Sincronização da casa do lago
Lakebase autoscale é a versão mais recente do Lakebase, com recursos como autoscale compute, escala-to-zero, branching e instant restore. Para regiões compatíveis, consulte Disponibilidade por região. Se você é usuário de provisionamento Lakebase , consulte ProvisionamentoLakebase.
O Lakehouse Sync está em versão prévia pública.
O que é o Lakehouse Sync?
O lakehouse Sync permite a replicação contínua e de baixa latência de suas tabelas Lakebase Postgres no Unity Catalog , gerenciando tabelas Delta ao capturar alterações em nível de linha e gravá-las como SCD Tipo 2. Cada alteração é adicionada como uma nova linha, permitindo manter um histórico completo de como as linhas mudaram ao longo do tempo. Essa sincronização não requer nenhum compute externo, pipeline ou tarefa. É um recurso nativo do Lakebase.
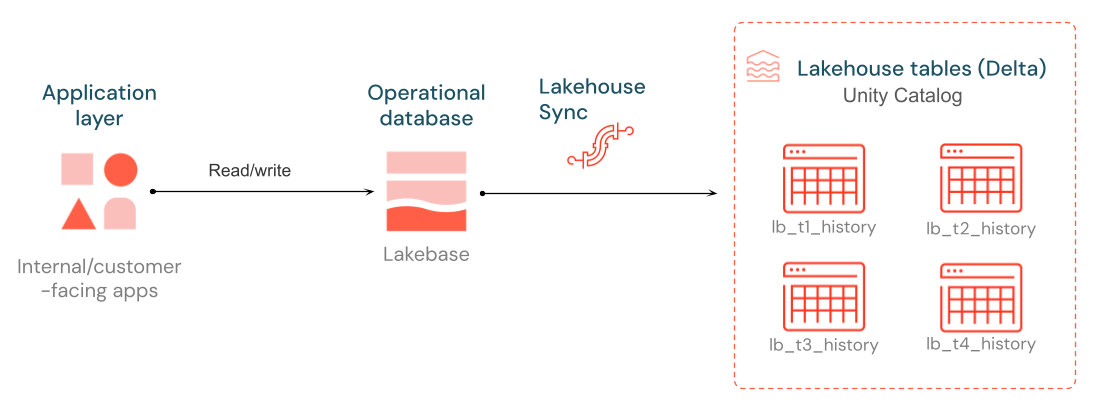
lakehouse Sync usa captura de dados de alterações (CDC) (CDC) para transmitir alterações de seu banco de dados Lakebase Postgres para o Unity Catalog. As tabelas Delta são nomeadas seguindo o formato lb_<table_name>_history no catálogo e esquema escolhidos. Cada alteração (inserção, atualização, exclusão) é adicionada como uma linha, permitindo que você mantenha um histórico completo de como seus dados evoluíram ao longo do tempo.
Exemplos de casos de uso
A seguir, apresentamos exemplos de casos de uso para o Lakehouse Sync, onde você transmite dados de alteração do seu banco de dados transacional Lakebase para o lakehouse.
Caso de uso | Descrição |
|---|---|
Análise rápida | agregações de execução e análises sobre dados do Lakebase. |
Fonte do medalhão | Utilize o Lakebase como fonte para a arquitetura do seu medalhão. As tabelas Delta podem ser processadas com o pipeline Databricks , o pipeline declarativoSpark (SDP) ou as tabelasDelta ativas (DLT) para construir tabelas subsequentes. |
História completa na lakehouse | Preserve o histórico completo de todas as mudanças na lakehouse , mantendo opcionalmente apenas um subconjunto dos dados no Lakebase. |
Ative esta pré-visualização
Para usar o Lakehouse Sync, um administrador workspace deve ativar a pré-visualização do Lakehouse Sync na página de pré-visualizações workspace .
Requisitos
- Lakebase autoscale: Um projeto Lakebase autoscale executando o Postgres 17.
