Monitorar GenAI em produção
Beta
Este recurso está em versão Beta. Os administradores do espaço de trabalho podem controlar o acesso a este recurso na página de Pré-visualizações . Veja as prévias do Gerenciador Databricks.
O monitoramento de produção para GenAI no Databricks permite que você execute automaticamente os scorers MLflow 3 em rastros de seus aplicativos de produção GenAI para monitorar continuamente a qualidade.
Você pode programar pontuadores para avaliar automaticamente uma amostra do seu tráfego de produção. Os resultados da avaliação do pontuador são automaticamente anexados como feedback aos traços avaliados.
O monitoramento da produção inclui o seguinte:
- Avaliação automatizada da qualidade usando avaliadores integrados ou personalizados, incluindo avaliadores de múltiplas interações para avaliar conversas inteiras.
- Taxas de amostragem configuráveis para que você possa controlar a compensação entre cobertura e custo computacional.
- Use os mesmos avaliadores no desenvolvimento e na produção para garantir uma avaliação consistente.
- Avaliação contínua da qualidade com monitoramento em segundo plano.
MLflow O monitoramento da produção 3 é compatível com os registros de traços do site MLflow 2.
Pré-requisitos
Antes de configurar o monitoramento de qualidade, certifique-se de que possui:
-
ExperimentoMLflow : Um experimento MLflow onde os rastros estão sendo registrados. Se nenhum experimento for especificado, o experimento ativo será usado.
-
Aplicação de produção instrumentada : seu aplicativo GenAI deve estar registrando rastreamentos usando o MLflow Tracing. Consulte o guia Rastreamento de produção.
-
Pontuadores definidos : Pontuadores testados que funcionam com o formato de rastreamento do seu aplicativo. Se você usou seu aplicativo de produção como o
predict_fnemmlflow.genai.evaluate()durante o desenvolvimento, seus avaliadores provavelmente já são compatíveis. -
IDSQL warehouse (para rastreamentos Unity Catalog ) : Se seus rastreamentos estiverem armazenados no Unity Catalog, você deve configurar um ID SQL warehouse para que o monitoramento funcione. Consulte Ativar o monitoramento de produção.
Iniciar o monitoramento da produção
Esta seção inclui um exemplo de código que mostra como criar os diferentes tipos de marcadores.
Para mais informações sobre os pontuadores, veja o seguinte:
A qualquer momento, no máximo 20 avaliadores podem estar associados a um experimento para monitoramento contínuo da qualidade.
Crie e programe juízes LLM usando a interface do usuário.
Você pode usar a interface do usuário do MLflow para criar e testar avaliadores com base em juízes de mestrado em direito (LLM).
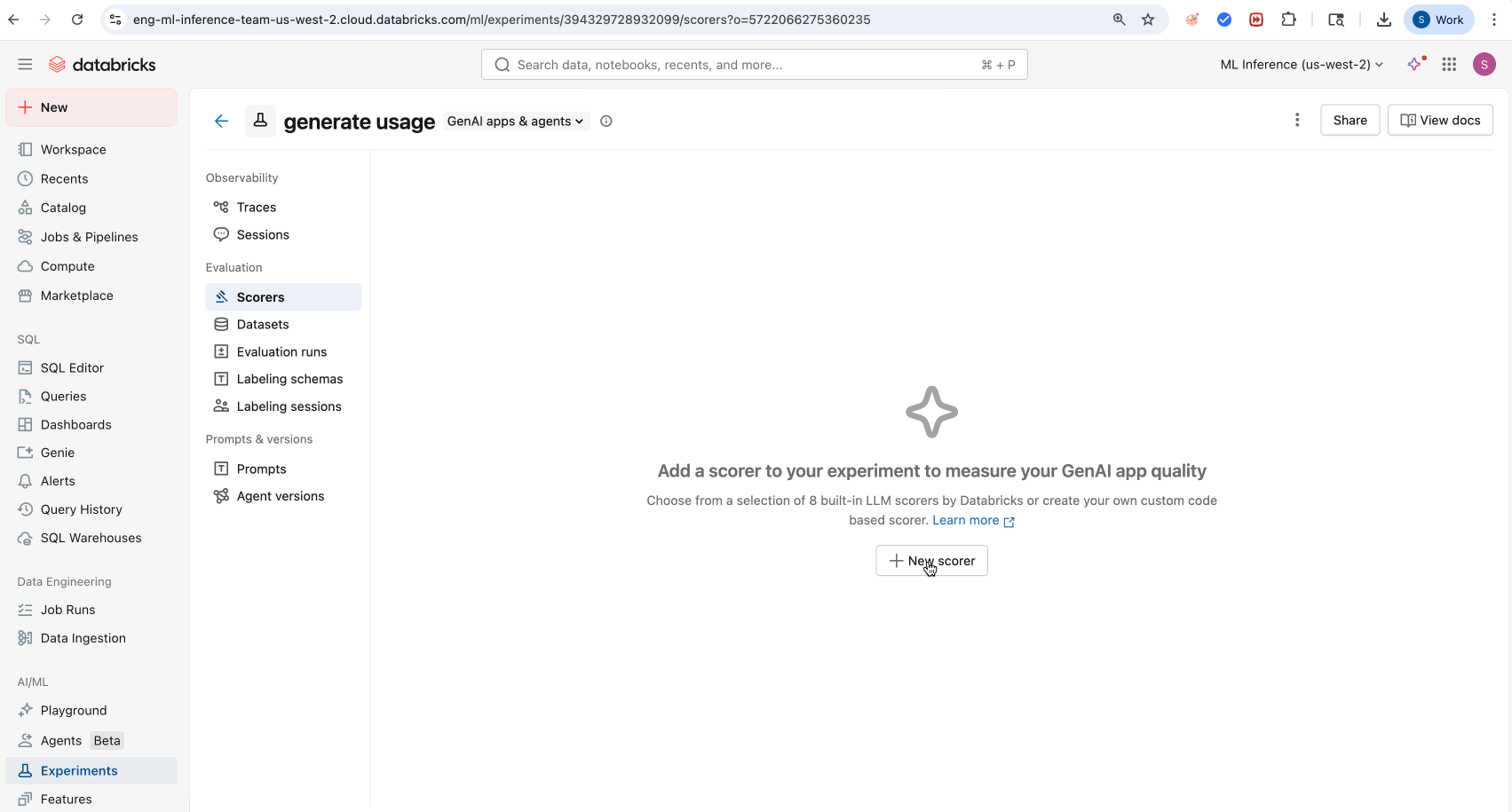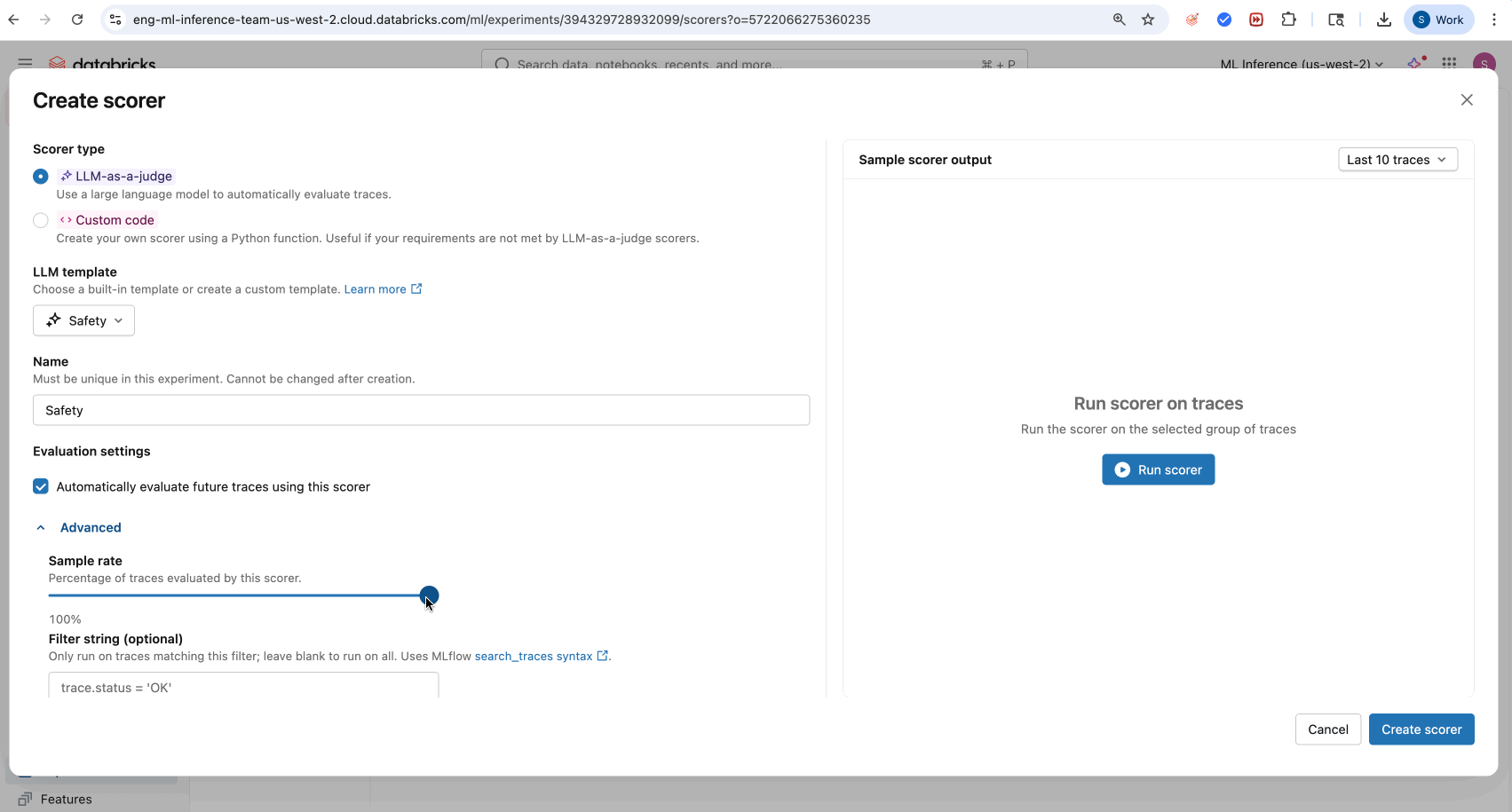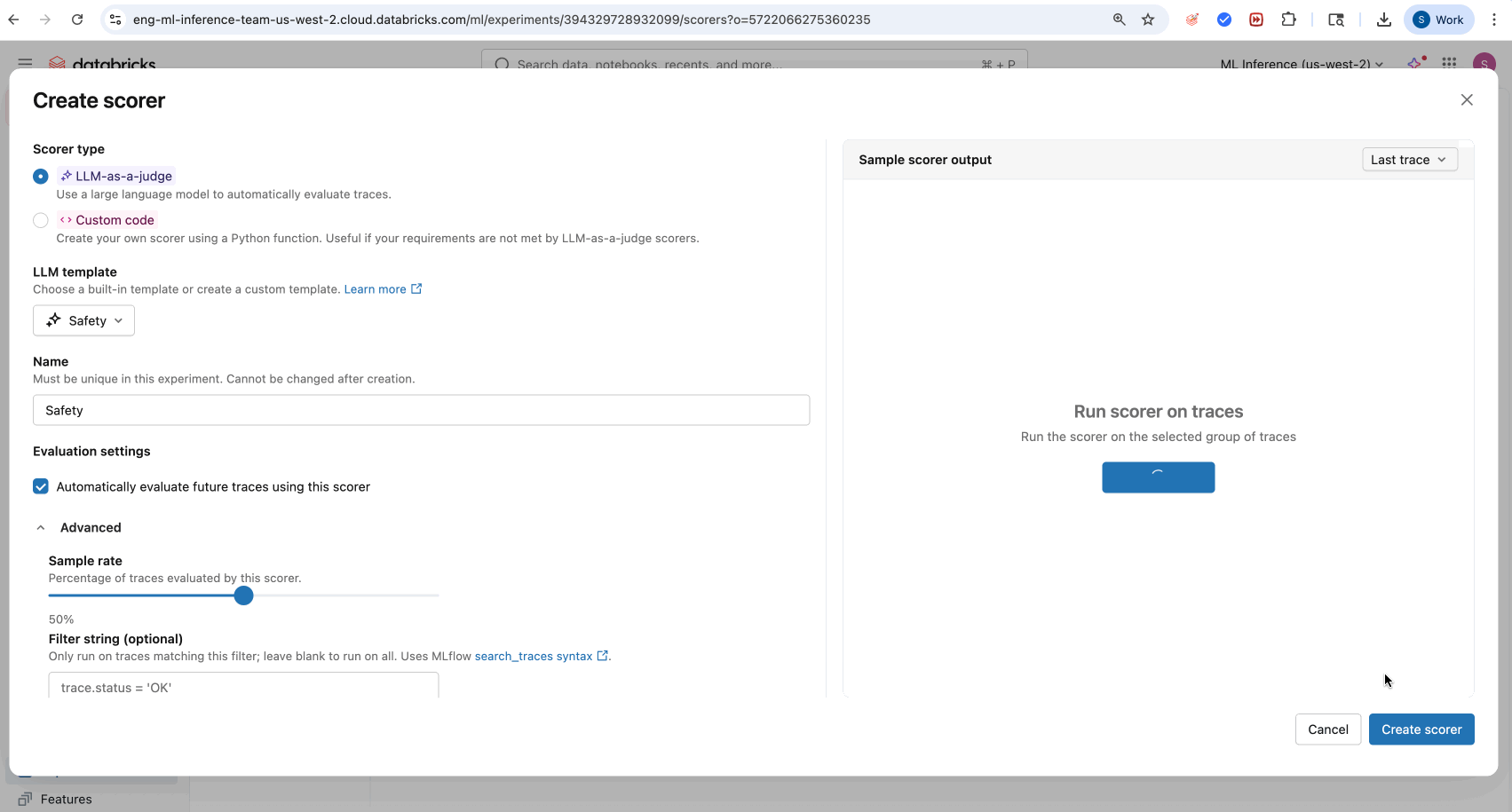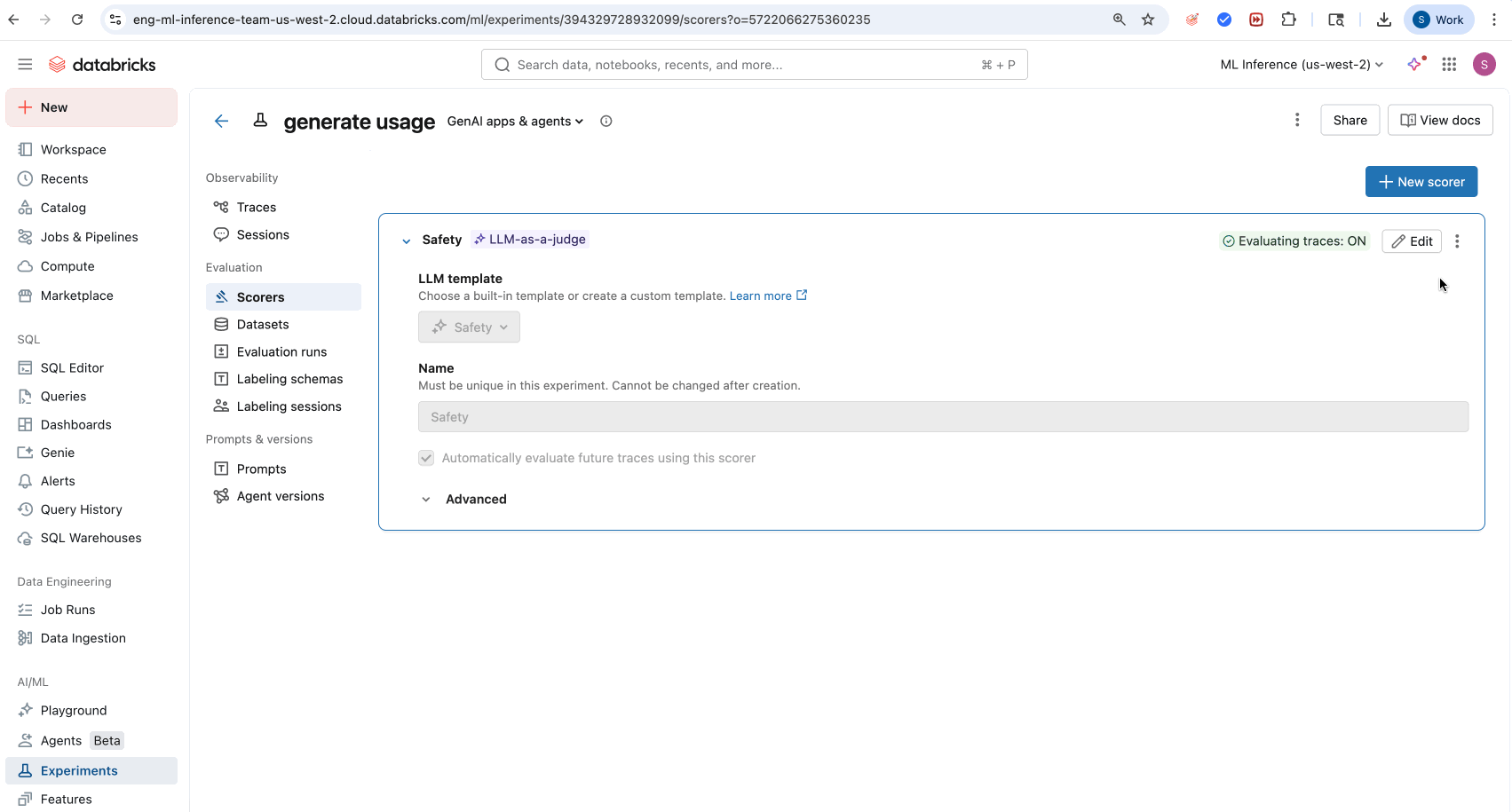
- Acesse a tab "Scorers" na interface do usuário do experimento MLflow .
- Clique em Novo Marcador .
- Selecione o seu juiz integrado LLM no menu suspenso LLM padrão .
- (Opcional) Clique em Pontuador de execução para executar um subconjunto de seus rastreamentos.
- (Opcional) Ajuste as configurações de avaliação para monitoramento da produção em rastreamentos futuros.
- Clique em Criar marcador .
Use juízes LLM integrados
MLflow fornece vários juízes LLM integrados que você pode usar imediatamente para monitoramento.
from mlflow.genai.scorers import Safety, ScorerSamplingConfig
# Register the scorer with a name and start monitoring
safety_judge = Safety().register(name="my_safety_judge") # name must be unique to experiment
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
Por default, cada juiz usa um LLM hospedado Databricks , projetado para realizar avaliações de qualidade do GenAI. Você pode alterar o modelo do juiz para usar um endpoint do modelo de atendimento Databricks usando o argumento model na definição do pontuador. O modelo deve ser especificado no formato databricks:/<databricks-serving-endpoint-name>.
safety_judge = Safety(model="databricks:/databricks-gpt-oss-20b").register(name="my_custom_safety_judge")
Diretrizes de uso para juízes do LLM
As diretrizes para o exame LLM definem que os avaliadores devem analisar as entradas e saídas usando critérios de linguagem natural de aprovação/reprovação.
from mlflow.genai.scorers import Guidelines
# Create and register the guidelines scorer
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"]
).register(name="is_english") # name must be unique to experiment
# Start monitoring with the specified sample rate
english_judge = english_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
Assim como os juízes integrados, você pode alterar o modelo do juiz para usar um endpoint do modelo servindo Databricks .
