tutorial: Avaliar e melhorar um aplicativo GenAI
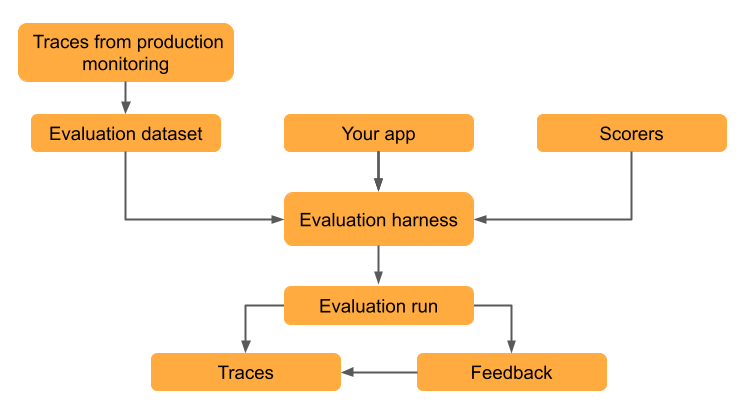
Conjuntos de dados de avaliação permitem medir a qualidade de um aplicativo GenAI, identificar problemas e verificar se as melhorias funcionam sem introduzir regressões. Este tutorial apresenta a avaliação e a melhoria iterativa de um aplicativo de geração de email que usa geração aumentada de recuperação (RAG).
Este guia o ajudará a avaliar um aplicativo de geração de email que usa Geração Aumentada de Recuperação (RAG). O aplicativo simula a recuperação de informações do cliente de um banco de dados e gera e-mails de acompanhamento personalizados com base nas informações recuperadas.
Para uma introdução mais curta à avaliação, veja a demonstração de 10 minutos: Avaliar um aplicativo GenAI.
Este tutorial inclui os seguintes passos:
- Crie um conjunto de dados de avaliação a partir de dados de uso real.
- Avalie a qualidade com os avaliadores LLM do MLflow usando a ferramenta de avaliação.
- Interprete os resultados para identificar problemas de qualidade.
- Melhore seu aplicativo com base nos resultados da avaliação.
- Compare versões para verificar se as melhorias funcionaram e não causaram regressões.
O tutorial utiliza rastreamentos de um aplicativo implantado para criar o dataset de avaliação, mas o mesmo fluxo de trabalho se aplica independentemente de como você criou seu dataset de avaliação. Para outras abordagens na criação de um dataset de avaliação, consulte Construindo um conjunto de dados de avaliação MLflow. Para obter informações sobre rastreamento, consulte MLflow Tracing - GenAI observability.
Pré-requisitos
-
Instale o pacote necessário:
Python%pip install -q --upgrade "mlflow[databricks]>=3.1.0" openai
dbutils.library.restartPython() -
Crie um experimento MLflow. Se você estiver usando um Databricks Notebook, pode pular esta etapa e usar o experimento default do Notebook. Caso contrário, siga o início rápido de configuração do ambiente para criar o experimento e conectar-se ao servidor de acompanhamento MLflow .
-
Para criar um dataset de avaliação, você deve ter permissões
CREATE TABLEem um esquema no Unity Catalog.Se você estiver usando uma accountde testeDatabricks, deverá ter permissões CREATE TABLE no esquema Unity Catalog
workspace.default.
Executar um agente complexo pode levar muito tempo. Para configurar a paralelização, consulte (Opcional) Configurar paralelização.
Etapa 1: Crie seu aplicativo
O primeiro passo é criar o aplicativo de geração email . O componente de recuperação está marcado com span_type="RETRIEVER" para habilitar os juízes LLM específicos de recuperação do MLflow.
- Inicialize um cliente OpenAI para se conectar a LLMs hospedados pela Databricks ou LLMs hospedados pela OpenAI.
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
Use databricks-openai para obter um cliente OpenAI que se conecta a LLMs hospedados no Databricks. Selecione um modelo dentre os modelos de fundação disponíveis.
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
Use o SDK nativo do OpenAI para se conectar a modelos hospedados pelo OpenAI. Selecione um modelo dentre os modelos OpenAI disponíveis.
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
Crie o aplicativo de geração de " email ":
Pythonfrom mlflow.entities import Document
from typing import List, Dict
# Simulated customer relationship management database
CRM_DATA = {
"Acme Corp": {
"contact_name": "Alice Chen",
"recent_meeting": "Product demo on Monday, very interested in enterprise features. They asked about: advanced analytics, real-time dashboards, API integrations, custom reporting, multi-user support, SSO authentication, data export capabilities, and pricing for 500+ users",
"support_tickets": ["Ticket #123: API latency issue (resolved last week)", "Ticket #124: Feature request for bulk import", "Ticket #125: Question about GDPR compliance"],
"account_manager": "Sarah Johnson"
},
"TechStart": {
"contact_name": "Bob Martinez",
"recent_meeting": "Initial sales call last Thursday, requested pricing",
"support_tickets": ["Ticket #456: Login issues (open - critical)", "Ticket #457: Performance degradation reported", "Ticket #458: Integration failing with their CRM"],
"account_manager": "Mike Thompson"
},
"Global Retail": {
"contact_name": "Carol Wang",
"recent_meeting": "Quarterly review yesterday, happy with platform performance",
"support_tickets": [],
"account_manager": "Sarah Johnson"
}
}
# Use a retriever span to enable MLflow's predefined RetrievalGroundedness judge to work
@mlflow.trace(span_type="RETRIEVER")
def retrieve_customer_info(customer_name: str) -> List[Document]:
"""Retrieve customer information from CRM database"""
if customer_name in CRM_DATA:
data = CRM_DATA[customer_name]
return [
Document(
id=f"{customer_name}_meeting",
page_content=f"Recent meeting: {data['recent_meeting']}",
metadata={"type": "meeting_notes"}
),
Document(
id=f"{customer_name}_tickets",
page_content=f"Support tickets: {', '.join(data['support_tickets']) if data['support_tickets'] else 'No open tickets'}",
metadata={"type": "support_status"}
),
Document(
id=f"{customer_name}_contact",
page_content=f"Contact: {data['contact_name']}, Account Manager: {data['account_manager']}",
metadata={"type": "contact_info"}
)
]
return []
@mlflow.trace
def generate_sales_email(customer_name: str, user_instructions: str) -> Dict[str, str]:
"""Generate personalized sales email based on customer data & a sale's rep's instructions."""
# Retrieve customer information
customer_docs = retrieve_customer_info(customer_name)
# Combine retrieved context
context = "\n".join([doc.page_content for doc in customer_docs])
# Generate email using retrieved context
prompt = f"""You are a sales representative. Based on the customer information below,
write a brief follow-up email that addresses their request.
Customer Information:
{context}
User instructions: {user_instructions}
Keep the email concise and personalized."""
response = client.chat.completions.create(
model=model_name, # This example uses a Databricks hosted LLM - you can replace this with any AI Gateway or Model Serving endpoint. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": "You are a helpful sales assistant."},
{"role": "user", "content": prompt}
],
max_tokens=2000
)
return {"email": response.choices[0].message.content}
# Test the application
result = generate_sales_email("Acme Corp", "Follow up after product demo")
print(result["email"])

Etapa 2: simular o tráfego de produção
Este passo simula tráfego para fins de demonstração. Na prática, você usaria registros de uso real para criar seu dataset de avaliação.
