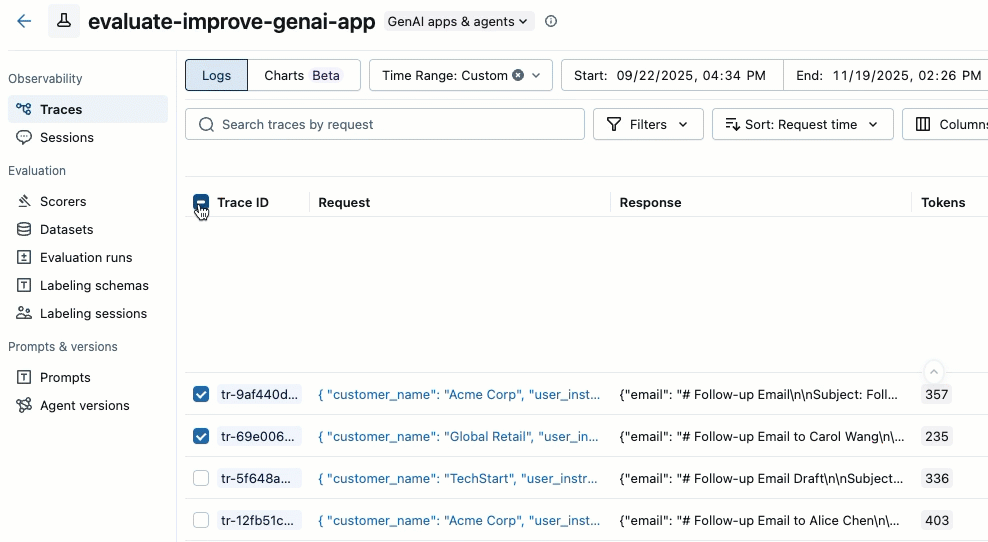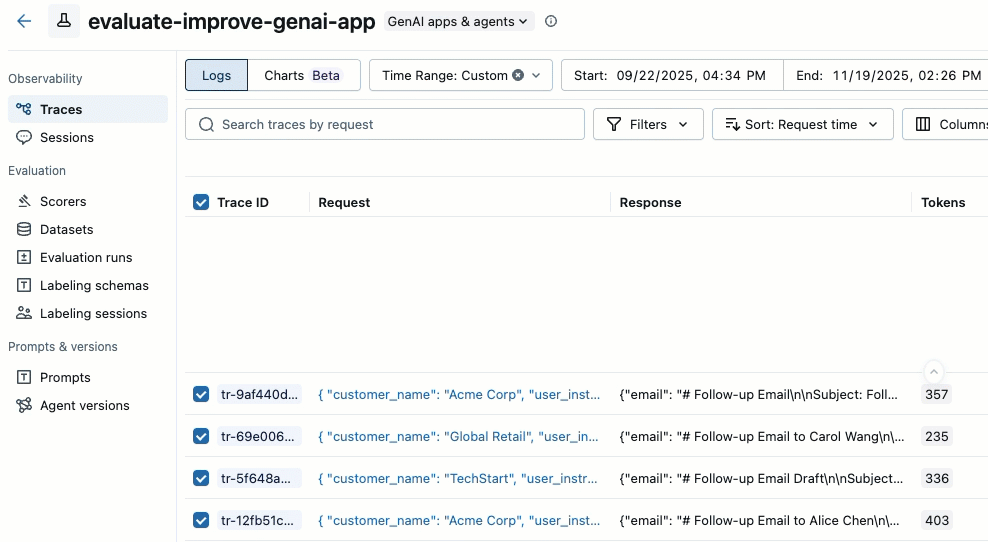
-
Ações de clique. O rótulo do botão mostra o número de rastros selecionados, por exemplo , Ações (3) .
