Rastreando Ollama
A Ollama é uma plataforma de código aberto que permite aos usuários executar modelos de linguagem de grande porte (LLMs) localmente em seus dispositivos, como Llama 3.2, Gemma 2, Mistral, Code Llama, entre outros.
Como o endpoint LLM local atendido pelo Ollama é compatível com a API OpenAI, é possível consultá-lo por meio do SDK OpenAI e habilitar o rastreamento para o Ollama com mlflow.openai.autolog(). Todas as interações do LLM através do Ollama serão registradas no Experimento MLflow ativo.
import mlflow
mlflow.openai.autolog()
Em serverless compute clusters, o autologging para estruturas de rastreamento genAI não é ativado automaticamente. Você deve habilitar explicitamente o registro automático chamando a função mlflow.<library>.autolog() apropriada para as integrações específicas que você deseja rastrear.
Exemplo de uso
- executar o servidor Ollama com o modelo LLM desejado.
ollama run llama3.2:1b
- Habilite o rastreamento automático para o OpenAI SDK.
import mlflow
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking on Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/ollama-demo")
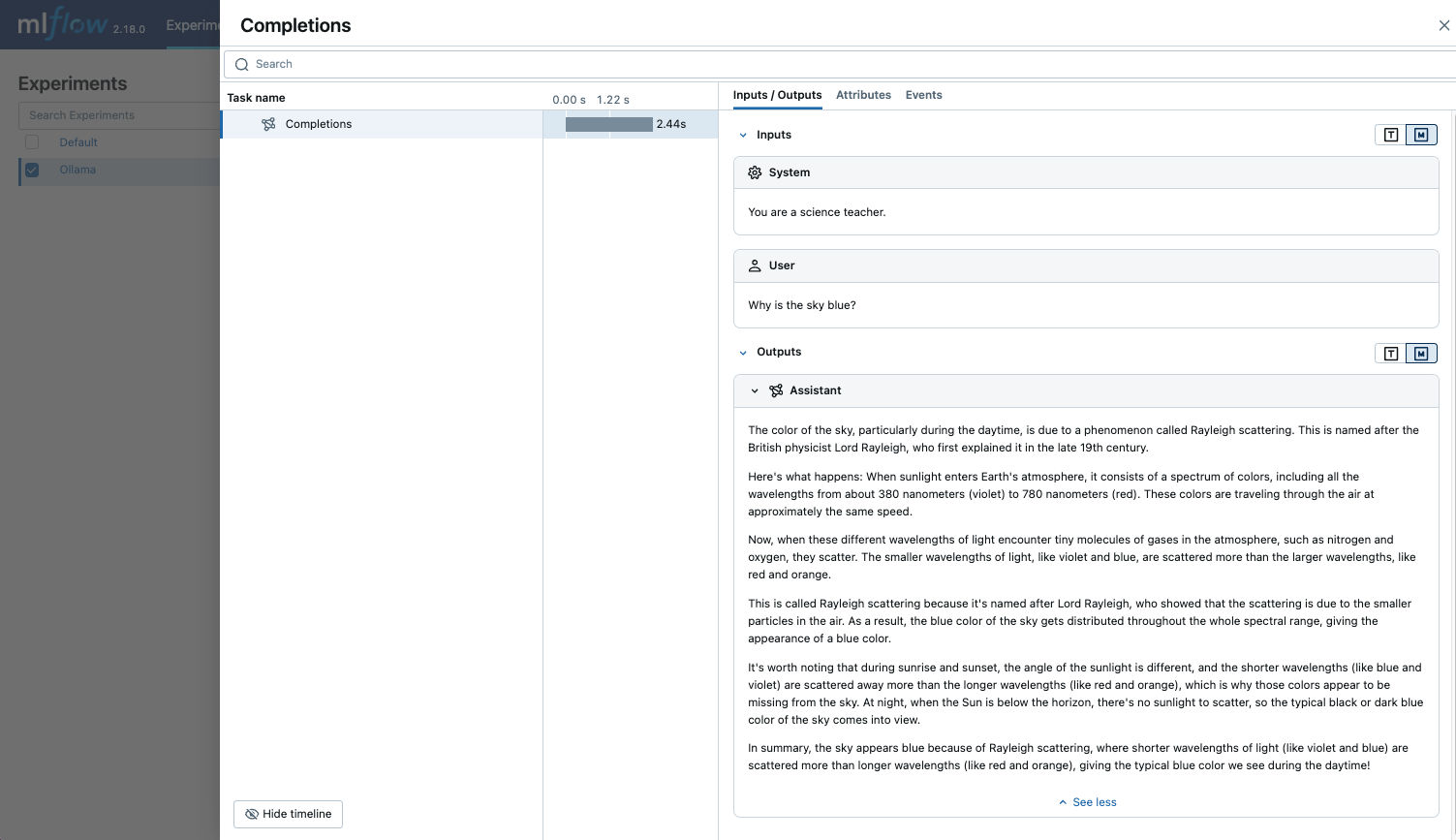
- Consulte o LLM e veja os traços na interface do usuário do MLflow.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
response = client.chat.completions.create(
model="llama3.2:1b",
messages=[
{"role": "system", "content": "You are a science teacher."},
{"role": "user", "content": "Why is the sky blue?"},
],
)
Desativar o rastreamento automático
O rastreamento automático do Ollama pode ser desativado globalmente ligando para mlflow.openai.autolog(disable=True) ou mlflow.autolog(disable=True).
Recursos adicionais
- Entenda os conceitos de rastreamento - Saiba como o MLflow captura e organiza os dados de rastreamento
- Depure e observe seu aplicativo - Use o Trace UI para analisar seus modelos Ollama de execução local
- Avalie a qualidade do seu aplicativo - Configure a avaliação de qualidade para seu aplicativo com tecnologia Ollama