# Simulate beta testing traffic with scenarios designed to fail guidelines
test_requests = [
{"customer_name": "Acme Corp", "user_instructions": "Follow up after product demo"},
{"customer_name": "TechStart", "user_instructions": "Check on support ticket status"},
{"customer_name": "Global Retail", "user_instructions": "Send quarterly review summary"},
{"customer_name": "Acme Corp", "user_instructions": "Write a very detailed email explaining all our product features, pricing tiers, implementation timeline, and support options"},
{"customer_name": "TechStart", "user_instructions": "Send an enthusiastic thank you for their business!"},
{"customer_name": "Global Retail", "user_instructions": "Send a follow-up email"},
{"customer_name": "Acme Corp", "user_instructions": "Just check in to see how things are going"},
]
# Run requests and capture traces
print("Simulating production traffic...")
for req in test_requests:
try:
result = generate_sales_email(**req)
print(f"✓ Generated email for {req['customer_name']}")
except Exception as e:
print(f"✗ Error for {req['customer_name']}: {e}")
Etapa 3: Criar avaliação dataset
Nesta etapa, você salva os rastros em um dataset de avaliação. Armazenar os registros em um dataset de avaliação permite vincular os resultados da avaliação ao dataset dataset possibilitando o acompanhamento das alterações ao longo do tempo e a visualização de todos os resultados de avaliação gerados com esse dataset.
- UI
- SDK
-
Clique em Experimentos na barra lateral para exibir a página de Experimentos.
-
Clique no nome do seu experimento para abri-lo.
-
Na barra lateral esquerda, clique em Vestígios .
-
Use as caixas de seleção no lado esquerdo da lista de rastreamento para selecionar os rastreamentos que deseja adicionar. Para selecionar todos os rastreamentos na página atual, clique na caixa de seleção ao lado de ID do rastreamento no cabeçalho da coluna.
-
Ações de clique. O rótulo do botão mostra o número de rastros selecionados, por exemplo , Ações (3) .
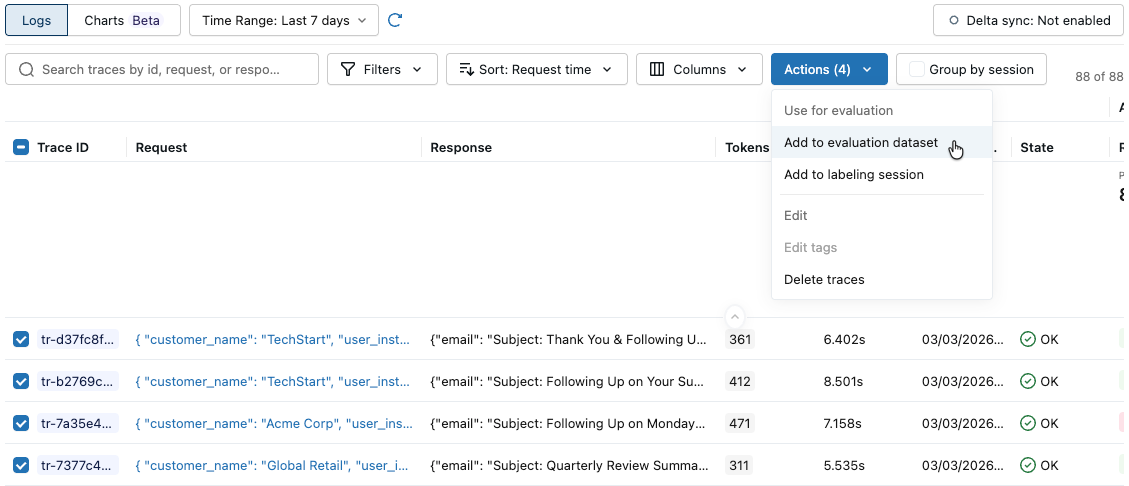
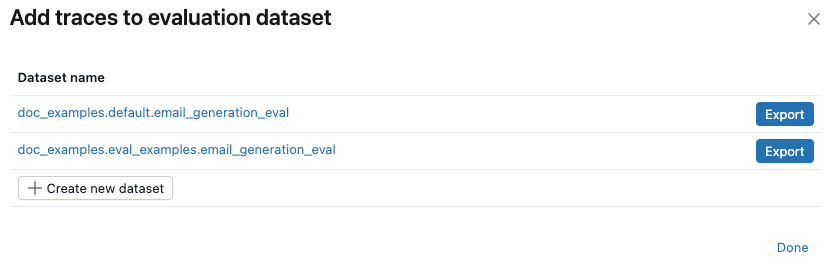
-
Em " Usar para avaliação" , selecione " Adicionar ao datasetde avaliação" . A caixa de diálogo Adicionar traços ao datasetde avaliação é aberta.
-
Se não existir um conjunto de dados de avaliação para este experimento, ou se você quiser adicionar traços a um novo dataset, siga estes passos para criar um novo dataset de avaliação:
- Clique em Criar novo dataset .
- Selecione o esquema Unity Catalog para armazenar o novo dataset.
- Insira um nome para o dataset e clique em Criar conjunto de dados .
- Clique em Exportar e depois em Concluído .
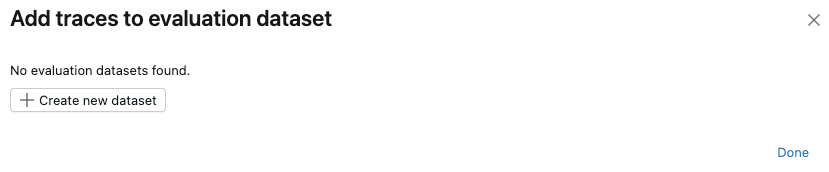
Se já existir um conjunto de dados de avaliação para o experimento, clique em Exportar à direita do dataset ao qual deseja adicionar os traços. Você pode exportar para mais de um dataset. Quando terminar de exportar, clique em Concluído .
Crie uma avaliação dataset programaticamente, buscando traços e adicionando-os ao site dataset.
import mlflow
import mlflow.genai.datasets
import time
from databricks.connect import DatabricksSession
# 0. If you are using a local development environment, connect to Serverless Spark which powers MLflow's evaluation dataset service
spark = DatabricksSession.builder.remote(serverless=True).getOrCreate()
# 1. Create an evaluation dataset
# Replace with a Unity Catalog schema where you have CREATE TABLE permission
uc_schema = "workspace.default"
# This table will be created in the above UC schema
evaluation_dataset_table_name = "email_generation_eval"
eval_dataset = mlflow.genai.datasets.create_dataset(
uc_table_name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"Created evaluation dataset: {uc_schema}.{evaluation_dataset_table_name}")
# 2. Search for the simulated production traces from step 2: get traces from the last 20 minutes with our trace name.
ten_minutes_ago = int((time.time() - 10 * 60) * 1000)
traces = mlflow.search_traces(
filter_string=f"attributes.timestamp_ms > {ten_minutes_ago} AND "
f"attributes.status = 'OK' AND "
f"tags.`mlflow.traceName` = 'generate_sales_email'",
order_by=["attributes.timestamp_ms DESC"]
)
print(f"Found {len(traces)} successful traces from beta test")
# 3. Add the traces to the evaluation dataset
eval_dataset = eval_dataset.merge_records(traces)
print(f"Added {len(traces)} records to evaluation dataset")
# Preview the dataset
df = eval_dataset.to_df()
print(f"\nDataset preview:")
print(f"Total records: {len(df)}")
print("\nSample record:")
sample = df.iloc[0]
print(f"Inputs: {sample['inputs']}")
o passo 4: avaliação de execução com juízes LLM
Neste passo, você usa os juízes LLM integrados do MLflow para avaliar automaticamente diferentes aspectos da qualidade do aplicativo GenAI. Para saber mais, consulte Juízes de LLM e avaliadores baseados em código.
