Reúna feedback e expectativas etiquetando os rastros existentes.
Uma das maneiras mais eficazes de aprimorar seu aplicativo GenAI é fazer com que os especialistas no domínio revisem e rotulem os traços existentes. O aplicativo de revisão do MLflow oferece um processo estruturado para coletar esse feedback de especialistas sobre interações reais com seu aplicativo.

Quando rotular os vestígios existentes
Peça a especialistas que analisem as interações existentes com seu aplicativo para fornecer feedback e expectativas.
Use o aplicativo de avaliações para:
- Entenda como são as respostas corretas e de alta qualidade para perguntas específicas.
- Reúna informações para alinhar os juízes do LLM com as necessidades da sua empresa.
- Criar conjunto de dados de avaliação a partir de rastreamentos de produção
Identificar vestígios para análise especializada.
Antes de criar uma sessão de rotulagem, identifique os rastros que se beneficiariam da revisão de especialistas. Foque nos casos que exigem julgamento humano:
- Vestígios com qualidade ambígua ou limítrofe
- Casos extremos não abrangidos pelos juízes automatizados
- Exemplos em que as métricas automatizadas divergem da qualidade esperada.
- Exemplos representativos de diferentes padrões de interação do usuário
Na interface do MLflow, você pode filtrar os rastreamentos por status, tags ou intervalo de tempo. Para seleção programática com filtros avançados, consulte Rastreamentos de consulta via SDK.
Pré-requisitos
-
Você precisa instalar MLflow e o pacote necessário. O recurso descrito neste guia requer a versão 3.1.0 MLflow ou acima. Execute o seguinte comando para instalar ou atualizar o SDK MLflow , incluindo os extras necessários para a integração Databricks :
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
Seu ambiente de desenvolvimento deve estar conectado ao experimentoMLflow , onde os rastreamentos do seu aplicativo GenAI são registrados.
- Siga o tutorial: Conecte seu ambiente de desenvolvimento ao MLflow para conectar seu ambiente de desenvolvimento.
-
Os especialistas de domínio devem ter as seguintes permissões para usar o aplicativo de revisão para rotular rastreamentos existentes:
-
Acesso à conta : É necessário ter permissão de acesso à sua account Databricks , mas não é preciso ter acesso ao seu workspace.
Para usuários sem acesso workspace , os administradores account podem:
- Use o provisionamento SCIM em nível accountpara sincronizar usuários do seu provedor de identidade.
- Registrar manualmente usuários e grupos no Databricks
Consulte a seção Gerenciamento de usuários e grupos para obter detalhes.
-
Acesso ao experimento : permissão
CAN_EDITpara o experimento MLflow.
-
o passo 1: Criar um aplicativo com rastreamento
Antes de poder coletar feedback, você precisa ter os registros de rastreamento do seu aplicativo GenAI. Esses rastreamentos capturam as entradas, saídas e etapas intermediárias da execução do seu aplicativo, incluindo quaisquer chamadas de ferramentas ou ações de recuperação.
Abaixo segue um exemplo de como você pode log rastreamentos. Este exemplo inclui um recuperador fictício para que possamos ilustrar como os documentos recuperados nos rastreamentos são renderizados no aplicativo de revisão. Consulte a seção "Renderização de conteúdo do aplicativo Review" para obter mais informações sobre como o aplicativo Review renderiza os rastros.
- Inicialize um cliente OpenAI para se conectar a LLMs hospedados pela Databricks ou LLMs hospedados pela OpenAI.
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
Use databricks-openai para obter um cliente OpenAI que se conecta a LLMs hospedados no Databricks. Selecione um modelo dentre os modelos de fundação disponíveis.
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
Use o SDK nativo do OpenAI para se conectar a modelos hospedados pelo OpenAI. Selecione um modelo dentre os modelos OpenAI disponíveis.
