gerenciar computação
compute é um serviço virtualizado que executa Postgres para seus projetos Lakebase . Cada ramificação possui um compute primário (de leitura e escrita). É necessário um compute para conectar-se a uma filial e acessar seus dados. Para uma visão geral de como computação e endpoint se relacionam, consulte computação e endpoint.
Entendendo a computação
visão geral de computação
Os recursos de computação fornecem o poder de processamento e a memória necessários para executar consultas, gerenciar conexões e lidar com operações de banco de dados. Cada projeto possui um compute principal de leitura e gravação para seu branch default .
Para se conectar a um banco de dados em uma filial, você deve usar um compute associado a essa filial. Computadores maiores consomem mais horas compute durante o mesmo período de atividade do que computadores menores.
calcular identificadores
Cada compute possui três identificadores, acessíveis pelo menu Obter ID na tab de Computação:
Identificador | Origem | Exemplo | Usado em |
|---|---|---|---|
Nome | O ID endpoint , definido como |
| Caminho do recurso da API ( |
UID | Gerado pelo sistema |
| hostnamede conexão |
Nome do recurso | Caminho completo da API |
| chamadas de API |
O hostname nas suas strings de conexão usa o UID , não o nome compute .
dimensionamento de cálculo
Tamanhos compute disponíveis
O Lakebase Postgres suporta os seguintes tamanhos compute :
- Autoscale de compute : 0,5 UC–64 UC (0,5, com incrementos inteiros: 1, 2, 3... 64)
- Computes de tamanho fixo maiores : 65 CU a 112 CU
O aplicativo Lakebase exibe um subconjunto de tamanhos comumente usados. Usando a API do Postgres, Terraform, pacotes de ativos da Databricks ou o SDK do Databricks, você pode definir qualquer valor inteiro de CU: 1–64 para compute com autoscale e 65–112 para compute de tamanho fixo maior.
O que contém uma unidade de computação?
Cada Unidade de Computação (CU) aloca aproximadamente 2 GB de RAM para a instância do banco de dados, juntamente com todos os recursos de CPU e SSD locais associados. A ampliação da escala aumenta esses recursos de forma linear. O Postgres distribui a memória alocada entre vários componentes:
- Caches de banco de dados
- memória do trabalhador
- Outros processos com requisitos de memória fixos
O desempenho varia de acordo com o tamanho dos dados e a complexidade da consulta. Antes de expandir, teste e otimize as consultas. O armazenamento escala automaticamente.
Provisionamento Lakebase vs escalonamento automático : No provisionamento Lakebase, cada unidade de computação alocou aproximadamente 16 GB de RAM. No Lakebase com escalonamento automático, cada Unidade de Computação (CU) aloca 2 GB de RAM. Essa mudança proporciona opções de dimensionamento mais detalhadas e maior controle de custos.
especificações de cálculo
Unidades de cálculo | BATER | Conexões máximas |
|---|---|---|
0,5 CU | ~1 GB | 105 |
1 CU | ~2 GB | 218 |
2 CU | ~4 GB | 443 |
3 CU | ~6 GB | 668 |
4 CU | ~8 GB | 894 |
5 CU | ~10 GB | 1.119 |
6 CU | ~12 GB | 1.344 |
7 CU | ~14 GB | 1.570 |
8 CU | ~16 GB | 1.795 |
9 CU | ~18 GB | 2020 |
10 CU | ~20 GB | 2.246 |
12 CU | ~24 GB | 2.696 |
14 CU | ~28 GB | 3.147 |
16 CU | ~32 GB | 3.597 |
24 CU | ~48 GB | 3.993 |
28 CU | ~56 GB | 3.993 |
32 CU | ~64 GB | 3.993 |
36 CU | ~72 GB | 3.993 |
40 CU | ~80 GB | 3.993 |
44 CU | ~88 GB | 3.993 |
48 CU | ~96 GB | 3.993 |
52 CU | ~104 GB | 3.993 |
56 CU | ~112 GB | 3.993 |
60 CU | ~120 GB | 3.993 |
64 CU | ~128 GB | 3.993 |
72 CU | ~144 GB | 3.993 |
80 CU | ~160 GB | 3.993 |
88 CU | ~176 GB | 3.993 |
96 CU | ~192 GB | 3.993 |
104 CU | ~208 GB | 3.993 |
112 CU | ~224 GB | 3.993 |
Limites de conexão para recursos de compute com autoscale : Quando o autoscale está ativado, o número máximo de conexões é determinado pelo menor entre sua CU máxima e 8x sua CU mínima. Por exemplo, se configurar o autoscale entre 2-8 UC, seu limite de conexão é 1.795 (o limite para 8 UC).