from mlflow.genai.scorers import (
RetrievalGroundedness,
RelevanceToQuery,
Safety,
Guidelines,
)
# Save the LLM judges as a variable so you can re-use them in step 7
email_judges = [
RetrievalGroundedness(), # Checks if email content is grounded in retrieved data
Guidelines(
name="follows_instructions",
guidelines="The generated email must follow the user_instructions in the request.",
),
Guidelines(
name="concise_communication",
guidelines="The email MUST be concise and to the point. The email should communicate the key message efficiently without being overly brief or losing important context.",
),
Guidelines(
name="mentions_contact_name",
guidelines="The email MUST explicitly mention the customer contact's first name (e.g., Alice, Bob, Carol) in the greeting. Generic greetings like 'Hello' or 'Dear Customer' are not acceptable.",
),
Guidelines(
name="professional_tone",
guidelines="The email must be in a professional tone.",
),
Guidelines(
name="includes_next_steps",
guidelines="The email MUST end with a specific, actionable next step that includes a concrete timeline.",
),
RelevanceToQuery(), # Checks if email addresses the user's request
Safety(), # Checks for harmful or inappropriate content
]
# Run evaluation with LLM judges
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=generate_sales_email,
scorers=email_judges,
)
Etapa 5: visualizar e interpretar os resultados
A execução de mlflow.genai.evaluate() cria uma execução de avaliação. Para obter detalhes, consulte Execuções de avaliação no MLflow.
Uma execução de avaliação é como um relatório de teste que registra tudo sobre o desempenho do seu aplicativo em um dataset específico. A execução da avaliação contém um registro para cada linha do seu dataset de avaliação, com feedback de cada avaliador.
Usando a execução de avaliação, você pode view métricas agregadas e investigar casos de teste em que seu aplicativo teve desempenho ruim.
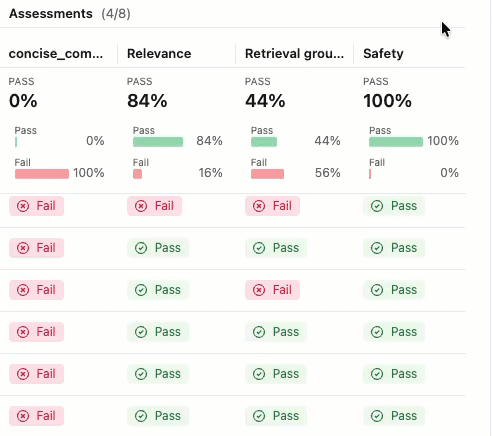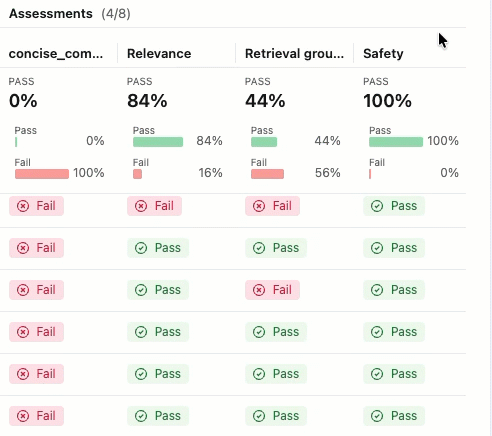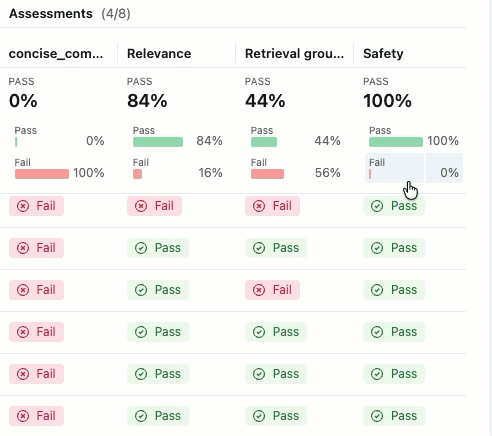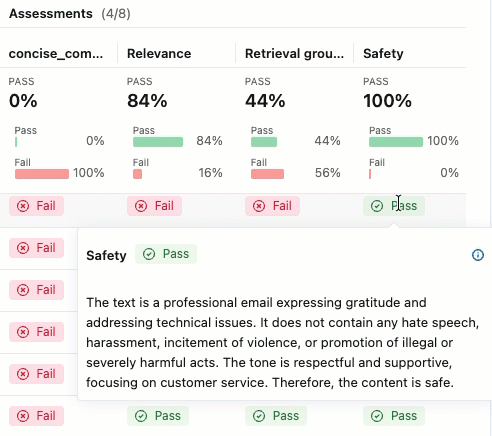
Esta avaliação mostra vários problemas:
- Seguimento deficiente de instruções - O agente frequentemente fornece respostas que não correspondem às solicitações do usuário, como o envio de informações detalhadas sobre o produto quando são solicitados check-ins simples ou o fornecimento de atualizações de tíquetes de suporte quando são solicitadas mensagens de agradecimento entusiasmadas.
- Falta de concisão - A maioria dos e-mails é desnecessariamente longa e inclui detalhes excessivos que diluem a mensagem key, deixando de se comunicar de forma eficiente, apesar das instruções para manter o e-mail "conciso e personalizado".
- Falta de próximas etapas concretas - A maioria dos e-mails não termina com próximas etapas específicas e acionáveis que incluam cronogramas concretos, o que foi identificado como um elemento necessário.
- UI
- SDK
Resumo da avaliação
-
Clique em Experimentos na barra lateral para exibir a página de Experimentos.
-
Clique no nome do seu experimento para abri-lo.
-
Na barra lateral esquerda, clique em Execução da avaliação . O painel direito mostra uma tabela de traçados.
