Alta disponibilidade
A alta disponibilidade combina um compute primário de leitura/gravação com uma ou mais instâncias compute secundárias distribuídas em diferentes zonas de disponibilidade. Quando o servidor primário fica indisponível, uma instância compute secundária é automaticamente promovida e sua aplicação continua a partir da última transação confirmada. Suas strings de conexão permanecem inalteradas.
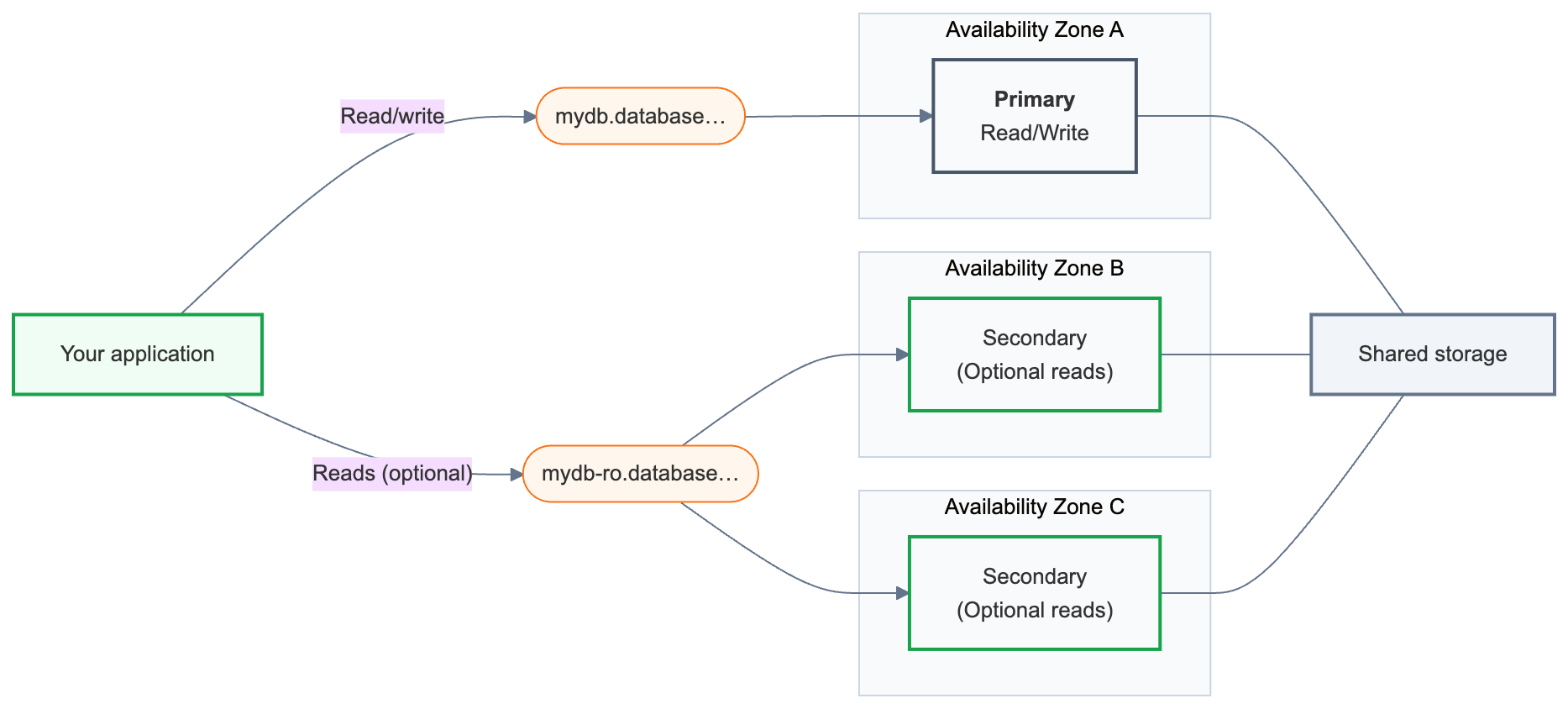
Alta disponibilidade configura somente redundância de compute. O armazenamento do Lakebase é altamente disponível independentemente da sua configuração de HA. Consulte Arquitetura de armazenamento.
