Feed de dados de alterações do Lakebase
O recurso de Feed de Dados de Alterações do Lakebase está em Pré-visualização Pública.
O que é o Lakebase Change Data Feed?
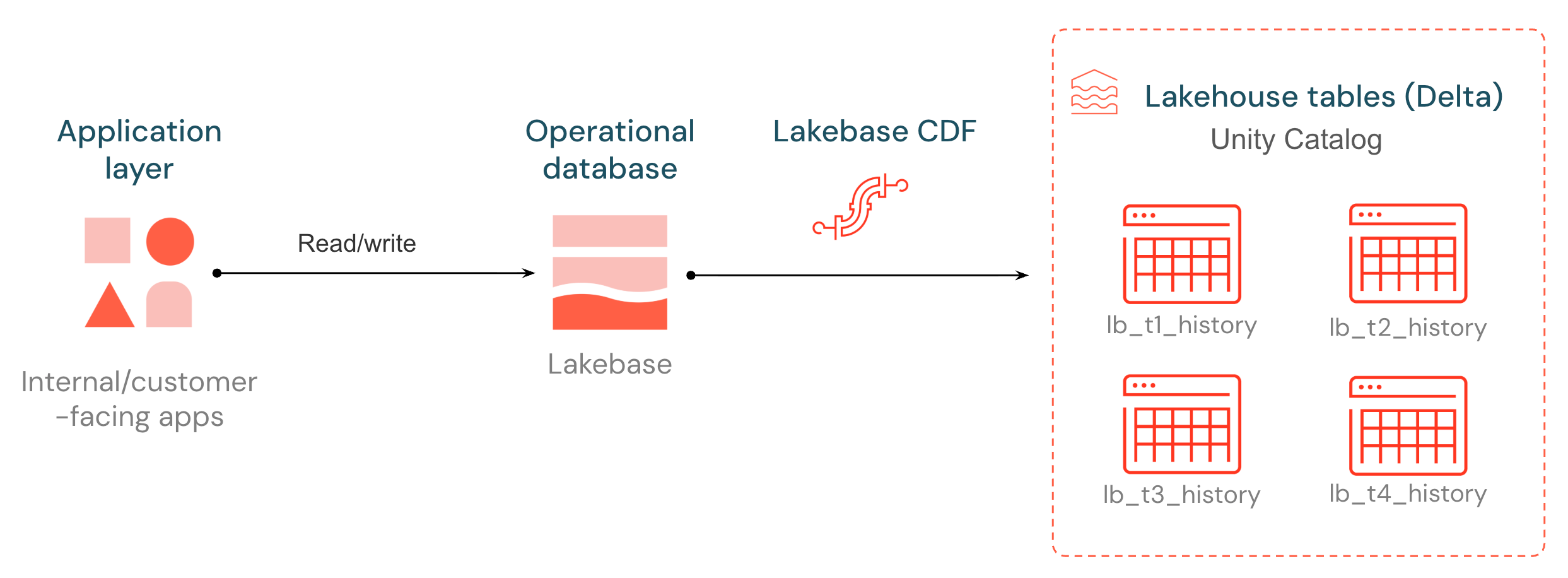
Lakebase introduz um Feed de Dados de Alteração (CDF) nativo, desbloqueando seus dados operacionais para pipelines, modelos e aplicações subsequentes. Cada inserção, atualização e exclusão em uma tabela Postgres Lakebase é capturada do log de escrita antecipada e armazenada como uma nova linha em uma tabela Delta Unity Catalog , sendo os lotes e liberados a cada ~15 segundos. O histórico de alterações é armazenado em um formato aberto que qualquer mecanismo compute pode ler.
As tabelas de destino seguem o mesmo formato do Delta Change Data Feed: cada linha contém um _pg_change_type, um LSN, um ID de transação e um carimbo de data/hora. As mudanças operacionais se tornam uma fonte de primeira classe para ETL, auditoria e consumidores subsequentes — sem a necessidade de instalar uma infraestrutura CDC externa.
Casos de uso
Lakebase CDF integra dados operacionais ao lakehouse , permitindo que os dutos e aplicativos subsequentes reajam às mudanças em tempo real.