- Banco de dados de origem: As tabelas devem residir no banco de dados
databricks_postgresno Lakebase. Essa é uma limitação conhecida. Cada projeto é criado com este banco de dados default . - Tipos de dados: Consulte o mapeamento de tipos de dados para saber como cada tipo do PostgreSQL é mapeado para o Delta. Os tipos sem um equivalente Delta direto são armazenados como strings.
- Unity Catalog: A identidade que configura a sincronização precisa de USE CATALOG , USE SCHEMA e CREATE TABLE no catálogo e esquema de destino. Consulte Conceder permissões a um objeto.
- Armazenamento padrão: Catálogos de destino configurados com armazenamento default não são suportados.
- Projeto Lakebase: Sua função no Postgres requer permissões CAN MANAGE no projeto Lakebase do qual você está sincronizando. Se a sua identidade for proprietária do projeto Lakebase, ela terá permissões CAN MANAGE por default. Consulte as permissões de gerenciamento do projeto.
Para começar: defina a identidade de réplica completa nas tabelas que deseja sincronizar (passo 1) e, em seguida, inicie a sincronização no aplicativo Lakebase (passo 2). Seus dados aparecem como tabelas lb_<table_name>_history no catálogo Unity Catalog e no esquema que você escolher. Se você quiser saber mais sobre como o Lakehouse Sync funciona antes de começar, consulte Como funciona o Lakehouse Sync.
Configurando a sincronização
o passo 1: Definir a identidade da réplica completa
Para que uma tabela do Lakebase seja sincronizada com sucesso, ela deve ter a identidade de réplica definida como completa. Você pode configurar a sincronização em um esquema vazio ou em um que já contenha tabelas. Tabelas particionadas não são suportadas.
Por default, o Postgres logs apenas a key primária quando uma linha é atualizada ou excluída. A configuração REPLICA IDENTITY FULL instrui o Postgres a registrar o estado completo da linha antes e depois no log de escrita antecipada. Isso é necessário para que o Lakehouse Sync possa construir um histórico de atualizações completo.
Você pode executar o seguinte comando no Editor SQL do Lakebase ou em qualquer cliente Postgres. Este exemplo utiliza o Editor SQL do Lakebase. Para abrir: no seu workspace Databricks , abra o Lakebase Postgres no seletor de aplicativos (canto superior direito), selecione seu projeto e a ramificação que deseja sincronizar (por exemplo, produção ou principal ), selecione EditorSQL na barra lateral e escolha a ramificação e o banco de dados. Consulte a seção "Consulta no Editor SQL do Lakebase" para obter detalhes.
- Single table
- Multiple tables
Para definir a identidade da réplica como completa em uma única tabela, execute o seguinte comando:
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Substitua <table_name> pelo nome da sua tabela.
Para definir a identidade da réplica como completa em todas as tabelas de um esquema (por exemplo, public), execute o seguinte comando:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
- Tabelas existentes: execute este comando em todas as tabelas existentes no esquema antes de iniciar a sincronização.
- Novas tabelas: Para tabelas criadas após a configuração da sincronização, execute este comando antes de inserir quaisquer dados. Se você inserir as linhas primeiro, a sincronização ainda as captura por meio de um Snapshot.
Verifique quais tabelas têm identidade de réplica definida.
Para ver quais tabelas têm identidade de réplica definida (e quais são full), execute o seguinte comando no Lakebase:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Altere n.nspname = 'public' para o nome do seu esquema, se for diferente. Somente as linhas com replica_identity = full estão prontas para a sincronização.
o passo 2: comece o Lakehouse Sync
O Lakehouse Sync é configurado no nível do esquema. Uma vez configurada, todas as tabelas atuais e futuras desse esquema são sincronizadas com o Unity Catalog.
-
No seu workspace Databricks , abra o Lakebase Postgres no seletor de aplicativos (canto superior direito).
-
Selecione seu projeto Lakebase e a ramificação que deseja sincronizar (por exemplo, produção ou principal ).
-
Abra a visão geral do Branch e clique na tab de sincronização do Lakehouse .
