gerenciar alta disponibilidade
Este guia aborda como habilitar e gerenciar a alta disponibilidade para seu endpoint Lakebase. Para obter informações básicas sobre como funciona a alta disponibilidade e como as instâncias compute secundárias diferem das réplicas de leitura independentes, consulte Alta disponibilidade.
Habilitar alta disponibilidade
Para habilitar alta disponibilidade, defina o tipo compute e a configuração HA na interface do usuário ou configure o endpoint 's EndpointGroupSpec via API.
Pré-requisitos
- A opção "escalar para zero" deve ser desativada. Na interface do usuário, defina a escala como zero ou " Desligado" no menu de edição compute . Por meio da API, defina
no_suspension: truena especificação do endpoint (usespec.suspensioncomo máscara de atualização).
- UI
- Python SDK
- CLI
- curl
Após criar um projeto, clique no link compute principal no painel do projeto para abrir a gaveta de edição compute .
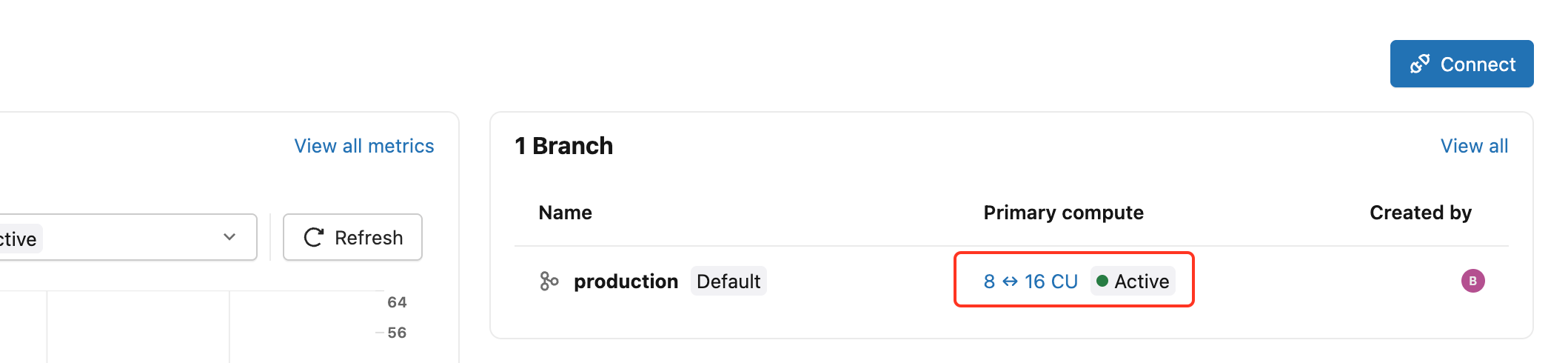
Defina o tipo de computação como Alta disponibilidade e, em seguida, escolha uma Configuração em Alta disponibilidade :
- 2 (1 primária, 1 secundária),
- 3 (1 primária, 2 secundárias),
- ou 4 instâncias compute no total (1 primária e 3 secundárias).
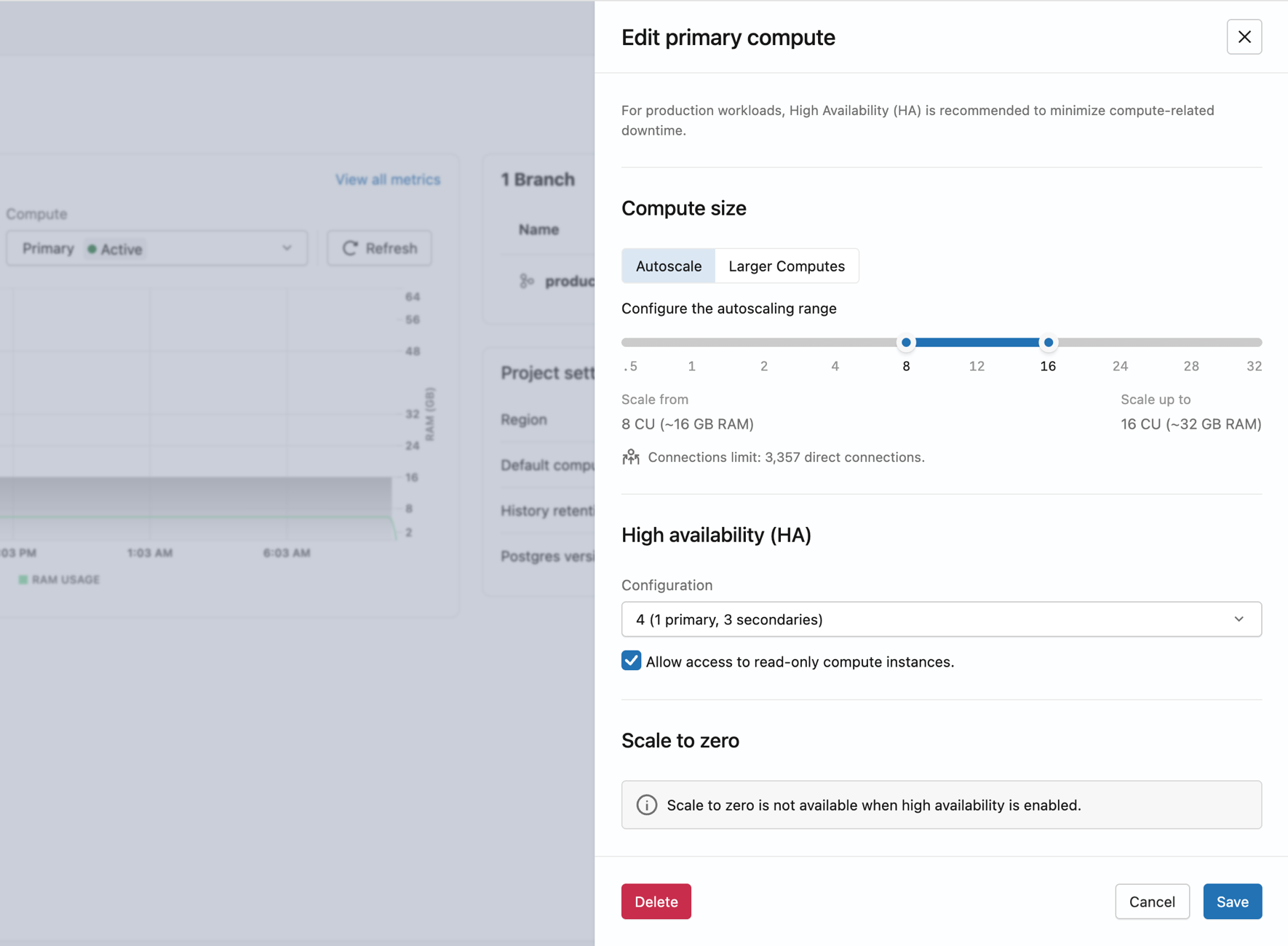
O Lakebase provisiona instâncias compute secundárias em diferentes zonas de disponibilidade. Assim que todas as instâncias compute estiverem ativas, o endpoint terá failover automático.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
no_suspension=True,
group=EndpointGroupSpec(
min=2,
max=2,
enable_readable_secondaries=True
)
)
),
update_mask=FieldMask(field_mask=["spec.group", "spec.suspension"])
).wait()
print(f"Group size: {result.status.group.max}")
print(f"Host: {result.status.hosts.host}")
print(f"Read-only host: {result.status.hosts.read_only_host}")
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group,spec.suspension" \
--json '{
"spec": {
"no_suspension": true,