Alta disponibilidade protege contra falhas de compute em uma única região. Para proteção contra problemas regionais, incluindo prejuízos e interrupções regionais, consulte Recuperação de desastres.
Como funciona a alta disponibilidade
Um endpoint do Lakebase é o endereço do banco de dados ao qual seu aplicativo se conecta. Um endpoint de alta disponibilidade expõe duas strings de conexão:
- Primário (
{endpoint-id}.database.{region}.databricks.com) — sua principal conexão de leitura/gravação. Utilize isso em todos os aplicativos que se conectam ao seu banco de dados. Após uma falha de compatibilidade, o encaminhamento é feito automaticamente para o compute que se tornou primário. - Secundário (
{endpoint-id}-ro.database.{region}.databricks.com) — disponível apenas quando Permitir acesso a instâncias compute somente leitura está habilitado. As instâncias compute secundárias existem principalmente como servidores de espera para contingências; habilitar o acesso de leitura permite que você também direcione consultas de leitura entre elas.
Ambas strings de conexão estão disponíveis na caixa de diálogo Conectar do seu endpoint.
Por trás dessas strings de conexão, um endpoint de alta disponibilidade sempre possui exatamente uma instância compute primária e de uma a três instâncias compute secundárias . O nó primário lida com todo o tráfego de leitura/gravação. Instâncias compute secundárias são executadas em diferentes zonas de disponibilidade e são promovidas a primárias em caso de falha.
Cada instância compute secundária possui uma configuração de Acesso que determina se ela também atende ao tráfego de leitura:
Acesso secundário | O que faz |
|---|---|
Somente leitura | A instância compute secundária atende às solicitações de leitura por meio das strings de conexão |
Desativada | A instância compute secundária está ativa e pronta para failover, mas não atende tráfego de leitura. |
Você controla isso com a configuração "Permitir acesso a instâncias compute somente leitura" no endpoint, que pode ser acessada no painel "Editar compute . Quando ativadas, todas as instâncias compute secundárias atendem a solicitações de leitura; quando desativadas, elas ficam em modo de espera apenas para casos de falha. Em ambos os casos, o hardware compute já está alocado e em funcionamento: a promoção não requer novo provisionamento, portanto, sua capacidade de failover é reservada independentemente da demanda na zona de disponibilidade.