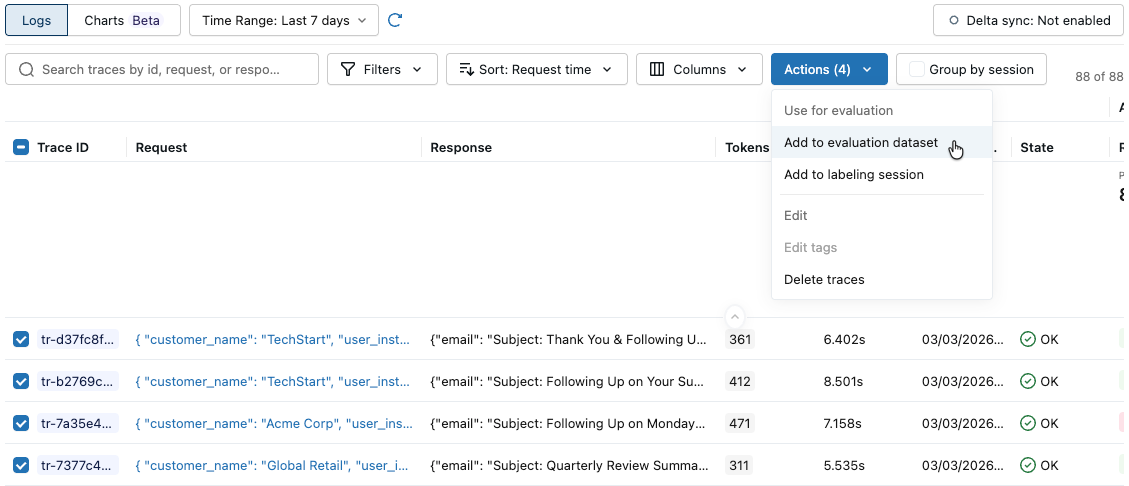
-
Em " Usar para avaliação" , selecione " Adicionar ao datasetde avaliação" . A caixa de diálogo Adicionar traços ao datasetde avaliação é aberta.
-
Se não existir um conjunto de dados de avaliação para este experimento, ou se você quiser adicionar traços a um novo dataset, siga estes passos para criar um novo dataset de avaliação:
- Clique em Criar novo dataset .
- Selecione o esquema Unity Catalog para armazenar o novo dataset.
- Insira um nome para o dataset e clique em Criar conjunto de dados .
- Clique em Exportar e depois em Concluído .
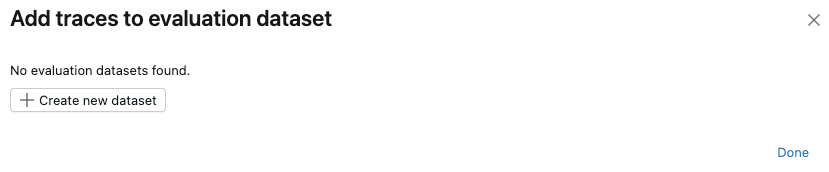
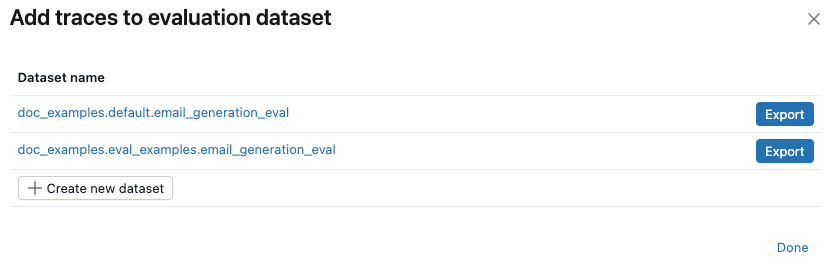
Se já existir um conjunto de dados de avaliação para o experimento, clique em Exportar à direita do dataset ao qual deseja adicionar os traços. Você pode exportar para mais de um dataset. Quando terminar de exportar, clique em Concluído .
Crie um dataset usando o SDK
Siga estes passos para usar o SDK para criar um dataset. Para informações de referência, consulte Referência dataset de avaliação.
o passo 1. Criar o dataset
import mlflow
import mlflow.genai.datasets
import time
from databricks.connect import DatabricksSession
# 0. If you are using a local development environment, connect to Serverless Spark which powers MLflow's evaluation dataset service
spark = DatabricksSession.builder.remote(serverless=True).getOrCreate()
# 1. Create an evaluation dataset
# Replace with a Unity Catalog schema where you have CREATE TABLE permission
uc_schema = "workspace.default"
# This table will be created in the above UC schema
evaluation_dataset_table_name = "email_generation_eval"
eval_dataset = mlflow.genai.datasets.create_dataset(
name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"Created evaluation dataset: {uc_schema}.{evaluation_dataset_table_name}")
a etapa 2: Adicione registros ao seu dataset
Esta seção descreve várias opções para adicionar registros ao dataset de avaliação.