-
Clique em Iniciar sincronização .
-
Na caixa de diálogo de configuração:
- Banco de dados: valor padrão
databricks_postgres. - Esquema: Selecione o esquema Postgres de origem a ser sincronizado.
- Para catalogar: Selecione o catálogo Unity Catalog de destino.
- Esquema: Selecione o esquema de destino Unity Catalog .
- Banco de dados: valor padrão
-
Clique em Iniciar sincronização para começar a sincronizar os dados.
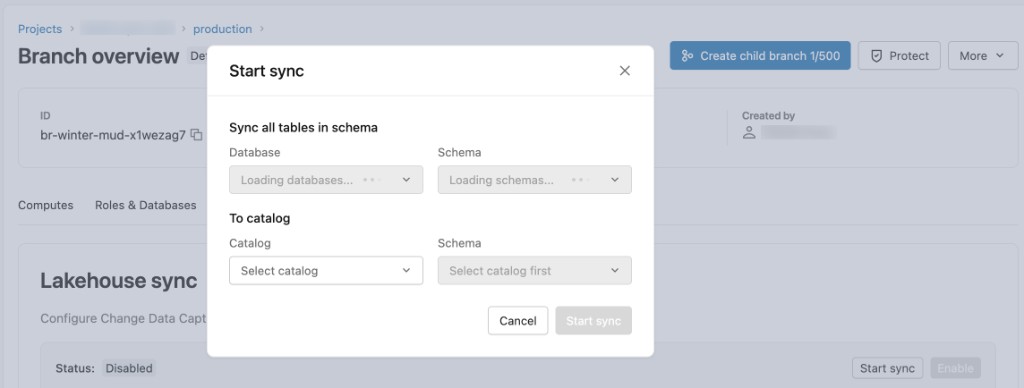
As tabelas aparecem no catálogo e esquema escolhidos do Unity Catalog como lb_<table_name>_history. No ambiente virtual (lakehouse), abra o Catálogo na barra lateral, acesse o catálogo e o esquema de destino e, em seguida, abra a tab Tabelas na Visão Geral do esquema para visualizar as tabelas Delta . Na tab de sincronização da casa no Lakebase, você pode confirmar o status e verificar o que está sendo sincronizado.
O que você vê na tabde sincronização da casa no lago.
Quando a sincronização está ativada, a parte superior da tab exibe o Status: Sincronizando e indica que as alterações estão sendo capturadas e sincronizadas com as tabelas Delta .
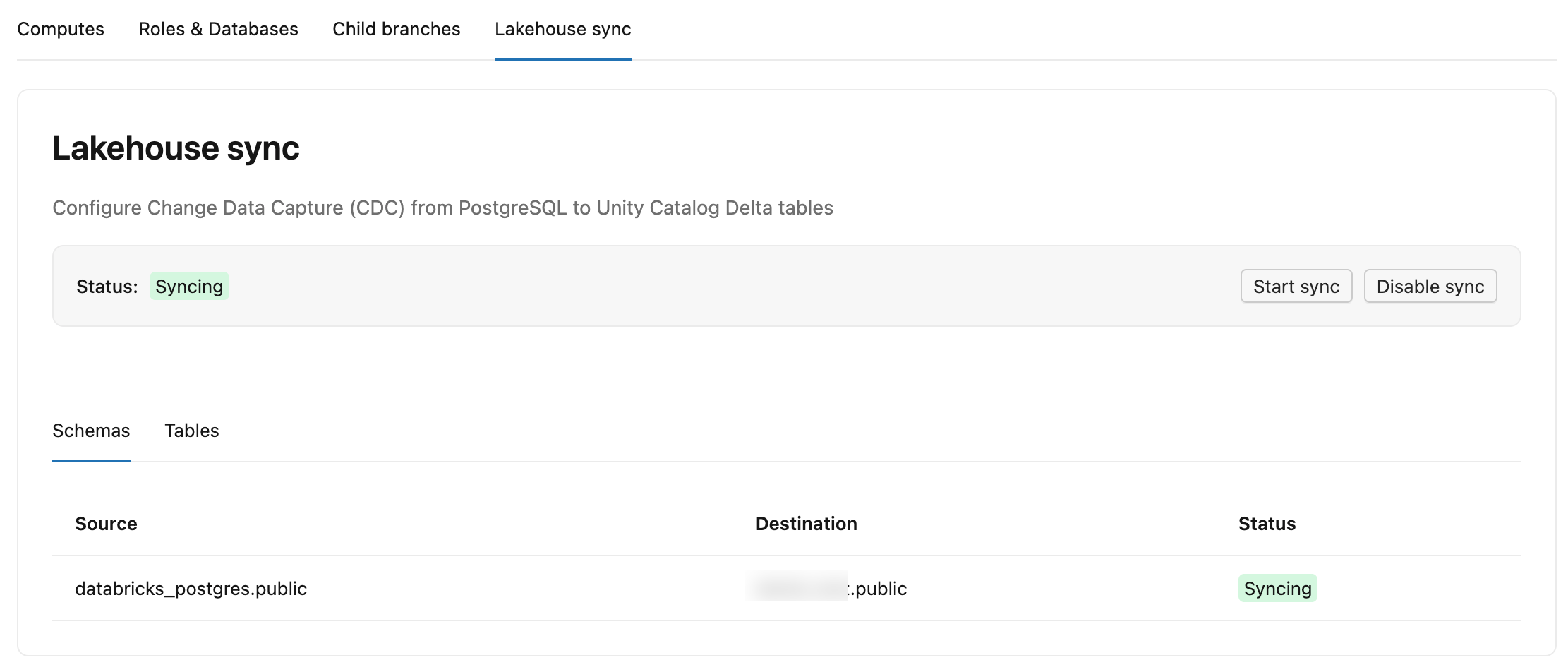
Duas subabas mostram o mapeamento e o progresso por tabela:
- Esquemas: Lista cada esquema de origem e seu catálogo e esquema de destino no Unity Catalog, com um Status (por exemplo, Sincronizando ) para esse esquema.
- Tabelas: Lista cada tabela de origem, sua tabela de destino
lb_<table_name>_historyno Unity Catalog, Status ( Sincronizando ou Capturando Snapshot ), LSN Confirmado (até onde a sincronização gravou no Delta; mostrado como-enquanto uma tabela ainda está no Snapshot inicial) e Última Sincronização (quando a tabela foi sincronizada pela última vez).