Limites de conexão da réplica de leitura : Os limites de conexão compute da réplica de leitura são sincronizados com suas configurações compute primária de leitura e gravação. Consulte o gerente para obter mais detalhes sobre as réplicas .
Algumas conexões são reservadas para uso administrativo e do sistema. Por esse motivo, SHOW max_connections pode apresentar um valor maior do que o número máximo de conexões exibido na tabela acima ou no painel Editar compute do aplicativo Lakebase. Os valores na tabela e na gaveta refletem o número real de conexões disponíveis para uso direto, enquanto SHOW max_connections inclui conexões reservadas.
Guia de tamanhos
Ao selecionar o tamanho compute , considere os seguintes fatores:
Fator | Recomendação |
|---|---|
Complexidade da consulta | Consultas analíticas complexas se beneficiam de capacidades compute maiores. |
conexões concorrentes | Mais conexões exigem mais CPU e memória. |
Volume de dados | Conjuntos de dados maiores podem exigir mais memória para um desempenho ideal. |
Tempo de resposta | Aplicações críticas podem exigir maior capacidade computacional para um desempenho consistente. |
Estratégia de dimensionamento ideal
Selecione um tamanho compute com base nos seus requisitos de dados:
- dataset completo na memória : Escolha um tamanho compute que possa armazenar todo o seu dataset na memória para obter o melhor desempenho.
- Conjunto de trabalho na memória : Para conjuntos de dados grandes, certifique-se de que os dados acessados com frequência caibam na memória.
- Limites de conexão : Selecione um tamanho que suporte o número máximo de conexões simultâneas previsto.
escala automática
O Lakebase suporta configurações compute de tamanho fixo e de escalonamento automático. O recurso de dimensionamento automático ajusta dinamicamente os recursos compute com base na demanda da carga de trabalho, otimizando tanto o desempenho quanto o custo.
Tipo de configuração | Descrição |
|---|---|
Tamanho fixo (0,5-64 UC) | Selecione um tamanho de compute fixo que não dimensiona conforme a demanda da carga de trabalho. Disponível para compute de 0,5 CU a 64 CU |
Dimensionamento automático (0,5–64 CU) | Use um controle deslizante para especificar os tamanhos mínimo e máximo de compute. O Lakebase escala para cima e para baixo dentro desses limites com base na carga atual. Disponível para compute até 64 CU (128 GB) |
Computes de tamanho fixo maiores (80–112 CU) | Selecione um compute maior de tamanho fixo de até 112 CU. Estes computes maiores estão disponíveis apenas em tamanhos fixos e não suportam autoscale. |
Autoscale limit: O autoscale é compatível com compute de até 64 CUs (128 GB). Para cargas de trabalho que exigem mais de 64 UC, computes de tamanho fixo maiores de 80, 96 ou 112 UC estão disponíveis.
Configurando o dimensionamento automático
Para ativar ou ajustar a escala automática de um compute, edite o compute e use o controle deslizante para definir os tamanhos mínimo e máximo compute .