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group,spec.suspension" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"no_suspension": true,
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Configure o acesso somente leitura às instâncias compute secundárias.
Permitir acesso a instâncias compute somente leitura controla se as instâncias compute secundárias atendem ao tráfego de leitura por meio das strings de conexão -ro .
- UI
- Python SDK
- CLI
- curl
- Na tab Computação , clique em Editar na compute primária.
- Em Alta disponibilidade , marque ou desmarque a opção Permitir acesso a instâncias compute somente leitura .
- Clique em Salvar .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Get current group size first
current = w.postgres.get_endpoint(name=endpoint_name)
current_size = current.status.group.max
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=current_size,
max=current_size,
enable_readable_secondaries=True # set False to disable
)
)
),
update_mask=FieldMask(field_mask=["spec.group.enable_readable_secondaries"])
).wait()
# Replace 2 with your current group size
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.enable_readable_secondaries" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
# Replace 2 with your current group size
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.enable_readable_secondaries" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Com apenas uma instância compute secundária e acesso de leitura habilitado, todo o tráfego de leitura nas strings de conexão -ro é interrompido durante um failover até que uma substituição seja adicionada. Para acesso de leitura resiliente, configure duas ou mais instâncias compute secundárias com acesso de leitura habilitado.
Alterar o número de instâncias compute secundárias
- UI
- Python SDK
- CLI
- curl
- Na tab Computação , clique em Editar na compute primária.
- Em Alta disponibilidade , escolha uma nova configuração de computação no dropdown ( 2 , 3 ou 4 instâncias compute no total).
