Exemplos de scorer baseados em código
No MLflow Evaluation for GenAI, pontuadores personalizados baseados em código permitem que você defina métricas de avaliação flexíveis para seu agente ou aplicativo AI . Este conjunto de exemplos e o exemplo complementar Notebook ilustram muitos padrões para usar pontuadores baseados em código com diferentes opções para entradas, saídas, implementação e tratamento de erros.
A imagem abaixo ilustra algumas saídas de pontuadores personalizados como métricas na interface do usuário do MLflow.
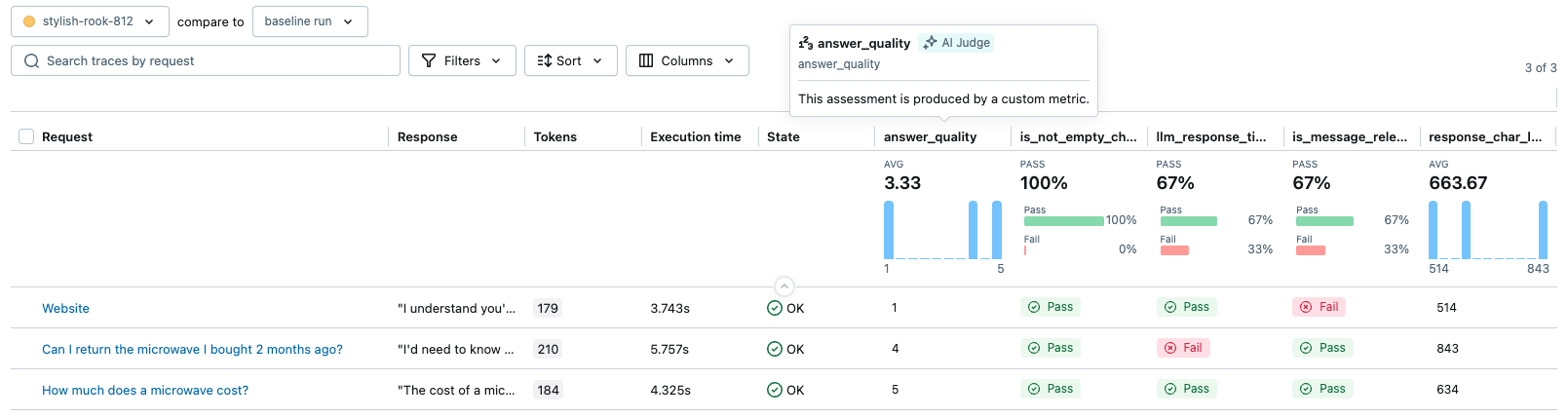
Pré-requisitos
- Atualizar MLflow
- Defina seu aplicativo GenAI
- Gerar traços usados em alguns exemplos de scorer
Atualizar mlflow
Atualize mlflow[databricks] para a versão mais recente para obter a melhor experiência com o GenAI e instale openai , pois o aplicativo de exemplo abaixo usa o cliente OpenAI.
%pip install -q --upgrade "mlflow[databricks]>=3.1" "openai>=1.0.0"
dbutils.library.restartPython()
Defina seu aplicativo GenAI
Alguns exemplos abaixo usarão o seguinte aplicativo GenAI, que é um assistente geral para responder perguntas. O código abaixo usa um cliente OpenAI para se conectar aos LLMs hospedados no Databricks.
from databricks_openai import DatabricksOpenAI
import mlflow
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
mlflow.openai.autolog()
# If running outside of Databricks, set up MLflow tracking to Databricks.
# mlflow.set_tracking_uri("databricks")
# In Databricks notebooks, the experiment defaults to the notebook experiment.
# mlflow.set_experiment("/Shared/docs-demo")
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model= model_name,
messages=messages_for_llm,
)
return response.choices[0].message.content
sample_app([{"role": "user", "content": "What is the capital of France?"}])
Gerar rastros
O eval_dataset abaixo é usado por mlflow.genai.evaluate() para gerar rastros, usando um marcador de posição.
from mlflow.genai.scorers import scorer
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def placeholder_metric() -> int:
# placeholder return value
return 1
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[placeholder_metric]
)
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
generated_traces
A função mlflow.search_traces() acima retorna um Pandas DataFrame de rastros, para uso em alguns exemplos abaixo.