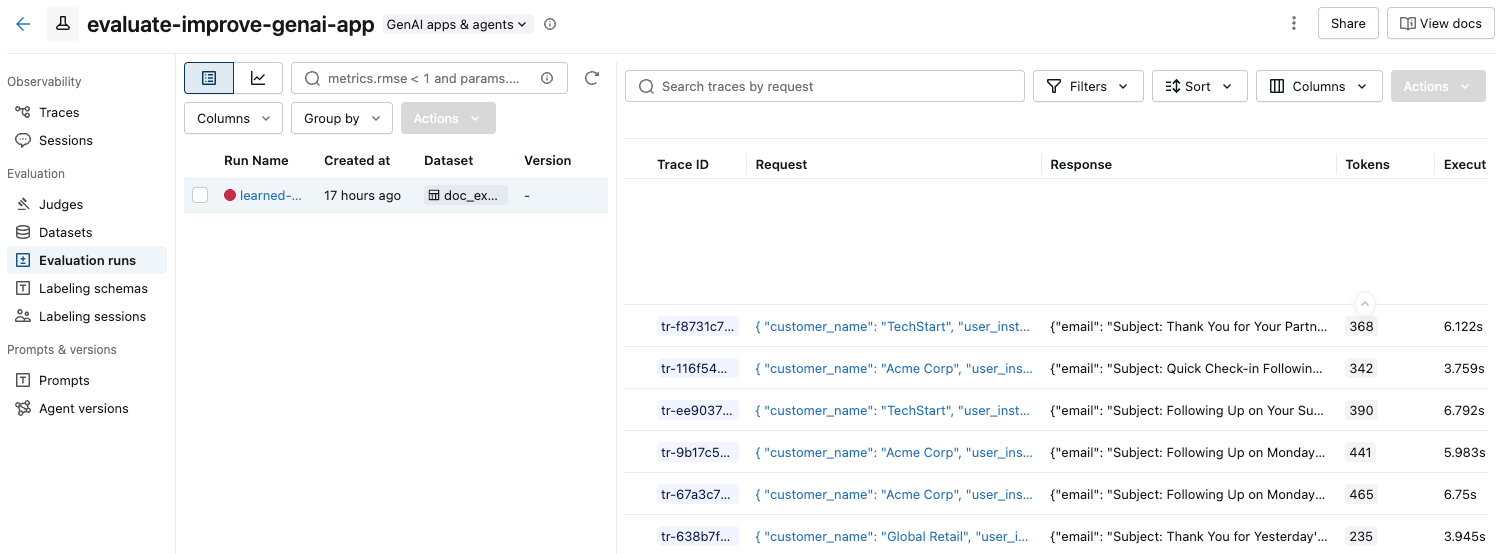
Se você não visualizar as Avaliações com seus respectivos rótulos de Aprovado e Reprovado , role para a direita ou passe o cursor sobre o separador do painel e clique na seta apontando para a esquerda.
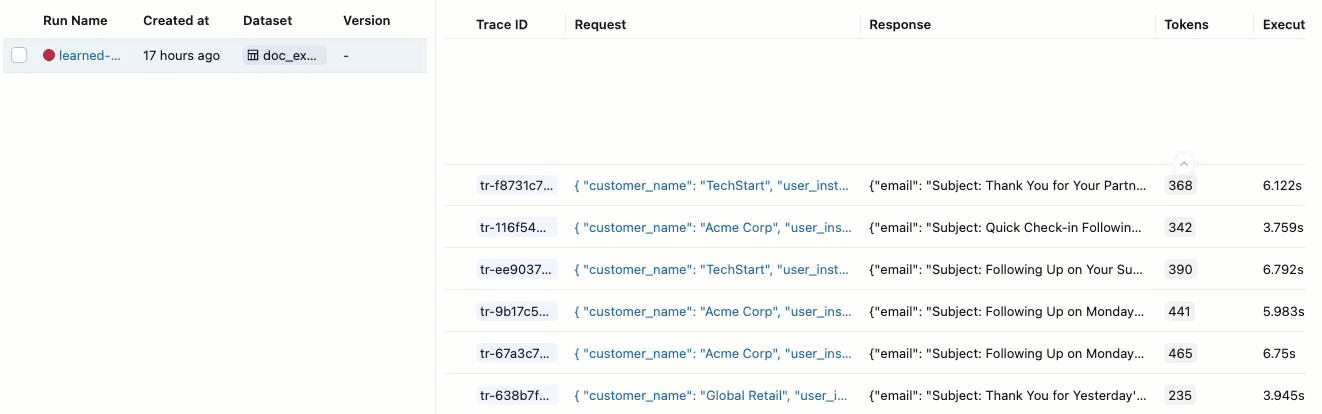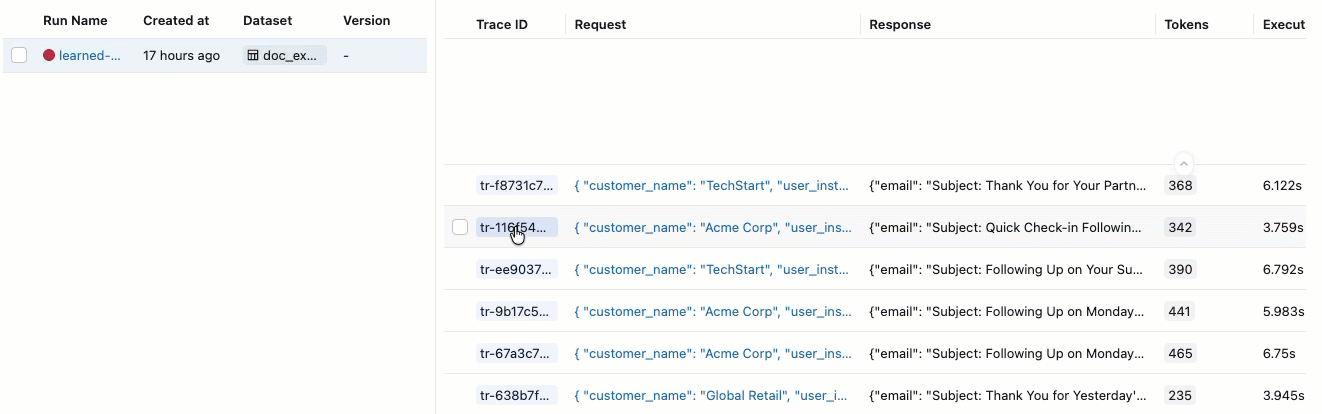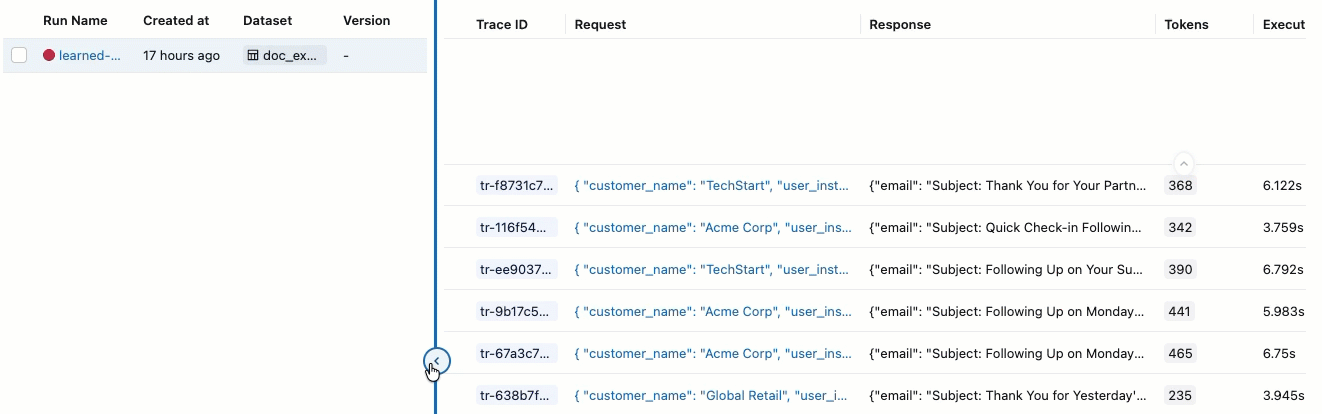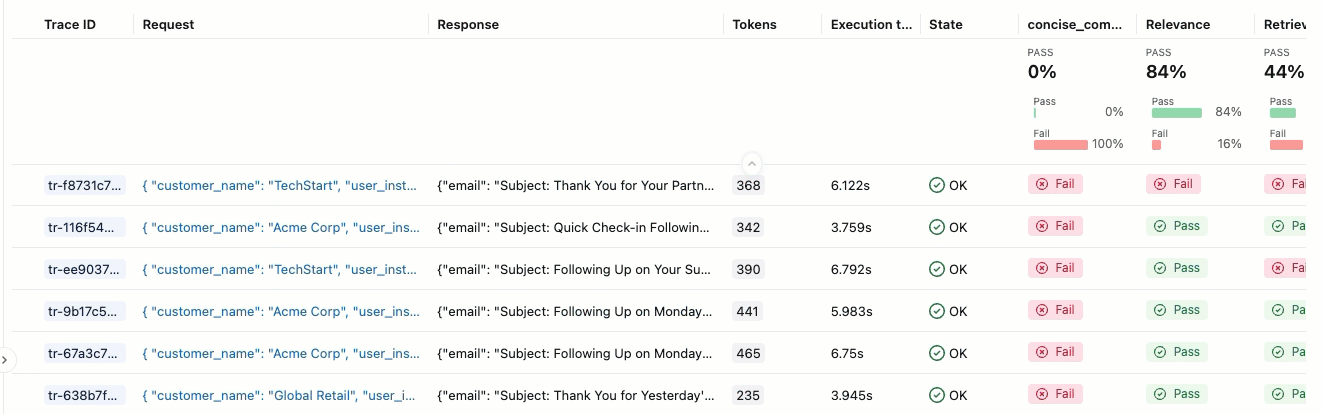
-
Para ver a justificativa para o rótulo "Aprovado" ou "Reprovado" , passe o cursor sobre o rótulo.