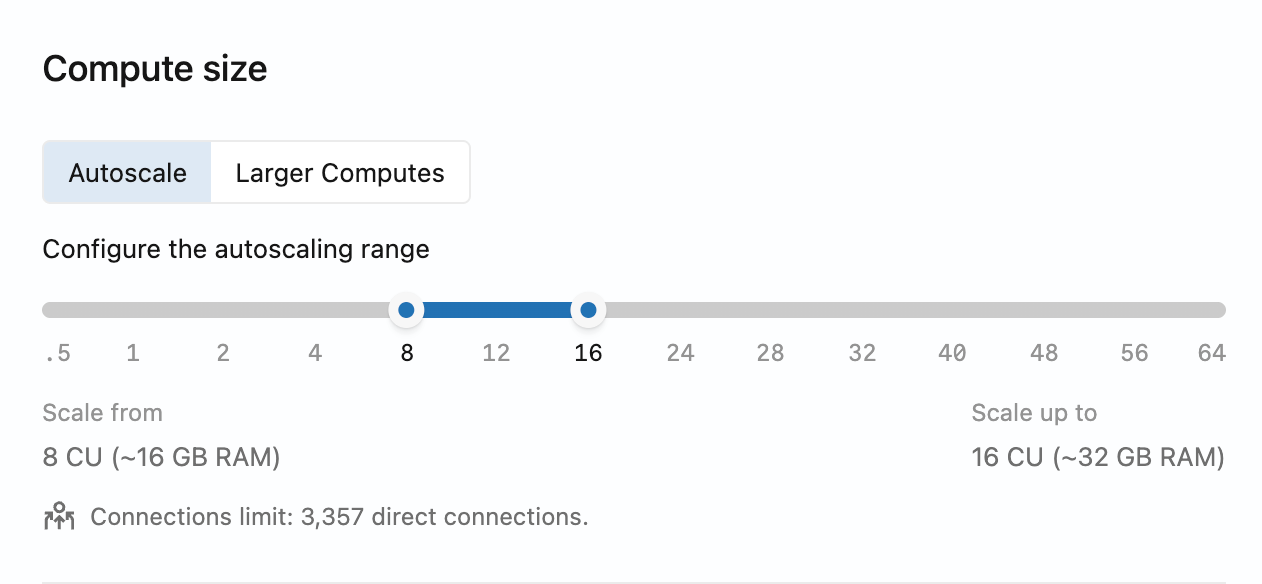
Para uma visão geral de como funciona o dimensionamento automático, consulte dimensionamento automático.
Considerações sobre escala automática
Para desempenho ideal de escala automática:
- Defina o tamanho mínimo compute suficientemente grande para armazenar em cache o conjunto de trabalho na memória.
- Considere que um desempenho ruim pode ocorrer até que o compute seja ampliado e seus dados sejam armazenados em cache.
- Seus limites de conexão são baseados no menor entre sua UC máxima e 8 vezes sua UC mínima
Restrições de Intervalo de Dimensionamento Automático : A diferença entre os tamanhos máximo e mínimo de compute não pode exceder 16 CU (ou seja, max - min ≤ 16 CU). Por exemplo, pode configurar o autoscale de 8 a 24 CU, ou de 48 a 64 CU, mas não de 0,5 a 32 CU (o que seria um intervalo de 31,5 CU). O controle deslizante no aplicativo Lakebase impõe essa restrição automaticamente. Para cargas de trabalho que exigem mais de 64 UC, use computes de tamanho fixo maiores, de até 112 UC.
escalar para zero
O recurso "escala-to-zero" do Lakebase automaticamente transforma um compute em um estado "parado" após um período de inatividade, reduzindo os custos para bancos de dados que não estão continuamente ativos.
Configuração | Descrição |
|---|---|
escalar para zero ativado | O sistema de computação suspende automaticamente a atividade após um período de inatividade para reduzir custos. |
escalar para zero desativado | Mantenha um compute "sempre ativo" que elimine a latência startup |
Para uma visão geral de como a escala para zero funciona, consulte Escala para zero. Para configurar a escala para zero para um compute, consulte Configurar escala para zero.
Criar e gerenciar computadores
visualizar computar
Visualizar na interface do usuário
Para view os dados de computação de uma ramificação, acesse a página "Ramos" do seu projeto no aplicativo Lakebase e selecione uma ramificação para view a tab de computação correspondente .
