Avalie aplicativos GenAI durante o desenvolvimento
A função mlflow.genai.evaluate() fornece uma estrutura de avaliação para aplicações GenAI. Em vez de executar seu aplicativo manualmente e verificar as saídas uma a uma, MLflow Evaluation oferece uma maneira estruturada de inserir dados de teste, executar seu aplicativo e avaliar automaticamente os resultados. Isso facilita a comparação de versões, o acompanhamento de melhorias e o compartilhamento de resultados entre as equipes.
O MLflow Evaluation conecta testes offline com monitoramento de produção. Isso significa que a mesma lógica de avaliação usada no desenvolvimento também pode ser executada em produção, proporcionando uma view consistente da qualidade em todo o ciclo de vida AI .
A função mlflow.genai.evaluate() testa sistematicamente a qualidade do aplicativo GenAI executando-o em dados de teste (conjunto de dados de avaliação e aplicando pontuadores).
Se você é novo na área de avaliação, comece com uma demonstração de 10 minutos: Avalie um aplicativo GenAI.
Quando usar
- Verificações noturnas ou semanais do seu aplicativo em relação a um conjunto de dados de avaliação selecionados
- Validando alterações de prompt ou modelo entre versões de aplicativos
- Antes de um lançamento ou PR para evitar regressões de qualidade
Referência rápida
A função mlflow.genai.evaluate() executa seu aplicativo GenAI em um dataset de avaliação usando pontuadores especificados e, opcionalmente, uma função de previsão ou ID de modelo, retornando um EvaluationResult.
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
- Para obter detalhes da API, consulte Parâmetros para
mlflow.genai.evaluate()ou a documentação do MLflow. - Para obter detalhes sobre
EvaluationDataset, consulte Construindo o conjunto de dados de avaliação MLflow. - Para obter detalhes sobre execuções de avaliação e registro, consulte Execuções de avaliação no MLflow.
Requisitos
-
Instale o site MLflow e o pacote necessário.
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
Crie um experimento MLflow seguindo o início rápido de configuração do ambiente.
(Opcional) Configurar paralelização
Por default MLflow usa o threadpool em segundo plano para acelerar o processo de avaliação. Para configurar o número de trabalhadores, defina a variável de ambiente MLFLOW_GENAI_EVAL_MAX_WORKERS.
export MLFLOW_GENAI_EVAL_MAX_WORKERS=10
Modos de avaliação
Há dois modos de avaliação:
-
Avaliação direta (recomendada). O MLflow chama seu aplicativo diretamente para gerar rastreamentos para avaliação:
- execute seu aplicativo em entradas de teste, capturando rastros.
- Aplica avaliadores ou juízes com mestrado em Direito (LLM) para avaliar a qualidade, gerando feedback.
- Armazena os resultados em uma execução de avaliação no experimento MLflow ativo.
-
Avaliação da folha de respostas. Você fornece resultados pré-computados ou rastreamentos existentes para avaliação:
- Aplica avaliadores ou juízes LLM para avaliar a qualidade das saídas ou rastreamentos pré-computados, criando feedback.
- Armazena os resultados em uma execução de avaliação no experimento MLflow ativo.
Avaliação direta (recomendada)
O MLflow chama seu aplicativo GenAI diretamente para gerar e avaliar rastros. Você pode passar o ponto de entrada do seu aplicativo encapsulado em uma função Python (predict_fn) ou, se seu aplicativo for usado como um endpoint Databricks servindo modelo, passe esse endpoint encapsulado em to_predict_fn.
Ao chamar seu aplicativo diretamente, esse modo permite que o senhor reutilize os avaliadores definidos para a avaliação off-line no monitoramento da produção, pois os traços resultantes serão idênticos.
Conforme mostrado no diagrama, os dados, seu aplicativo e os pontuadores selecionados são fornecidos como entradas para mlflow.genai.evaluate(), que executa o aplicativo e os pontuadores em paralelo e registra a saída como rastros e feedback.