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"],
model="databricks:/databricks-gpt-oss-20b",
).register(name="custom_is_english")
Use juízes LLM com prompts personalizados
Para maior flexibilidade do que os avaliadores das Diretrizes, utilize os Avaliadores LLM com instruções personalizadas , que permitem uma avaliação de qualidade em vários níveis com categorias de escolha personalizáveis.
from typing import Literal
from mlflow.genai import make_judge
from mlflow.genai.scorers import ScorerSamplingConfig
# Create a custom judge using make_judge
formality_judge = make_judge(
name="formality",
instructions="""You will look at the response and determine the formality of the response.
Request: {{ inputs }}
Response: {{ outputs }}
Evaluate whether the response is formal, somewhat formal, or not formal.
A response is somewhat formal if it mentions friendship, etc.""",
feedback_value_type=Literal["formal", "semi_formal", "not_formal"],
model="databricks:/databricks-gpt-oss-20b", # optional
)
# Register the custom judge and start monitoring
registered_judge = formality_judge.register(name="my_formality_judge") # name must be unique to experiment
registered_judge = registered_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.1))
Use funções personalizadas de pontuação
Para máxima flexibilidade, defina e utilize uma função de pontuação personalizada.
:::importante Requisitos de pontuação personalizados para monitoramento de produção
- Apenas os avaliadores baseados em decoradores
@scorersão suportados. Subclasses baseadas em classesScorernão podem ser registradas para monitoramento de produção. Se você precisar de um avaliador baseado em classe, refatore-o para usar o decorador@scorerem vez disso. - Os avaliadores devem ser definidos e registrados a partir de um Notebook Databricks . O serviço de monitoramento serializa o código da função de pontuação para execução remota, e essa serialização requer o ambiente Notebook. Os indicadores de pontuação definidos em arquivos Python independentes ou em ambientes IDE locais não podem ser serializados para monitoramento em produção.
- Os marcadores devem ser autossuficientes. Como as funções de pontuação são serializadas como código para execução remota, todas as importações devem ser feitas diretamente no corpo da função. A função não pode referenciar variáveis, objetos ou módulos definidos fora dela.
:::
Ao definir avaliadores personalizados, não utilize dicas de tipo que precisem ser importadas na assinatura da função. Se o corpo da função de avaliação usar pacotes que precisam ser importados, importe-os diretamente na função para garantir a serialização correta.
Alguns pacotes estão disponíveis em default sem a necessidade de uma importação inline. Estes incluem databricks-agents, mlflow-skinny, openai e todos os pacotes incluídos na versão 2 do ambiente sem servidor.
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
# Custom metric: Check if response mentions Databricks
@scorer
def mentions_databricks(outputs):
"""Check if the response mentions Databricks"""
return "databricks" in str(outputs.get("response", "")).lower()
# Custom metric: Response length check
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(str(outputs.get("response", "")))
# Custom metric with multiple inputs
@scorer
def response_relevance_score(inputs, outputs):
"""Score relevance based on keyword matching"""
query = str(inputs.get("query", "")).lower()
response = str(outputs.get("response", "")).lower()
# Simple keyword matching (replace with your logic)
query_words = set(query.split())
response_words = set(response.split())
if not query_words:
return 0.0
overlap = len(query_words & response_words)
return overlap / len(query_words)
# Register and start monitoring custom scorers
databricks_scorer = mentions_databricks.register(name="databricks_mentions")
databricks_scorer = databricks_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
length_scorer = response_length.register(name="response_length")
length_scorer = length_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
relevance_scorer = response_relevance_score.register(name="response_relevance_score") # name must be unique to experiment
relevance_scorer = relevance_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
Use juízes de múltiplas rodadas
O monitoramento de produção oferece suporte a avaliadores de múltiplas interações que avaliam conversas inteiras em vez de registros individuais. Esses avaliadores analisam padrões de qualidade que emergem ao longo de múltiplas interações, como frustração do usuário, completude da conversa e retenção de conhecimento.
Os juízes de múltiplas voltas são registrados e começam exatamente como os juízes de volta única. O trabalho de monitoramento agrupa automaticamente os rastreamentos em conversas com base na tag mlflow.trace.session . O recurso de julgamentos de múltiplas rodadas avalia a execução após uma conversa ser considerada completa — por default, uma conversa é considerada completa quando nenhum novo rastreamento com esse ID de sessão é ingerido por 5 minutos . Para configurar este buffer, configure a MLFLOW_ONLINE_SCORING_DEFAULT_SESSION_COMPLETION_BUFFER_SECONDS variável de ambiente no Job de monitoramento.
