Conceitos de extensão
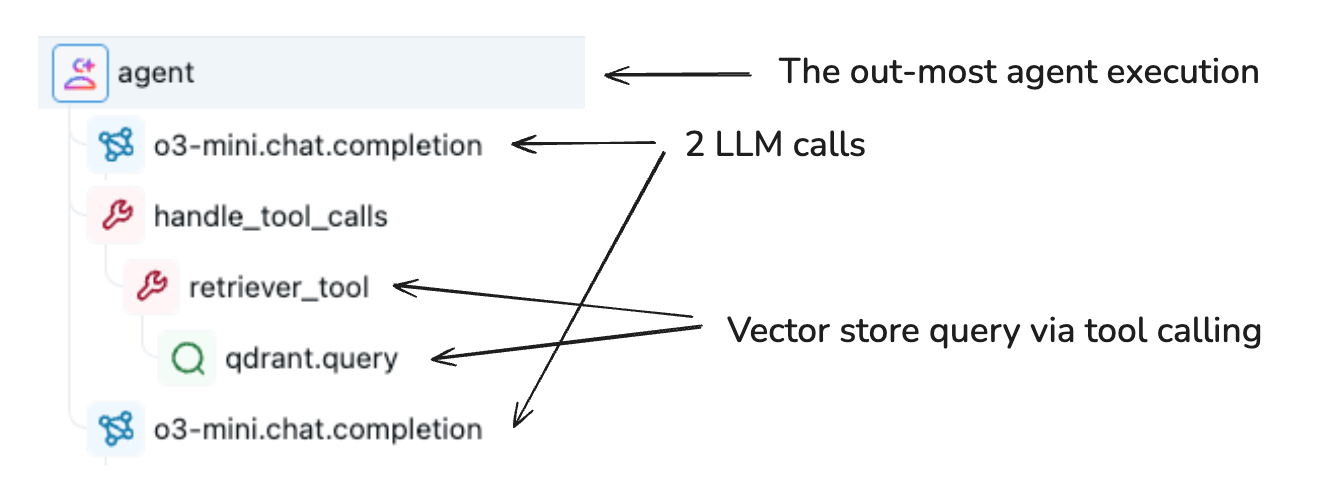
O objeto Span é um componente fundamental no modelo de dados Trace. Ele serve como um contêiner para informações sobre os passos individuais de um rastreamento, como chamadas LLM , execução de ferramentas, operações de recuperação e muito mais.
Os intervalos (spans) são organizados hierarquicamente em um rastreamento para representar o fluxo de execução do seu aplicativo. Cada intervalo captura:
- Dados de entrada e saída
- Informação de horários (horários de início e término)
- Status (sucesso ou erro)
- Metadados e atributos sobre as operações
- Relação com outros âmbitos (conexões entre pais e filhos)
Esquema de objeto Span
O design Span do MLflow mantém a compatibilidade com as especificações do OpenTelemetry. O esquema inclui onze propriedades principais:
Propriedade | Tipo | Descrição |
|---|---|---|
|
| Identificador único para este trecho no rastreamento. |
|
| Os links se estendem até seu rastreamento pai. |
|
| Estabelece relação hierárquica; |
|
| Nome do intervalo definido pelo usuário ou gerado automaticamente |
|
| Timestamp Unix (nanossegundos) de quando o intervalo começa |
|
| Timestamp Unix (em nanossegundos) do término do intervalo. |
|
| Estado do trecho: |
|
| Dados de entrada entrando nestas operações |
|
| Dados de saída desta operação |
|
| Metadados por valor- keyfornecendo percepções comportamentais |
|
| Exceções no nível do sistema e informações de rastreamento de pilha |
Para obter detalhes completos, consulte a referência da API do MLflow.
Atributos de extensão
Os atributos são pares de pares key-valor que fornecem informações sobre modificações comportamentais para chamadas de funções e métodos. Eles capturam metadados sobre a configuração e o contexto de execução das operações.
Você pode adicionar atributos específicos da plataforma, como informaçõesUnity Catalog, detalhes endpointdo modelo de serviço e metadados de infraestrutura para uma melhor observabilidade.