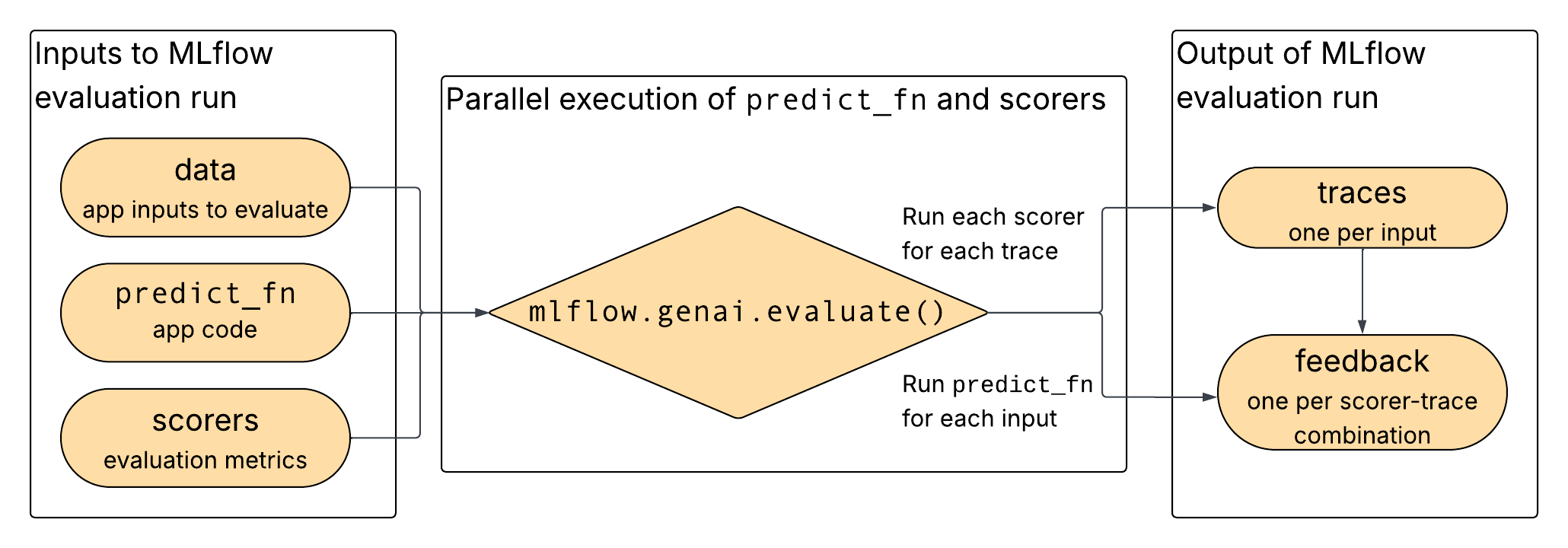
Formatos de dados para avaliação direta
Para obter detalhes sobre o esquema, consulte a referência dataset de avaliação.
campo | Tipo de dados | Obrigatório | Descrição |
|---|---|---|---|
|
| Sim | Dicionário passado para o seu |
|
| Não | Verdade básica opcional para marcadores |
Exemplo usando avaliação direta
O código a seguir mostra um exemplo de como executar a avaliação:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
# Your GenAI app with MLflow tracing
@mlflow.trace
def my_chatbot_app(question: str) -> dict:
# Your app logic here
if "MLflow" in question:
response = "MLflow is an open-source platform for managing ML and GenAI workflows."
else:
response = "I can help you with MLflow questions."
return {"response": response}
# Evaluate your app
results = mlflow.genai.evaluate(
data=[
{"inputs": {"question": "What is MLflow?"}},
{"inputs": {"question": "How do I get started?"}}
],
predict_fn=my_chatbot_app,
scorers=[RelevanceToQuery(), Safety()]
)
Chamadas de modelo de limitação de taxa
Ao avaliar modelos com limites de taxa (como APIs de terceiros ou endpoints de modelos de base), envolva sua função de previsão com lógica de limitação de taxa. Este exemplo usa a biblioteca ratelimit:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
from ratelimit import limits, sleep_and_retry
# You can replace this with your own predict_fn
predict_fn = mlflow.genai.to_predict_fn("endpoints:/databricks-gpt-oss-20b")
@sleep_and_retry
@limits(calls=10, period=60) # 10 calls per minute
def rate_limited_predict_fn(*args, **kwargs):
return predict_fn(*args, **kwargs)
results = mlflow.genai.evaluate(
data=[{"inputs": {"messages": [{"role": "user", "content": "How does MLflow work?"}]}}],
predict_fn=predict_fn,
scorers=[RelevanceToQuery(), Safety()]
)
O limite de taxa acima controla as chamadas à sua função predict_fn. Você também pode controlar o número de trabalhadores usados para avaliar seu agente configurando a paralelização.