- From existing traces
- From domain expert labels
- Build from scratch or import existing
- Seed using synthetic data
- For conversation simulation
Uma das maneiras mais eficazes de criar uma avaliação relevante dataset é selecionar exemplos diretamente das interações históricas do seu aplicativo capturadas por MLflow Tracing. O senhor pode criar um conjunto de dados a partir de traços usando a UI de monitoramento MLflow ou o SDK.
Pesquise programaticamente por rastros e adicione-os ao dataset usando search_traces(). Utilize filtros para identificar rastros por sucesso, falha, uso em produção ou outras propriedades. Consulte Rastreamentos de pesquisa programaticamente.
import mlflow
# 2. Search for traces
traces = mlflow.search_traces(
filter_string="attributes.status = 'OK'",
order_by=["attributes.timestamp_ms DESC"],
tags.environment = 'production',
max_results=10
)
print(f"Found {len(traces)} successful traces")
# 3. Add the traces to the evaluation dataset
eval_dataset = eval_dataset.merge_records(traces)
print(f"Added {len(traces)} records to evaluation dataset")
# Preview the dataset
df = eval_dataset.to_df()
print(f"\nDataset preview:")
print(f"Total records: {len(df)}")
print("\nSample record:")
sample = df.iloc[0]
print(f"Inputs: {sample['inputs']}")
Selecione os traços para o conjunto de dados de avaliação.
Antes de adicionar rastreamentos ao seu dataset, identifique quais rastreamentos representam casos de teste importantes para suas necessidades de avaliação. Você pode usar análises quantitativas e qualitativas para selecionar traços representativos.
Seleção quantitativa de traços
Utilize a interface de usuário ou o SDK do MLflow para filtrar e analisar rastreamentos com base em características mensuráveis:
- Na interface do MLflow : filtre por tags (ex.:
tag.quality_score < 0.7), pesquise entradas/saídas específicas, classifique por latência ou uso de tokens. - Programaticamente : consulte rastreamentos para realizar análises avançadas.
import mlflow
import pandas as pd
# Search for traces with potential quality issues
traces_df = mlflow.search_traces(
filter_string="tag.quality_score < 0.7",
max_results=100
)
# Analyze patterns
# For example, check if quality issues correlate with token usage
correlation = traces_df["span.attributes.usage.total_tokens"].corr(traces_df["tag.quality_score"])
print(f"Correlation between token usage and quality: {correlation}")
Para obter a sintaxe completa da consulta de rastreamento e exemplos, consulte Pesquisar rastreamentos programaticamente.
Seleção qualitativa de traços
Analise os rastros individuais para identificar padrões que exijam julgamento humano:
- Analise os fatores que levaram a resultados de baixa qualidade.
- Procure padrões em como seu aplicativo lidou com casos extremos.
- Identificar contexto ausente ou raciocínio falho
- Compare traços de alta e baixa qualidade para entender os fatores de diferenciação.
Após identificar os rastros representativos, adicione-os ao seu dataset usando os métodos de busca e merge descritos acima.
Enriqueça seus rastreamentos com resultados esperados ou indicadores de qualidade para permitir a comparação com a realidade. Veja a seção sobre como coletar feedback de especialistas da área para adicionar rótulos humanos.
Aproveite o feedback de especialistas da área, coletado em sessões de rotulagem MLflow para enriquecer seu conjunto de dados de avaliação com rotulagem de referência. Antes de realizar esses passos, siga o guia de coleta de feedback de especialistas do domínio para criar uma sessão de rotulagem.
import mlflow.genai.labeling as labeling
# Get a labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
# Sync from the labeling session to the dataset
all_sessions[0].sync(dataset_name=f"{uc_schema}.{evaluation_dataset_table_name}")
Após coletar feedback especializado, é possível alinhar os juízes para corresponder ao feedback humano. Consulte Alinhar juízes LLM com feedback humano.
