Notebook compute recurso
Você pode executar um Notebook Databricks em um recurso de compute de uso geral, compute serverless ou, para comandos SQL, um SQL warehouse, um tipo de compute otimizado para analítica SQL. Para mais informações sobre tipos de compute, consulte Compute.
computepadrão
Em espaços de trabalho com o Unity Catalog habilitado, o novo Notebook default compute serverless por padrão. Se você não selecionar manualmente um recurso compute e executar uma célula, o Notebook se conectará automaticamente à compute serverless .
computede conexão automática
Nas suas configurações de desenvolvedor, você pode configurar o Notebook para se conectar automaticamente a um recurso compute e iniciar uma sessão quando você interagir com o editor:
-
Clique no ícone de usuário no canto superior direito.
-
Clique em Configurações .
-
Clique em Desenvolvedor para acessar as configurações de desenvolvedor.
-
Ative a opção "Criar sessão automaticamente ao interagir com o editor" para iniciar automaticamente uma sessão compute ao interagir com o editor. Por padrão, Databricks utiliza um recurso compute baseado em suas preferências (serverless ou SQL warehouse) e no último recurso compute utilizado.
ou
Desative esta configuração se não quiser que o Notebook se conecte e inicie automaticamente um recurso compute .
Os recursos de assistência de código, incluindo preenchimento automático, formatação de código e o depurador, exigem que o Notebook esteja conectado a uma sessão compute ativa. Se o Notebook não tiver iniciado uma sessão compute , os recursos de assistência de código ficarão inativos.
sem servidor compute para Notebook
sem servidor compute permite que o senhor conecte rapidamente seu Notebook a um recurso de computação sob demanda.
Para conectar-se ao compute serverless , clique no menu suspenso compute no Notebook e selecione "sem servidor" .
Consulte compute sem servidor para Notebook para obter mais informações.
Restauração automatizada de sessões para o serverless Notebook
O encerramento abrupto de um processo de compute serverless compute) pode causar a perda de trabalho em andamento, como valores de variáveis Python , em seu Notebook. Para evitar isso, ative a restauração automática de sessão para Notebooks serverless .
- Clique no seu nome de usuário no canto superior direito da sua workspace e, em seguida, clique em Configurações na lista suspensa.
- Na barra lateral Configurações , selecione Desenvolvedor .
- Em Recurso experimental , ative a configuração Automated session restoration for serverless Notebook .
Habilitar essa configuração permite que Databricks capture um instantâneo do estado da memória do Notebook serverless antes do encerramento do Parado. Ao retornar a um Notebook após uma desconexão do Parado, um banner aparece na parte superior da página. Clique em Reconectar para restaurar seu estado de funcionamento.
Quando você se reconecta, o Databricks restabelece todo o seu ambiente de trabalho, incluindo:
- Variáveis, funções e definições de classe em Python : o estado do Python é serializado em processo usando pickle/cloudpickle e restaurado em um novo REPL, portanto, você não precisa reimportar ou redeclarar.
- Spark DataFrames, visualização em cache e temporária : os dados que você carregou, transformou ou armazenou em cache (incluindo a visualização temporária) são preservados, evitando assim recarregamentos ou recálculos dispendiosos.
- Estado da sessãoSpark : as configurações em nível Spark , a visualização temporária, as modificações no catálogo e as funções definidas pelo usuário (UDFs) são restauradas por meio da migração da sessão Spark Connect, portanto, você não precisa redefini-las.
Se o ambiente tiver sido alterado de forma a tornar a desserialização insegura, por exemplo, devido a versões incompatíveis Python ou do pacote, o Snapshot será invalidado e o Notebook recorrerá a uma nova sessão.
Armazenamento de dadosSnapshot
Os dados Snapshot são armazenados no armazenamentodefault do seu workspace . O próprio Notebook armazena apenas metadados, incluindo um ponteiro com o ID do Notebook, um registro de data e hora e informações da sessão. Os dados não estão armazenados no Notebook. Os caminhos dos Blobs são criptografados antes de serem armazenados nos atributos do Notebook, e os caminhos dos Snapshots são excluídos da exportação e importação do Notebook para evitar a restauração do estado em um workspace diferente.
Os snapshots seguem o TTL padrão do seu armazenamento cloud (cerca de um mês) e expiram automaticamente. Excluir um Notebook também exclui seu Snapshot. Sua account cloud incorre em custos de armazenamento como parte do uso padrão workspace . O recurso usa serialização de processos Python em vez de checkpointing em nível de contêiner, o que mantém o Snapshot menor e mais rápido de criar.
Segurança e controle de acesso
A restauração Snapshot respeita as permissões do Notebook. Restaurar o estado requer permissão de execução no Notebook. Os metadados criptografados impedem que os visualizadores busquem diretamente os blobs do Snapshot, e as verificações de permissão são aplicadas na restauração.
Limitações
Este recurso possui limitações e não suporta a restauração dos seguintes itens:
- Estados Spark com mais de 4 dias
- Estados Spark maiores que 50 MB
- Dados relacionados ao script SQL
- Alças de arquivo
- Bloqueios e outras primitivas de concorrência
- Conexões de rede
Anexe um Notebook a um recurso multifuncional compute
Para anexar um Notebook a um recurso multifuncional compute, o senhor precisa da permissãoCAN ATTACH TO no recurso compute.
Desde que um Notebook esteja anexado a um recurso compute, qualquer usuário com a permissãoCAN RUN no Notebook tem permissão implícita para acessar o recurso compute.