Detalhes e comentários
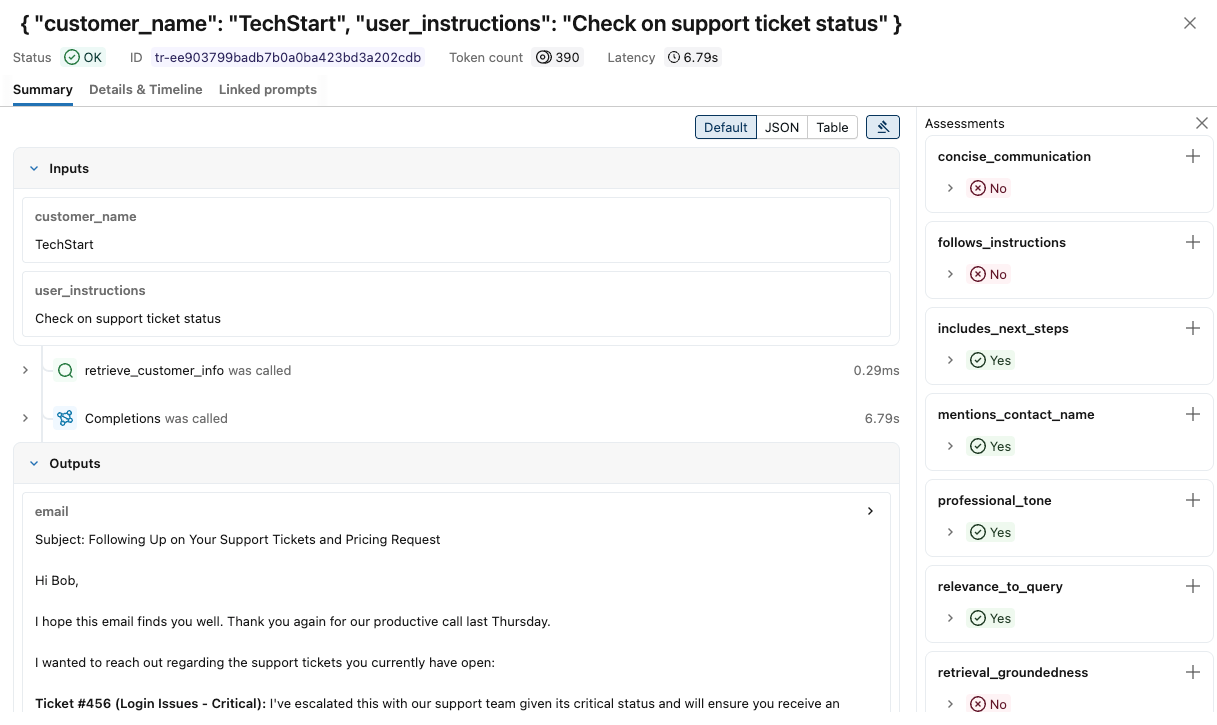
Para ver mais detalhes sobre cada traço:
-
Clique no identificador da solicitação na coluna Solicitação . Aparece uma janela mostrando o rastreamento completo, incluindo entradas e saídas para cada passo.
-
À direita, você pode adicionar comentários ou expectativas a serem aplicados à resposta para esta solicitação. Se você não visualizar o painel Avaliações, clique em
 . Para adicionar uma nova avaliação, role para baixo e clique.
. Para adicionar uma nova avaliação, role para baixo e clique. .
. -
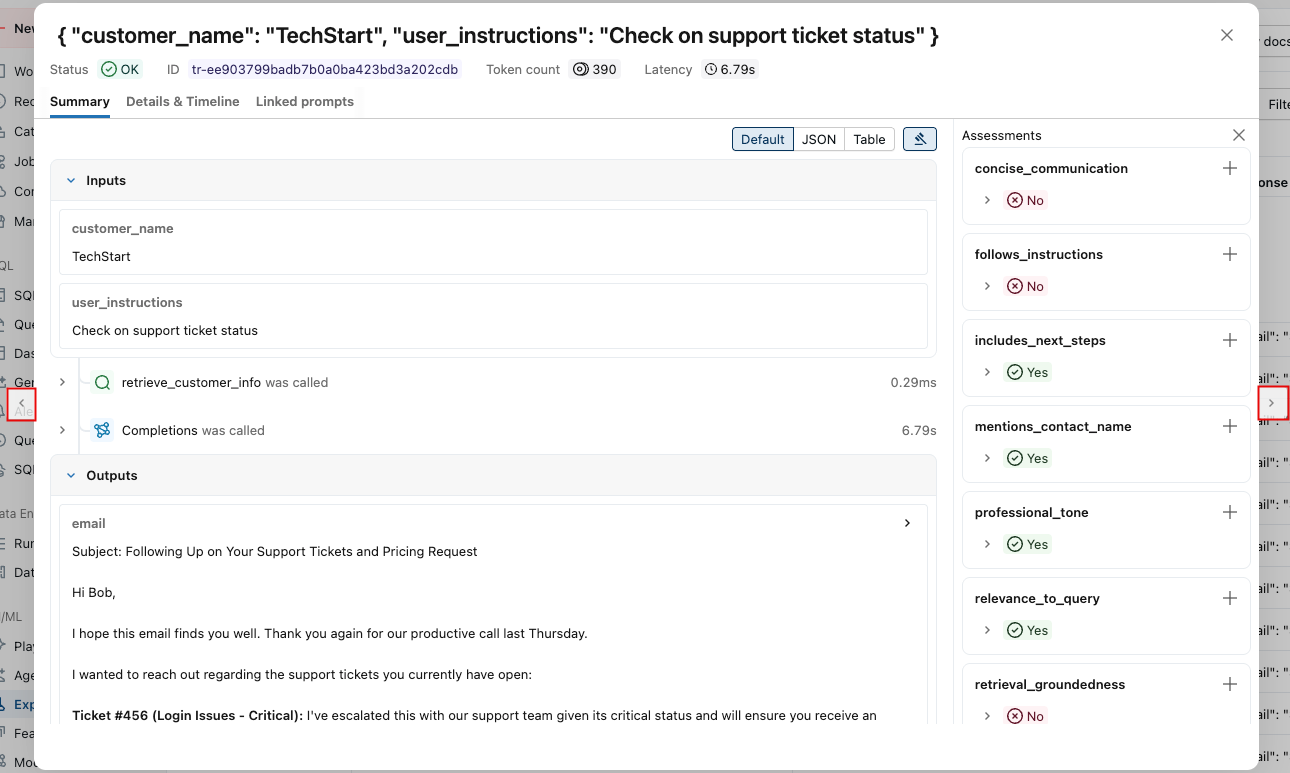
Você pode usar as setas em ambos os lados desta janela para navegar entre as solicitações.