Para usar juízes de múltiplas rodadas, seu agente deve definir IDs de sessão nos rastreamentos. Consulte a seção "Rastrear usuários e sessões" para obter detalhes.
from mlflow.genai.scorers import (
ConversationCompleteness,
UserFrustration,
ConversationalSafety,
ScorerSamplingConfig,
)
# Register and start multi-turn judges just like single-turn judges
completeness_scorer = ConversationCompleteness().register(name="conversation_completeness")
completeness_scorer = completeness_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
frustration_scorer = UserFrustration().register(name="user_frustration")
frustration_scorer = frustration_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
safety_scorer = ConversationalSafety().register(name="conversational_safety")
safety_scorer = safety_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5),
)
Para obter a lista completa de juízes de múltiplas rodadas disponíveis, consulte Juízes de múltiplas rodadas. Para obter detalhes sobre a avaliação de conversas, consulte Avaliar conversas.
Configuração de vários marcadores
Para uma configuração de monitoramento abrangente, registre-se e comece vários marcadores individualmente. É possível combinar juízes de turno único e juízes de múltiplos turnos no mesmo experimento.
from mlflow.genai.scorers import Safety, Guidelines, UserFrustration, ScorerSamplingConfig, list_scorers
# Register single-turn judges
safety_judge = Safety().register(name="safety") # name must be unique within an MLflow experiment
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0), # Check all traces
)
guidelines_judge = Guidelines(
name="english",
guidelines=["Response must be in English"]
).register(name="english_check")
guidelines_judge = guidelines_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5), # Sample 50%
)
# Register multi-turn judges alongside single-turn judges
frustration_judge = UserFrustration().register(name="user_frustration")
frustration_judge = frustration_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0), # Check all sessions
)
# List and manage all judges (both single-turn and multi-turn)
all_scorers = list_scorers()
for scorer in all_scorers:
if scorer.sample_rate > 0:
print(f"{scorer.name} is active")
else:
print(f"{scorer.name} is stopped")
Ciclo de vida do marcador
Os ciclos de vida dos avaliadores são centrados em experimentos do MLflow. A tabela a seguir lista os estados do ciclo de vida do avaliador.
Os marcadores são imutáveis , portanto, uma operação de ciclo de vida não modifica o marcador original. Em vez disso, retorna uma nova instância de avaliador.
Status | Descrição | API |
|---|---|---|
Não registrado | A função de pontuação está definida, mas não é conhecida pelo servidor. | |
Registrado | O avaliador está registrado no experimento MLflow ativo. | |
Ativas | O Scorer está sendo executado com uma taxa de amostragem > 0. | |
Parado | O sistema de pontuação está registrado, mas não está em execução (taxa de amostragem = 0). | |
Excluído | O avaliador foi removido do servidor e não está mais associado ao experimento MLflow. |
Ciclo de vida básico do scorer
from mlflow.genai.scorers import Safety, scorer, ScorerSamplingConfig
# Built-in scorer lifecycle
safety_judge = Safety().register(name="safety_check")
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
safety_judge = safety_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
safety_judge = safety_judge.stop()
delete_scorer(name="safety_check")
# Custom scorer lifecycle
@scorer
def response_length(outputs):
return len(str(outputs.get("response", "")))
length_scorer = response_length.register(name="length_check")
length_scorer = length_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5),
)
marcadores
As seguintes APIs estão disponíveis para gerenciar os avaliadores.
API | Descrição | Exemplo |
|---|---|---|
Liste todos os avaliadores registrados para o experimento atual. | ||
Recupere o nome de um avaliador registrado. | ||
Modifique a configuração de amostragem de um avaliador ativo. Esta é uma operação imutável. | ||
Aplicar retroativamente métricas novas ou atualizadas a registros históricos. | ||
Excluir um avaliador registrado pelo nome. |
Liste os pontuadores atuais.
Para view todos os avaliadores registrados para o seu experimento:
from mlflow.genai.scorers import list_scorers
# List all registered scorers
scorers = list_scorers()
for scorer in scorers:
print(f"Name: {scorer._server_name}")
print(f"Sample rate: {scorer.sample_rate}")
print(f"Filter: {scorer.filter_string}")
print("---")
Obtenha e atualize um marcador.
