Defina os atributos de extensão do OpenTelemetry para o MLflow.
Ao enviar rastreamentos de um aplicativo personalizado instrumentado com OpenTelemetry (OTel) para o Databricks MLflow, você deve definir atributos de intervalo específicos para renderizar corretamente os dados de rastreamento na interface do usuário do MLflow. Esta página mostra quais atributos da Convenção Semântica GenAI do OpenTelemetry devem ser configurados.
Se você usar uma integração pré-configurada como o Langfuse, essa integração definirá esses atributos automaticamente. Esta página destina-se a aplicações com instrumentação OTel personalizada.
Os atributos no Databricks gerenciando MLflow diferem do OSS (código aberto software) MLflow. Para o mapeamento de atributos do MLflow de código aberto, consulte a documentação do MLflow.
Requisitos
Antes de começar, certifique-se de ter:
- Um workspace Databricks com a pré-visualização de rastreamento OTel ativada.
- O exportador OTLP foi configurado para enviar rastreamentos para seu workspace. Consulte os registros de log nas tabelas Unity Catalog.
- Uma aplicação instrumentada com o SDK OpenTelemetry
Definir tipo de intervalo
Cada trecho (span) no seu rastreamento precisa de um rótulo de tipo para que MLflow possa identificar que tipo de operação ele representa. Defina gen_ai.operation.name para um dos valores na tabela a seguir chamando span.set_attribute("gen_ai.operation.name", "<value>"). O MLflow lê esse atributo e exibe o tipo de extensão MLflow correspondente na interface de rastreamento.
Valor OTel | tipo de extensão MLflow |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
span.set_attribute("gen_ai.operation.name", "chat")
Configurar entradas e saídas
Defina gen_ai.input.messages e gen_ai.output.messages em cada intervalo que deve exibir entradas e saídas. Ao configurá-los no span raiz, também preenchem as pré-visualizações de solicitação e resposta em nível de rastreamento.
Atributo OTel | Atributo MLflow |
|---|---|
|
|
|
|
Os valores podem ser strings simples ou strings serializadas em JSON . O uso de arrays JSON de objetos de mensagem com campos role e content permite uma renderização mais rica na interface do usuário MLflow (por exemplo, balões com os rótulos "Usuário" e "Assistente"):
import json
# Plain string — displays as-is in the UI
span.set_attribute("gen_ai.input.messages", "What is the weather today?")
# JSON message array — renders with role labels in the UI
span.set_attribute("gen_ai.input.messages", json.dumps([
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the weather today?"}
]))
span.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": "It is sunny and 72°F in San Francisco."}
]))
Definir uso de tokens
Para exibir a contagem de tokens no resumo de rastreamento da interface do usuário, defina gen_ai.usage.input_tokens e gen_ai.usage.output_tokens chamando span.set_attribute() no span raiz. O MLflow lê esses valores especificamente do span raiz porque agrega contagens no nível de rastreamento.
Atributo OTel | Campo de tokens MLflow |
|---|---|
| Contagem de tokens de entrada |
| Contagem de tokens de saída |
(não definido — calculado automaticamente) | Contagem total de tokens |
root.set_attribute("gen_ai.usage.input_tokens", 150)
root.set_attribute("gen_ai.usage.output_tokens", 42)
Configurar sessão e usuário
Para associar rastreamentos a uma sessão ou usuário específico, defina session.id e user.id em qualquer span chamando span.set_attribute(). O MLflow lê esses atributos do span raiz e os exibe como metadados em nível de rastreamento. A configuração session.id ativa a tab de sessão na interface do usuário MLflow .