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
Defina seu aplicativo:
Pythonfrom mlflow.entities import Document
from typing import List, Dict
# Spans of type RETRIEVER are rendered in the Review App as documents.
@mlflow.trace(span_type="RETRIEVER")
def retrieve_docs(query: str) -> List[Document]:
normalized_query = query.lower()
if "john doe" in normalized_query:
return [
Document(
id="conversation_123",
page_content="John Doe mentioned issues with login on July 10th. Expressed interest in feature X.",
metadata={"doc_uri": "http://domain.com/conversations/123"},
),
Document(
id="conversation_124",
page_content="Follow-up call with John Doe on July 12th. Login issue resolved. Discussed pricing for feature X.",
metadata={"doc_uri": "http://domain.com/conversations/124"},
),
]
else:
return [
Document(
id="ticket_987",
page_content="Acme Corp raised a critical P0 bug regarding their main dashboard on July 15th.",
metadata={"doc_uri": "http://domain.com/tickets/987"},
)
]
# Sample app to review traces from
@mlflow.trace
def my_app(messages: List[Dict[str, str]]):
# 1. Retrieve conversations based on the last user message
last_user_message_content = messages[-1]["content"]
retrieved_documents = retrieve_docs(query=last_user_message_content)
retrieved_docs_text = "\n".join([doc.page_content for doc in retrieved_documents])
# 2. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant!"},
{
"role": "user",
"content": f"Additional retrieved context:\n{retrieved_docs_text}\n\nNow, please provide the one-paragraph summary based on the user's request {last_user_message_content} and this retrieved context.",
},
]
# 3. Call LLM to generate the summary
return client.chat.completions.create(
model=model_name, # This example uses :re[DB] hosted claude-sonnet-4-5. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
o passo 2: Definir esquemas de rótulo
Os esquemas de rótulo definem as perguntas e os tipos de entrada que os especialistas de domínio usarão para fornecer feedback sobre seus traços. O senhor pode usar os esquemas integrados do MLflow ou criar esquemas personalizados adaptados aos seus critérios de avaliação específicos.
Há dois tipos principais de esquemas de rótulos:
- Tipo de expectativa (
type="expectation") : Usado quando o especialista fornece uma verdade básica " " ou uma resposta correta. Por exemplo, fornecer oexpected_factspara a resposta de um sistema RAG. Esses rótulos geralmente podem ser usados diretamente no conjunto de dados de avaliação. - Tipo de feedback (
type="feedback") : usado para avaliações, classificações ou classificações subjetivas. Por exemplo, classificar uma resposta em uma escala de 1 a 5 quanto à polidez, ou classificar se uma resposta atende a determinados critérios.
Consulte Criar e gerenciar esquemas de rótulos para entender os vários métodos de entrada para seus esquemas, como opções categóricas, escala numérica ou texto livre.
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
# Collect feedback on the summary
summary_quality = create_label_schema(
name="summary_quality",
type="feedback",
title="Is this summary concise and helpful?",
input=InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True,
overwrite=True,
)
# Collect a ground truth summary
expected_summary = create_label_schema(
name="expected_summary",
type="expectation",
title="Please provide the correct summary for the user's request.",
input=InputText(),
overwrite=True,
)
o passo 3: Crie uma sessão de rótulo
Uma sessão de rótulo é um tipo especial de execução MLflow que organiza um conjunto de rastreamentos para revisão por especialistas específicos, utilizando esquemas de rótulo selecionados. Funciona como uma fila para o processo de revisão.
Consulte Criar e gerenciar sessões de rótulos para obter mais detalhes.
Veja como criar uma sessão de rótulo:
from mlflow.genai.labeling import create_labeling_session
# Create the labeling session with the schemas we created in the previous step
label_summaries = create_labeling_session(
name="label_summaries",
assigned_users=[],
label_schemas=[summary_quality.name, expected_summary.name],
)
o passo 4: Gere rastreamentos e adicione à sessão de rótulos
Após a criação da sua sessão de rótulo, você deve adicionar rastreamentos a ela. Os rastreamentos são copiados para a sessão de rótulos, portanto, quaisquer rótulos ou modificações feitas durante o processo de revisão não afetam os rastreamentos de logs originais.
Você pode adicionar qualquer traço ao seu experimento MLflow. Consulte Criar e gerenciar sessões de rótulos para obter mais detalhes.
Após a geração dos rastreamentos, você também pode adicioná-los à sessão de rótulos selecionando os rastreamentos na tab Rastreamento, clicando em Exportar Rastreamentos e, em seguida, selecionando a sessão de rótulos que você criou anteriormente.
import mlflow
# Use version tracking to be able to easily query for the traces
tracked_model = mlflow.set_active_model(name="my_app")
# Run the app to generate traces
sample_messages_1 = [
{"role": "user", "content": "what issues does john doe have?"},
]
summary1_output = my_app(sample_messages_1)
sample_messages_2 = [
{"role": "user", "content": "what issues does acme corp have?"},
]
summary2_output = my_app(sample_messages_2)
# Query for the traces we just generated
traces = mlflow.search_traces(model_id=tracked_model.model_id)
# Add the traces to the session
label_summaries.add_traces(traces)
# Print the URL to share with your domain experts
print(f"Share this Review App with your team: {label_summaries.url}")
Passo 5: Compartilhe o aplicativo de avaliações com especialistas
Depois que sua sessão de rótulo for preenchida com rastreamentos, você poderá compartilhar seu URL com seus especialistas em domínio. Eles podem usar este URL para acessar o aplicativo de revisão, view os rastreamentos atribuídos a eles (ou selecionar entre os não atribuídos) e fornecer feedback usando os esquemas de rótulos que você configurou.
