Criar e gerenciar sessões de rótulo
As sessões de rótulo oferecem uma maneira estruturada de coletar feedback de especialistas da área sobre o comportamento de seus aplicativos GenAI. Uma sessão de rótulo é um tipo especial de execução MLflow que contém um conjunto específico de rastreamentos que você deseja que especialistas no domínio revisem usando o aplicativo MLflow Review.
O objetivo de uma sessão de rótulo é coletar avaliações geradas por humanos (rótulo) sobre os Traces existentesMLflow. Você pode capturar dados Feedback ou Expectation , que podem então ser usados para melhorar seu aplicativo GenAI por meio de avaliação sistemática. Para obter mais informações sobre a coleta de avaliações durante o desenvolvimento do aplicativo, consulte o rótulo durante o desenvolvimento.
As sessões de rótulo aparecem na tab Avaliações da interface do usuário MLflow . Como as sessões de rótulo são registros da execução MLflow , você também pode acessar os rastreamentos e avaliações associadas usando a API MLflow mlflow.search_runs().
Como funcionam as sessões
Uma sessão de rótulo funciona como um contêiner para rastros e seus rótulos associados, permitindo a coleta sistemática de feedback que pode impulsionar a avaliação e a melhoria do fluxo de trabalho. Ao criar uma sessão de rótulo, você define:
- Nome: Um identificador descritivo para a sessão.
- Usuários designados: Especialistas da área que fornecerão a rotulagem.
- Agente: (Opcional) O aplicativo GenAI para gerar respostas, se necessário.
- Esquemas de rótulo: As perguntas e o formato para a coleta de feedback. Você pode usar esquemas integrados (
EXPECTED_FACTS,EXPECTED_RESPONSE,GUIDELINES) ou criar esquemas personalizados. Consulte Criar e gerenciar esquemas de rótulo para obter informações detalhadas sobre como criar e usar esquemas. - Bate-papo com várias interações: se deve ou não suportar rótulos em estilo de conversa.
O campo opcional Agente conecta uma sessão de rótulo à interface de bate-papo do aplicativo de avaliação para testes interativos. A interface de chat requer um agente implantado em um endpointde modelo de serviço e atualmente não oferece suporte a agentes implantados em Databricks Apps. A revisão e rotulagem dos rastros existentes funciona independentemente de como o agente for implantado.
Para obter detalhes sobre a API LabelingSession, consulte mlflow.genai.LabelingSession.
Criar sessões
Você pode criar sessões de rótulo usando a interface do usuário ou a API.
Os nomes das sessões podem não ser únicos. Use o ID de execução do MLflow (session.mlflow_run_id) para armazenar e referenciar sessões.
Crie sessões usando a interface do usuário.
Para criar uma sessão de rótulo na interface do usuário MLflow :
-
No workspace Databricks , na barra lateral esquerda, clique em Experimentos .
-
Clique no nome do seu experimento para abri-lo.
-
Clique em "rotular sessões" na barra lateral.
-
Clique em Criar sessão . A caixa de diálogo Criar rótulo Sessão é exibida.
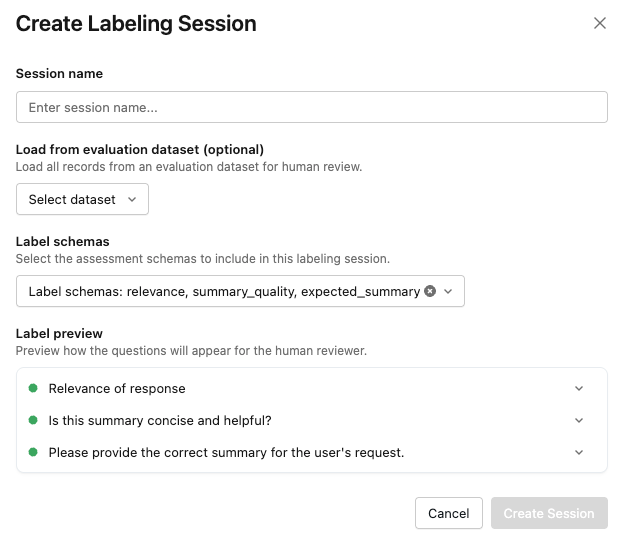
-
Insira um nome para a sessão.
Você também pode, opcionalmente, especificar um dataset de avaliação ou selecionar esquemas de rótulos.
A seção de pré-visualização do rótulo permite que você view como as perguntas aparecem para os revisores.