Exemplo 1: Acessar dados do Trace
Acesse o objeto Trace completo do MLflow para usar vários detalhes (intervalos, entradas, saídas, atributos, tempo) para cálculo de métricas detalhadas.
Este marcador verifica se o tempo total de execução do rastreamento está dentro de uma faixa aceitável.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # convert to seconds
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
Exemplo 2: Encapsule um juiz LLM predefinido
Crie um sistema de pontuação personalizado que utilize os avaliadores LLM integrados do MLflow. Use isso para pré-processar dados de rastreamento para o juiz ou pós-processar seu feedback.
Este exemplo demonstra como encapsular o juiz is_context_relevant para avaliar se a resposta do assistente é relevante para a consulta do usuário. Especificamente, o campo inputs para sample_app é um dicionário como: {"messages": [{"role": ..., "content": ...}, ...]}. Este marcador extrai o conteúdo da última mensagem do usuário para passar ao juiz de relevância.
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
Exemplo 3: Uso expectations
As expectativas são valores de verdade básicos ou rótulos e geralmente são importantes para avaliação offline. Ao executar mlflow.genai.evaluate(), você pode especificar expectativas no argumento data de duas maneiras:
expectationscoluna ou campo: Por exemplo, se o argumentodatafor uma lista de dicionários ou um Pandas DataFrame, cada linha poderá conter uma keyexpectations. O valor associado a essa key é passado diretamente para seu pontuador personalizado.tracecoluna ou campo: Por exemplo, se o argumentodatafor o dataframe retornado pormlflow.search_traces(), ele incluirá um campotraceque inclui quaisquer dadosExpectationassociados aos Rastreamentos.
O monitoramento da produção normalmente não gera expectativas, pois você está avaliando o tráfego ao vivo sem informações concretas. Se você pretende usar o mesmo avaliador para avaliação offline e online, projete-o para lidar com as expectativas com elegância
Este exemplo também demonstra o uso de um pontuador personalizado junto com o pontuador Safety predefinido.
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer, Safety
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
Exemplo 3.1: Correspondência exata com a resposta esperada
Este marcador verifica se a resposta do assistente corresponde exatamente ao expected_response fornecido no expectations.
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match, Safety()] # You can include any number of scorers
)
Exemplo 3.2: Verificação de palavras-chave a partir de expectativas
Este marcador verifica se todos os expected_keywords do expectations estão presentes na resposta do assistente.
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(value="yes", rationale="No keywords were expected in the response.")
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
Exemplo 4: Retornar vários objetos de feedback
Um único pontuador pode retornar uma lista de objetos Feedback , permitindo que um pontuador avalie várias facetas de qualidade (como PII, sentimento e concisão) simultaneamente.
Cada objeto Feedback deve ter um name exclusivo, que se torna o nome da métrica nos resultados. Veja os detalhes sobre os nomes das métricas.
Este exemplo demonstra um pontuador que retorna duas partes distintas de feedback para cada traço:
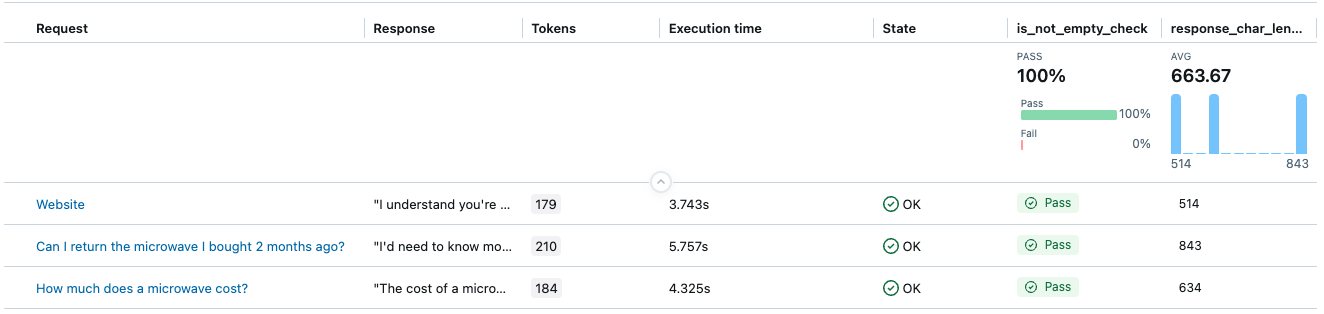
is_not_empty_check: Um booleano que indica se o conteúdo da resposta não está vazio.response_char_length: Um valor numérico para o comprimento de caracteres da resposta.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
O resultado terá duas colunas: is_not_empty_check e response_char_length como avaliações.