Caso de uso | Descrição |
|---|---|
Pipeline ETL | Use o Lakebase como fonte bronze para pipelines medallion. Crie incrementais LakeFlow Pipelines ou Jobs Spark Structured Streaming contra o feed de alterações e atualize as tabelas silver e ouro downstream. |
Logs de auditoria | Mantenha um histórico completo e pesquisável de cada inserção, atualização e exclusão em uma tabela Lakebase para compliance e análise forense. A história é imutável, Delta. |
Sistemas externos | Armazene os dados de alteração do Lakebase em um formato aberto que qualquer mecanismo possa consumir. Como o destino é uma tabela Delta no Unity Catalog, sistemas externos e leitores que não sejam da Databricks podem acessar o feed diretamente. |
Ative esta pré-visualização
O administrador workspace deve ativar a pré-visualização do feed de dados de alteraçõesLakebase na página de pré-visualizações workspace .
Requisitos
- Lakebase autoscale: Um projetoLakebase autoscale executando o Postgres 17.
- Banco de dados de origem: As tabelas devem residir no banco de dados
databricks_postgresno Lakebase. Cada projeto é criado com este banco de dados default . Essa é uma limitação conhecida. - Unity Catalog: O CDF de configuração de identidade precisa de USE CATALOG , USE SCHEMA e CREATE TABLE no catálogo e esquema de destino. Consulte Conceder permissões a um objeto.
- Armazenamento padrão: Catálogos de destino configurados com armazenamento default não são suportados.
- Projeto Lakebase: Sua função no Postgres requer permissões CAN MANAGE no projeto Lakebase. Os proprietários de projetos têm CAN MANAGE por default. Consulte as permissões de gerenciamento do projeto.
- Tipos de dados: Consulte Mapeamento de tipos de dados. Os tipos sem um equivalente Delta direto são armazenados como strings.
Configure o CDF do Lakebase
Para começar, defina a identidade de réplica completa nas tabelas que você deseja no feed (passo 1) e, em seguida, inicie o CDF no aplicativo Lakebase (passo 2). Seus dados aparecem como tabelas Delta lb_<table_name>_history no catálogo Unity Catalog e no esquema que você escolher.
o passo 1: Definir a identidade da réplica completa
Para que uma tabela do Lakebase participe da CDF, ela deve ter REPLICA IDENTITY FULL definido. Por default o Postgres logs apenas a key primária quando uma linha é atualizada ou excluída. A configuração de identidade completa instrui o Postgres a registrar o estado da linha antes e depois da alteração no log de escrita antecipada (write-ahead log), o que o CDF precisa para construir um histórico de alterações completo.
Você pode executar esses comandos no Editor SQL Lakebase ou em qualquer cliente Postgres.
- Single table
- All existing tables in a schema
- Auto-apply to future tables
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Para definir a identidade de réplica em todas as tabelas existentes em um esquema (public neste exemplo), execute o seguinte comando:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Para que cada tabela recém-criada receba automaticamente REPLICA IDENTITY FULL, instale um gatilho de evento do Postgres. A execução ocorre após cada CREATE TABLE e define a identidade na nova tabela:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Combine o gatilho de evento com o loop na tab anterior para abranger tabelas existentes e futuras em uma única configuração.
Verifique quais tabelas têm identidade de réplica definida.
Para ver quais tabelas em um esquema têm identidade de réplica configurada, execute o seguinte comando:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Somente as linhas com replica_identity = 'full' estão prontas para a CDF.
o passo 2: comece o feed de dados de alteração
O CDF do Lakebase é configurado no nível do esquema. Uma vez iniciado, todas as tabelas atuais e futuras do esquema de origem são incluídas no feed.
-
No seu workspace Databricks , abra Lakebase Postgres no seletor de aplicativos (canto superior direito).
-
Selecione seu projeto Lakebase e a ramificação que deseja usar (por exemplo, produção ou principal ).