Para conectar um Notebook a um recurso compute , clique no seletorcompute na barra de ferramentas do Notebook e selecione o recurso no menu suspenso.
O menu mostra uma seleção de armazéns para todos os fins compute e SQL que o senhor usou recentemente ou está executando no momento.
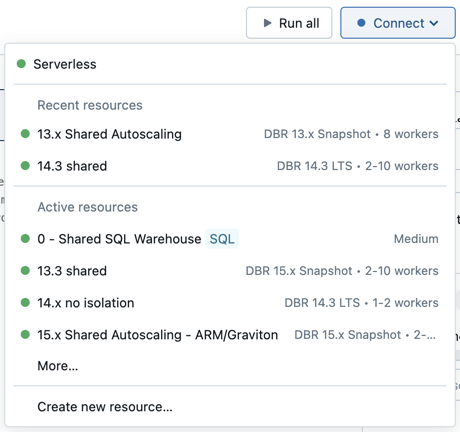
Para selecionar entre todas as opções disponíveis compute, clique em More.... Selecione entre os armazéns gerais disponíveis compute ou SQL.
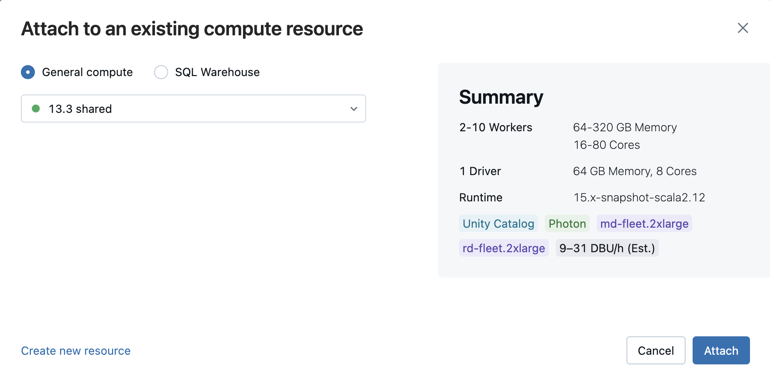
Você também pode criar um novo recurso compute de uso geral selecionando "Criar novo recurso" no menu suspenso.
Um bloco de anotações anexado tem as seguintes variáveis do Apache Spark definidas.
Aula | Nome da variável |
|---|---|
|
|
|
|
|
|
Não crie um SparkSession, SparkContext ou SQLContext. Fazer isso leva a um comportamento inconsistente.
Use um notebook com um SQL warehouse
Quando um Notebook é anexado a um SQL warehouse, o senhor pode executar SQL e células Markdown. A execução de uma célula em qualquer outra linguagem (como Python ou R) gera um erro. SQL As células executadas em um SQL warehouse aparecem no histórico de consultas doSQL warehouse. O usuário que executa uma consulta pode view o perfil da consulta no Notebook clicando no tempo decorrido na parte inferior da saída.
Os notebooks conectados ao SQL Warehouse oferecem suporte a sessões SQL warehouse , onde você pode definir variáveis, criar visualizações temporárias e persistir o estado entre várias execuções de consultas. Você pode construir a lógica SQL iterativamente, sem precisar executar todas as instruções de uma só vez. Consulte O que são sessões SQL warehouse ?
A execução de um notebook requer um profissional ou serverless SQL warehouse. O senhor deve ter acesso ao workspace e ao SQL warehouse.
Para anexar um Notebook a um SQL warehouse faça o seguinte:
-
Clique no seletorcompute na barra de ferramentas do Notebook. O menu suspenso mostra os recursos compute que estão em execução no momento ou que você usou recentemente. Os armazéns SQL são marcados com
 .
. -
No menu, selecione um SQL warehouse.
Para visualizar todos os data warehouses SQL disponíveis, selecione Mais… no menu suspenso. Aparece uma caixa de diálogo mostrando os recursos compute disponíveis para o Notebook. Selecione o repositórioSQL , escolha o repositório que deseja usar e clique em Anexar .
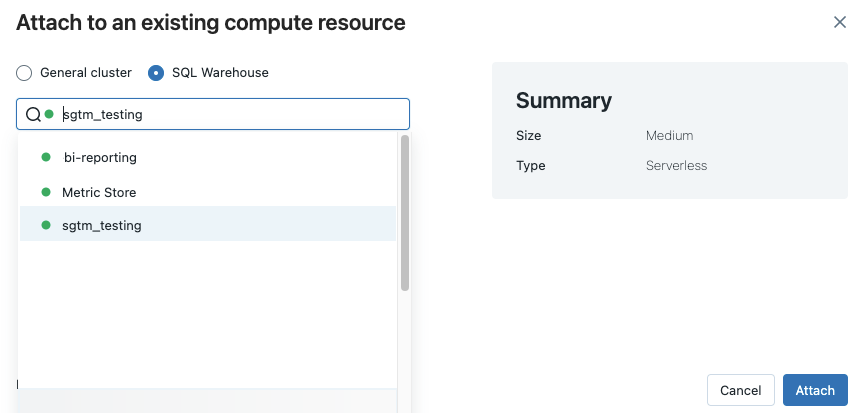
O senhor também pode selecionar um SQL warehouse como o compute recurso para um SQL Notebook quando criar um fluxo de trabalho ou um trabalho agendado.
Limitações do SQL warehouse
Consulte a seção Limitações conhecidas do Databricks Notebook para obter mais informações.