Lakebase Postgres
O Lakebase é um banco de dados Postgres totalmente gerenciado e integrado à plataforma Databricks. Crie aplicações transacionais em tempo real em conjunto com seus dados lakehouse , com escalonamento automático, ramificação instantânea e integração nativa Unity Catalog .
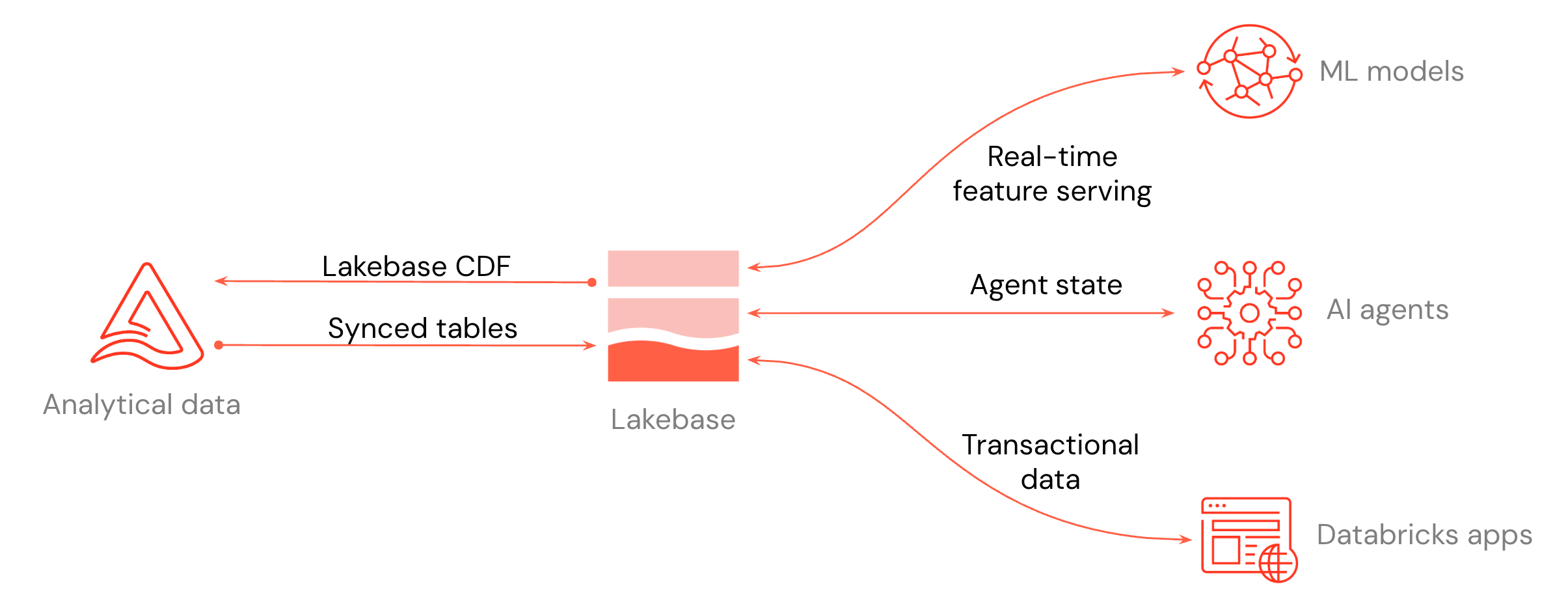
- Crie aplicativos de baixa latência: Conecte Databricks Apps ou qualquer outro aplicativo ao Lakebase para cargas de trabalho transacionais.
- Disponibilize dados lakehouse : Sincronize as tabelas Unity Catalog com Lakebase para que os aplicativos possam consultá-las com baixa latência.
- Armazenar alterações do Postgres: Armazenar as alterações do Postgres como tabelas Delta para o pipeline e auditoria subsequentes.
- AI e ML: Use Lakebase como um repositório de recursos online para modelos ML ou como armazenamento do estado para agentes AI .
Se você já possui instâncias de provisionamento Lakebase , elas serão atualizadas para o Lakebase Autoscale. Consulte Atualização para dimensionamento automático Lakebase.
Comece agora
-
- Obtenha um banco de dados Postgres
- Crie um projeto, uma ramificação e um banco de dados. Conecte-se com
psqlou qualquer driver Postgres.
-
- Dados de serviço lakehouse
- Sincronize as tabelas Unity Catalog com o Postgres para leituras de aplicativos com baixa latência.
-
- Armazene as alterações do Postgres na lakehouse
- (Pré-visualização pública) Armazene as alterações do Postgres como Delta com o histórico de alterações completo.
-
- Criar aplicativos
- Crie aplicativos com suporte do Lakebase usando o Databricks Apps, integrações externas ou a API de Dados.
recurso principal
Explore recursos que otimizam desempenho, reduzem custos e permitem fluxo de trabalho flexível no desenvolvimento.
-
- Dimensionamento automático
- Ajustar automaticamente os recursos compute com base na demanda da carga de trabalho.
-
- Dimensionar para zero
- Suspender automaticamente os cálculos inativos para minimizar custos.
-
- Galhos
- Crie branches isoladas para desenvolvimento e teste.
-
- Leia as réplicas
- Crie réplicas somente leitura para escalar operações de leitura.
-
- Restauração instantânea
- Crie uma nova ramificação a partir de qualquer ponto no tempo dentro da sua janela de história.
-
- Alta disponibilidade
- Configure o failover automático para manter seu banco de dados disponível durante falhas compute .
Conecte-se e faça uma consulta.
Utilize diversas ferramentas e interfaces para conectar-se ao seu banco de dados e consultá-lo.
-
- Conecte-se ao seu banco de dados
- Aprenda diferentes maneiras de se conectar ao seu banco de dados Lakebase.
-
- Consulta com o Editor SQL
- Utilize o editor SQL integrado para consultar e gerenciar seu banco de dados.
-
- Editor de tabelas
- Utilize a interface visual para view, editar e gerenciar dados e esquemas.
-
- Clientes Postgres
- Conecte-se usando clientes e ferramentas padrão do Postgres.
-
- Consultar dados em um determinado momento.
- Consulte ramificações pontuais de uso de dados.
Saber mais
-
- Casos de uso
- Padrões Lakebase : disponibilizar dados lakehouse , replicar para o lakehouse, backend da aplicação, agentes AI e ML.
-
- Disponibilidade regional
- Regiões da AWS e do Azure suportadas para o Lakebase Postgres.