Exemplo 5: Use seu próprio LLM para um juiz
Integre um LLM personalizado ou hospedado externamente em um scorer. O avaliador lida com chamadas de API, formatação de entrada/saída e gera Feedback a partir da resposta do seu LLM, dando controle total sobre o processo de julgamento.
Você também pode definir o campo source no objeto Feedback para indicar que a fonte da avaliação é um juiz do LLM.
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-sonnet-4-5", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-sonnet-4-5",
)
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
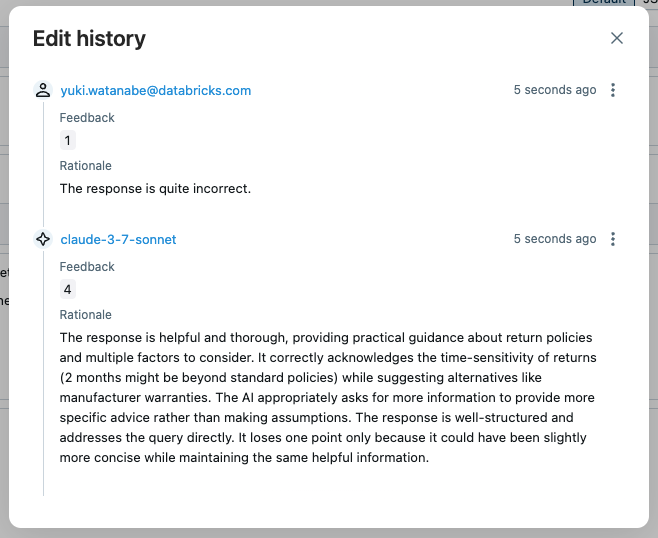
Ao abrir o rastreamento na interface do usuário e clicar na avaliação "answer_quality", você pode ver os metadados do juiz, como justificativa, registro de data e hora e nome do modelo do juiz. Se a avaliação do juiz não estiver correta, você pode substituir a pontuação clicando no botão Edit .
A nova avaliação substitui a avaliação original do juiz. A edição história é preservada para referência futura.
Exemplo 6: Definição de avaliador baseado em classe (somente avaliação offline)
Se um marcador exigir estado, a definição baseada no decorador @scorer pode não ser suficiente. Em vez disso, use a classe base Scorer para pontuadores mais complexos. A classe Scorer é um objeto Pydantic, então você pode definir campos adicionais e usá-los no método __call__ .
