Obtenha um banco de dados Postgres
Ao final deste guia, você terá um banco de dados Postgres em funcionamento com dados de exemplo, pronto para se conectar ao seu aplicativo ou integrar-se ao Databricks lakehouse.
Os passos: ① Criar um projeto → ② Conectar → ③ Criar uma tabela
o passo 1: Crie seu primeiro projeto
Abra o aplicativo Lakebase no seletor de aplicativos.
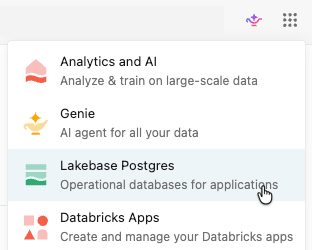
Selecione "Autodimensionar" para acessar a interface de usuário de dimensionamento automático do Lakebase.
Clique em Novo projeto . Dê um nome ao seu projeto e selecione a versão do Postgres. Seu projeto é criado com uma única ramificação production , um banco de dados default databricks_postgres e recurso compute configurado para a ramificação.
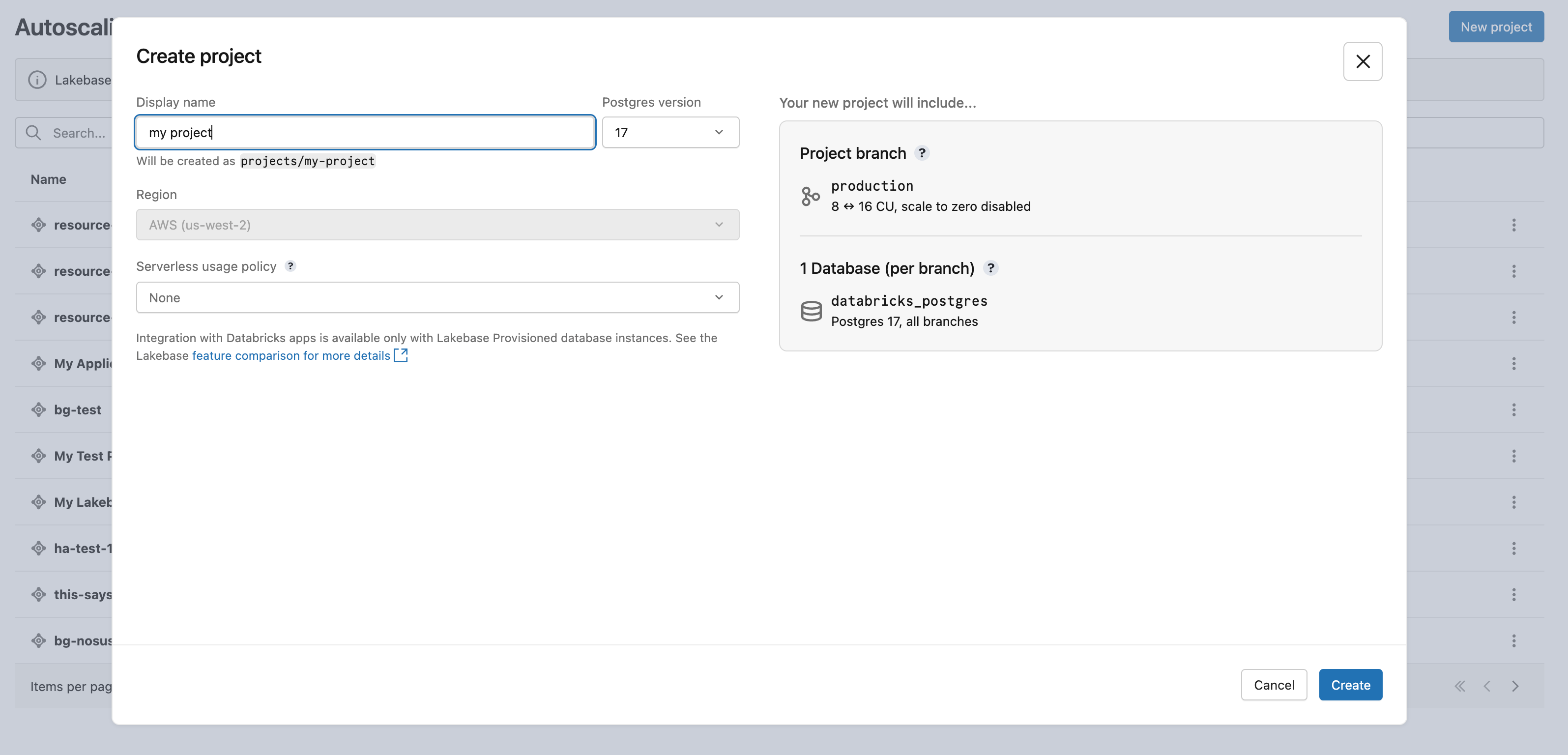
Pode levar alguns instantes para que seu compute seja ativado. O compute para o ramo production tem a escalação para zero ativada por default com um tempo limite de inatividade de 24 horas, mas você pode configurar essa opção, se necessário.