Atributo OTel | Campo de metadados do MLflow |
|---|---|
| Identificador de sessão ou conversa |
| Identificador do usuário final do aplicativo |
span.set_attribute("session.id", "conversation-123")
span.set_attribute("user.id", "user-456")
Exemplo completo: instrumentar um agente Python
O exemplo a seguir reúne todas as quatro categorias de atributos em um agente simples com um span filho LLM. Isso pressupõe que você já tenha configurado o exportador OTLP para enviar rastreamentos para o Databricks.
import json
from opentelemetry import trace
tracer = trace.get_tracer("my-agent")
def run_agent(query: str) -> str:
with tracer.start_as_current_span("agent-run") as root:
# Child LLM span — set gen_ai attributes for this individual call
with tracer.start_as_current_span("chat") as llm:
llm.set_attribute("gen_ai.operation.name", "chat")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": query}
]
response = call_llm(messages)
llm.set_attribute("gen_ai.input.messages", json.dumps(messages))
llm.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": response}
]))
llm.set_attribute("gen_ai.usage.input_tokens", 150)
llm.set_attribute("gen_ai.usage.output_tokens", 42)
# Root span — MLflow reads inputs, outputs, token usage, and session ID
# from the root span to populate the trace summary in the UI.
root.set_attribute("gen_ai.operation.name", "chat")
root.set_attribute("session.id", "conversation-123")
root.set_attribute("user.id", "user-456")
root.set_attribute("gen_ai.input.messages", json.dumps([
{"role": "user", "content": query}
]))
root.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": response}
]))
root.set_attribute("gen_ai.usage.input_tokens", 150)
root.set_attribute("gen_ai.usage.output_tokens", 42)
return response
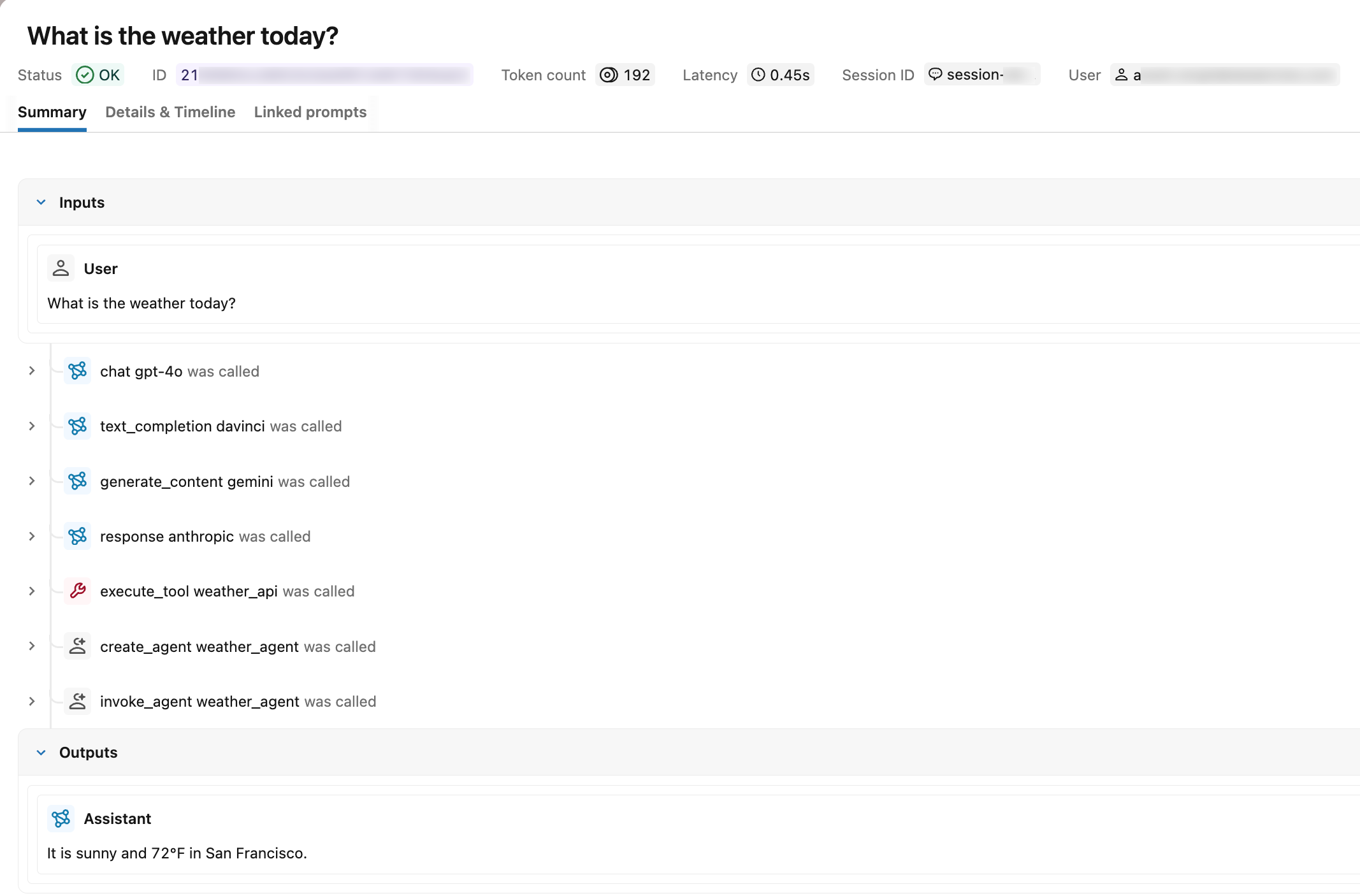
Verifique na interface do usuário do MLflow.