Avaliação da folha de respostas
Use este modo quando não puder – ou não quiser – executar seu aplicativo GenAI diretamente durante a avaliação. Por exemplo, você já possui resultados (por exemplo, de sistemas externos, registros históricos ou trabalho em lote) e deseja apenas pontuá-los. Você fornece as entradas e a saída, e evaluate() avaliadores de execução e logs de uma execução de avaliação.
Se o senhor usar uma folha de respostas com traços diferentes dos do seu ambiente de produção, talvez seja necessário reescrever as funções do avaliador para usá-las no monitoramento da produção.
Conforme mostrado no diagrama, você fornece dados de avaliação e pontuadores selecionados como entradas para mlflow.genai.evaluate(). Os dados de avaliação podem consistir em rastros existentes ou em entradas e saídas pré-computadas. Se entradas e saídas de pré-cálculo forem fornecidas, mlflow.genai.evaluate() constrói rastros a partir das entradas e saídas. Para ambas as opções de entrada, mlflow.genai.evaluate() executa os marcadores nos traços e gera feedback dos marcadores.
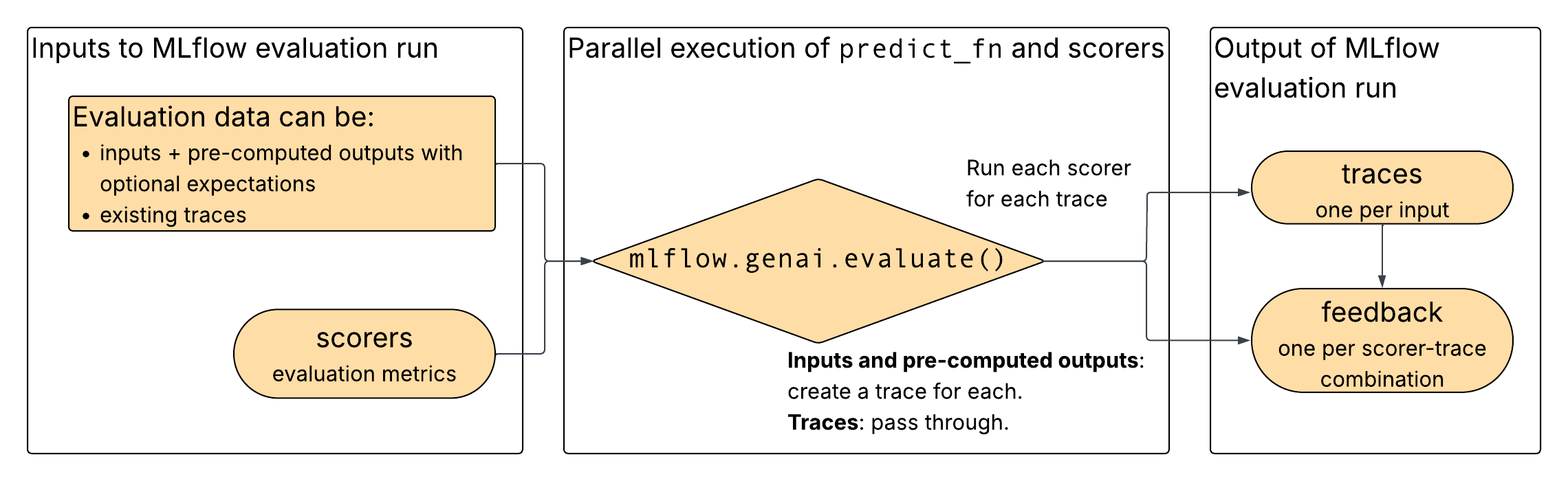
Formatos de dados para avaliação da folha de respostas
Para obter detalhes sobre o esquema, consulte a referência dataset de avaliação.