A região do seu projeto é definida automaticamente como a região do seu workspace . Consulte a disponibilidade por região.
Saiba mais: Criar um projeto | dimensionamento automático | escalar até zero
Passo 2: Conecte-se ao seu banco de dados
No seu projeto, selecione a ramificação de produção e clique em Conectar . As strings de conexão funcionam com qualquer cliente Postgres padrão (psql, pgAdmin, DBeaver ou frameworks de aplicação).
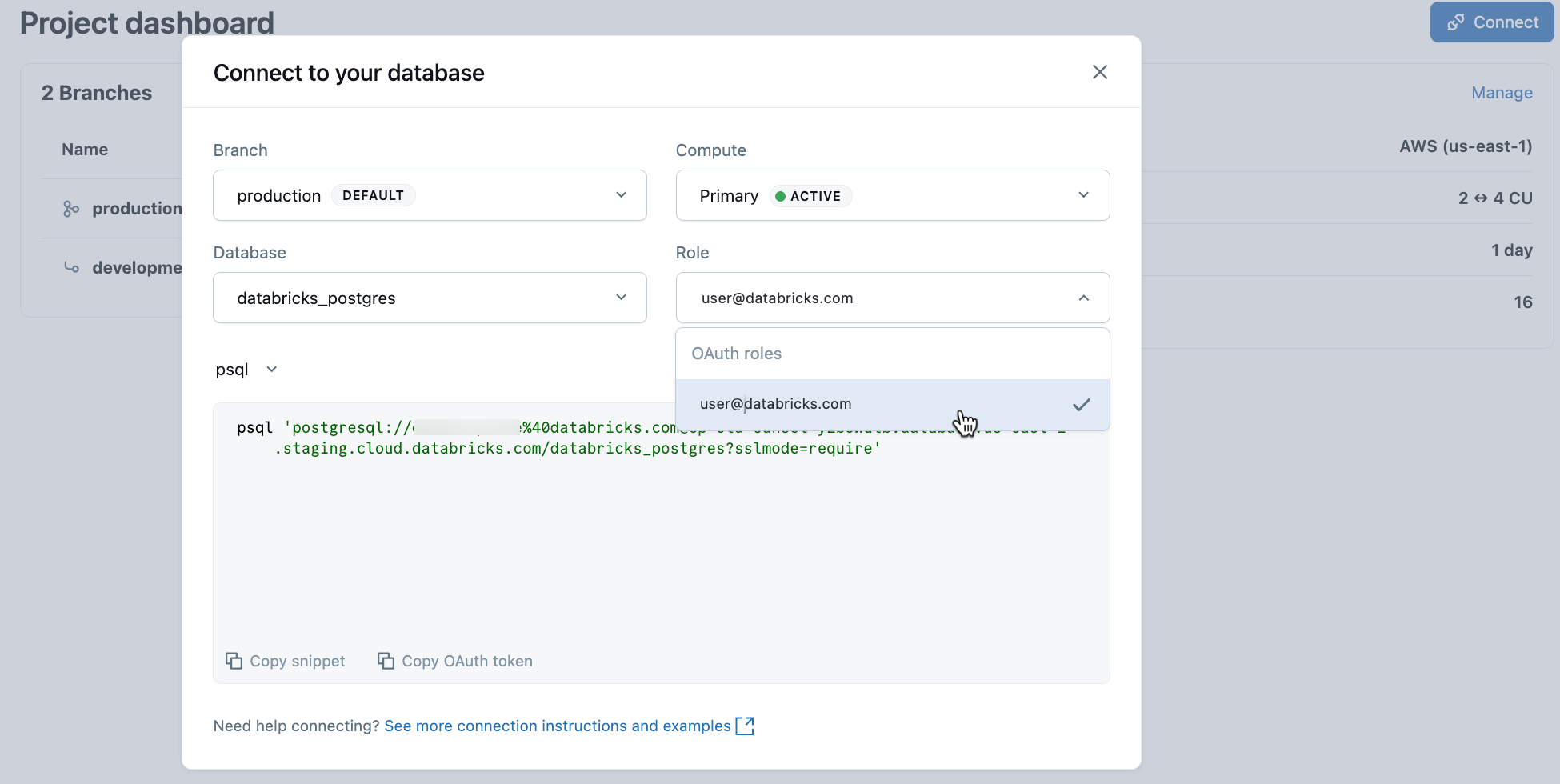
Para conectar-se à sua identidade Databricks , copie o trecho psql da caixa de diálogo de conexão e cole os tokens OAuth quando solicitado:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Saiba mais: Guia rápido de conexão | psql | pgAdmin | Clientes Postgres
a etapa 3: Crie sua primeira tabela