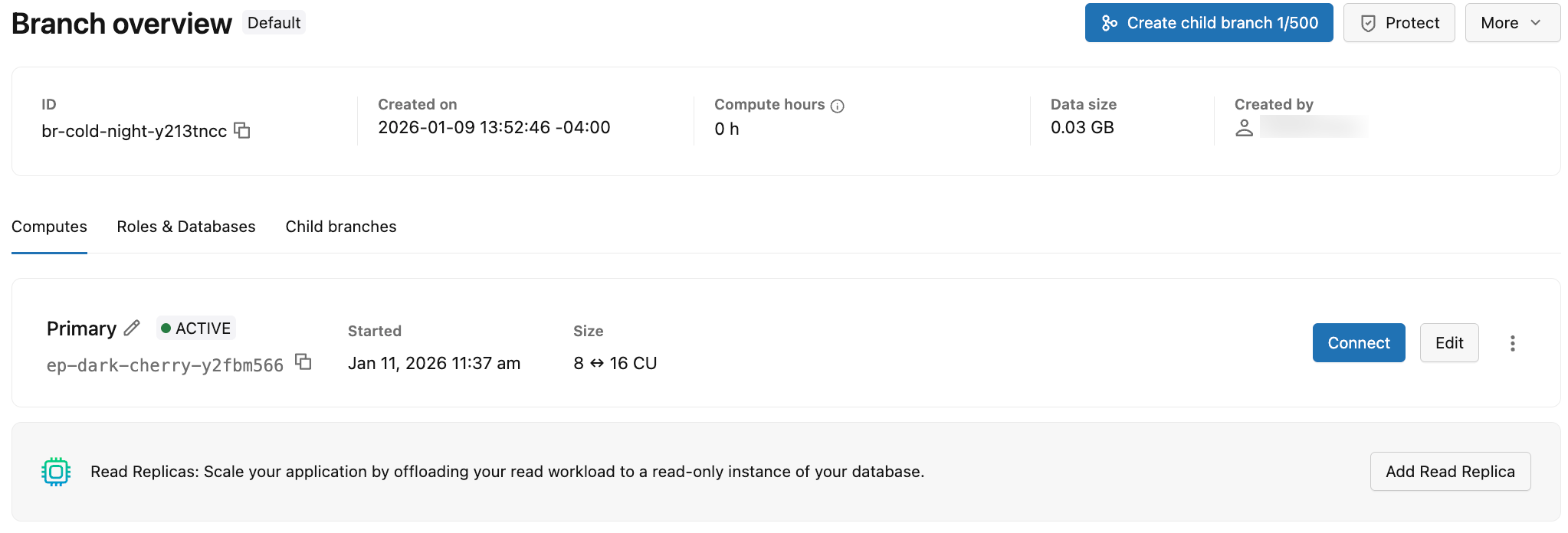
A tab "Compute" exibe informações sobre todos os cálculos associados à ramificação. As informações exibidas na tab "Calcular" estão resumidas na tabela a seguir.
Detalhe | Descrição |
|---|---|
Tipo de Compute | O tipo compute é Primário (leitura e gravação) ou Réplica de Leitura (somente leitura). Uma ramificação pode ter um único servidor primário (leitura e gravação) e várias réplicas de leitura (somente leitura). |
Status | Estado atual: Ativo ou Suspenso (quando o compute foi suspenso devido à redução da capacidade para zero). Mostra a data e a hora em que o compute foi suspenso. |
UID | O identificador único gerado pelo sistema para o compute, que começa com um prefixo |
Tamanho | O tamanho compute em unidadescompute (CU). Exibe um único valor de CU (por exemplo, 8 CU) para computação de tamanho fixo. Exibe um intervalo (por exemplo, 8-16) para computação com dimensionamento automático ativado. |
Última atividade | A data e a hora em que o compute esteve ativo pela última vez. |
Para cada compute, você pode:
- Clique em Conectar para abrir uma caixa de diálogo de conexão com os detalhes da conexão para a ramificação associada ao compute. A caixa de diálogo inclui uma opção para ativar/desativar o agrupamento de conexões para funções de senha nativas do Postgres. Consulte Conectar-se ao seu banco de dados e Usar o pool de conexões.
- Clique em Editar para modificar o tamanho compute (intervalo fixo ou de escala automática) e configurar as definições de escala para zero. Consulte Editar um compute.
- Clique no ícone de menu para acessar opções adicionais:
- Monitorar atividade : visualizar atividades compute e métricas de desempenho. Consulte Monitorar seu banco de dados.
- Reiniciar compute : Reinicie o compute para resolver problemas de conexão ou aplicar alterações de configuração. Consulte Reiniciar um compute.
Para adicionar uma compute de leitura ao branch, clique em Adicionar Réplica de Leitura . As réplicas de leitura são computação somente leitura que permitem o escalonamento horizontal, possibilitando o descarregamento da carga de trabalho de leitura da compute primária. Veja Réplicas de leitura e gerenciar réplicas de leitura.
Obtenha um programa compute
Para obter detalhes sobre um compute específico usando a API do Postgres:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get endpoint details
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute"
)
print(f"Endpoint: {endpoint.name}")
print(f"Type: {endpoint.status.endpoint_type}")
print(f"State: {endpoint.status.current_state}")
print(f"Host: {endpoint.status.hosts.host}")
print(f"Min CU: {endpoint.status.autoscaling_limit_min_cu}")
print(f"Max CU: {endpoint.status.autoscaling_limit_max_cu}")
No SDK, acesse o host através de endpoint.status.hosts.host (não endpoint.status.host).