O senhor pode importar um site existente dataset ou selecionar exemplos do zero. Seus dados devem corresponder (ou ser transformados para corresponder) ao esquema de avaliação dataset.
# Define comprehensive test cases
evaluation_examples = [
{
"inputs": {"question": "What is MLflow?"},
"expected": {
"expected_response": "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models.",
"expected_facts": [
"open source AI engineering platform",
"agents, LLMs, and ML models",
"experiment tracking",
"model deployment"
]
},
},
]
eval_dataset = eval_dataset.merge_records(evaluation_examples)
A geração de dados sintéticos pode expandir seus esforços de teste, criando rapidamente diversas entradas e abrangendo casos extremos. Consulte Sintetizar conjuntos de avaliação.
Para permitir testes reproduzíveis de múltiplas interações, use um código semelhante ao seguinte para armazenar casos de teste para simulação de conversação. Para obter documentação completa sobre como simular conversas com múltiplas interações, consulte Simulação de conversação.
from mlflow.genai.datasets import create_dataset, get_dataset
from mlflow.genai.simulators import ConversationSimulator
# Create a dataset for simulation test cases
dataset = create_dataset(
name="conversation_scenarios",
tags={"type": "simulation", "agent": "support-bot"},
)
# Define test cases with goals and personas
simulation_test_cases = [
{
"inputs": {
"goal": "Get help setting up experiment tracking",
"persona": "You are a data scientist new to MLflow",
},
},
{
"inputs": {
"goal": "Debug a model deployment error",
"persona": "You are a senior engineer who expects precise answers",
},
},
{
"inputs": {
"goal": "Understand model versioning best practices",
"persona": "You are building an ML platform for your team",
"context": {"team_size": "large", "compliance": "strict"},
},
},
]
dataset.merge_records(simulation_test_cases)
# Later, use the dataset with ConversationSimulator
dataset = get_dataset(name="conversation_scenarios")
simulator = ConversationSimulator(test_cases=dataset)
Atualizar conjunto de dados existente
Você pode usar a interface do usuário ou o SDK para atualizar um dataset de avaliação.
- Databricks UI
- MLflow SDK
Utilize a interface do usuário para adicionar registros a um dataset de avaliação existente.
-
Abra a página dataset no workspace Databricks :
- No workspace Databricks , navegue até o seu experimento.
- Na barra lateral à esquerda, clique em conjunto de dados .
- Clique no nome do dataset na lista.
-
Clique em Adicionar registro . Uma nova linha aparece com conteúdo genérico.
-
Edite a nova linha diretamente para inserir os dados e as expectativas para o novo registro. Opcionalmente, defina quaisquer tags para o novo registro.
-
Clique em Salvar alterações .
Utilize o SDK MLflow para atualizar um dataset de avaliação existente:
import mlflow.genai.datasets
import pandas as pd
# Load existing dataset
dataset = mlflow.genai.datasets.get_dataset(name="catalog.schema.eval_dataset")
# Add new test cases
new_cases = [
{
"inputs": {"question": "What are MLflow models?"},
"expectations": {
"expected_facts": ["model packaging", "deployment", "registry"],
"min_response_length": 100
}
}
]
# Merge new cases
dataset = dataset.merge_records(new_cases)
Limitações
- Datasets de avaliação não podem ser armazenados em catálogos criptografados com Chaves gerenciadas pelo cliente (CMK). Workspaces com CMK são compatíveis desde que o dataset seja armazenado em um catálogo que não usa CMK.
- Máximo de 2000 linhas por dataset de avaliação.
- Máximo de 20 expectativas por registro dataset .
Caso precise que alguma dessas limitações seja flexibilizada para o seu caso específico, entre em contato com seu representante da Databricks.
Recursos adicionais
- Avalie seu aplicativo - Use o recém-criado dataset para avaliação
- Crie avaliadores personalizados - Desenvolva avaliadores personalizados para o LLM para avaliar os resultados da sua candidatura.
- Alinhe os juízes com o feedback - Melhore continuamente suas avaliações alinhando os juízes com o feedback de especialistas.
- Rastreamento de consultas via SDK - Análise programática avançada de rastreamento para seleção de dataset