Para modificar as configurações existentes do marcador:
from mlflow.genai.scorers import get_scorer
# Get existing scorer and update its configuration (immutable operation)
safety_judge = get_scorer(name="safety_monitor")
updated_judge = safety_judge.update(sampling_config=ScorerSamplingConfig(sample_rate=0.8)) # Increased from 0.5
# Note: The original scorer remains unchanged; update() returns a new scorer instance
print(f"Original sample rate: {safety_judge.sample_rate}") # Original rate
print(f"Updated sample rate: {updated_judge.sample_rate}") # New rate
Pare e exclua os marcadores
Para interromper o monitoramento ou remover um avaliador completamente:
from mlflow.genai.scorers import get_scorer, delete_scorer
# Get existing scorer
databricks_scorer = get_scorer(name="databricks_mentions")
# Stop monitoring (sets sample_rate to 0, keeps scorer registered)
stopped_scorer = databricks_scorer.stop()
print(f"Sample rate after stop: {stopped_scorer.sample_rate}") # 0
# Remove scorer entirely from the server
delete_scorer(name=databricks_scorer.name)
# Or restart monitoring from a stopped scorer
restarted_scorer = stopped_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
Atualizações imutáveis
Os avaliadores, incluindo os juízes do LLM, são objetos imutáveis. Ao atualizar um marcador de pontuação, você não modifica o marcador de pontuação original. Em vez disso, é criada uma cópia atualizada do marcador. Essa imutabilidade ajuda a garantir que os marcadores destinados à produção não sejam modificados acidentalmente. O trecho de código a seguir mostra como funcionam as atualizações imutáveis.
# Demonstrate immutability
original_judge = Safety().register(name="safety")
original_judge = original_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.3),
)
# Update returns new instance
updated_judge = original_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
# Original remains unchanged
print(f"Original: {original_judge.sample_rate}") # 0.3
print(f"Updated: {updated_judge.sample_rate}") # 0.8
Avaliar traços históricos (preenchimento de métricas)
É possível aplicar retroativamente métricas novas ou atualizadas a rastreamentos históricos.
Preenchimento básico de métricas utilizando taxas de amostragem atuais
from databricks.agents.scorers import backfill_scorers
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Use existing sample rates for specified scorers
job_id = backfill_scorers(
scorers=["safety_check", "response_length"]
)
Preenchimento de métricas utilizando taxas de amostragem e intervalos de tempo personalizados
from databricks.agents.scorers import backfill_scorers, BackfillScorerConfig
from datetime import datetime
from mlflow.genai.scorers import Safety, Correctness
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Define custom sample rates for backfill
custom_scorers = [
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
]
job_id = backfill_scorers(
experiment_id=YOUR_EXPERIMENT_ID,
scorers=custom_scorers,
start_time=datetime(2024, 6, 1),
end_time=datetime(2024, 6, 30)
)
Preenchimento de dados recentes
from datetime import datetime, timedelta
# Backfill last week's data with higher sample rates
one_week_ago = datetime.now() - timedelta(days=7)
job_id = backfill_scorers(
scorers=[
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
],
start_time=one_week_ago
)
visualizar resultados
Após programar os avaliadores, aguarde 15 a 20 minutos para o processamento inicial. Então:
- Navegue até o seu experimento MLflow.
- Abra o Traces tab para visualizar as avaliações anexadas aos traços.
- Utilize os painéis de monitoramento para acompanhar as tendências de qualidade.
Para juízes com múltiplas rodadas, as avaliações são anexadas ao primeiro traçado em cada sessão. Consulte a seção "Como as avaliações são armazenadas" para obter mais detalhes.
Melhores práticas
Gestão do estado do marcador
- Verifique o estado do avaliador antes das operações usando
sample_rate. - Utilize o padrão imutável. Atribua os resultados de
.start(),.update(),.stop()às variáveis. - Entenda o ciclo de vida do marcador.
.stop()preserva o registro,delete_scorer()remove o marcador completamente.
métricas de preenchimento
- começar pequeno. Comece com intervalos de tempo menores para estimar a duração do trabalho e a utilização dos recursos.
- Use taxas de amostragem apropriadas. Considere as implicações de custo e tempo do uso de altas taxas de amostragem.
Estratégia de amostragem
-
Para pontuações críticas, como verificações de segurança, use
sample_rate=1.0. -
Para avaliadores caros, como juízes LLM complexos, use taxas de amostragem mais baixas (0,05-0,2).
-
Para melhoria iterativa durante o desenvolvimento, use taxas moderadas (0,3-0,5).
-
Equilibre a cobertura com o custo, conforme mostrado nos exemplos a seguir:
Python# High-priority scorers: higher sampling
safety_judge = Safety().register(name="safety")
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0)) # 100% coverage for critical safety
# Expensive scorers: lower sampling
complex_scorer = ComplexCustomScorer().register(name="complex_analysis")
complex_scorer = complex_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.05)) # 5% for expensive operations
Design de marcador personalizado
Mantenha os marcadores personalizados independentes, conforme mostrado no exemplo a seguir:
@scorer
def well_designed_scorer(inputs, outputs):
# All imports inside the function
import re
import json
# Handle missing data gracefully
response = outputs.get("response", "")
if not response:
return 0.0
# Return consistent types
return float(len(response) > 100)
Solução de problemas
Os marcadores não estão correndo
Se os marcadores não estiverem em execução, verifique o seguinte:
- Verifique o experimento : certifique-se de que os rastreamentos são registros do experimento, e não de execuções individuais.