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Endpoint;
WorkspaceClient w = new WorkspaceClient();
// Get endpoint details
Endpoint endpoint = w.postgres().getEndpoint(
"projects/my-project/branches/production/endpoints/my-compute"
);
System.out.println("Endpoint: " + endpoint.getName());
System.out.println("Type: " + endpoint.getStatus().getEndpointType());
System.out.println("State: " + endpoint.getStatus().getCurrentState());
System.out.println("Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println("Min CU: " + endpoint.getStatus().getAutoscalingLimitMinCu());
System.out.println("Max CU: " + endpoint.getStatus().getAutoscalingLimitMaxCu());
# Get endpoint details
databricks postgres get-endpoint projects/my-project/branches/production/endpoints/my-compute --output json | jq
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Listar computacionalmente
Para listar todas as réplicas de computação e leitura de uma ramificação usando a API do Postgres:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all endpoints for a branch
endpoints = list(w.postgres.list_endpoints(
parent="projects/my-project/branches/production"
))
for endpoint in endpoints:
print(f"Endpoint: {endpoint.name}")
print(f" Type: {endpoint.status.endpoint_type}")
print(f" State: {endpoint.status.current_state}")
print(f" Host: {endpoint.status.hosts.host}")
print(f" CU Range: {endpoint.status.autoscaling_limit_min_cu}-{endpoint.status.autoscaling_limit_max_cu}")
print()
No SDK, acesse o host através de endpoint.status.hosts.host (não endpoint.status.host).
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all endpoints for a branch
for (Endpoint endpoint : w.postgres().listEndpoints("projects/my-project/branches/production")) {
System.out.println("Endpoint: " + endpoint.getName());
System.out.println(" Type: " + endpoint.getStatus().getEndpointType());
System.out.println(" State: " + endpoint.getStatus().getCurrentState());
System.out.println(" Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println(" CU Range: " + endpoint.getStatus().getAutoscalingLimitMinCu() +
"-" + endpoint.getStatus().getAutoscalingLimitMaxCu());
System.out.println();
}
# List endpoints for a branch
databricks postgres list-endpoints projects/my-project/branches/production --output json | jq
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Configurações típicas de ramificação:
- 1 endpoint: compute primária somente para leitura e gravação
- 2+ pontos de extremidade: compute primária mais uma ou mais réplicas de leitura
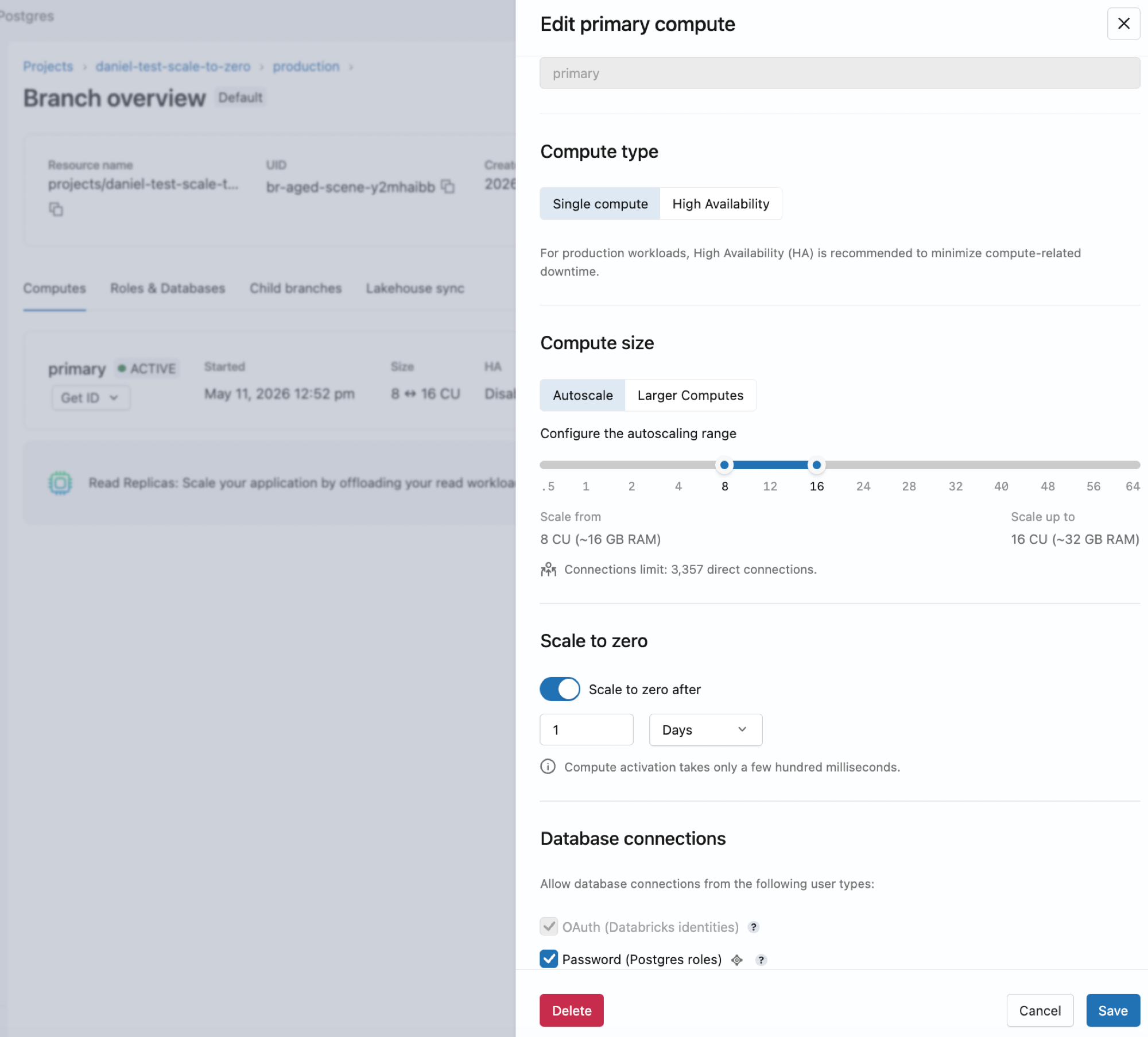