O editor SQL do Lakebase vem pré-carregado com exemplos de SQL. A partir do seu projeto, selecione a ramificação de produção , abra o Editor SQL e execute as instruções fornecidas para criar uma tabela playing_with_lakebase e inserir dados de exemplo.
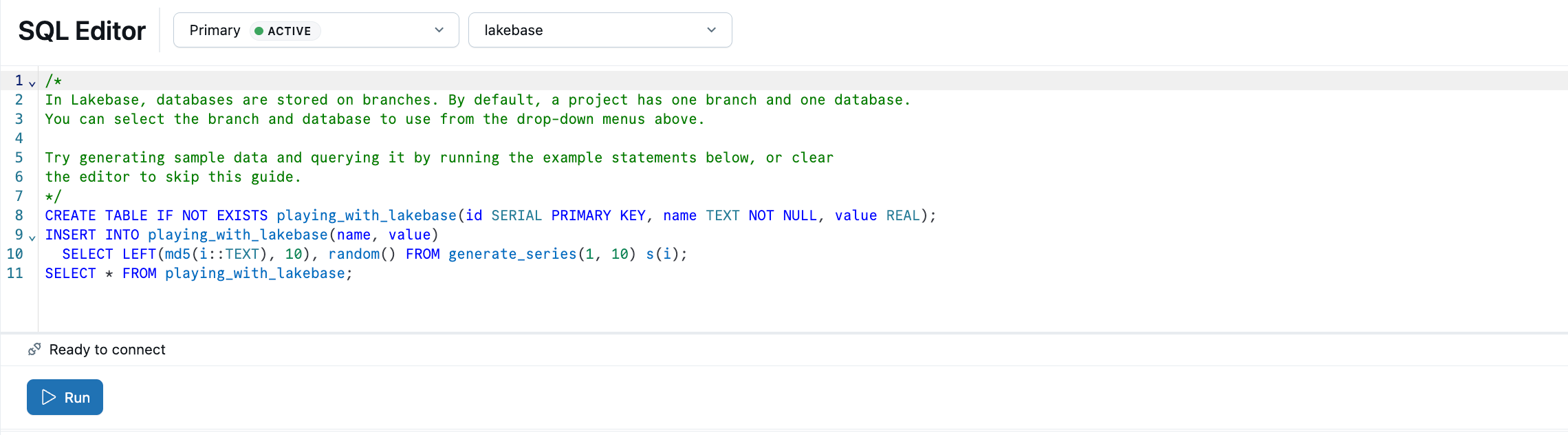
Saiba mais: Editor SQL | Editor de Tabelas | Clientes Postgres
Próximos passos
Próximo passo | Descrição |
|---|---|
Sincronize as tabelas Unity Catalog com o Postgres para leituras de aplicativos com baixa latência. | |
Armazene as alterações do Postgres como Delta com o CDF do Lakebase. (Prévia pública) |
Saber mais
-
- Crie um aplicativo
- Implantei um aplicativo Databricks com conexão automática Lakebase .
-
- registro no Unity Catalog
- Governança unificada, linhagem e consultas entre fontes.
-
- Conceitos básicos
- Escala automática, escala para zero, ramificação e como funcionam.
-
- Projetos
- Arquitetura, modelo de ramificação e visão geral do produto.