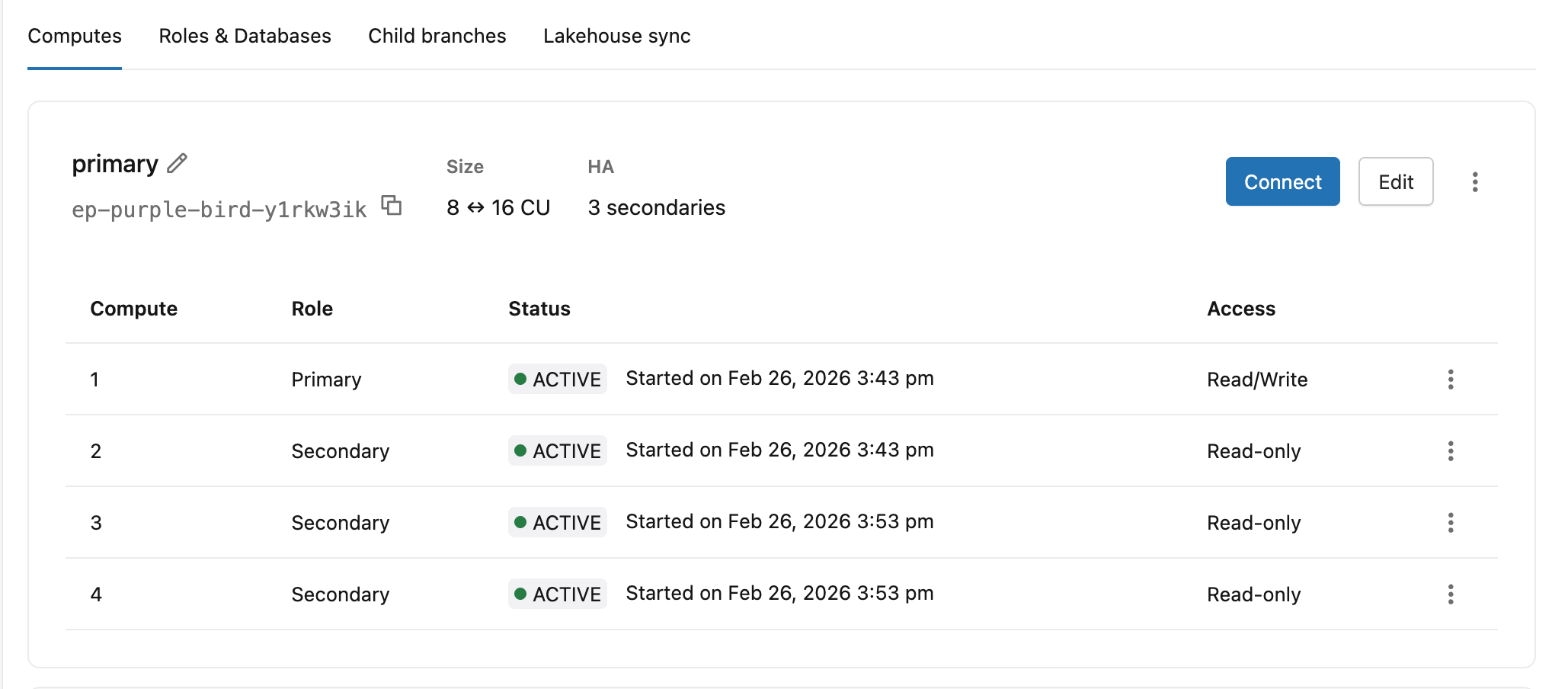
A tab "Computação" exibe, de forma resumida, a função (primária ou secundária), o status e o nível de acesso de cada instância compute .
Distribuição AZ
O Lakebase distribui as instâncias compute primárias e secundárias entre as zonas de disponibilidade, reduzindo o risco de que uma única falha em uma zona de disponibilidade afete tanto a instância primária quanto todas as instâncias compute secundárias.
dimensionamento automático em alta disponibilidade
Todas as instâncias compute em uma configuração de alta disponibilidade compartilham o mesmo intervalo de dimensionamento automático. A diferença máxima entre o seu número mínimo e máximo de CUs é de 16 CUs, o mesmo limite das instâncias compute independentes.
As instâncias compute secundárias são sempre dimensionadas para, no mínimo, o mesmo tamanho de CU (Unidade de Computação) que a instância primária, garantindo que a capacidade do seu banco de dados permaneça consistente após uma falha.
A opção "escalar para zero" não está disponível para instâncias compute em uma configuração de alta disponibilidade. Você pode pausar manualmente todas as instâncias compute , mas seu endpoint ficará indisponível durante esse período.
Instâncias compute secundárias versus réplicas de leitura independentes
Instâncias compute secundárias e réplicas de leitura independentes são recursos diferentes que podem coexistir no mesmo branch:
Instâncias compute secundárias | Réplicas de leitura independentes | |
|---|---|---|
Propósito | Failover + descarregamento de leitura opcional | Somente descarregamento de leitura |
Adicionado via | Configuração de alta disponibilidade | Adicionar Réplica de Leitura |
Participa em regime de failover. | Sim | Não |
Cadeias de conexão |
| endpointpróprio e separado |
Dimensionamento | Compartilhado com o nível primário (endpoint ) | Dimensionados independentemente |
Quando você precisa de alta disponibilidade e capacidade de leitura adicional além do que suas instâncias compute secundárias oferecem, você pode combinar ambos os recursos na mesma ramificação. Veja as réplicas de leitura.