Se entradas e saídas forem fornecidas
campo | Tipo de dados | Obrigatório | Descrição |
|---|---|---|---|
|
| Sim | Entradas originais para seu aplicativo GenAI |
|
| Sim | Pré-computar os resultados de seu aplicativo |
|
| Não | Verdade básica opcional para marcadores |
Se forem fornecidos vestígios existentes
campo | Tipo de dados | Obrigatório | Descrição |
|---|---|---|---|
|
| Sim | Objetos de rastreamento do MLflow com entradas/saídas |
|
| Não | Verdade básica opcional para marcadores |
Exemplo de uso de entradas e saídas
O código a seguir mostra um exemplo de como executar a avaliação:
import mlflow
from mlflow.genai.scorers import Safety, RelevanceToQuery
# Pre-computed results from your GenAI app
results_data = [
{
"inputs": {"question": "What is MLflow?"},
"outputs": {"response": "MLflow is an open-source platform for managing machine learning workflows, including tracking experiments, packaging code, and deploying models."},
},
{
"inputs": {"question": "How do I get started?"},
"outputs": {"response": "To get started with MLflow, install it using 'pip install mlflow' and then run 'mlflow ui' to launch the web interface."},
}
]
# Evaluate pre-computed outputs
evaluation = mlflow.genai.evaluate(
data=results_data,
scorers=[Safety(), RelevanceToQuery()]
)
Exemplo de uso de traços existentes
O código a seguir demonstra como executar a avaliação utilizando traços existentes:
import mlflow
# Retrieve traces from production
traces = mlflow.search_traces(
filter_string="trace.status = 'OK'",
)
# Evaluate problematic traces
evaluation = mlflow.genai.evaluate(
data=traces,
scorers=[Safety(), RelevanceToQuery()]
)
Visualizar resultados na interface do usuário
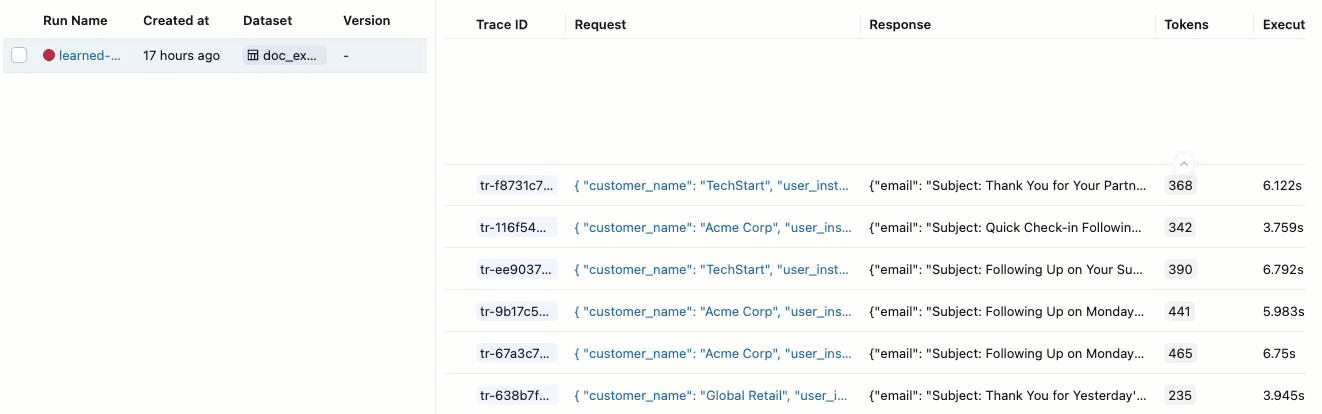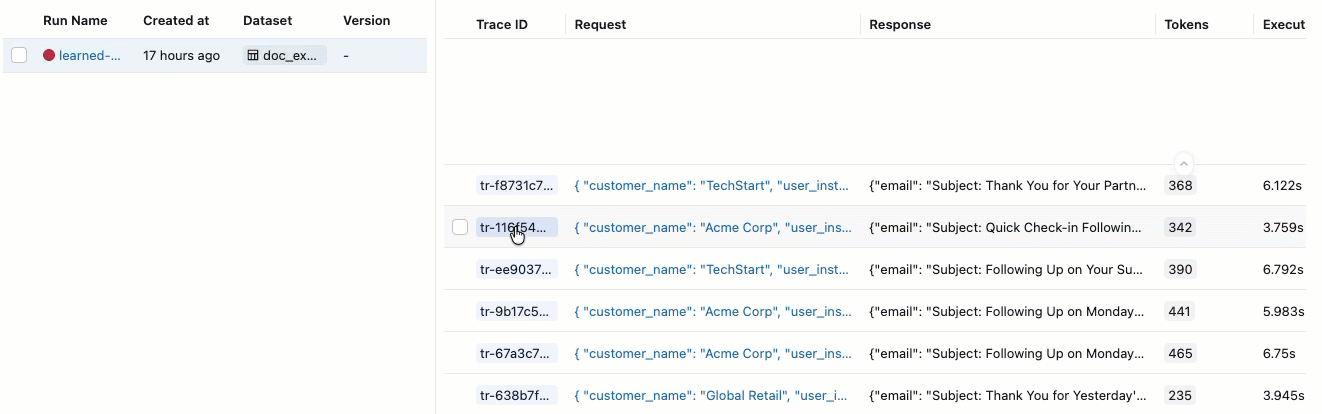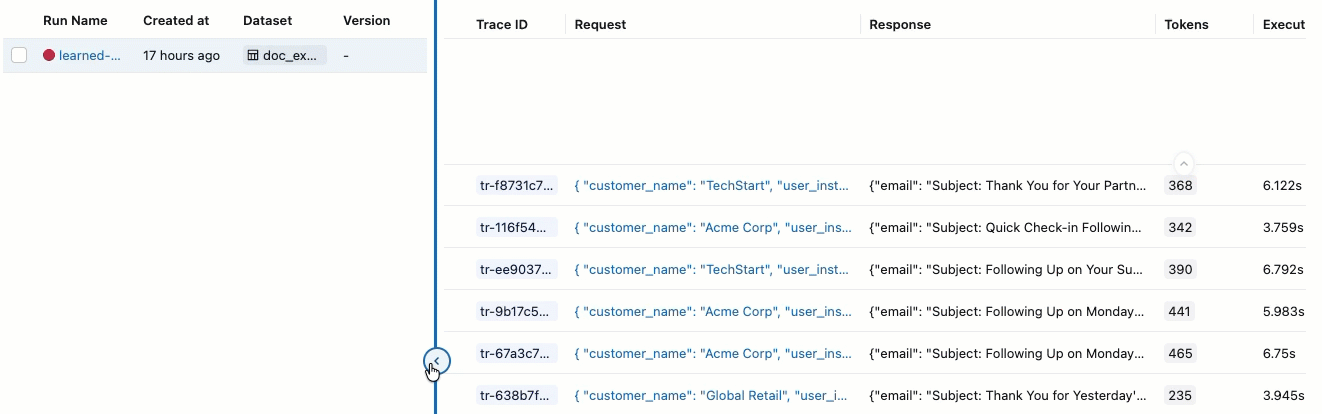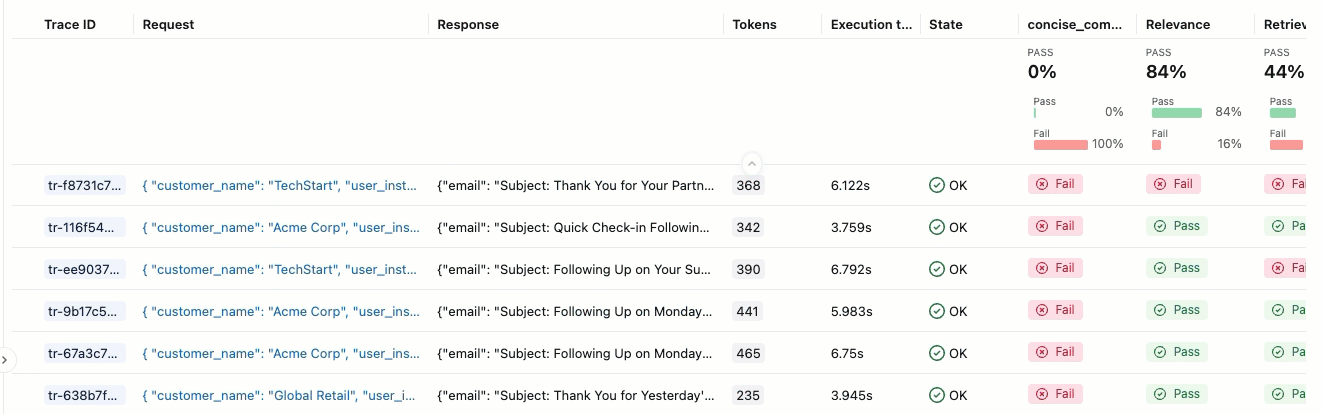
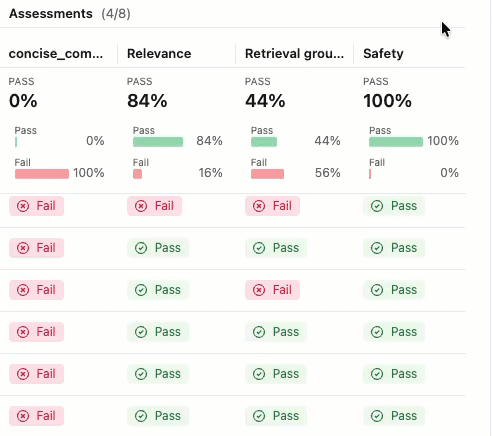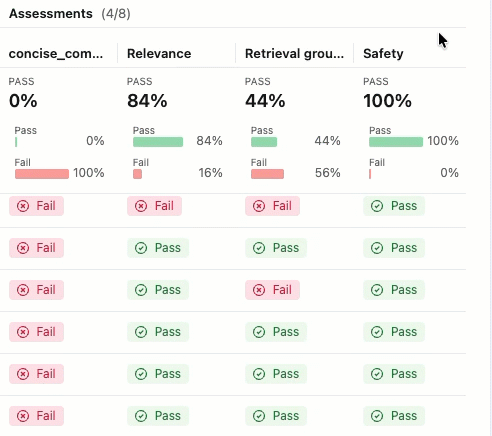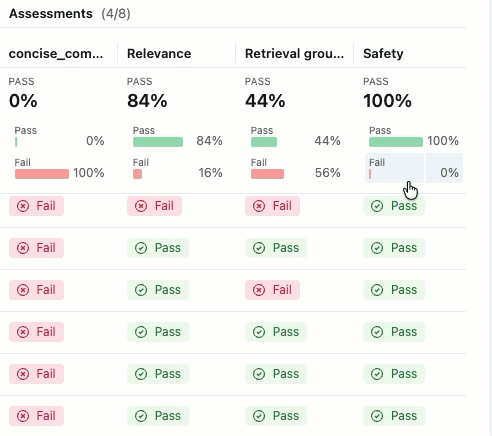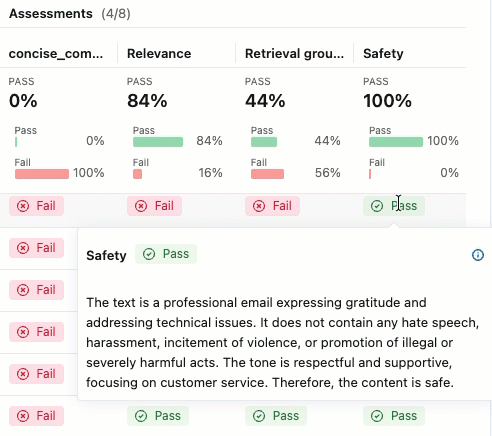
Uma execução de avaliação é como um relatório de teste que registra tudo sobre o desempenho do seu aplicativo em um dataset específico. A execução da avaliação contém um registro para cada linha do seu dataset de avaliação, com feedback de cada avaliador.
Ao usar a execução da avaliação, você pode view métricas agregadas e investigar casos de teste em que seu aplicativo teve um desempenho ruim.
Resumo da avaliação
-
Clique em Experimentos na barra lateral para exibir a página de Experimentos.
-
Clique no nome do seu experimento para abri-lo.
-
Na barra lateral esquerda, clique em Execução da avaliação . O painel direito mostra uma tabela de traçados.
Se você não visualizar as Avaliações com seus respectivos rótulos de Aprovado e Reprovado , role para a direita ou passe o cursor sobre o separador do painel e clique na seta apontando para a esquerda.
-
Para ver a justificativa para o rótulo "Aprovado" ou "Reprovado" , passe o cursor sobre o rótulo.