-
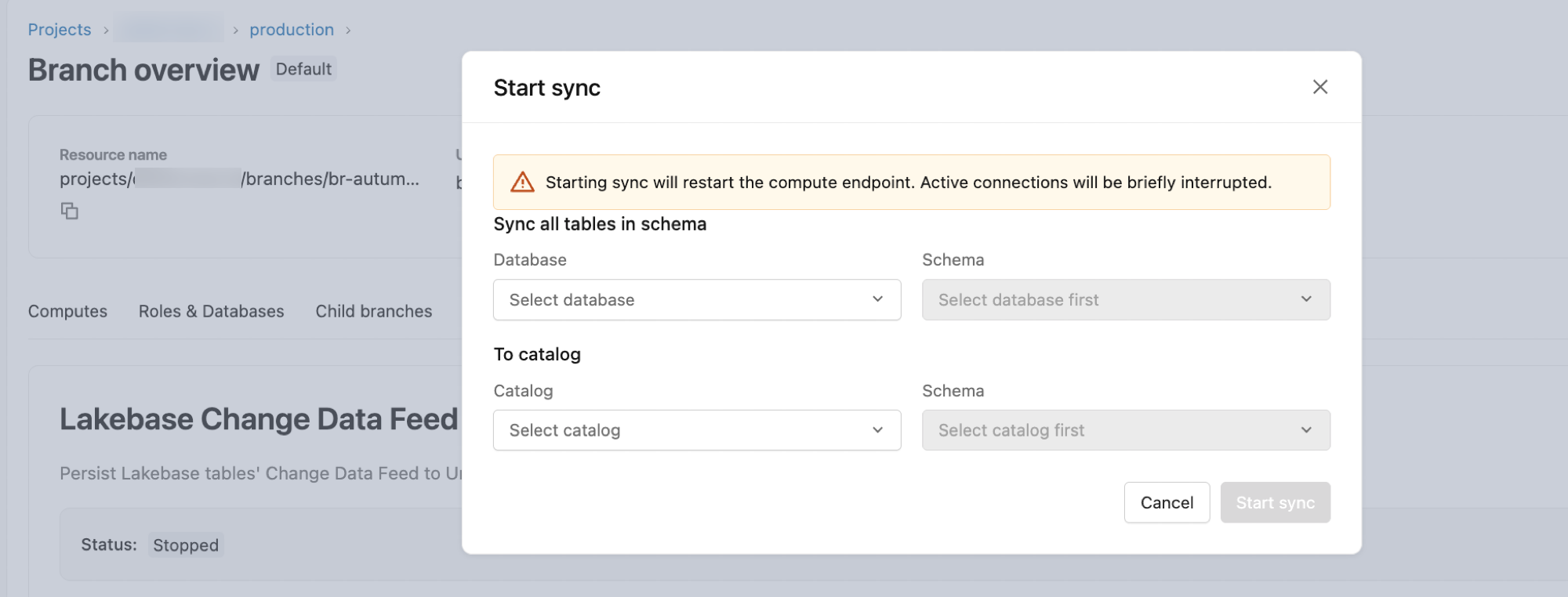
Abra a visão geral da Branch clicando no nome da Branch no breadcrumb superior e, em seguida, clique na tab Lakebase CDF .
-
Click começar .
-
Na caixa de diálogo de configuração:
- Banco de dados: valor padrão
databricks_postgres. - Esquema: Selecione o esquema Postgres de origem.
- Para catalogar: Selecione o catálogo Unity Catalog de destino.
- Esquema: Selecione o esquema de destino Unity Catalog .
- Banco de dados: valor padrão
-
Clique em Iniciar para começar a reprodução do feed.
As tabelas aparecem no destino como lb_<table_name>_history. Para encontrá-las, abra o Catálogo na barra lateral, navegue até o catálogo e esquema de destino e abra a tab Tabelas .