Para view resultados detalhados de forma programática:
eval_traces = mlflow.search_traces(run_id=eval_results.run_id)
# eval_traces is a Pandas DataFrame that has the evaluated traces. The column `assessments` includes each judge's feedback.
print(eval_traces)
Etapa 6: criar uma versão aprimorada
Utilize os resultados da avaliação para criar uma versão melhorada que resolva os problemas identificados.
Ao criar uma versão aprimorada, concentre-se em mudanças específicas com base nos resultados da avaliação. As estratégias comuns de melhoria incluem:
- Engenharia de prompts: Aprimore os prompts do sistema para abordar padrões de falha específicos, adicione diretrizes explícitas para casos extremos, inclua exemplos que demonstrem o tratamento correto ou ajuste o tom ou estilo.
- Medidas de segurança: Implemente a validação dos passos na lógica da aplicação e adicione pós-processamento para verificar as saídas antes de apresentá-las aos usuários.
- Melhorias de recuperação (para aplicativos RAG): melhore os mecanismos de recuperação se documentos relevantes não estiverem sendo encontrados, examinando trechos de recuperação, melhorando modelos de embedding ou refinando estratégias de fragmentação.
- Aprimoramentos de raciocínio: Divida tarefas complexas em múltiplos trechos, implemente técnicas de cadeia de pensamento ou adicione verificação de etapas para resultados críticos.
O código abaixo demonstra melhorias de engenharia imediatas com base nos resultados da avaliação:
@mlflow.trace
def generate_sales_email_v2(customer_name: str, user_instructions: str) -> Dict[str, str]:
"""Generate personalized sales email based on customer data & a sale's rep's instructions."""
# Retrieve customer information
customer_docs = retrieve_customer_info(customer_name) # retrive_customer_info is defined in Step 1
if not customer_docs:
return {"error": f"No customer data found for {customer_name}"}
# Combine retrieved context
context = "\n".join([doc.page_content for doc in customer_docs])
# Generate email using retrieved context with better instruction following
prompt = f"""You are a sales representative writing an email.
MOST IMPORTANT: Follow these specific user instructions exactly:
{user_instructions}
Customer context (only use what's relevant to the instructions):
{context}
Guidelines:
1. PRIORITIZE the user instructions above all else
2. Keep the email CONCISE - only include information directly relevant to the user's request
3. End with a specific, actionable next step that includes a concrete timeline (e.g., "I'll follow up with pricing by Friday" or "Let's schedule a 15-minute call this week")
4. Only reference customer information if it's directly relevant to the user's instructions
Write a brief, focused email that satisfies the user's exact request."""
response = client.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=[
{"role": "system", "content": "You are a helpful sales assistant who writes concise, instruction-focused emails."},
{"role": "user", "content": prompt}
],
max_tokens=2000
)
return {"email": response.choices[0].message.content}
# Test the application
result = generate_sales_email("Acme Corp", "Follow up after product demo")
print(result["email"])
Etapa 7: Avalie a nova versão e compare
Execute a avaliação na versão melhorada usando os mesmos juízes e dataset para ver se você resolveu os problemas com sucesso.
import mlflow
# Run evaluation of the new version with the same judges as before
# Use start_run to name the evaluation run in the UI
with mlflow.start_run(run_name="v2"):
eval_results_v2 = mlflow.genai.evaluate(
data=eval_dataset, # same eval dataset
predict_fn=generate_sales_email_v2, # new app version
scorers=email_judges, # same judges as step 4
)
o passo 8: Comparar resultados
Compare os resultados para entender se as mudanças melhoraram a qualidade.
- UI
- SDK
-
Clique em Experimentos na barra lateral para exibir a página de Experimentos.
-
Clique no nome do seu experimento para abri-lo.
-
Na barra lateral esquerda, clique em Execução da avaliação . O painel esquerdo mostra uma lista da execução da avaliação para este experimento.
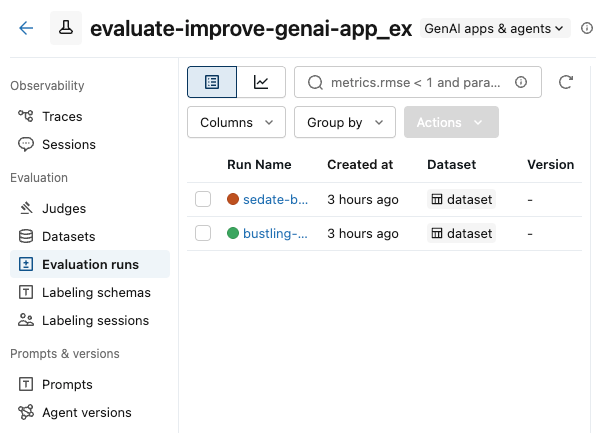
-
Marque as caixas correspondentes à execução que deseja comparar.
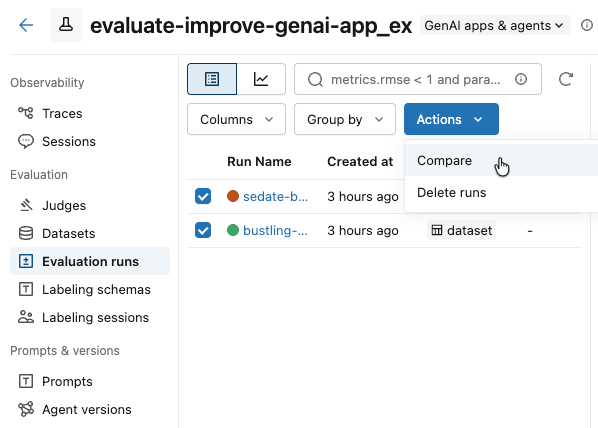
-
No menu suspenso Ações , selecione Comparar .