Detalhes e comentários
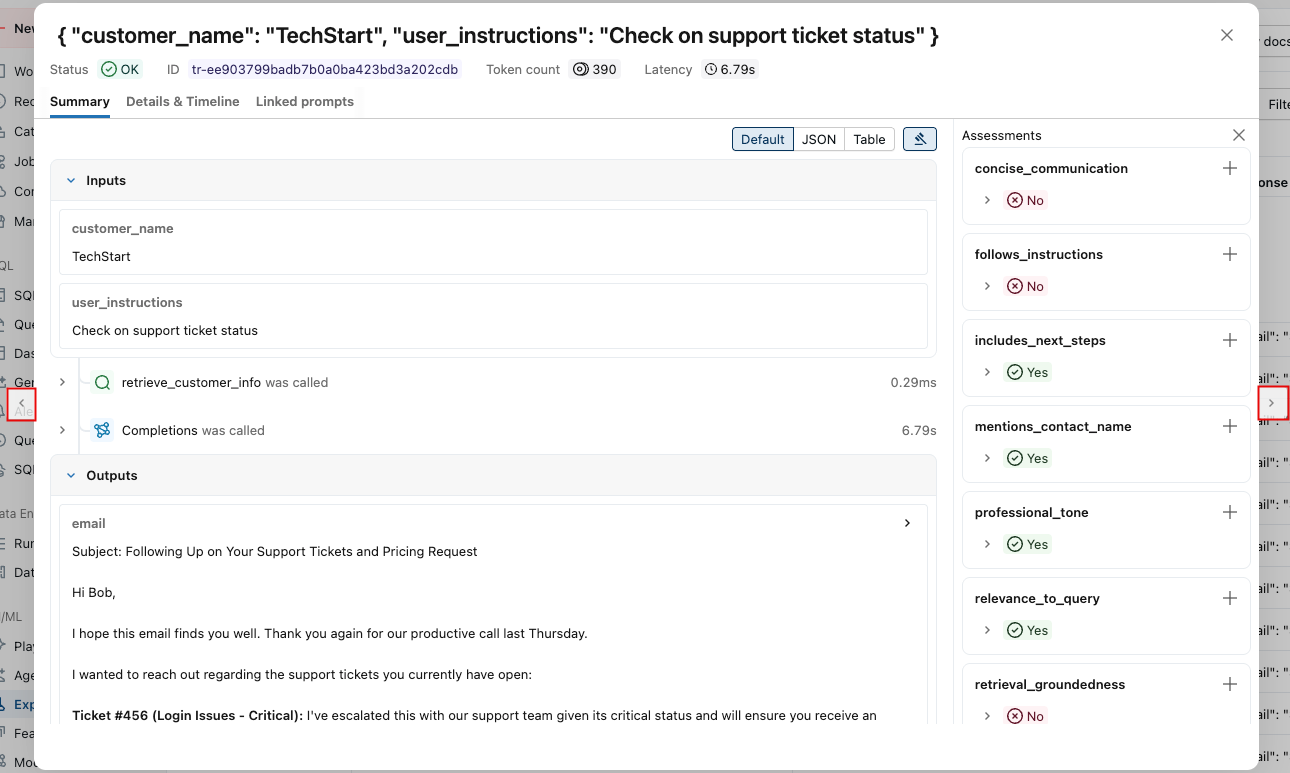
Para ver mais detalhes sobre cada traço:
-
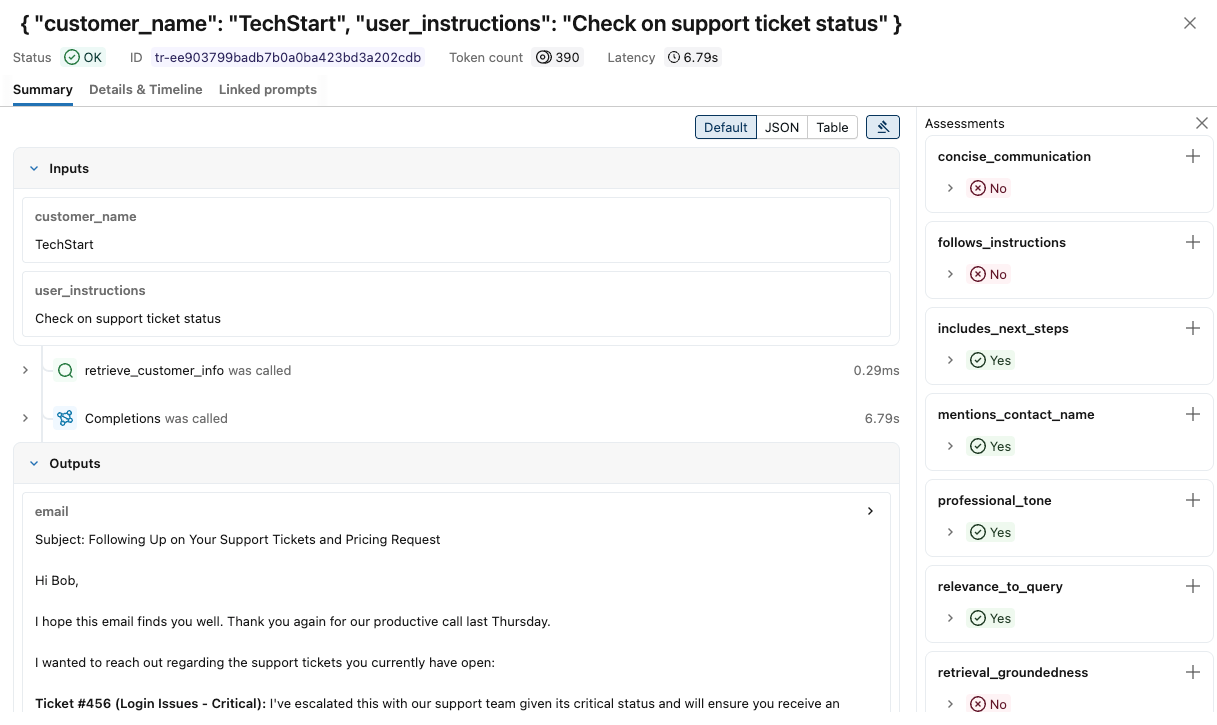
Clique no identificador da solicitação na coluna Solicitação . Aparece uma janela mostrando o rastreamento completo, incluindo entradas e saídas para cada passo.
-
À direita, você pode adicionar comentários ou expectativas a serem aplicados à resposta para esta solicitação. Se você não visualizar o painel Avaliações, clique em
 . Para adicionar uma nova avaliação, role para baixo e clique.
. Para adicionar uma nova avaliação, role para baixo e clique. .
. -
Você pode usar as setas em ambos os lados desta janela para navegar entre as solicitações.
Parâmetros para mlflow.genai.evaluate()
Esta seção descreve cada um dos parâmetros usados por mlflow.genai.evaluate().
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
data
A avaliação dataset deve estar em um dos seguintes formatos:
EvaluationDataset(recomendado).- Lista de dicionários, Pandas DataFrame ou Spark DataFrame.
Se o argumento de dados for fornecido como um DataFrame ou lista de dicionários, ele deverá seguir o esquema a seguir. Isso é consistente com o esquema usado pelo EvaluationDataset. Databricks Recomenda-se utilizar um EvaluationDataset, pois ele impõe a validação do esquema, além de acompanhar a linhagem de cada registro.