Seus especialistas de domínio devem ser provisionados em sua account Databricks e ter permissão CAN_EDIT no experimento MLflow . Eles não precisam ter acesso ao seu workspace Databricks . Consulte a seção Pré-requisitos para obter detalhes sobre como configurar o acesso em nível account .

Personalize a interface do usuário do aplicativo de avaliações (opcional)
Para casos de uso que exigem visualização de rastreamento personalizada, interfaces de rótulo personalizadas ou fluxo de trabalho específico, implantamos um aplicativo de revisão personalizável padrão. Este código aberto padrão utiliza as mesmas APIs de backend e modelo de dados MLflow (sessões, esquemas e avaliações do rótulo), ao mesmo tempo que oferece controle total sobre a experiência do usuário no frontend. As opções de personalização incluem:
- Renderizadores de rastreamento especializados para seus tipos de agente.
- Disponibilidade e interações de interface de rótulo personalizado
- Visualizações específicas do domínio
- Controle quais informações de rastreamento são exibidas aos revisores.
O catálogo inclui ferramentas de linha de comando para configuração programática ou um assistente AI (Claude Code) para personalização interativa: GitHub - custom-mlflow-review-app. O aplicativo de revisão personalizado é implantado como um aplicativoDatabricks e se integra diretamente aos seus experimentos e sessões de rótulo existentes MLflow . Consulte a documentação do repositório padrão para obter instruções completas de personalização e implantação.
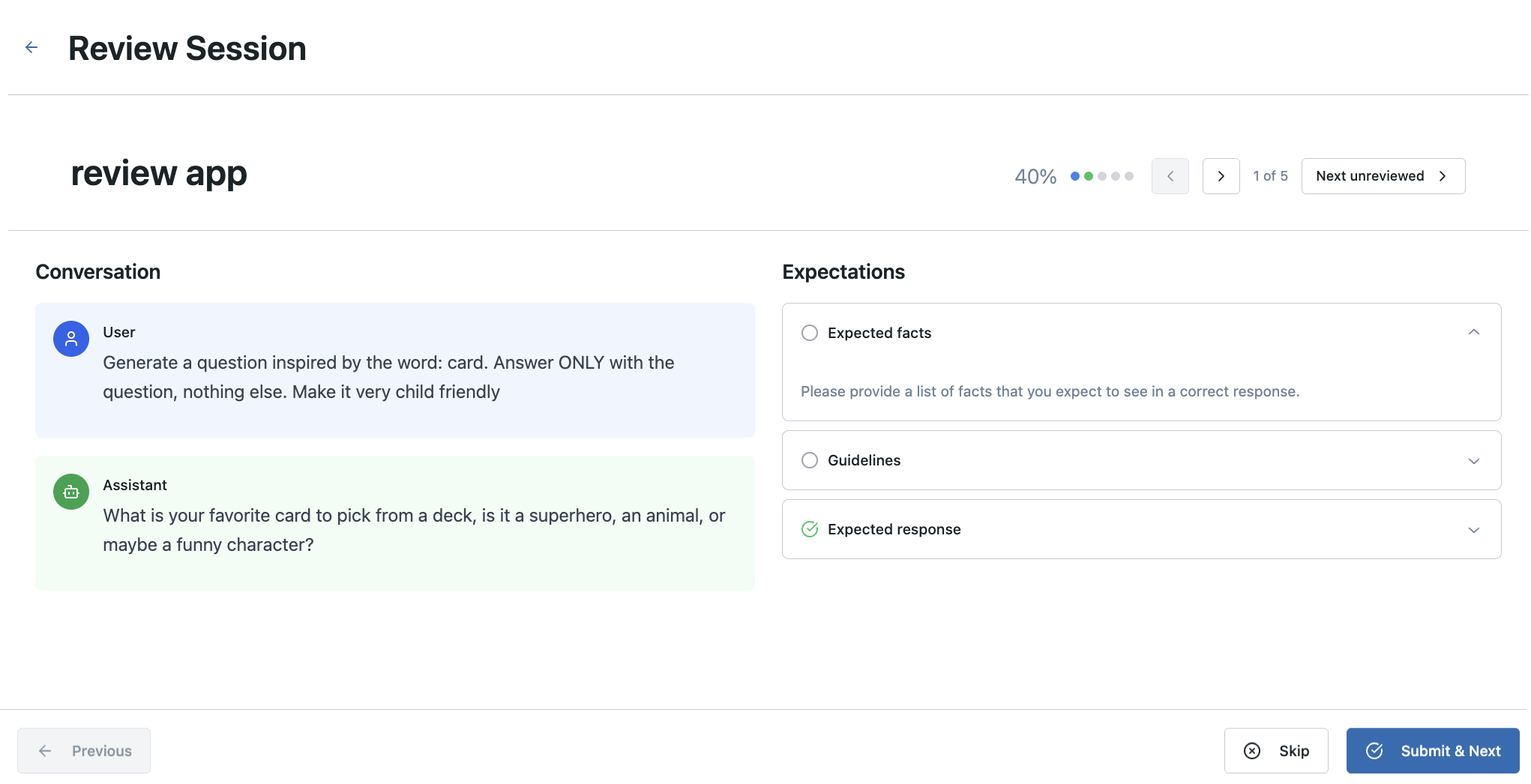
O padrão personalizável é ideal para equipes que precisam de visualização de rastreamento personalizada, avaliação do fluxo de trabalho ou requisitos específicos de interface do usuário que vão além da interface padrão do aplicativo Review. Para avaliação padrão do fluxo de trabalho, o aplicativo Review integrado fornece soluções prontas para produção sem configuração adicional.
o passo 6: visualizar e usar etiquetas coletadas
Depois que os especialistas de domínio concluírem suas análises, o feedback coletado será anexado aos traços na sessão de rótulo. O senhor pode recuperar esses rótulos programaticamente para analisá-los ou usá-los para criar um conjunto de dados de avaliação.