Editar um compute
Você pode editar um compute para alterar seu tamanho, configuração de dimensionamento automático ou configurações de escalonamento para zero. Os nomes dos computadores são somente leitura e não podem ser renomeados.
Para editar um compute:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Vá para a tab **Computes** da sua ramificação no aplicativo Lakebase.
- Clique em Editar para o compute, ajuste suas configurações e clique em Salvar .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
# Update a single field (max CU)
endpoint_spec = EndpointSpec(endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE, autoscaling_limit_max_cu=6.0)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=["spec.autoscaling_limit_max_cu"])
).wait()
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
Para atualizar vários campos, inclua-os tanto na especificação quanto na máscara de atualização:
# Update multiple fields (min and max CU)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
autoscaling_limit_min_cu=1.0,
autoscaling_limit_max_cu=8.0
)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=[
"spec.autoscaling_limit_min_cu",
"spec.autoscaling_limit_max_cu"
])
).wait()
print(f"Updated min CU: {result.status.autoscaling_limit_min_cu}")
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
// Update a single field (max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMaxCu(6.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
Para atualizar vários campos, inclua-os tanto na especificação quanto na máscara de atualização:
// Update multiple fields (min and max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMinCu(1.0)
.setAutoscalingLimitMaxCu(8.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_min_cu")
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
# Update a single field (max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute spec.autoscaling_limit_max_cu \
--json '{
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}'
# Update multiple fields (min and max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute "spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
--json '{
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}'
# Update a single field (max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}' | jq
# Update multiple fields (min and max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}' | jq
As alterações nas configurações compute entram em vigor imediatamente e podem causar breves interrupções de conexão durante a reinicialização.