- Clique em Salvar .
Para desativar a alta disponibilidade, defina o tipo de computação de volta para computeúnica . Isso remove todas as instâncias compute secundárias e seu endpoint retorna a uma configuraçãocompute única.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Scale to 3 compute instances (1 primary + 2 secondaries)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(min=3, max=3)
)
),
update_mask=FieldMask(field_mask=["spec.group.min", "spec.group.max"])
).wait()
# Scale to 3 compute instances (1 primary + 2 secondaries)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.min,spec.group.max" \
--json '{
"spec": {
"group": { "min": 3, "max": 3 }
}
}'
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.min,spec.group.max" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": { "min": 3, "max": 3 }
}
}' | jq
Veja o status e as funções de alta disponibilidade.
A tab "Computação" mostra todas as instâncias compute em sua configuração de alta disponibilidade, com sua função, status e nível de acesso atuais.
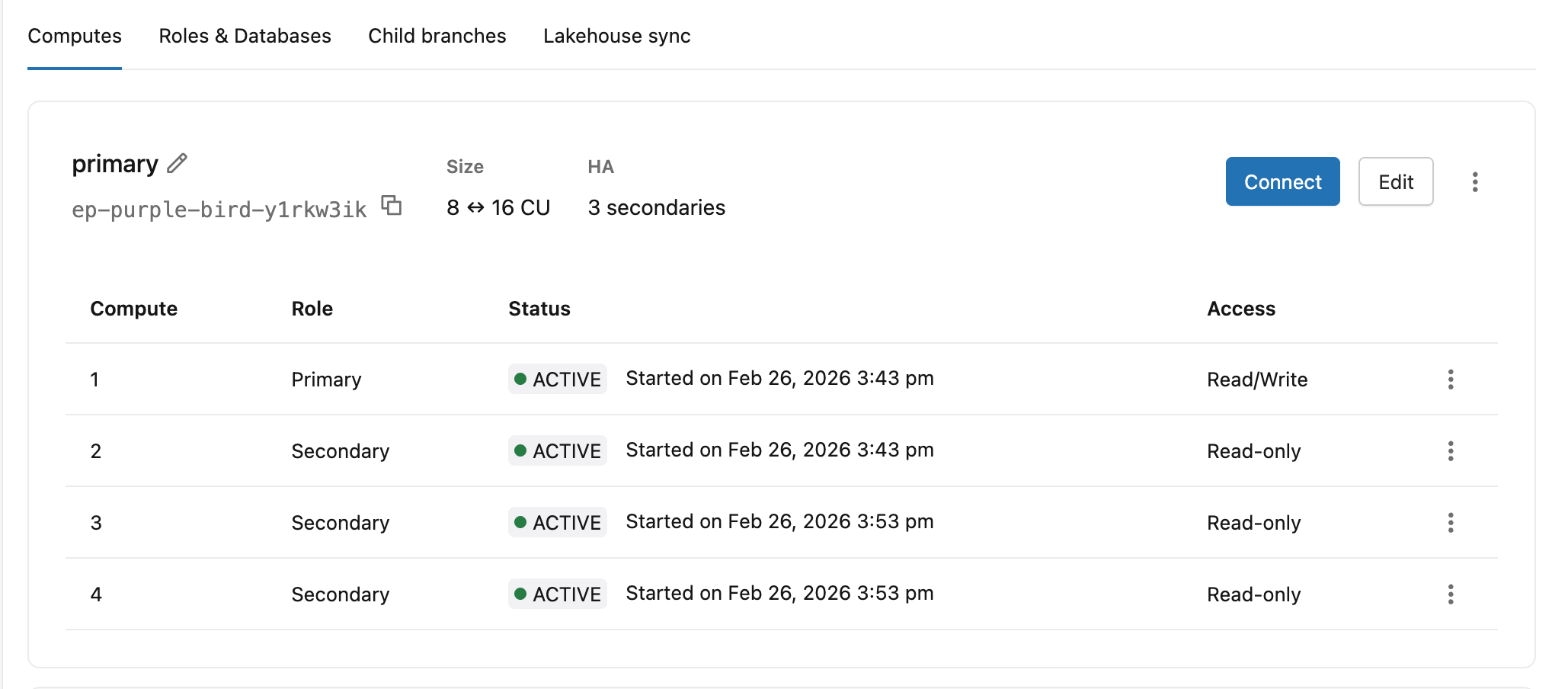
Coluna | Valores |
|---|---|
Função | Ensino fundamental, Ensino médio |
Status | Iniciando, Ativo |
Acesso | Leitura/Gravação (primária), Somente leitura (instância compute secundária com acesso habilitado), Desabilitado (instância compute secundária sem acesso de leitura) |
O cabeçalho compute primário também mostra o ID endpoint , o intervalo de dimensionamento automático e a contagem secundária (por exemplo, 8 ↔ 16 CU · 3 secondaries).