rótulo são armazenados como objetos Assessment em cada Trace dentro da sessão rótulo.
Usar a interface de usuário do MLflow
Para analisar os resultados, acesse o experimento MLflow.

Use o SDK do MLflow
O código a seguir busca todos os rastros da execução da sessão do rótulo e extrai as avaliações (rótulo) em um Pandas DataFrame para facilitar a análise.
labeled_traces_df = mlflow.search_traces(run_id=label_summaries.mlflow_run_id)
Análise da renderização do conteúdo do aplicativo
Ao rotular rastreamentos existentes, o aplicativo Review usa as entradas e saídas dos rastreamentos existentes e armazena os resultados em rastreamentos MLflow dentro de uma sessão de rotulagem. Você deve fornecer um esquema de rótulos personalizado para definir as perguntas e os critérios para o seu caso de uso.
O aplicativo Review renderiza automaticamente diferentes tipos de conteúdo a partir do seu rastreamento MLflow:
-
Documentos recuperados : Os documentos dentro de um intervalo
RETRIEVERsão renderizados para exibição. -
Mensagens no formato OpenAI : Entradas e saídas do MLflow Trace, seguindo as conversas do chat OpenAI, são renderizadas:
outputsque contêm um objeto ChatCompletions no formato OpenAIinputsou dicionáriosoutputsque contêm uma keymessagescom uma matriz de mensagens de bate-papo no formato OpenAI- Se a matriz
messagescontiver chamadas de ferramentas no formato OpenAI, essas chamadas também serão renderizadas.
- Se a matriz
-
Dicionários : As entradas e saídas do MLflow Trace que são dicionários são renderizadas como JSONs formatados.
Caso contrário, o conteúdo de input e output do intervalo raiz de cada traço é usado como conteúdo primário para revisão.
Exemplo de notebook
O Notebook a seguir inclui todo o código desta página.
Coletar feedback de especialistas no domínio Notebook
Próximos passos
Convertendo para conjunto de dados de avaliação
O rótulo do tipo "expectation" (como o expected_summary do nosso exemplo) é particularmente útil para criar o conjunto de dados de avaliação. Esses conjuntos de dados podem então ser utilizados com mlflow.genai.evaluate() para testar sistematicamente novas versões da sua aplicação GenAI em relação à verdade fundamental definida por especialistas.