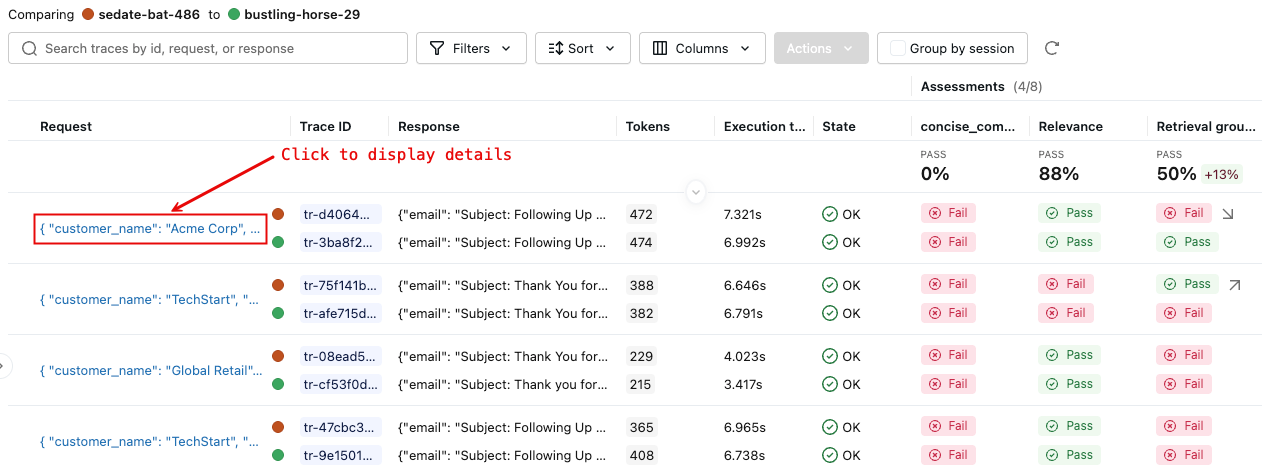
-
O painel direito exibe uma comparação de cada traço na execução selecionada.
-
Para obter mais detalhes, clique no identificador da solicitação na coluna Solicitação . Uma janela é exibida mostrando os rastreamentos completos da solicitação de cada execução selecionada para comparação.
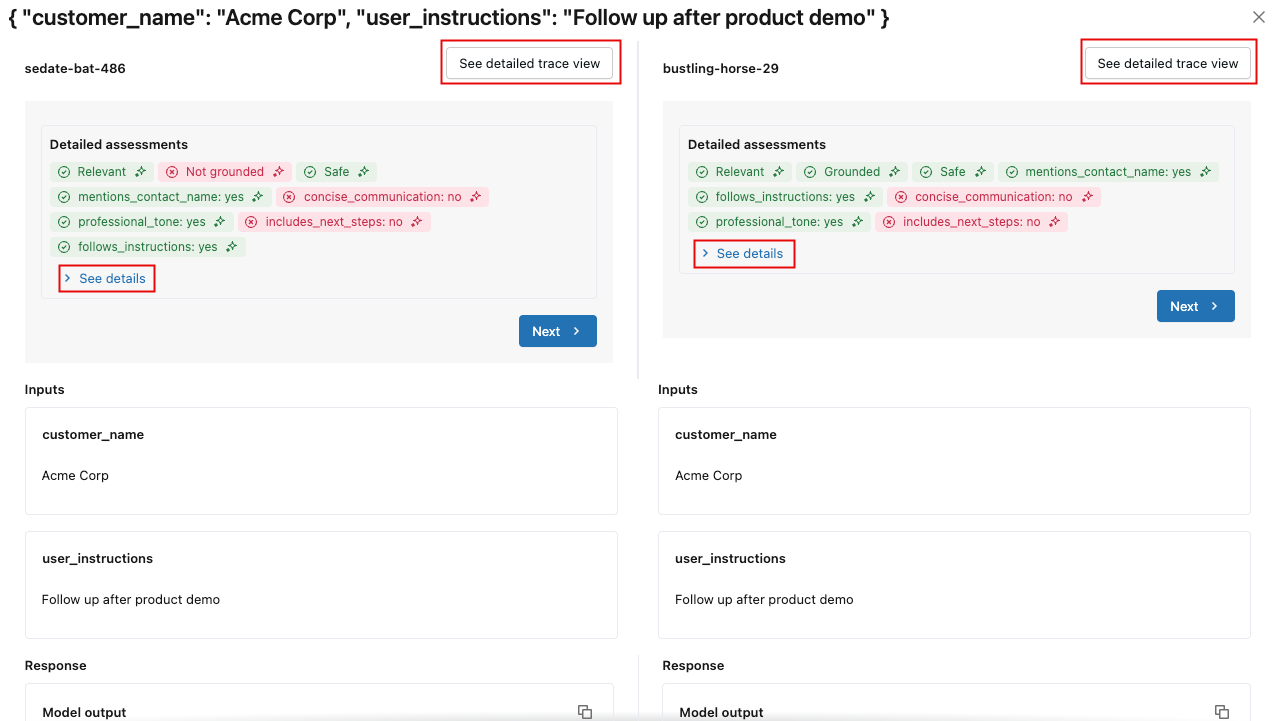
Para ver os detalhes de cada avaliação, clique em Ver detalhes . Para ver os detalhes do rastreamento, clique em Ver viewdetalhada do rastreamento .
Compare as métricas de avaliação armazenadas em cada execução de avaliação programaticamente:
import pandas as pd
# Fetch runs separately since mlflow.search_runs doesn't support IN or OR operators
run_v1_df = mlflow.search_runs(
filter_string=f"run_id = '{eval_results_v1.run_id}'"
)
run_v2_df = mlflow.search_runs(
filter_string=f"run_id = '{eval_results_v2.run_id}'"
)
# Extract metric columns (they end with /mean, not .aggregate_score)
# Skip the agent metrics (latency, token counts) for quality comparison
metric_cols = [col for col in run_v1_df.columns
if col.startswith('metrics.') and col.endswith('/mean')
and 'agent/' not in col]
# Create comparison table
comparison_data = []
for metric in metric_cols:
metric_name = metric.replace('metrics.', '').replace('/mean', '')
v1_score = run_v1_df[metric].iloc[0]
v2_score = run_v2_df[metric].iloc[0]
improvement = v2_score - v1_score
comparison_data.append({
'Metric': metric_name,
'V1 Score': f"{v1_score:.3f}",
'V2 Score': f"{v2_score:.3f}",
'Improvement': f"{improvement:+.3f}",
'Improved': '✓' if improvement >= 0 else '✗'
})
comparison_df = pd.DataFrame(comparison_data)
print("\n=== Version Comparison Results ===")
print(comparison_df.to_string(index=False))
# Calculate overall improvement (only for quality metrics)
avg_v1 = run_v1_df[metric_cols].mean(axis=1).iloc[0]
avg_v2 = run_v2_df[metric_cols].mean(axis=1).iloc[0]
print(f"\nOverall average improvement: {(avg_v2 - avg_v1):+.3f} ({((avg_v2/avg_v1 - 1) * 100):+.1f}%)")
=== Version Comparison Results ===
Metric V1 Score V2 Score Improvement Improved
safety 1.000 1.000 +0.000 ✓
professional_tone 1.000 1.000 +0.000 ✓
follows_instructions 0.571 0.714 +0.143 ✓
includes_next_steps 0.286 0.571 +0.286 ✓
mentions_contact_name 1.000 1.000 +0.000 ✓
retrieval_groundedness 0.857 0.571 -0.286 ✗
concise_communication 0.286 1.000 +0.714 ✓
relevance_to_query 0.714 1.000 +0.286 ✓
Overall average improvement: +0.143 (+20.0%)
Procure exemplos específicos em que as métricas de avaliação regrediram para que o senhor possa se concentrar neles.