Obtenha as strings de conexão.
- UI
- Python SDK
- CLI
- curl
Clique em Conectar no compute principal para abrir a caixa de diálogo com os detalhes da conexão. O dropdown "Compute " lista as duas opções de conexão para o seu endpoint de alta disponibilidade.
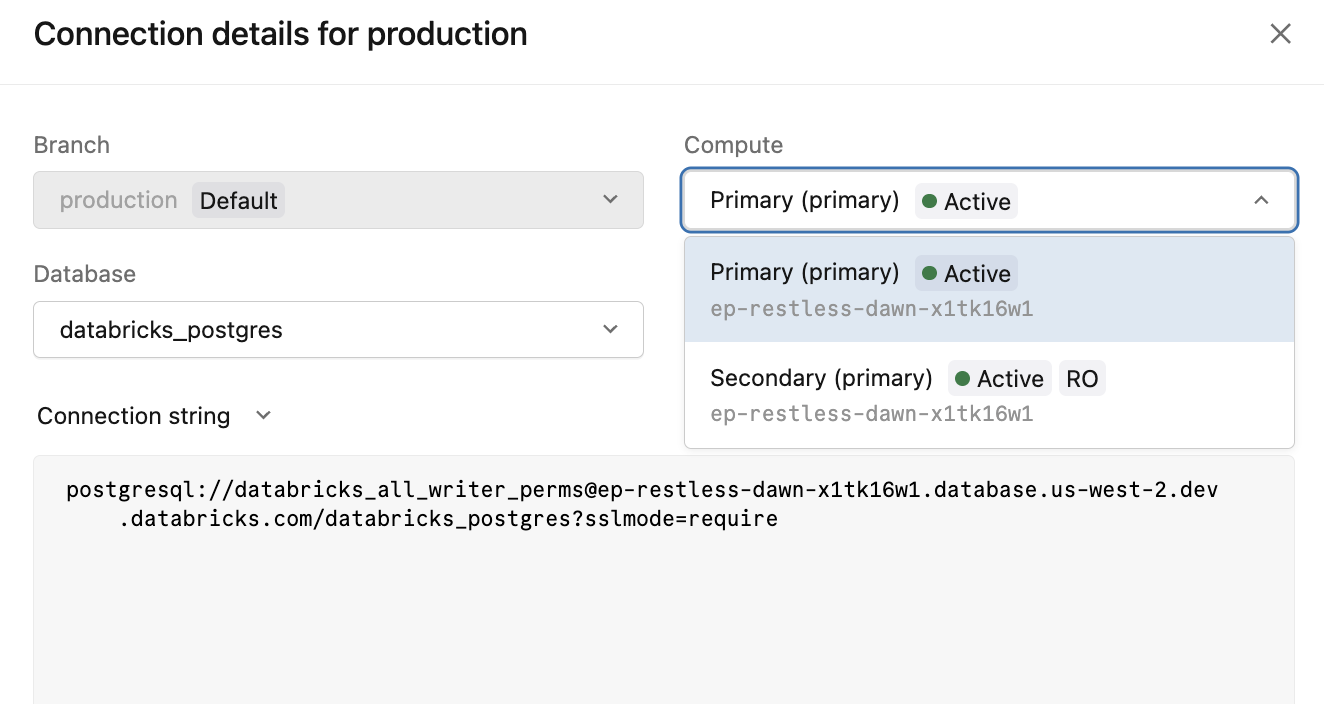
opção de cálculo | Cadeias de conexão | Usar para |
|---|---|---|
|
| Todas as conexões de escrita e leitura/escrita |
|
| Descarregamento de leitura para instâncias compute secundárias |
As cadeias de conexão -ro só estão disponíveis quando a opção Permitir acesso a instâncias compute somente leitura está habilitada.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-endpoint"
)
print(f"Read/write host: {endpoint.status.hosts.host}")
print(f"Read-only host: {endpoint.status.hosts.read_only_host}")
databricks postgres get-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
-o json | jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
curl -X GET "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
| jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
Para obter uma referência completa sobre cadeias de conexão, consulte stringsde conexão.
Recursos adicionais
- Alta disponibilidade — conceitos, comportamento em caso de falha e melhores práticas
- Réplicas de leitura — réplicas de leitura independentes para capacidade de leitura adicional sem alta disponibilidade.
- stringsde conexão