Comportamento de failover
Failover automático
O Lakebase monitora continuamente a integridade compute principal. Caso o servidor primário fique indisponível, o failover é acionado automaticamente.
O failover preserva todas as transações confirmadas.
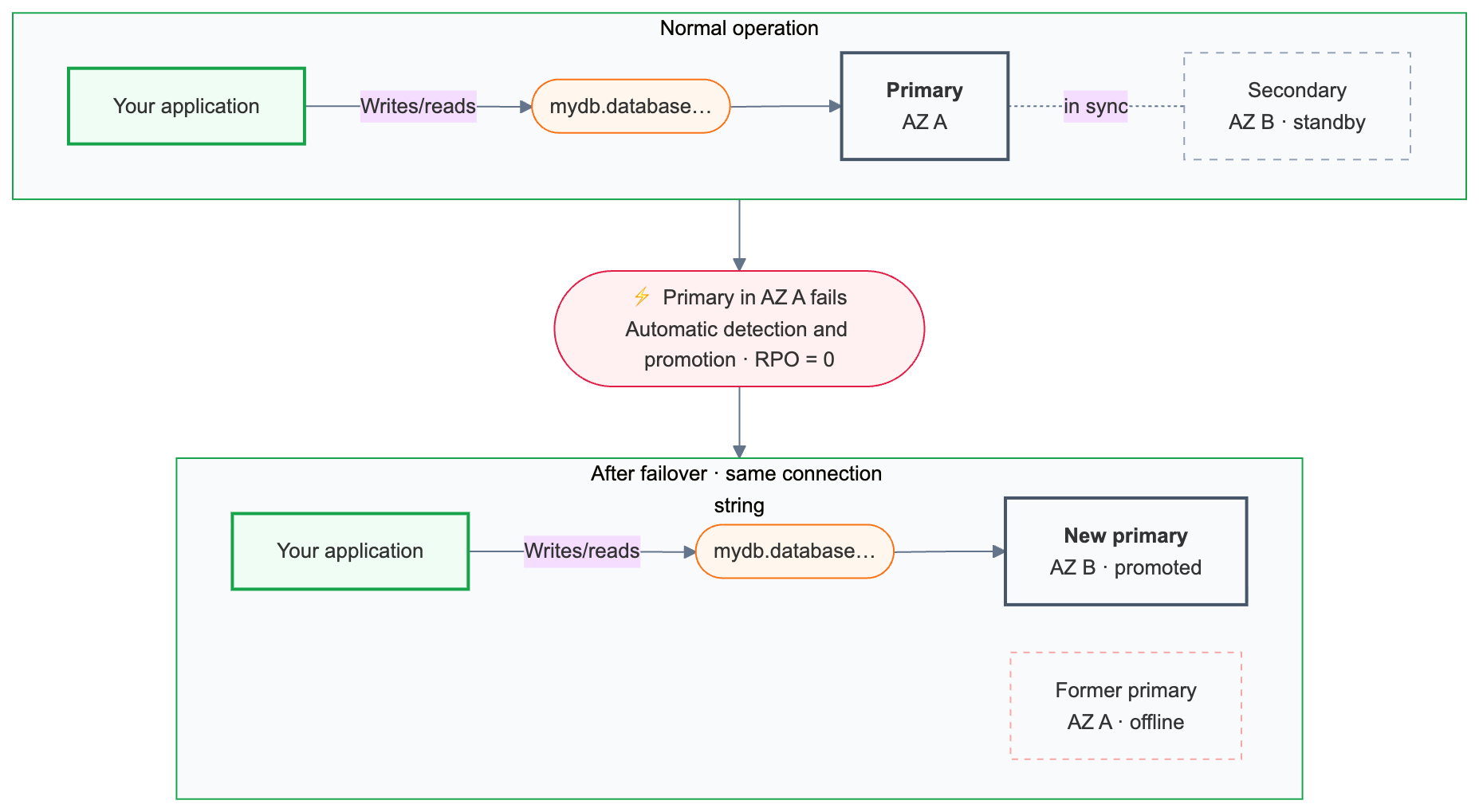
Após o failover, as strings de conexão primárias ({endpoint-id}.database.{region}.databricks.com) são automaticamente roteadas para a instância compute recém-promovida. Os aplicativos não precisam alterar sua configuração de conexão, mas as conexões existentes são encerradas durante o failover e devem se reconectar. Aplicações com lógica de repetição lidam com isso automaticamente.