A tab Lakebase CDF tem duas sub-tabs:
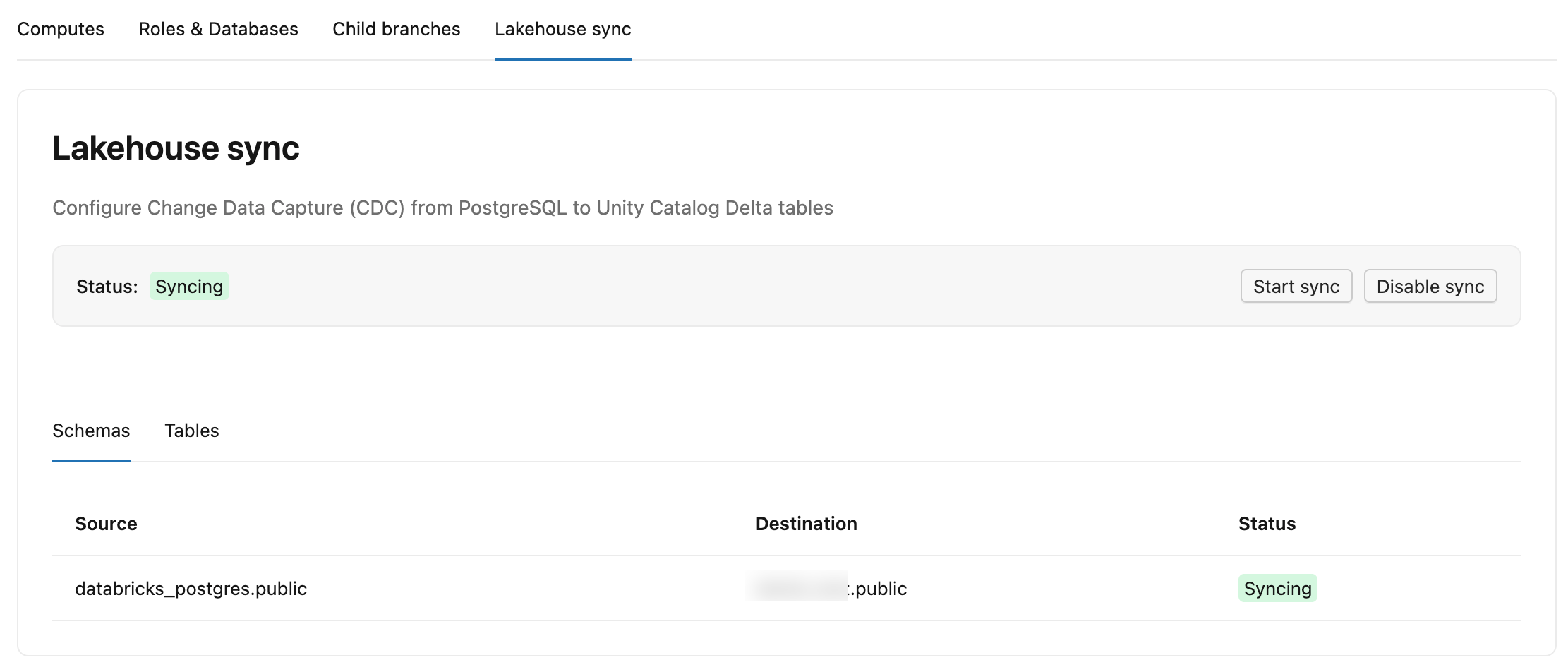
- Esquemas: Lista cada esquema de origem, seu catálogo de destino e esquema no Unity Catalog, além de um status.
- Tabelas: Lista cada tabela de origem, sua tabela de destino
lb_<table_name>_history, status (StreamingouSnapshotting), LSN confirmado (até que ponto o feed gravou no Delta, mostrado como-enquanto ainda no Snapshot inicial) e Última atualização (última vez que a tabela recebeu alterações).
Você também pode inspecionar o estado do feed do Postgres executando o seguinte comando no Editor SQL do Lakebase:
SELECT * FROM wal2delta.tables;
O resultado inclui table_oid, status (STREAMING ou SNAPSHOTTING), committed_lsn e last_write_time por tabela.
O que é wal2delta? Lakebase CDF é alimentado pela extensão wal2delta do Postgres, que é executada dentro do compute do Lakebase . Ele usa decodificação lógica para capturar as alterações log de gravação antecipada (WAL) e as grava em tabelas Delta no Unity Catalog.
