Avaliadores e juízes de LLM
Os avaliadores são um componente key da estrutura de avaliação MLflow GenAI. Eles fornecem uma interface unificada para definir critérios de avaliação para seus modelos, agentes e aplicativos. Como o próprio nome sugere, os avaliadores classificam o desempenho da sua candidatura com base nos critérios de avaliação. Isso pode ser um resultado de aprovado/reprovado, verdadeiro/falso, valor numérico ou valor categórico.
Você pode usar o mesmo sistema de pontuação para avaliação em desenvolvimento e monitoramento em produção , mantendo a consistência da avaliação ao longo de todo o ciclo de vida da aplicação.
Escolha o tipo certo de marcador de pontos dependendo do nível de personalização e controle que você precisa. Cada abordagem se baseia na anterior, adicionando mais complexidade e controle.
comece com juízes integrados para avaliação rápida. À medida que suas necessidades evoluem, crie juízes LLM personalizados para critérios específicos de domínio e avaliadores personalizados baseados em código para lógica de negócios determinística.
Abordagem | Nível de personalização | Casos de uso |
|---|---|---|
Mínimo | Experimente rapidamente a avaliação LLM com avaliadores integrados como | |
Moderado | Um sistema integrado de avaliação que verifica se as respostas atendem ou não a regras personalizadas de linguagem natural, como diretrizes de estilo ou de veracidade factual. | |
Completo | Crie juízes de LLM totalmente personalizados com critérios de avaliação detalhados e otimização de feedback. Capaz de retornar pontuações numéricas, categorias ou valores booleanos. | |
Completo | Avaliadores programáticos e determinísticos que avaliam aspectos como correspondência exata, validação de formato e métricas de desempenho. |
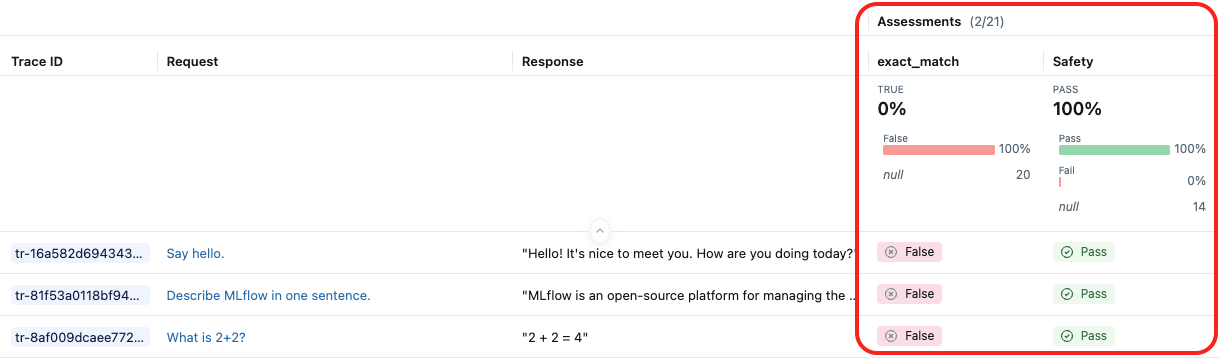
A seguinte captura de tela mostra os resultados do juiz integrado LLM Safety e de um avaliador personalizado exact_match:
Como funcionam os marcadores
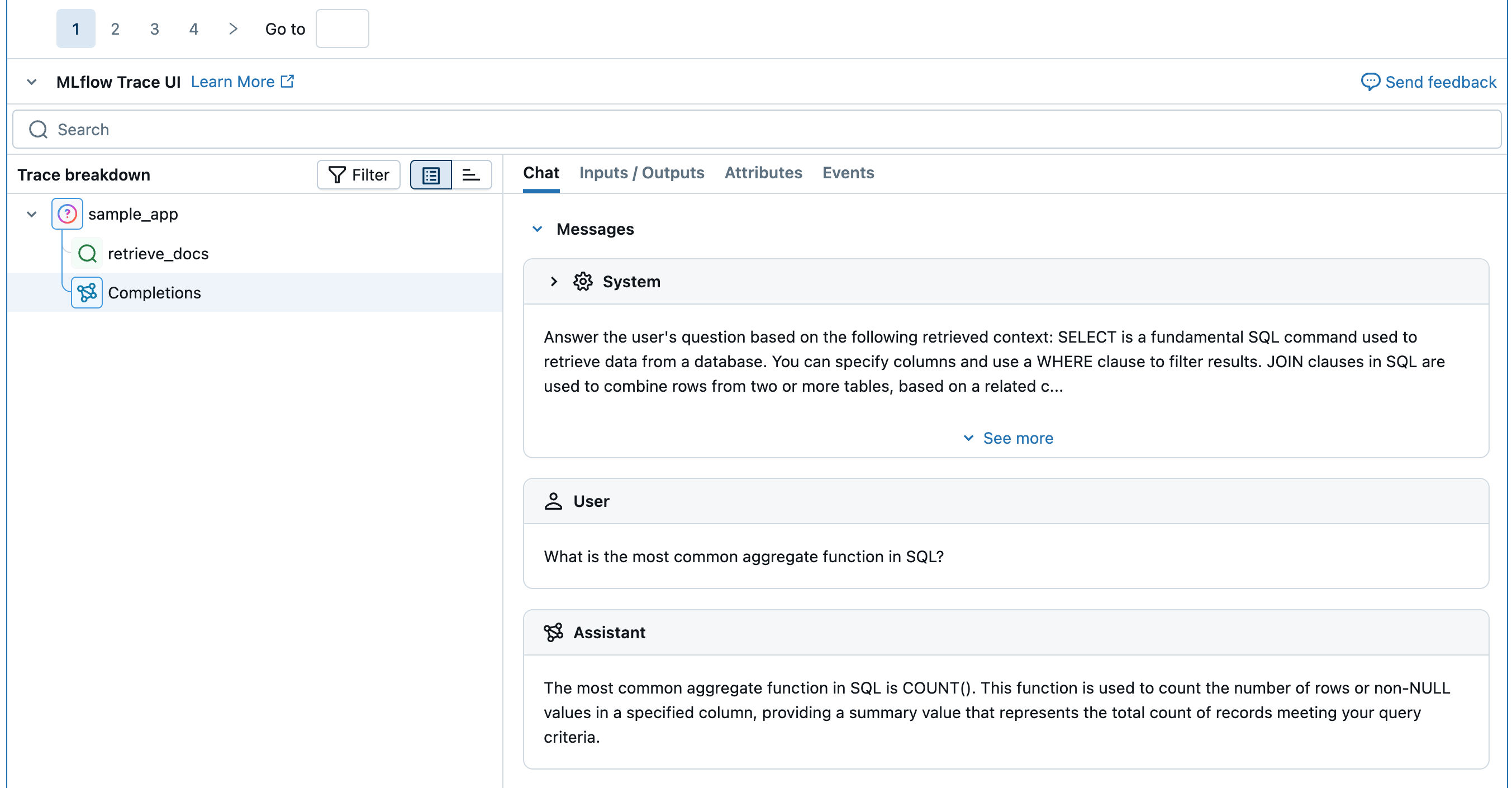
Um avaliador recebe um Trace de evaluate() ou do serviço de monitoramento. Em seguida, realiza o seguinte:
- Analisa o
tracepara extrair campos e dados específicos usados para avaliar a qualidade. - A execução do avaliador consiste em realizar a avaliação da qualidade com base nos campos e dados extraídos.
- Retorna a avaliação de qualidade como
Feedbackpara anexar aotrace
Mestres em Direito como juízes