Você também pode executar SELECT * FROM wal2delta.tables; no Editor SQL do Lakebase (ou em qualquer cliente Postgres) para inspecionar o status de sincronização. O resultado inclui table_oid, status (por exemplo, STREAMING ou SNAPSHOTTING), committed_lsn e last_write_time para cada tabela.
O que é wal2delta? O lakehouse Sync é alimentado pela extensão wal2delta do Postgres, que é executada dentro do compute do Lakebase. Ele usa decodificação lógica para capturar as alterações log de gravação antecipada (WAL) e as grava em tabelas Delta no Unity Catalog.
Desativar a sincronização
Desativar a sincronização interrompe a replicação de todos os esquemas do Lakebase que estavam sendo sincronizados.
- No seu workspace Databricks , abra o Lakebase Postgres no seletor de aplicativos (canto superior direito).
- Selecione seu projeto Lakebase e a ramificação onde você configurou a sincronização (por exemplo, produção ou principal ).
- Abra a visão geral do Branch e clique na tab de sincronização do Lakehouse .
- Clique em Desativar sincronização . Na caixa de diálogo de confirmação, revise o aviso de que as alterações deixarão de ser sincronizadas com as tabelas Delta e clique em Desativar novamente para confirmar.
Desativar a sincronização não reinicia o seu compute.
Se você reativar a sincronização posteriormente, o sistema não realizará um novo snapshot completo. Quaisquer alterações que tenham ocorrido enquanto a sincronização estava desativada são permanentemente perdidas da tabela Delta de destino.