Esquema da tabela de destino
O CDF grava uma tabela Delta por tabela de origem, nomeada lb_<table_name>_history em seu catálogo e esquema de destino. Além das colunas de origem, cada linha contém estas colunas do sistema:
Coluna | Tipo | Descrição |
|---|---|---|
| TEXT | tipo de operações: |
| BigInt | Número de sequência do log do Postgres. |
| Integer | ID da transação do Postgres. |
| Timestamp | Carimbo de data e hora em que a alteração foi processada (sem fuso horário). |
| BigInt | key de classificação monotônica usada para ordenar todas as alterações. |
Padrões de mudança comuns
- Instantâneo inicial: Na primeira execução do CDF em uma tabela existente Lakebase , cada linha existente é escrita com
_pg_change_type = 'insert'. - Atualizações: Uma atualização produz duas linhas: uma com
_pg_change_type = 'update_preimage'(linha antiga) e uma com_pg_change_type = 'update_postimage'(linha nova). - Exclusões: Uma exclusão produz uma linha com
_pg_change_type = 'delete'.
Esses são os mesmos eventos de alteração que o Delta Change Data Feed, portanto, os mesmos padrões subsequentes se aplicam.
Comportamento operacional
- Colisões de nomes: Se duas tabelas de origem mapearem para o mesmo nome de destino (por exemplo,
sales.usersemarketing.usersambas mapeando paralb_users_history), o CDF grava a primeira emlb_users_historye adiciona automaticamente o sufixolb_users_history_1à segunda. Você pode renomear qualquer uma das tabelas de destino no Unity Catalog e o feed continuará funcionando. - Escopo em nível de esquema: Ao iniciar um CDF em um esquema Lakebase , todas as tabelas atuais e futuras desse esquema são incluídas. Tabelas vazias são ignoradas — uma tabela precisa ter pelo menos uma linha para aparecer no destino.
- Tabelas de origem excluídas: Se você excluir uma tabela no Lakebase, a tabela Delta de destino no Unity Catalog será preservada.
Construir o oleoduto a jusante
Lakebase CDF foi projetado para dutos de distribuição que reagem a mudanças operacionais. Os padrões abaixo mostram três maneiras de consumir a ração, ordenadas da mais simples à mais flexível.
Cenário de exemplo. Um aplicativo de ecommerce registra pedidos em uma tabela Postgres orders, cada linha contendo um item_id e quantity. A equipe de logística precisa de níveis de estoque em tempo real. Com CDF, toda alteração em orders é armazenada na lb_orders_history tabela Delta no Unity Catalog. Pipelines a jusante leem esse feed de alterações e atualizam uma tabela inventory_levels sempre que um pedido é feito, editado ou cancelado.
Calcular o estoque atual com uma viewmaterializada.
O padrão mais simples é uma viewmaterializada em SQL sobre a tabela história. A tabela MV é atualizada incrementalmente à medida que novos eventos de alteração chegam, e os consumidores subsequentes a consultam como qualquer outra tabela.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
As duas linhas geradas a cada atualização se cancelam, exceto pela variação líquida, de modo que a soma acumulada permanece correta à medida que os pedidos são editados.
mudanças de transmissão com pipeline declarativo Spark
Para uma arquitetura medallion estruturada, use LakeFlow Pipelines para declarar tabelas bronze, silver e ouro. LakeFlow Pipelines os executam como um pipeline conectado com pontos de verificação e gerenciamento de dependências feito para você.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments lê lb_orders_history incrementalmente com readStream e produz um delta por evento. inventory_levels agrega por item_id para compute o estoque atual. A expectativa de queda de linhas levaria o estoque a valores negativos, sinalizando um bug em um estágio anterior do processamento.
Para obter um passo a passo completo, consulte o tutorial: Construir um pipeline ETL usando captura de dados de alterações (CDC).
Processamento personalizado com Spark transmissão estruturada
Quando você precisa de controle total — por exemplo, mesclagem personalizada, efeitos colaterais ou vários sinks — leia a tabela de história diretamente com Spark transmissão estruturada e use foreachBatch para escrever em seu destino.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Cada microlote agrega os eventos de mudança por item_id e mescla os deltas líquidos em inventory_levels.
**Incremental por design.** Cada tabela lb_<table_name>_history é uma tabela Delta somente de acréscimo. Cada alteração de origem é registrada como uma nova linha com _pg_change_type marcando a operação. Databricks SQL views materializadas, Lakeflow pipelines, e Spark Structured Streaming Job processam todas as novas linhas incrementalmente do log de transações Delta, assim, os pipelines downstream fazem apenas o trabalho proporcional ao que foi alterado. Não é necessário habilitar Feed de Dados de Alterações do Delta na tabela de história porque a semântica de alteração já está codificada nos dados da linha.