Exemplo de set_attributes() para uma chamada de LLM:
span.set_attributes({
"ai.model.name": "claude-3-5-sonnet-20250122",
"ai.model.version": "2025-01-22",
"ai.model.provider": "anthropic",
"ai.model.temperature": 0.7,
"ai.model.max_tokens": 1000,
})
Tipos de extensão
O MLflow fornece valores predefinidos SpanType para categorização. Você também pode usar valores de string personalizados para operações especializadas.
Tipo | Descrição |
|---|---|
| Consulta a um modelo de chat (interação especializada em LLM) |
| Cadeia de operações |
| operações de agentes autônomos |
| Execução de ferramentas (normalmente por agentes), como consultas de pesquisa |
| operações de incorporação de texto |
| Operações de recuperação de contexto, como consultas de banco de dados vetoriais |
| Operações de análise sintática transformam texto em formato estruturado. |
| Reclassificação dos contextos de ordenação de operações por relevância. |
| Operações de memória que persistem no contexto em armazenamento de longo prazo |
| Tipo padrão quando nenhum outro tipo for especificado. |
Definindo tipos de intervalo
Use o parâmetro span_type com decoradores ou gerenciadores de contexto para definir SpanType:
import mlflow
from mlflow.entities import SpanType
# Using a built-in span type
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_documents(query: str):
...
# Using a custom span type
@mlflow.trace(span_type="ROUTER")
def route_request(request):
...
# With context manager
with mlflow.start_span(name="process", span_type=SpanType.TOOL) as span:
span.set_inputs({"data": data})
result = process_data(data)
span.set_outputs({"result": result})
Pesquisando intervalos por tipo
Consultar intervalos programaticamente usando MLflow search_spans():
import mlflow
from mlflow.entities import SpanType
trace = mlflow.get_trace("<trace_id>")
retriever_spans = trace.search_spans(span_type=SpanType.RETRIEVER)
Você também pode filtrar por tipo de intervalo na interface do usuário do MLflow ao visualizar os rastreamentos.
Períodos ativos vs. períodos concluídos
Um span ativo ou LiveSpan é aquele que está sendo registrado ativamente, como em uma função decorada com @mlflow.trace ou um gerenciador de contexto de span. Assim que a função decorada ou o gerenciador de contexto forem encerrados, o span é finalizado e se torna um imutável Span.
Para modificar o intervalo ativo, obtenha um identificador para o intervalo usando mlflow.get_current_active_span().
RETRIEVER esquema de extensão
O tipo de span RETRIEVER lida com operações que envolvem a recuperação de dados de um armazenamento de dados, como consultar documentos de um armazenamento vetorial. Este tipo de intervalo possui um esquema de saída específico que possibilita recursos de interface do usuário aprimorados e capacidades de avaliação. O resultado deve ser uma lista de documentos, onde cada documento é um dicionário com:
-
page_content(str): Conteúdo textual do bloco de documento recuperado -
metadata(Optional[Dict[str, Any]]): Metadados adicionais, incluindo:doc_uri(str): URI de origem do documento. Ao usar a Pesquisa Vetorial no Databricks, os spans do RETRIEVER podem incluir caminhos de volume Unity Catalog nos metadadosdoc_uripara acompanhamento completo da linhagem.chunk_id(str): Identificador se o documento faz parte de um documento fragmentado maior.
-
id(Optional[str]): Identificador único para o bloco de documento
A entidade MLflowDocument ajuda a construir esta estrutura de saída.
Exemplo de implementação :
import mlflow
from mlflow.entities import SpanType, Document
def search_store(query: str) -> list[tuple[str, str]]:
# Simulate retrieving documents from a vector database
return [
("MLflow Tracing helps debug GenAI applications...", "docs/mlflow/tracing_intro.md"),
("Key components of a trace include spans...", "docs/mlflow/tracing_datamodel.md"),
("MLflow provides automatic instrumentation...", "docs/mlflow/auto_trace.md"),
]
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_relevant_documents(query: str):
docs = search_store(query)
span = mlflow.get_current_active_span()
# Set outputs in the expected format
outputs = [
Document(page_content=doc, metadata={"doc_uri": uri})
for doc, uri in docs
]
span.set_outputs(outputs)
return docs
# Usage
user_query = "MLflow Tracing benefits"
retrieved_docs = retrieve_relevant_documents(user_query)
Próximos passos
- Conceitos de traços - Compreender os conceitos e a estrutura do nível de traços.
- Traçando em um caderno - Obtenha experiência prática com traçado.