Failover com acesso somente leitura ativado
Quando a opção "Permitir acesso a instâncias compute somente leitura" está habilitada e ocorre um failover, a instância secundária promovida se torna a nova primária e para de atender às solicitações de leitura. Se você tiver dois ou mais servidores secundários legíveis, o tráfego de leitura nas strings de conexão -ro continuará com capacidade reduzida até que uma substituição seja provisionada. Se houver apenas uma unidade, as leituras serão totalmente interrompidas até que a substituta esteja pronta.
stringsde conexão
A caixa de diálogo Conectar exibe ambas strings de conexão com seus respectivos status compute atuais:
opção de cálculo na caixa de diálogo Conectar | Cadeias de conexão | Usar para |
|---|---|---|
|
| Todas as escritas e leituras devem atingir o servidor primário atual. |
|
| Descarregamento de leitura para instâncias compute secundárias (disponível somente quando a opção "Permitir acesso a instâncias compute somente leitura " estiver ativada). |
As cadeias de conexão primárias sempre direcionam para o servidor primário atual, mesmo após uma falha.
Cada instância compute também possui suas próprias strings de conexão direta, acessíveis na tab de computação através do menu de ações (⋮) em cada linha. As conexões diretas destinam-se à resolução de problemas em instâncias compute individuais, não ao uso em aplicações. strings de conexão direta são porcompute e podem mudar quando servidores secundários são adicionados, removidos ou promovidos.
Limites de alta disponibilidade
Limite | Valor |
|---|---|
instâncias de computação | 2, 3 ou 4 (1 instância de computação primária + 1 a 3 instâncias compute secundárias) |
intervalo de escala automática (máximo − mínimo) | ≤ 16 CU entre o mínimo e o máximo |
Dimensionar para zero | Não disponível para instâncias compute em uma configuração de alta disponibilidade. |
Melhores práticas
Seguir essas práticas ajuda sua aplicação a permanecer resiliente e disponível durante eventos de failover.
Prática | Detalhes |
|---|---|
Implementar lógica de repetição de conexão | As conexões ativas são encerradas durante o failover. As conexões com o servidor primário com falha podem ficar travadas até que o tempo limite seja atingido — configure keepalives TCP ou um tempo limite de conexão em seu driver para detectar falhas prontamente. As conexões com o servidor secundário que está sendo promovido são encerradas ativamente, retornando um erro imediatamente. Aplicações com lógica de repetição se reconectam automaticamente em segundos. |
Configure a contagem secundária de acordo com seu caso de uso. | Cada instância compute secundária representa hardware pré-alocado reservado para failover. Reduzir o número de nós secundários significa menor capacidade de failover e menos zonas de disponibilidade cobertas. Uma instância compute secundária fornece cobertura de failover. Se você habilitar os secundários legíveis, configure dois ou mais. Com apenas um dispositivo, as leituras são totalmente interrompidas durante uma falha até que um substituto seja provisionado. |
Evite sobrecarregar instâncias compute secundárias. | O serviço pode reiniciar uma instância compute secundária que esteja sobrecarregada ou com desempenho abaixo do esperado. Monitore a carga de consultas e a contagem de conexões e aumente o tamanho da Unidade de Configuração (CU) se observar uma utilização elevada e sustentada. |
Recursos adicionais
- Gerenciar alta disponibilidade para habilitar e configurar alta disponibilidade.
- Para obter detalhes sobre o dimensionamento de CUs e os intervalos de dimensionamento automático, consulte a seção "Escala automática".
- stringsde conexão para referência completa de cadeias de conexão