Como funciona o Lakehouse Sync
Em vez de sobrescrever a tabela de destino do Unity Catalog para refletir o estado atual dos seus dados no Lakebase, a sincronização adiciona uma nova linha para cada evento de alteração. Isso fornece um log completo e imutável de como seus dados evoluíram ao longo do tempo.
- Nomeação de destino: As tabelas Delta são criadas no Unity Catalog e usam o padrão de nomenclatura
lb_<table_name>_history. Estas são tabelas Delta da UC. - Colisões de nomes: Se duas tabelas de origem mapearem para o mesmo nome de destino (por exemplo,
sales.usersemarketing.usersambas mapeando paralb_users_history), o lakehouse Sync grava a primeira tabela que detecta emlb_users_historye adiciona automaticamente o sufixolb_users_history_1à segunda. Você pode renomear qualquer uma das tabelas de destino no Unity Catalog como achar melhor, e a sincronização continuará funcionando. O Unity Catalog impõe nomes de tabela exclusivos dentro de um esquema, portanto, duas tabelas Delta não podem compartilhar o mesmo nome de destino. - Sincronização em nível de esquema: Ao configurar a sincronização para um esquema do Lakebase, todas as tabelas atuais e futuras desse esquema são sincronizadas. Tabelas vazias não são sincronizadas. Deve haver pelo menos uma linha na tabela Lakebase para que ela apareça na sincronização.
- Tabelas excluídas: Se você excluir uma tabela no Lakebase, a tabela Delta de destino no Unity Catalog será preservada (não excluída).
Você pode monitorar o status de sincronização na tab de sincronização do Lakehouse na visão geral do branch ou executando SELECT * FROM wal2delta.tables; no Lakebase.
Esquema da tabela Delta de destino
Além das suas colunas de dados, a sincronização adiciona estas colunas do sistema a cada tabela Delta de destino no Unity Catalog:
Coluna | Tipo | Descrição |
|---|---|---|
| TEXT | tipo de operações: |
| BigInt | Número de sequência do log do Postgres. |
| Integer | ID da transação do Postgres. |
| Timestamp | Carimbo de data/hora em que a sincronização processou a alteração (sem fuso horário). |
| BigInt | key de classificação monotônica usada para ordenar todas as alterações. |
Padrões de mudança comuns
Esses padrões aparecem nas tabelas Delta de destino no Unity Catalog:
- Carga inicial: Na primeira execução de sincronização em uma tabela Lakebase existente, cada linha existente é escrita com
_pg_change_type=insert. - Atualizações: Uma atualização produz duas linhas: uma com
_pg_change_type=update_preimage(linha antiga) e uma com_pg_change_type=update_postimage(linha nova). - Exclusões: Uma exclusão produz uma linha com
_pg_change_type=delete.
Limitações e resolução de problemas
Você pode ver o status da tabela (quais tabelas estão sendo atualizadas, ignoradas ou transmitidas) na tab de sincronização do Lakehouse ou executando o seguinte comando no Lakebase:
SELECT * FROM wal2delta.tables;
Motivos comuns para uma tabela não sincronizar:
- IDENTIDADE DE RÉPLICA COMPLETA não definida: Certifique-se de executar
ALTER TABLE <table_name> REPLICA IDENTITY FULL;para cada tabela. - Tabelas particionadas: Tabelas particionadas no Lakebase não são suportadas. A sincronização de um esquema que contém tabelas particionadas faz com que essas tabelas não sejam sincronizadas.
Mapeamento de tipo de dados
A sincronização é compatível com a maioria dos tipos primitivos padrão do PostgreSQL. Os tipos sem um equivalente Delta direto são armazenados como strings.