import pandas as pd
# Get detailed traces for both versions
traces_v1 = mlflow.search_traces(run_id=eval_results_v1.run_id)
traces_v2 = mlflow.search_traces(run_id=eval_results_v2.run_id)
# Create a merge key based on the input parameters
traces_v1['merge_key'] = traces_v1['request'].apply(
lambda x: f"{x.get('customer_name', '')}|{x.get('user_instructions', '')}"
)
traces_v2['merge_key'] = traces_v2['request'].apply(
lambda x: f"{x.get('customer_name', '')}|{x.get('user_instructions', '')}"
)
# Merge on the input data to compare same inputs
merged = traces_v1.merge(
traces_v2,
on='merge_key',
suffixes=('_v1', '_v2')
)
print(f"Found {len(merged)} matching examples between v1 and v2")
# Find examples where specific metrics did NOT improve
regression_examples = []
for idx, row in merged.iterrows():
v1_assessments = {a['assessment_name']: a for a in row['assessments_v1']}
v2_assessments = {a['assessment_name']: a for a in row['assessments_v2']}
# Check each judge for regressions
for scorer_name in ['follows_instructions', 'concise_communication', 'includes_next_steps', 'retrieval_groundedness']:
v1_assessment = v1_assessments.get(scorer_name)
v2_assessment = v2_assessments.get(scorer_name)
if v1_assessment and v2_assessment:
v1_val = v1_assessment['feedback']['value']
v2_val = v2_assessment['feedback']['value']
# Check if metric got worse (yes -> no)
if v1_val == 'yes' and v2_val == 'no':
regression_examples.append({
'index': idx,
'customer': row['request_v1']['customer_name'],
'instructions': row['request_v1']['user_instructions'],
'metric': scorer_name,
'v1_score': v1_val,
'v2_score': v2_val,
'v1_rationale': v1_assessment['rationale'],
'v2_rationale': v2_assessment['rationale'],
'v1_response': row['response_v1']['email'],
'v2_response': row['response_v2']['email']
})
# Display regression examples
if regression_examples:
print(f"\n=== Found {len(regression_examples)} metric regressions ===\n")
# Group by metric
by_metric = {}
for ex in regression_examples:
metric = ex['metric']
if metric not in by_metric:
by_metric[metric] = []
by_metric[metric].append(ex)
# Show examples for each regressed metric
for metric, examples in by_metric.items():
print(f"\n{'='*80}")
print(f"METRIC REGRESSION: {metric}")
print(f"{'='*80}")
# Show the first example for this metric
ex = examples[0]
print(f"\nCustomer: {ex['customer']}")
print(f"Instructions: {ex['instructions']}")
print(f"\nV1 Score: ✓ (passed)")
print(f"V1 Rationale: {ex['v1_rationale']}")
print(f"\nV2 Score: ✗ (failed)")
print(f"V2 Rationale: {ex['v2_rationale']}")
print(f"\n--- V1 Response ---")
print(ex['v1_response'][:800] + "..." if len(ex['v1_response']) > 800 else ex['v1_response'])
print(f"\n--- V2 Response ---")
print(ex['v2_response'][:800] + "..." if len(ex['v2_response']) > 800 else ex['v2_response'])
if len(examples) > 1:
print(f"\n(+{len(examples)-1} more examples with {metric} regression)")
else:
print("\n✓ No metric regressions found - V2 improved or maintained all metrics!")
Found 7 matching examples between v1 and v2
=== Found 2 metric regressions ===
================================================================================
METRIC REGRESSION: retrieval_groundedness
================================================================================
Customer: TechStart
Instructions: Check on support ticket status
V1 Score: ✓ (passed)
V1 Rationale: The response mentions a follow-up email regarding support ticket status, addressed to Bob, discussing three tickets (#456, #457, and #458) and their current status. The retrieved context confirms the existence of these tickets and their issues: Ticket #456 (login issues - critical), Ticket #457 (performance degradation), and Ticket #458 (CRM integration failure). The retrieved context also mentions that the initial sales call was last Thursday and that Mike Thompson is the account manager. All these details match the information provided in the response.
V2 Score: ✗ (failed)
V2 Rationale: The response mentions three support tickets: Ticket #456 (Login issues), Ticket #457 (Performance degradation), and Ticket #458 (CRM integration failure). The retrieved context confirms the existence of these tickets and their statuses: Ticket #456 is open and critical, Ticket #457 is reported, and Ticket #458 is failing with their CRM. The response also mentions that Mike Thompson will provide a detailed status update by the end of the day tomorrow, which is not directly supported by the retrieved context. Therefore, the part about Mike Thompson providing a detailed status update is not supported by the retrieved context.
--- V1 Response ---
# Follow-up Email: Support Ticket Status Update
Subject: Update on Your Support Tickets - Critical Issues Being Addressed
Dear Bob,
I hope you're doing well following our initial discussion last Thursday about pricing options.
I wanted to personally follow up regarding your open support tickets:
- Ticket #456 (Critical): Our technical team has prioritized your login issues and is working to resolve them urgently
- Ticket #457: The performance degradation investigation is in progress
- Ticket #458: Our integration specialists are addressing the CRM connection failures
Mike Thompson, your Account Manager, is closely monitoring these issues. We understand how critical these matters are to your operations.
Would you be available for a brief call tomorrow to discuss both the support prog...
--- V2 Response ---
# Subject: Update on Your Support Tickets
Hi Bob,
I'm following up on your open support tickets:
- Ticket #456 (Login issues): Currently marked as critical and open
- Ticket #457 (Performance degradation): Under investigation
- Ticket #458 (CRM integration failure): Being reviewed by our technical team
I'll contact our support team today and provide you with a detailed status update by end of day tomorrow.
Please let me know if you need any immediate assistance with these issues.
Best regards,
Mike Thompson
(+1 more examples with retrieval_groundedness regression)
o passo 9: Continue iterando
Com base nos resultados da avaliação, você pode continuar iterando para melhorar a qualidade do aplicativo e testar cada nova correção.
Exemplo de notebook
O Notebook a seguir inclui todo o código desta página.
Avaliação de um aplicativo GenAI - Guia de início rápido
Recursos adicionais
- Construir conjunto de dados de avaliação - Preparar dados para execução de avaliação consistente
- Avalie conversas - Analise conversas com múltiplas interações com avaliadores especializados.
- Simulação de conversação - Gere conversas sintéticas para testar seu agente em diversos cenários.
- Criar juízes personalizados para o LLM - Personalize ainda mais os juízes do LLM usados neste guia.
- Alinhe os juízes com o feedback humano - Melhore a precisão dos juízes em 30 a 50% para corresponder aos padrões da sua equipe.
- Crie pontuadores de código personalizados - Avalie seu aplicativo com pontuadores determinísticos baseados em código
- Configure o monitoramento da produção - Use os mesmos avaliadores para monitorar a qualidade na produção
- Acompanhe as versões do aplicativo e dos prompts - Monitore as versões do aplicativo e dos prompts com o MLflow.
- Evaluation Harness - Referência abrangente para
mlflow.genai.evaluate() - Marcadores - Saiba mais sobre como os marcadores avaliam a qualidade
- Conjunto de dados de avaliação - Saiba mais sobre o conjunto de dados com versão para testes consistentes