-
Quando estiver pronto, clique em Criar sessão . A nova sessão aparece na lista do lado esquerdo da página.
-
Para compartilhar a sessão com os revisores, clique no nome da sessão na lista e, em seguida, clique em Compartilhar no canto superior direito.
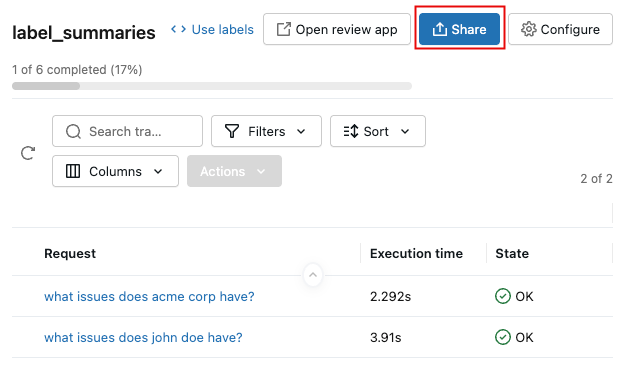
-
Insira um endereço email para cada avaliador e clique em Salvar . Os avaliadores são notificados e recebem acesso ao aplicativo de avaliação.
Ver sessões usando a UI
Para view o feedback dos avaliadores sobre uma sessão, clique no nome da sessão na lista e, em seguida, clique na solicitação.
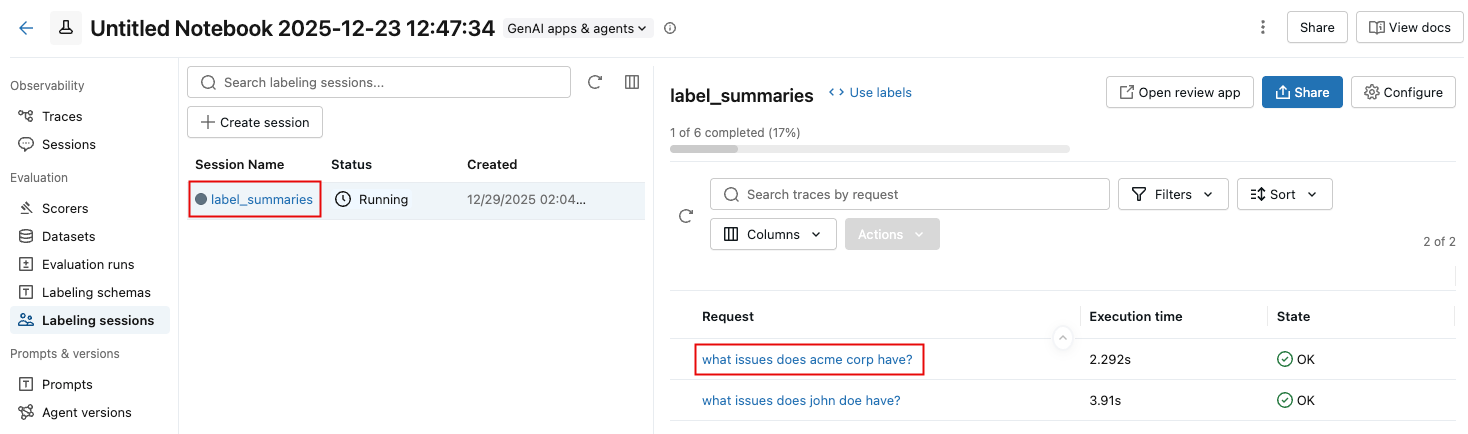
Aparece uma notificação mostrando o rastreamento e as avaliações do revisor. Para visualizar os comentários dos avaliadores, clique em Avaliações no canto superior direito.