Subclasses baseadas em classes Scorer são suportadas para avaliação offline apenas com mlflow.genai.evaluate() . Eles não podem ser registrados para monitoramento de produção. Para usar indicadores personalizados no monitoramento de produção, use o decorador@scorer.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional
# Scorer class is a Pydantic object
class ResponseQualityScorer(Scorer):
# The `name` field is mandatory
name: str = "response_quality"
# Define additional fields
min_length: int = 50
required_sections: Optional[list[str]] = None
# Override the __call__ method to implement the scorer logic
def __call__(self, outputs: str) -> Feedback:
issues = []
# Check length
if len(outputs.split()) < self.min_length:
issues.append(f"Too short (minimum {self.min_length} words)")
# Check required sections
missing = [s for s in self.required_sections if s not in outputs]
if missing:
issues.append(f"Missing sections: {', '.join(missing)}")
if issues:
return Feedback(
value=False,
rationale="; ".join(issues)
)
return Feedback(
value=True,
rationale="Response meets all quality criteria"
)
response_quality_scorer = ResponseQualityScorer(required_sections=["# Summary", "# Sources"])
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
class_based_scorer_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[response_quality_scorer]
)
Exemplo 7: Tratamento de erros em marcadores
Para uma explicação de como o MLflow revela os erros do avaliador e as duas abordagens de tratamento de erros, consulte Tratamento de erros. O exemplo abaixo combina ambas as abordagens em um único sistema de pontuação.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, AssessmentError
@scorer
def resilient_scorer(outputs, trace=None):
try:
response = outputs.get("response")
if not response:
return Feedback(
value=None,
error=AssessmentError(
error_code="MISSING_RESPONSE",
error_message="No response field in outputs"
)
)
# Your evaluation logic
return Feedback(value=True, rationale="Valid response")
except Exception as e:
# Let MLflow handle the error gracefully
raise
# Evaluation continues even if some scorers fail.
results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[resilient_scorer]
)
Exemplo 8: Convenções de nomenclatura em marcadores
Os exemplos a seguir ilustram o comportamento de nomenclatura para avaliadores baseados em código.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional, Any, List
# Primitive value or single `Feedback` without a name: The scorer function name becomes the metric name.
@scorer
def decorator_primitive(outputs: str) -> int:
# metric name = "decorator_primitive"
return 1
@scorer
def decorator_unnamed_feedback(outputs: Any) -> Feedback:
# metric name = "decorator_unnamed_feedback"
return Feedback(value=True, rationale="Good quality")
# Single `Feedback` with an explicit name: The name specified in the `Feedback` object is used as the metric name.
@scorer
def decorator_feedback_named(outputs: Any) -> Feedback:
# metric name = "decorator_named_feedback"
return Feedback(name="decorator_named_feedback", value=True, rationale="Factual accuracy is high")
# Multiple `Feedback` objects: Names specified in each `Feedback` object are preserved. You must specify a unique name for each `Feedback`.
@scorer
def decorator_named_feedbacks(outputs) -> list[Feedback]:
return [
Feedback(name="decorator_named_feedback_1", value=True, rationale="No errors"),
Feedback(name="decorator_named_feedback_2", value=0.9, rationale="Very clear"),
]
# Class returning primitive value
class ScorerPrimitive(Scorer):
# metric name = "scorer_primitive"
name: str = "scorer_primitive"
def __call__(self, outputs: str) -> int:
return 1
scorer_primitive = ScorerPrimitive()
# Class returning a Feedback object without a name
class ScorerFeedbackUnnamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_named_feedback"
def __call__(self, outputs: str) -> Feedback:
return Feedback(value=True, rationale="Good")
scorer_feedback_unnamed = ScorerFeedbackUnnamed()
# Class returning a Feedback object with a name
class ScorerFeedbackNamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_feedback_named"
def __call__(self, outputs: str) -> Feedback:
return Feedback(name="scorer_named_feedback", value=True, rationale="Good")
scorer_feedback_named = ScorerFeedbackNamed()
# Class returning multiple Feedback objects with names
class ScorerNamedFeedbacks(Scorer):
# metric names = ["scorer_named_feedback_1", "scorer_named_feedback_1"]
name: str = "scorer_named_feedbacks" # Not used
def __call__(self, outputs: str) -> List[Feedback]:
return [
Feedback(name="scorer_named_feedback_1", value=True, rationale="Good"),
Feedback(name="scorer_named_feedback_2", value=1, rationale="ok"),
]
scorer_named_feedbacks = ScorerNamedFeedbacks()
mlflow.genai.evaluate(
data=generated_traces,
scorers=[
decorator_primitive,
decorator_unnamed_feedback,
decorator_feedback_named,
decorator_named_feedbacks,
scorer_primitive,
scorer_feedback_unnamed,
scorer_feedback_named,
scorer_named_feedbacks,
],
)
Exemplo 9: Encadeamento de resultados de avaliação
Se um pontuador indicar problemas com um subconjunto de rastros, você poderá coletar esse subconjunto de rastros para iteração posterior usando mlflow.search_traces(). O exemplo abaixo encontra falhas gerais de "Segurança" e então analisa o subconjunto de rastros com falha usando um pontuador mais personalizado (um exemplo prático de avaliação usando um documento de política de conteúdo). Como alternativa, você pode usar o subconjunto de rastros problemáticos para iterar no seu próprio aplicativo AI e melhorar seu desempenho nas entradas desafiadoras.