campo | Tipo de dados | Descrição | Uso com avaliação direta | Use com folha de respostas |
|---|---|---|---|---|
|
| Um | Obrigatório |
|
|
| Um | Não deve ser fornecido, gerado pelo MLflow a partir do Trace. |
|
|
| Um | Opcional | Opcional |
|
| O objeto de rastreamento da solicitação. Se o | Não deve ser fornecido, gerado pelo MLflow a partir do Trace. |
|
scorers
Lista de métricas de qualidade a serem aplicadas. Você pode fornecer:
Consulte Marcadores para obter mais detalhes.
predict_fn
O ponto de entrada do aplicativo GenAI. Esse parâmetro só é usado com avaliação direta. predict_fn deve atender aos seguintes requisitos:
- Aceite a chave do dicionário
inputsemdatacomo argumentos de palavra-chave. - Retorna um dicionário serializável em JSON.
- Seja equipado com o MLflow Tracing.
- Emita exatamente um rastreamento por chamada.
model_id
Identificador de modelo opcional para vincular os resultados à versão do seu aplicativo (por exemplo, "models:/my-app/1").
Recursos adicionais
- Avalie seu aplicativo - Guia passo a passo para realizar sua primeira avaliação.
- logs Criar um conjunto de dados de avaliação - Crie dados de teste estruturados a partir de dados de produção ou do zero.
- Defina avaliadores personalizados - Crie métricas adaptadas ao seu caso específico.