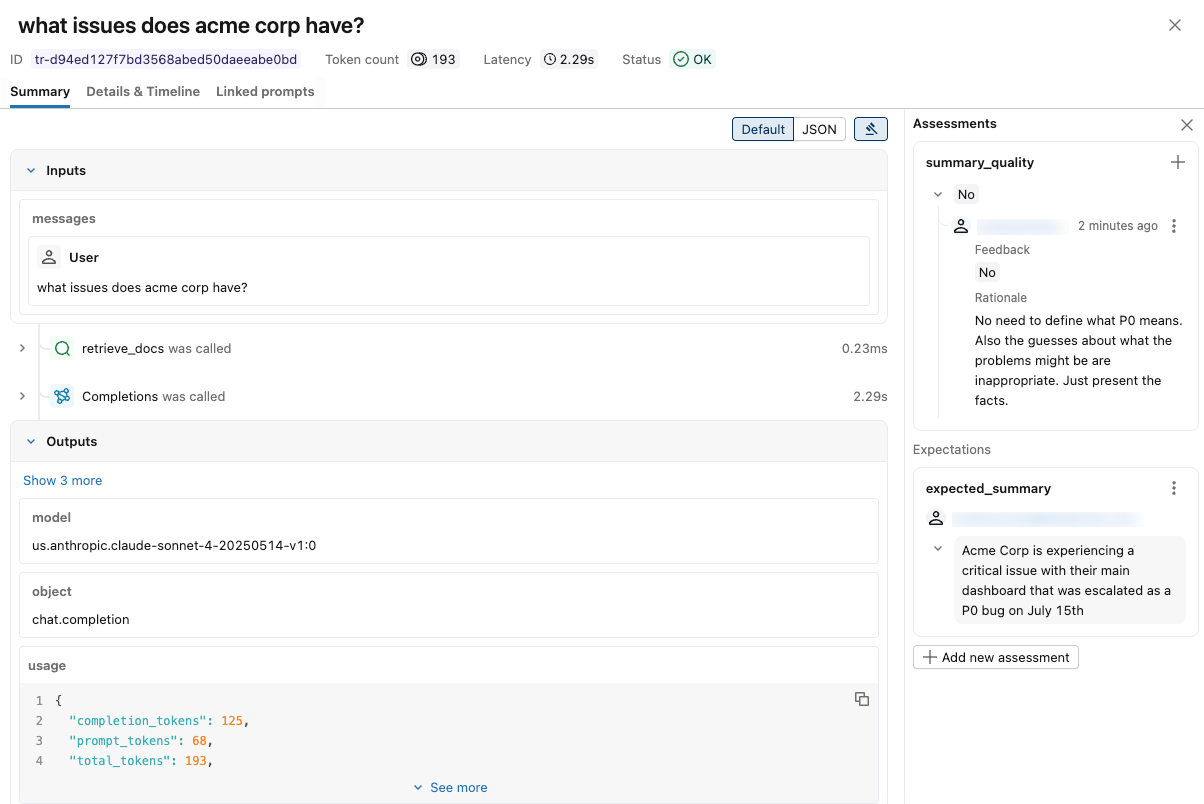
Criar sessões usando a API
Para criar sessões com controle programático completo sobre todas as opções de configuração, use a API MLflow mlflow.genai.labeling.create_labeling_session().
Criar uma sessão básica
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create a simple labeling session with built-in schemas
session = labeling.create_labeling_session(
name="customer_service_review_jan_2024",
assigned_users=["alice@company.com", "bob@company.com"],
label_schemas=[schemas.EXPECTED_FACTS] # Required: at least one schema needed
)
print(f"Created session: {session.name}")
print(f"Session ID: {session.labeling_session_id}")
Criar uma sessão usando esquemas de rótulos personalizados
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create custom schemas first
quality_schema = schemas.create_label_schema(
name="response_quality",
type="feedback",
title="Rate the response quality",
input=schemas.InputCategorical(options=["Poor", "Fair", "Good", "Excellent"]),
overwrite=True,
)
# Create session using the schemas
session = labeling.create_labeling_session(
name="quality_assessment_session",
assigned_users=["expert@company.com"],
label_schemas=["response_quality", schemas.EXPECTED_FACTS],
)
· sessões
Para detalhes da API, consulte mlflow.genai.get_labeling_sessions e mlflow.genai.delete_labeling_sessions.
Recuperar sessões
import mlflow.genai.labeling as labeling
# Get all labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
Agende uma sessão específica.