- Taxa de amostragem : Com taxas de amostragem baixas, pode demorar para ver os resultados.
- Verifique as strings de filtro : Certifique-se de que seu
filter_stringcorresponda aos rastreamentos reais.
Problemas de serialização
Os indicadores personalizados para monitoramento de produção são serializados para que possam ser executados remotamente pelo serviço de monitoramento. Isso impõe diversas restrições:
- RequisitoNotebook : Funções personalizadas
@scorerdevem ser definidas e registradas a partir de um Notebook Databricks . O mecanismo de serialização depende do ambiente Notebook. - Funções autocontidas : Todas as importações devem estar embutidas no corpo da função. Referências a variáveis externas, módulos ou objetos definidos fora da função não são capturadas durante a serialização.
- Não há avaliadores baseados em classes : apenas avaliadores baseados em decoradores
@scorerpodem ser registrados. Subclasses baseadas em classesScorernão podem ser serializadas para execução remota. - Sem dicas de tipo que exigem importações : Dicas de tipo na assinatura da função que exigem instruções de importação (por exemplo,
Listdetyping) causam falhas de serialização.
Ao criar um marcador personalizado, inclua as importações na definição da função.
# ❌ Avoid external dependencies
import external_library # Outside function
@scorer
def bad_scorer(outputs):
return external_library.process(outputs)
# ✅ Include imports in the function definition
@scorer
def good_scorer(outputs):
import json # Inside function
return len(json.dumps(outputs))
# ❌ Avoid using type hints in scorer function signature that requires imports
from typing import List
@scorer
def scorer_with_bad_types(outputs: List[str]):
return False
# ❌ Class-based scorers are not supported for production monitoring
class MyScorer(Scorer):
name: str = "my_scorer"
def __call__(self, outputs):
return len(outputs) > 10
problemas de preenchimento de métricas
" Marcador programado 'X' não encontrado no experimento "
- Certifique-se de que o nome do avaliador corresponda a um avaliador registrado em seu experimento.
- Verifique os avaliadores disponíveis usando o método
list_scorers.
Rastros de arquivo
O senhor pode salvar traços e suas avaliações associadas em uma tabela Delta do Unity Catalog para armazenamento de longo prazo e análise avançada. Isso é útil para criar painéis personalizados, realizar análises detalhadas dos dados de rastreamento e manter um registro duradouro do comportamento do seu aplicativo.
O senhor deve ter as permissões necessárias para gravar na tabela Delta do Unity Catalog especificada. A tabela de destino será criada se ainda não existir.
Se a tabela já existir, os traços serão anexados a ela.
Habilitar rastreamentos de arquivamento
- MLflow API
- Databricks UI
Para começar a arquivar rastreamentos para um experimento, use a função enable_databricks_trace_archival. O senhor deve especificar o nome completo da tabela Delta de destino, incluindo o catálogo e o esquema. Se você não fornecer um experiment_id, o arquivamento de rastreamentos será habilitado para o experimento atualmente ativo.
from mlflow.tracing.archival import enable_databricks_trace_archival
# Archive traces from a specific experiment to a Unity Catalog Delta table
enable_databricks_trace_archival(
delta_table_fullname="my_catalog.my_schema.archived_traces",
experiment_id="YOUR_EXPERIMENT_ID",
)
Pare de arquivar rastros para um experimento a qualquer momento usando a função disable_databricks_trace_archival .
from mlflow.tracing.archival import disable_databricks_trace_archival
# Stop archiving traces for the specified experiment
disable_databricks_trace_archival(experiment_id="YOUR_EXPERIMENT_ID")
Para arquivar rastros de um experimento na interface do usuário:
- Acesse a página Experimentos no workspace do Databrick.
- Clique em Sincronização Delta: Não ativada .
- Especifique o nome completo da tabela Delta de destino, incluindo o catálogo e o esquema.
Para desativar o arquivamento de rastreamento:
- Acesse a página Experimentos no workspace do Databrick.
- Clique em Sincronização Delta: Ativada > Desativar sincronização .
Próximos passos
- Crie marcadores personalizados - Crie marcadores adaptados às suas necessidades.
- Avalie conversas - Aprenda sobre avaliação de conversas com múltiplas interações e juízes de múltiplas interações.
- Construir conjunto de dados de avaliação - Usar resultados de monitoramento para melhorar a qualidade.
Guia de referência
- Referência da API de gerenciamento do ciclo de vida do scorer - API e exemplos para gerenciar scorers para monitoramento.
- Pontuadores - Compreenda as métricas que impulsionam o monitoramento.
- Evaluation Harness - Como a avaliação off-line se relaciona com a produção.