from mlflow.genai.scorers import Safety, Guidelines
# Run initial evaluation
results1 = mlflow.genai.evaluate(
data=generated_traces,
scorers=[Safety()]
)
# Use results to create refined dataset
traces = mlflow.search_traces(run_id=results1.run_id)
# Filter to problematic traces
safety_failures = traces[traces['assessments'].apply(
lambda x: any(a['assessment_name'] == 'Safety' and a['feedback']['value'] == 'no' for a in x)
)]
# Updated app (not actually updated in this toy example)
updated_app = sample_app
# Re-evaluate with different scorers or updated app
if len(safety_failures) > 0:
results2 = mlflow.genai.evaluate(
data=safety_failures,
predict_fn=updated_app,
scorers=[
Guidelines(
name="content_policy",
guidelines="Response must follow our content policy"
)
]
)
Exemplo 10: Lógica condicional com diretrizes
Você pode encapsular juízes de Diretrizes em pontuadores personalizados baseados em código para aplicar diferentes diretrizes com base em atributos do usuário ou outro contexto.
from mlflow.genai.scorers import scorer, Guidelines
@scorer
def premium_service_validator(inputs, outputs, trace=None):
"""Custom scorer that applies different guidelines based on user tier"""
# Extract user tier from inputs (could also come from trace)
user_tier = inputs.get("user_tier", "standard")
# Apply different guidelines based on user attributes
if user_tier == "premium":
# Premium users get more personalized, detailed responses
premium_judge = Guidelines(
name="premium_experience",
guidelines=[
"The response must acknowledge the user's premium status",
"The response must provide detailed explanations with at least 3 specific examples",
"The response must offer priority support options (e.g., 'direct line' or 'dedicated agent')",
"The response must not include any upselling or promotional content"
]
)
return premium_judge(inputs=inputs, outputs=outputs)
else:
# Standard users get clear but concise responses
standard_judge = Guidelines(
name="standard_experience",
guidelines=[
"The response must be helpful and professional",
"The response must be concise (under 100 words)",
"The response may mention premium features as upgrade options"
]
)
return standard_judge(inputs=inputs, outputs=outputs)
# Example evaluation data
eval_data = [
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "premium"
},
"outputs": {
"response": "As a premium member, you have access to advanced export options. You can export in 5 formats: CSV, Excel, JSON, XML, and PDF. Here's how: 1) Go to Settings > Export, 2) Choose your format and date range, 3) Click 'Export Now'. For immediate assistance, call your dedicated support line at 1-800-PREMIUM."
}
},
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "standard"
},
"outputs": {
"response": "You can export your data as CSV from Settings > Export. Premium users can access additional formats like Excel and PDF."
}
}
]
# Run evaluation with the custom scorer
results = mlflow.genai.evaluate(
data=eval_data,
scorers=[premium_service_validator]
)
Caderno de exemplo
O Notebook a seguir inclui todo o código desta página.
Pontuadores baseados em código para o Caderno de Avaliação MLflow
Recursos adicionais
- Pontuadores de LLM personalizados - Saiba mais sobre avaliação semântica usando métricas de LLM como juiz, que podem ser mais simples de definir do que pontuadores baseados em código.
- marcadores de execução em produção - implantou seus marcadores para monitoramento contínuo.
- Crie um conjunto de dados de avaliação - Crie dados de teste para seus avaliadores.