Mapeamento de tipo de dados
O CDF suporta a maioria dos tipos primitivos padrão do PostgreSQL. Os tipos sem um equivalente Delta direto são armazenados como strings.
Tipo PostgreSQL | Tipo Databricks Delta | Notas |
|---|---|---|
Booleana | Booleana | |
INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
TEXT, VARCHAR, CARACTERE | String | |
JSONB | String | Armazenado como uma string JSON . |
ENUM | String | Armazenado como o rótulo enum. |
NUMÉRICO / DECIMAL | DECIMAL ou strings | Utiliza a precisão/escala da fonte sempre que possível. Realiza reescalonamento sem perda de dados para valores de precisão/escala incompatíveis. Recorre a strings quando a precisão excede 38 ou quando a precisão/escala não estão definidas (NUMERIC ilimitado). Todas as colunas NUMERIC/DECIMAL podem ser nulas, pois os valores NaN são mapeados para NULL. Consulte Tipos numéricos do PostgreSQL. |
Data | Data | |
Timestamp | TIMESTAMP_NTZ | |
MARCAÇÃO DE TEMPO | Timestamp | |
FLUTUAR, DUPLO | FLUTUAR, DUPLO |
Tipos armazenados como strings:
- Geografia/Geometria (PostGIS): Tipos da extensão PostGIS (por exemplo,
geometry,geography). - Vetor (pgvector): O tipo
vectorda extensão pgvector. - Tipos compostos/estruturais: Tipos personalizados definidos com
CREATE TYPE ... AS (field_name type, ...). Esses são tipos semelhantes a linhas com campos nomeados. - Mapa: Tipos key-valor semelhantes a mapas, como hstore (da extensão
hstore). O Postgres não possui um tipo de mapa integrado.hstoreé a maneira comum de armazenar par key-valor em uma coluna.
Gerenciando alterações de esquema
- Renomear uma tabela no Postgres (por exemplo,
ALTER TABLE users RENAME TO customers) permite que o feed continue. O nome da tabela Delta de destino não muda — permanecelb_users_history. - Alterações no esquema (adicionar uma coluna, remover uma coluna ou alterar o tipo de dados de uma coluna) acionam um novo snapshot da tabela afetada. O CDF lê novamente a tabela inteira do Postgres e a reescreve na tabela Delta de destino.
Desativar CDF do Lakebase
Desativar o CDF interrompe o feed para todos os esquemas do Lakebase no projeto.
- No seu workspace Databricks , abra Lakebase Postgres no seletor de aplicativos (canto superior direito).
- Selecione seu projeto Lakebase e a ramificação onde você configurou o CDF.
- Abra a visão geral da Branch clicando no nome da Branch no breadcrumb superior e, em seguida, clique na tab Lakebase CDF .
- Clique em Desativar . Na caixa de diálogo de confirmação, revise o aviso de que as alterações deixarão de ser propagadas para as tabelas Delta e clique em Desativar novamente para confirmar.
Desativar o CDF não reinicia o seu compute.
Limitações e resolução de problemas
É possível ver o status por tabela (snapshotting, ignorada ou em transmissão) na tab Lakebase CDF , ou executando isso no Lakebase:
SELECT * FROM wal2delta.tables;
Motivos comuns pelos quais uma tabela não aparece no feed:
REPLICA IDENTITY FULLnão definido: execuçãoALTER TABLE <table_name> REPLICA IDENTITY FULL;para a tabela. Veja o passo 1: Defina a identidade da réplica como completa.- Tabelas particionadas: Tabelas particionadas no Lakebase não são suportadas. Um esquema que contém tabelas particionadas faz com que essas tabelas falhem.
- Tabelas vazias: Uma tabela com zero linhas é ignorada até que exista pelo menos uma linha.
Próximos passos
- Crie ETLincremental com o pipeline declarativoSpark. Consulte o tutorial: Construa um pipeline ETL usando captura de dados de alterações (CDC) para obter um passo a passo completo.
- Consulte a camada de bronze com o Databricks SQL. Consulte o artigo Introdução ao data warehousing usando Databricks SQL.
- Audit história com consultas de viagem do tempo nas tabelas Delta de destino.