Tipo PostgreSQL | Tipo Databricks Delta | Notas |
|---|---|---|
Booleana | Booleana | |
INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
TEXT, VARCHAR, CARACTERE | String | |
JSONB | String | Armazenado como uma string JSON . |
ENUM | String | Armazenado como o rótulo enum. |
NUMÉRICO / DECIMAL | DECIMAL ou strings | Utiliza a precisão/escala da fonte sempre que possível. Realiza reescalonamento sem perda de dados para valores de precisão/escala incompatíveis. Recorre a strings quando a precisão excede 38 ou quando a precisão/escala não estão definidas (NUMERIC ilimitado). Todas as colunas NUMERIC/DECIMAL podem ser nulas, pois os valores NaN são mapeados para NULL. Consulte Tipos numéricos do PostgreSQL. |
Data | Data | |
Timestamp | TIMESTAMP_NTZ | |
MARCAÇÃO DE TEMPO | Timestamp | |
FLUTUAR, DUPLO | FLUTUAR, DUPLO |
Tipos armazenados como strings:
- Geografia/Geometria (PostGIS): Tipos da extensão PostGIS (por exemplo,
geometry,geography). - Vetor (pgvector): O tipo
vectorda extensão pgvector. - Tipos compostos/estruturais: Tipos personalizados definidos com
CREATE TYPE ... AS (field_name type, ...). São tipos semelhantes a linhas com campos nomeados (às vezes chamados de structs). - Mapa: Tipos key-valor semelhantes a mapas, como hstore (da extensão
hstore). O Postgres não possui um tipo de mapa integrado;hstoreé a maneira usual de armazenar pares key-valor em uma coluna.
Gerenciando alterações de esquema
Renomear uma tabela no Postgres (por exemplo, ALTER TABLE users RENAME TO customers) permite que a sincronização continue. O nome da tabela Delta de destino não muda. Permanece lb_users_history.
Alterações no esquema (adicionar uma coluna, remover uma coluna ou alterar o tipo de dados de uma coluna) acionam um novo snapshot da tabela afetada. O Lakehouse Sync lê novamente a tabela inteira do Postgres e a reescreve na tabela Delta de destino.
Desduplicar para criar um espelho do estado atual
Para análises que precisam do estado atual da tabela Lakebase (um espelho) em vez do histórico completo, você pode remover duplicatas no Databricks SQL (por exemplo, no editor SQL do Lakehouse ou em um Notebook conectado a um SQL warehouse) agrupando pela key primária e selecionando o valor mais recente para cada coluna com max_by:
SELECT
id,
max_by(<column>, _sort_by) AS <column>
FROM `<catalog>.<schema>.lb_<table_name>_history`
GROUP BY id
HAVING max_by(_pg_change_type, _sort_by) IN ('insert', 'update_postimage');
Substitua id pela coluna key primária da sua tabela e adicione uma projeção max_by(<column>, _sort_by) AS <column> para cada coluna nãokey que você deseja manter. A consulta agrupa pela key e usa max_by com _sort_by para selecionar o valor mais recente para cada coluna. A cláusula HAVING mantém apenas a chave cujo evento mais recente foi um insert ou update_postimage, excluindo a chave cujo evento mais recente foi uma exclusão.
Próximos passos
Dependendo do seu objetivo, use as tabelas Delta lb_<table_name>_history com outros recursos Databricks :
- Análises rápidas: agregações de execução e análises ad-hoc sobre seu uso sincronizado de dados Databricks SQL (editor de consultas, dashboards, Notebook anexado a um SQL warehouse). Consulte o artigo "Primeiros passos com data warehousing usando Databricks SQL para obter um guia completo.
- Fonte do medalhão: Use suas tabelas Delta como camada de bronze e construa as camadas de prata e ouro com o pipeline. Veja O que é a arquitetura lakehouse com medalhão? Para o padrão e tutorial: Construa um pipeline ETL usando captura de dados de alterações (CDC) para um pipeline prático com camadas CDC e medallion usando o pipeline declarativo LakeFlow Spark .
- História completa na lakehouse: Consulte suas tabelas Delta em um ponto específico no tempo com Trabalhar com a história da tabela (viagem do tempo). Para obter um espelho do estado atual a partir de uma tabela Delta, consulte a seção "Remoção de duplicatas para criar um espelho do estado atual" acima.