import mlflow
import mlflow.genai.labeling as labeling
import pandas as pd
# Get all labeling sessions first
all_sessions = labeling.get_labeling_sessions()
# Find session by name (note: names may not be unique)
target_session = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
target_session = session
break
if target_session:
print(f"Session name: {target_session.name}")
print(f"Experiment ID: {target_session.experiment_id}")
print(f"MLflow Run ID: {target_session.mlflow_run_id}")
print(f"Label schemas: {target_session.label_schemas}")
else:
print("Session not found")
# Alternative: Get session by MLflow Run ID (if you know it)
run_id = "your_labeling_session_run_id"
run = mlflow.search_runs(
experiment_ids=["your_experiment_id"],
filter_string=f"tags.mlflow.runName LIKE '%labeling_session%' AND attribute.run_id = '{run_id}'"
).iloc[0]
print(f"Found labeling session run: {run['run_id']}")
print(f"Session name: {run['tags.mlflow.runName']}")
Excluir sessões
import mlflow.genai.labeling as labeling
# Find the session to delete by name
all_sessions = labeling.get_labeling_sessions()
session_to_delete = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
session_to_delete = session
break
if session_to_delete:
# Delete the session (removes from Review App)
review_app = labeling.delete_labeling_session(session_to_delete)
print(f"Deleted session: {session_to_delete.name}")
else:
print("Session not found")
Adicionar rastreamentos às sessões
Após criar uma sessão, você deve adicionar registros a ela para revisão por especialistas. Você pode fazer isso usando a interface do usuário ou a API add_traces() . Para detalhes da API, consulte mlflow.genai.LabelingSession.add_traces.
Para obter detalhes sobre como os rastros são renderizados e exibidos aos rotuladores na interface do usuário do aplicativo Review, incluindo como diferentes tipos de dados (dicionários, mensagens OpenAI, chamadas de ferramentas) são apresentados, consulte Renderização de conteúdo do aplicativo Review.
Adicione rastreamentos usando a interface do usuário.
Para adicionar registros a uma sessão de rótulo:
-
No workspace Databricks , na barra lateral esquerda, clique em Experimentos .
-
Clique no nome do seu experimento para abri-lo.
-
Clique em "Rastros" na barra lateral.
-
Selecione os rastreamentos que deseja adicionar marcando a caixa à esquerda do ID do rastreamento.
-
No menu suspenso Ações , selecione Adicionar à sessão de rótulos .
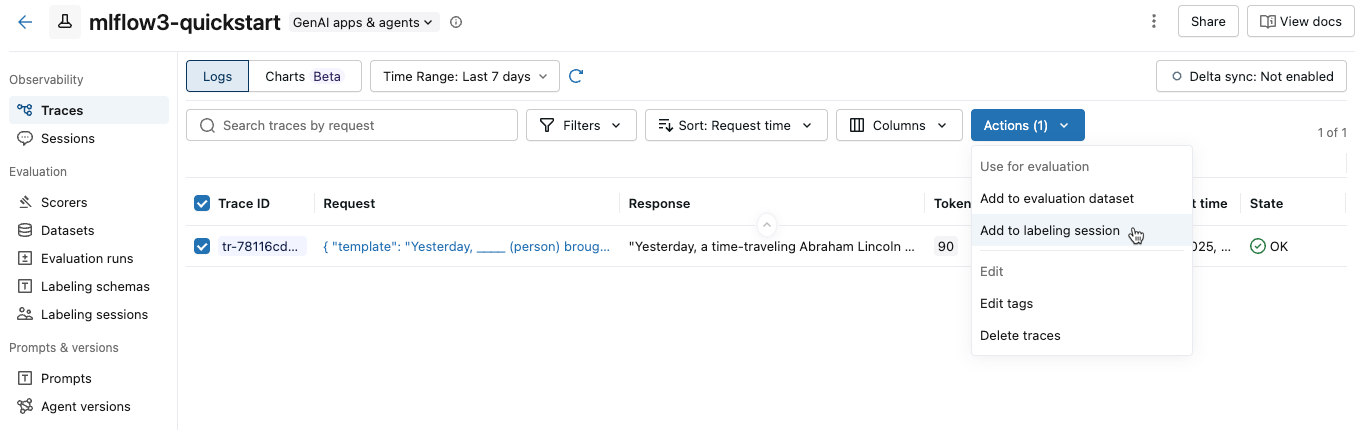
Aparece uma caixa de diálogo mostrando as sessões de rótulo existentes para o experimento.
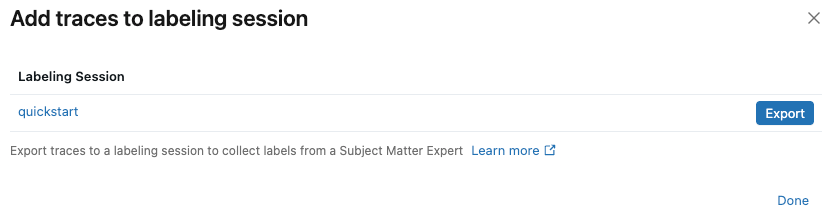
-
Na caixa de diálogo, clique em Exportar ao lado da sessão de rótulo à qual deseja adicionar os rastreamentos e, em seguida, clique em Concluído .