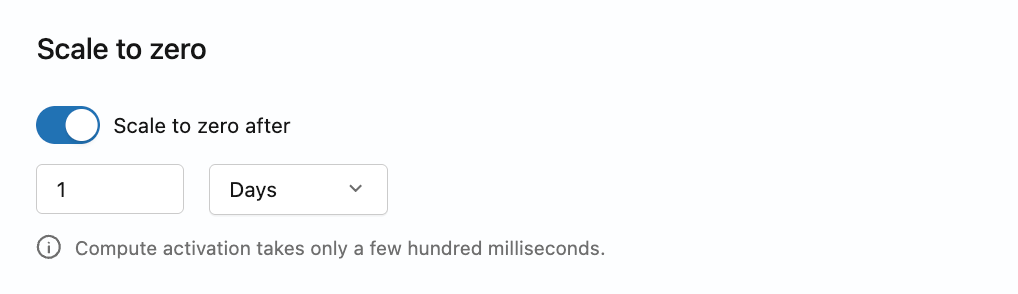
Configurar a escala para zero
Para configurar a escala para zero, inclua spec.suspension na máscara de atualização. Configure suspend_timeout_duration (60s–604800s) para definir o tempo limite de inatividade, ou no_suspension: true para desativá-lo. Não se deve definir ambos. A configuração no_suspension: false é inválida e retorna um erro. Por padrão, o branch production tem a escala para zero ativada com um tempo limite de 24 horas.
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Vá para a tab **Computes** da sua ramificação no aplicativo Lakebase.
- Clique em **Editar** para o compute e, em seguida, ative ou desative a configuração de escala para zero. Quando ativado, configure o limite de tempo de inatividade entre 60 segundos e 7 dias.
- Clique em Salvar .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
from google.protobuf.duration_pb2 import Duration
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-compute"
# Disable scale to zero (compute stays active indefinitely)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
no_suspension=True
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.suspension"])
).wait()
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
suspend_timeout_duration=Duration(seconds=300)
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.suspension"])
).wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.Duration;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
String endpointName = "projects/my-project/branches/production/endpoints/my-compute";
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.suspension")
.build();
// Disable scale to zero (compute stays active indefinitely)
EndpointSpec noSuspensionSpec = new EndpointSpec()
.setNoSuspension(true);
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(noSuspensionSpec))
.setUpdateMask(updateMask)
);
// Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
EndpointSpec timeoutSpec = new EndpointSpec()
.setSuspendTimeoutDuration(
Duration.newBuilder().setSeconds(300).build()
);
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(timeoutSpec))
.setUpdateMask(updateMask)
);
# Disable scale to zero (compute stays active indefinitely)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.suspension \
--json '{
"spec": {
"no_suspension": true
}
}'
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.suspension \
--json '{
"spec": {
"suspend_timeout_duration": "300s"
}
}'
# Disable scale to zero (compute stays active indefinitely)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.suspension" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"no_suspension": true
}
}' | jq
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.suspension" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"suspend_timeout_duration": "300s"
}
}' | jq
Desativar ou ativar o compute
Desativar um compute suspende-o e bloqueia todas as novas conexões. Ao contrário da escala para zero, um compute desativado não pode ser ativado por uma tentativa de conexão ou a partir do aplicativo Lakebase. Para reabilitá-lo, você pode usar a API.
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-compute"
# Disable a compute (blocks all connections)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
disabled=True
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.disabled"])
).wait()
# Re-enable a compute
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
disabled=False
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.disabled"])
).wait()
Para verificar se um compute está atualmente desativado, leia o valor do status do endpoint. Você define o valor em spec.disabled, mas o lê de volta de status.disabled:
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute"
)
print(endpoint.status.disabled) # True = disabled, False or None = enabled
# Disable a compute (blocks all connections)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.disabled \
--json '{
"spec": {
"disabled": true
}
}'
# Re-enable a compute
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.disabled \
--json '{
"spec": {
"disabled": false
}
}'
Para verificar se um compute está atualmente desativado, leia status.disabled do endpoint:
databricks postgres get-endpoint projects/my-project/branches/production/endpoints/my-compute --output json | jq '.status.disabled'
# Disable a compute (blocks all connections)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.disabled" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"disabled": true
}
}' | jq
# Re-enable a compute
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.disabled" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"disabled": false
}
}' | jq
Para verificar se um compute está atualmente desativado, leia status.disabled do endpoint:
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq '.status.disabled'
Após reabilitar um compute, novas tentativas de conexão poderão falhar até que o compute conclua a reinicialização.
Reinicie um compute
Reinicie um compute para aplicar atualizações, resolver problemas de desempenho ou obter alterações de configuração.
Para reiniciar um compute:
- Vá para a tab **Computes** da sua ramificação no aplicativo Lakebase.
- Clique no
 No menu do compute, selecione Reiniciar e confirme as operações.
No menu do compute, selecione Reiniciar e confirme as operações.
Reiniciar um compute interrompe todas as conexões ativas. Configure seus aplicativos para se reconectarem automaticamente e evitar interrupções prolongadas.