Desenvolver pontuadores baseados em código
No MLflow Evaluation for GenAI, pontuadores personalizados baseados em código permitem que você defina métricas de avaliação flexíveis para seu agente ou aplicativo AI .
À medida que você desenvolve marcadores, muitas vezes será necessário iterar rapidamente. Use este fluxo de trabalho do desenvolvedor para atualizar seu scorer sem precisar executar todo o aplicativo novamente a cada vez:
- Definir dados de avaliação
- Gere rastros do seu aplicativo
- Consultar e armazenar os rastros resultantes
- À medida que você itera em seu scorer, avalie usando os rastros armazenados
O exemplo do Notebook contém todo o código deste tutorial.
Pré-requisitos: Configure o MLflow e defina seu aplicativo
Atualize mlflow[databricks] para a versão mais recente para obter a melhor experiência com o GenAI e instale openai , pois o aplicativo de exemplo abaixo usa o cliente OpenAI.
%pip install -q --upgrade "mlflow[databricks]>=3.1" "openai>=1.0.0"
dbutils.library.restartPython()
A chamada mlflow.openai.autolog() abaixo instrumenta automaticamente o aplicativo com o MLflow Tracing. Os traços registrados serão as entradas para os pontuadores durante a avaliação.
import mlflow
mlflow.openai.autolog()
# If running outside of Databricks, set up MLflow tracking to Databricks.
# mlflow.set_tracking_uri("databricks")
# In Databricks notebooks, the experiment defaults to the notebook experiment.
# mlflow.set_experiment("/Shared/docs-demo")
Use o pacote databricks-openai para obter um cliente OpenAI que se conecta a LLMs hospedados no Databricks. Selecione um modelo dentre os modelos de fundação disponíveis:
from databricks_openai import DatabricksOpenAI
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
Crie um aplicativo simples de assistente de resposta a perguntas para este tutorial:
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model= model_name,
messages=messages_for_llm,
)
return response.choices[0].message.content
sample_app([{"role": "user", "content": "What is the capital of France?"}])
o passo 1: Definir dados de avaliação
Os dados de avaliação abaixo são uma lista de solicitações para o LLM responder. Para este aplicativo, as solicitações podem ser perguntas simples ou conversas com várias mensagens.
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
o passo 2: Gerar rastros do seu aplicativo
Use mlflow.genai.evaluate() para gerar rastros do aplicativo. Como evaluate() requer pelo menos um pontuador, defina um pontuador de espaço reservado para esta geração de rastreamento inicial:
from mlflow.genai.scorers import scorer
@scorer
def placeholder_metric() -> int:
# placeholder return value
return 1
avaliação de execução usando o marcador de espaço reservado:
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[placeholder_metric]
)
Depois de executar o código acima, você deve ter um rastreamento em seu experimento para cada linha em seu dataset de avaliação. Databricks Notebook também exibe visualizações de rastreamento como parte dos resultados das células. A resposta do LLM gerada pelo sample_app durante a avaliação aparece no campo Saídas da IU do Notebook Trace e na coluna Resposta da IU do Experimento MLflow .
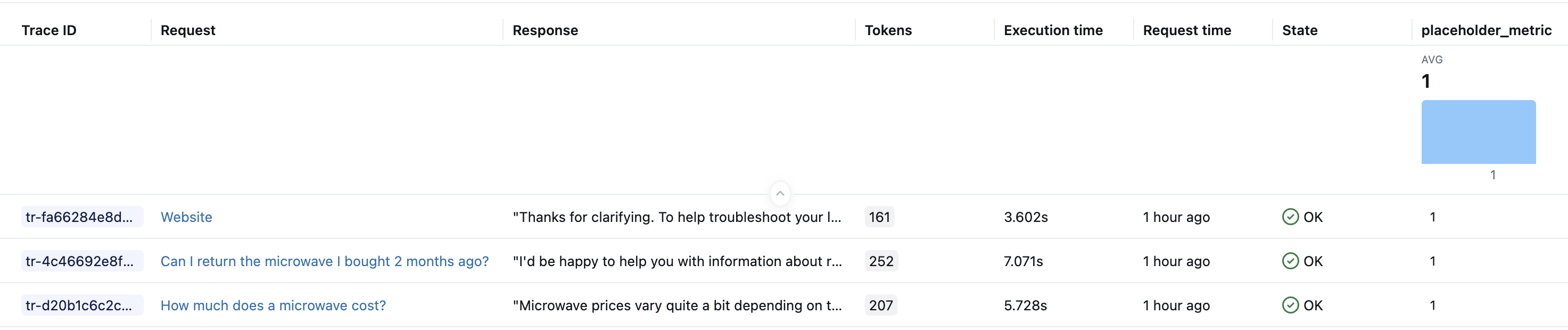
o passo 3: Consultar e armazenar os rastros resultantes
Armazene os rastros gerados em uma variável local. A função mlflow.search_traces() retorna um Pandas DataFrame de rastros.
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
generated_traces
o passo 4: Conforme você itera em seu scorer, chame evaluate() usando os rastreamentos armazenados
Passe o Pandas DataFrame de rastros diretamente para evaluate() como um dataset de entrada. Isso permite que você itere rapidamente em suas métricas sem precisar reexecutar seu aplicativo. O código abaixo executa um novo marcador no generated_traces pré-computado.
from mlflow.genai.scorers import scorer
@scorer
def response_length(outputs: str) -> int:
# Example metric.
# Implement your actual metric logic here.
return len(outputs)
# Note the lack of a predict_fn parameter.
mlflow.genai.evaluate(
data=generated_traces,
scorers=[response_length],
)
Caderno de exemplo
O Notebook a seguir inclui todo o código desta página.
Fluxo de trabalho do desenvolvedor para marcadores baseados em código para avaliação de MLflow
Recursos adicionais
- Pontuadores de LLM personalizados - Saiba mais sobre avaliação semântica usando métricas de LLM como juiz, que podem ser mais simples de definir do que pontuadores baseados em código.
- marcadores de execução em produção - implantou seus marcadores para monitoramento contínuo.
- Crie um conjunto de dados de avaliação - Crie dados de teste para seus avaliadores.
- Referência do avaliador baseado em código - Referência para
@scorereScorer, incluindo assinaturas, entradas, saídas, nomenclatura de métricas, tratamento de erros e acesso a segredos.