Adicionar rastros dos resultados da pesquisa
- Inicialize um cliente OpenAI para se conectar a LLMs hospedados pela Databricks ou LLMs hospedados pela OpenAI.
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
Use databricks-openai para obter um cliente OpenAI que se conecta a LLMs hospedados no Databricks. Selecione um modelo dentre os modelos de fundação disponíveis.
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
Use o SDK nativo do OpenAI para se conectar a modelos hospedados pelo OpenAI. Selecione um modelo dentre os modelos OpenAI disponíveis.
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
Crie traços de amostra e adicione-os a uma sessão rótulo:
Pythonimport mlflow.genai.labeling as labeling
# First, create some sample traces with a simple app
@mlflow.trace
def support_app(question: str):
"""Simple support app that generates responses"""
mlflow.update_current_trace(tags={"test_tag": "C001"})
response = client.chat.completions.create(
model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": question},
],
)
return {"response": response.choices[0].message.content}
# Generate some sample traces
with mlflow.start_run():
# Create traces with negative feedback for demonstration
support_app("My order is delayed")
support_app("I can't log into my account")
# Now search for traces to label
traces_df = mlflow.search_traces(
filter_string="tags.test_tag = 'C001'", max_results=50
)
# Create session and add traces
session = labeling.create_labeling_session(
name="negative_feedback_review",
assigned_users=["quality_expert@company.com"],
label_schemas=["response_quality", "expected_facts"]
)
# Add traces from search results
session.add_traces(traces_df)
print(f"Added {len(traces_df)} traces to session")
Adicionar objetos de rastreamento individuais
- Inicialize um cliente OpenAI para se conectar a LLMs hospedados pela Databricks ou LLMs hospedados pela OpenAI.
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
Use databricks-openai para obter um cliente OpenAI que se conecta a LLMs hospedados no Databricks. Selecione um modelo dentre os modelos de fundação disponíveis.
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
Use o SDK nativo do OpenAI para se conectar a modelos hospedados pelo OpenAI. Selecione um modelo dentre os modelos OpenAI disponíveis.
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
Crie e adicione objetos de rastreamento individuais a uma sessão de rótulo:
Pythonimport mlflow.genai.labeling as labeling
# Set up the app to generate traces
@mlflow.trace
def support_app(question: str):
"""Simple support app that generates responses"""
mlflow.update_current_trace(tags={"test_tag": "C001"})
response = client.chat.completions.create(
model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": question},
],
)
return {"response": response.choices[0].message.content}
# Generate specific traces for edge cases
with mlflow.start_run() as run:
# Create traces for specific scenarios
support_app("What's your refund policy?")
trace_id_1 = mlflow.get_last_active_trace_id()
support_app("How do I cancel my subscription?")
trace_id_2 = mlflow.get_last_active_trace_id()
support_app("The website is down")
trace_id_3 = mlflow.get_last_active_trace_id()
# Get the trace objects
trace1 = mlflow.get_trace(trace_id_1)
trace2 = mlflow.get_trace(trace_id_2)
trace3 = mlflow.get_trace(trace_id_3)
# Create session and add traces
session = labeling.create_labeling_session(
name="negative_feedback_review",
assigned_users=["name@databricks.com"],
label_schemas=["response_quality", schemas.EXPECTED_FACTS],
)
# Add individual traces
session.add_traces([trace1, trace2, trace3])
Recuperar respostas de feedback
Após os revisores concluírem uma sessão de etiquetagem, o MLflow armazena suas respostas como Assessments nos rastreamentos na sessão. Você pode recuperá-los na IU ou com a API do MLflow.
- UI
- API
Abra a UI de Experimentos , clique na sessão de rotulagem e, em seguida, clique na solicitação. Clique em **Avaliações** no canto superior direito para visualizar as respostas de cada avaliador. Para capturas de tela, consulte Visualizar sessões usando a UI.
Use mlflow.search_traces() com o mlflow_run_id da sessão. O DataFrame retornado inclui uma coluna assessments contendo os rótulos de cada avaliador.
import mlflow
traces = mlflow.search_traces(run_id=session.mlflow_run_id)
print(traces[["trace_id", "assessments"]])
Para obter detalhes da API, consulte mlflow.search_traces.
gerenciar usuários atribuídos
Requisitos de acesso do usuário
Qualquer usuário em Databricks account pode ser atribuído a uma sessão de rótulo, independentemente de ter acesso a workspace. No entanto, conceder permissão a um usuário para uma sessão de rótulo dará a ele acesso ao experimento MLflow da sessão de rótulo.