Os juízes LLM são um tipo de MLflow Scorer que usa Large Language Models para avaliação de qualidade.
Imagine um juiz como um assistente AI especializado em avaliação de qualidade. Ele pode avaliar as entradas e saídas do seu aplicativo, e até mesmo explorar todo o rastreamento de execução para fazer avaliações com base em critérios que você definir. Por exemplo, um juiz pode entender que give me healthy food options e food to keep me fit são consultas semelhantes.
Os juízes são um tipo de avaliador que utiliza LLMs para avaliação. Use-os diretamente com mlflow.genai.evaluate() ou envolva-os em marcadores personalizados para lógica de pontuação avançada.
juízes integrados LLM
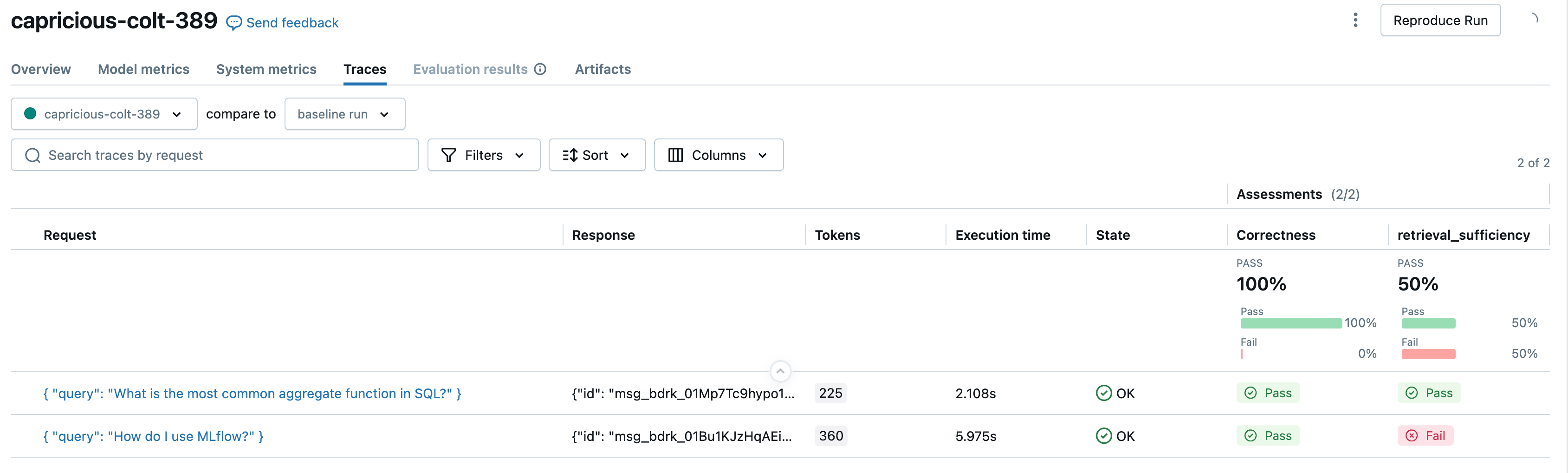
O MLflow fornece juízes validados por pesquisas para casos de uso comuns:
Juiz | Argumentos | Requer dados concretos. | O que avalia |
|---|---|---|---|
| Não | A resposta é diretamente relevante para a solicitação do usuário? | |
| Não | O contexto obtido é diretamente relevante para a solicitação do usuário? | |
| Não | O conteúdo está livre de material prejudicial, ofensivo ou tóxico? | |
| Não | A resposta está fundamentada nas informações fornecidas no contexto? O agente está tendo alucinações? | |
| Sim | A resposta está correta em comparação com a verdade fundamental fornecida? | |
| Sim | O contexto fornece todas as informações necessárias para gerar uma resposta que inclua os fatos reais? | |
| Não | A resposta atende aos critérios especificados de linguagem natural? | |
| Não (mas é preciso ter diretrizes quanto às expectativas). | A resposta atende aos critérios de linguagem natural por exemplo? |
Juízes LLM personalizados
Além dos juízes integrados, MLflow facilita a criação de juízes personalizados com instruções e perguntas customizadas.
Utilize juízes LLM personalizados quando precisar definir tarefas de avaliação especializadas, tiver maior controle sobre notas ou pontuações (e não apenas aprovação/reprovação) ou precisar validar se seu agente tomou as decisões apropriadas e executou as operações corretamente para seu caso de uso específico.
Veja Juízes personalizados.
Depois de criar juízes personalizados, você pode aprimorar ainda mais a precisão deles, alinhando-os com o feedback humano.
Selecione o LLM que capacita o juiz.
Por default, cada juiz utiliza um LLMhospedadoDatabricks , projetado para realizar avaliações de qualidade do GenAI. Você pode alterar o modelo de juiz usando o argumento model na definição do juiz. Especifique o modelo no formato <provider>:/<model-name>. Por exemplo:
from mlflow.genai.scorers import Correctness
Correctness(model="databricks:/databricks-gpt-5-mini")
Para obter uma lista dos modelos suportados, consulte a documentação do MLflow.
informações sobre os modelos que capacitam os juízes LLM
- Os juízes do LLM podem utilizar serviços de terceiros para avaliar suas aplicações GenAI, incluindo o Azure OpenAI operado pela Microsoft.
- Para o Azure OpenAI, a Databricks optou por não utilizar o Abuse Monitoring, portanto nenhum prompt ou resposta é armazenado com o Azure OpenAI.
- Para os espaços de trabalho da União Europeia (UE), os juízes do LLM utilizam modelos hospedados na UE. Todas as outras regiões utilizam modelos hospedados nos EUA.
- Desativar o recurso AI baseado em parceiros impede que o juiz LLM invoque modelos baseados em parceiros. Você ainda pode usar juízes LLM fornecendo seu próprio modelo.
- Os juízes LLM têm como objetivo ajudar os clientes a avaliar seus agentes/aplicativos GenAI, e os resultados dos juízes LLM não devem ser usados para ensinar, aprimorar ou ajustar um LLM.
Precisão do avaliador
A Databricks aprimora continuamente a qualidade dos juízes por meio de:
- Validação da pesquisa por meio de avaliação de especialistas humanos
- Acompanhamento de métricas : Kappa de Cohen, precisão, pontuação F1
- Testes diversificados em conjuntos de dados acadêmicos e do mundo real.
Consulte os blogsDatabricks sobre melhorias LLM Judge para obter mais detalhes.
Avaliadores baseados em código
Os sistemas de avaliação personalizados baseados em código oferecem a máxima flexibilidade para definir com precisão como a qualidade da sua aplicação GenAI será medida. Você pode definir métricas de avaliação personalizadas para o seu caso de uso específico, seja com base em heurísticas simples, lógica avançada ou avaliações programáticas.
Utilize avaliadores personalizados para os seguintes cenários:
- Definir uma heurística personalizada ou uma métrica de avaliação baseada em código.
- Personalizar a forma como os dados do rastreamento do seu aplicativo são mapeados para os juízes do Integral LLM .
- Utilizando seu próprio sistema de avaliação de mestrado LLM LLM ) (em vez de um sistema hospedado Databricks ) para a avaliação.
- Quaisquer outros casos de uso em que você precise de mais flexibilidade e controle do que os oferecidos por juízes LLM personalizados.
Consulte Criar avaliadores personalizados baseados em código.