Depois de chamar run_agent(), abra a tab MLflow Traces em seu experimento. Um traçado corretamente instrumentado mostra:
- Tipos de span : Cada span exibe seu rótulo de tipo (por exemplo,
chat) em vez deUNKNOWN - Solicitação e resposta : O span raiz exibe as mensagens de entrada e as mensagens de saída.
- Uso de tokens : O resumo do rastreamento exibe a entrada, a saída e a contagem total de tokens.
- Sessão e usuário : O rastreamento aparece na tab Sessão, sob o identificador de sessão especificado, e o ID do usuário é visível nos metadados do rastreamento.
Pesquise rastros por atributos de extensão OTel
Após ingerir rastreamentos OTel no Unity Catalog, use o prefixo span.attributes.* em mlflow.search_traces() para filtrar pelos valores de atributo OTel que você definiu. O nome do atributo após o prefixo é o mesmo nome do atributo OTel que você definiu com span.set_attribute().
import mlflow
# experiment_id is visible in the MLflow UI URL and experiment details panel
mlflow.set_experiment(experiment_id="<experiment-id>")
# Find traces from a specific session (set using session.id)
traces = mlflow.search_traces(
filter_string="span.attributes.session.id = 'conversation-123'"
)
# Find traces from a specific user (set using user.id)
traces = mlflow.search_traces(
filter_string="span.attributes.user.id = 'user-456'"
)
# Find traces from a specific model (set using gen_ai.request.model)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.request.model LIKE '%gpt%'"
)
# Find traces by operation type (set using gen_ai.operation.name)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.operation.name = 'chat'"
)
# Find high-token traces (set using gen_ai.usage.input_tokens)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.usage.input_tokens > 1000"
)
Para a sintaxe completa filter_string , incluindo operadores e comparadores suportados, consulte Pesquisar rastreamentos programaticamente.
Limitações
Os atributos de extensão OTel personalizados não são exibidos como tags de rastreamento do MLflow. Os atributos que você definir com span.set_attribute() fora dos mapeamentos OTel-para-MLflow reconhecidos nesta página não aparecerão em:
- A coluna de tags ou a view de rastreamento unificado na interface do usuário MLflow
- A tabela Unity Catalog
_traces_unified - O campo
tagsretornado pormlflow.search_traces()
Esses atributos são preservados no span subjacente. Eles permanecem visíveis na tab Atributos da interface do usuário de rastreamento MLflow e podem ser consultados por meio do campo <prefix>_otel_spans.attributes da tabela de extensões OTel.
Para adicionar tags pesquisáveis que aparecem na view de rastreamento unificada, use as APIs tag MLflow . Consulte Anexar tags e metadados personalizados.
Recursos adicionais
- Buscar rastreamentos programaticamente — Busque e filtre rastreamentos programaticamente usando o SDK do MLflow.
- Consulte rastreamentos OpenTelemetry armazenados no Unity Catalog — Consulte dados de rastreamento em escala usando o Databricks SQL.