Configurar permissões para usuários
- Para usuários que não têm acesso workspace ao, um administrador do account usa accounto SCIM provisionamento de nível para sincronizar usuários e grupos automaticamente do provedor de identidade para o Databricks account. O senhor também pode registrar manualmente esses usuários e grupos para dar-lhes acesso quando configurar identidades em Databricks. Consulte Gerenciamento de usuários e grupos.
- Para os usuários que já têm acesso ao site workspace que contém o aplicativo de revisão, não é necessária nenhuma configuração adicional.
Ao atribuir usuários a uma sessão de rótulo, o sistema concede automaticamente as permissões WRITE necessárias no Experimento MLflow que contém a sessão de rótulo. Isso concede aos usuários designados acesso para view e interagir com os dados do experimento.
Adicionar usuários a sessões existentes
Para adicionar usuários a sessões existentes, use set_assigned_users. Para detalhes da API, consulte mlflow.genai.LabelingSession.set_assigned_users.
import mlflow.genai.labeling as labeling
# Find existing session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "customer_review_session":
session = s
break
if session:
# Add more users to the session
new_users = ["expert2@company.com", "expert3@company.com"]
session.set_assigned_users(session.assigned_users + new_users)
print(f"Session now has users: {session.assigned_users}")
else:
print("Session not found")
Substituir usuários atribuídos
import mlflow.genai.labeling as labeling
# Find session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "session_name":
session = s
break
if session:
# Replace all assigned users
session.set_assigned_users(["new_expert@company.com", "lead_reviewer@company.com"])
print("Updated assigned users list")
else:
print("Session not found")
Sincronizar com o conjunto de dados de avaliação
Você pode sincronizar os dados coletados Expectations com o conjunto de dados de avaliação.
Como funciona a sincronização dataset
O método sync() realiza uma operação de upsert inteligente. Para detalhes da API, consulte mlflow.genai.LabelingSession.sync.
- Os dados de entrada de cada rastreamento servem como uma key única para identificar registros no dataset.
- Para rastreamentos com entradas correspondentes, as expectativas da sessão de rótulos sobrescrevem as expectativas existentes no dataset quando os nomes das expectativas são os mesmos.
- Os registros da sessão de rótulo que não correspondem às entradas de registro existentes no dataset são adicionados como novos registros.
- Os registros de dataset existentes com entradas diferentes permanecem inalterados.
Essa abordagem permite que você melhore iterativamente seu dataset de avaliação, adicionando novos exemplos e atualizando os dados de referência para os exemplos existentes.
sincronização de conjuntos de dados
import mlflow.genai.labeling as labeling
# Find session with completed labels by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "completed_review_session":
session = s
break
if session:
# Sync expectations to dataset
session.sync(to_dataset="customer_service_eval_dataset")
print("Synced expectations to evaluation dataset")
else:
print("Session not found")
Melhores práticas
Organização da sessão
-
Use nomes claros, descritivos e com data, como
customer_service_review_march_2024. -
Mantenha as sessões focadas em objetivos de avaliação específicos ou períodos de tempo.
-
Procure analisar de 25 a 100 traços por sessão para evitar a fadiga do revisor.
-
Sempre armazene o
session.mlflow_run_idao criar uma sessão. Use o ID de execução para acesso programático em vez de depender de nomes de sessão, pois o nome da sessão pode não ser exclusivo.Pythonimport mlflow.genai.labeling as labeling
# Good: Store run ID for later reference
session = labeling.create_labeling_session(name="my_session", ...)
session_run_id = session.mlflow_run_id # Store this!
# Later: Use run ID to find session via mlflow.search_runs()
# rather than searching by name through all sessions
Gestão de usuários
- Atribua usuários com base em sua especialização na área e disponibilidade.
- Distribua o trabalho de rotulagem uniformemente entre vários especialistas.
- Lembre-se de que os usuários devem ter acesso ao workspace Databricks .
Recursos adicionais
- rótulo existing traces - Guia passo a passo para usar o rótulo sessions
- Criar esquemas de rótulos personalizados - Definir perguntas de feedback estruturado
- Criar conjunto de dados de avaliação - Converter sessões de rótulo em conjunto de dados de teste