projetos
Um projeto é o contêiner de nível superior para seu recurso do Lakebase, incluindo ramificações, computação, bancos de dados e funções. Esta página explica como criar projetos, entender sua estrutura, configurar as definições e gerenciar seu ciclo de vida.
Se você é novo no Lakebase, comece com "Obter início" para criar seu primeiro projeto.
Compreendendo projetos
Estrutura do projeto
Compreender a estrutura do projeto Lakebase ajuda você a organizar e gerenciar seus recursos de forma eficaz. Um projeto é o contêiner de nível superior para seus bancos de dados, ramificações, computação e recursos relacionados. Cada projeto inclui configurações para valores padrão compute , janelas de restauração e atualizações que se aplicam a todas as ramificações dentro do projeto.
No nível mais alto, um projeto contém uma ou mais ramificações. Dentro de um projeto, você pode criar ramificações para diferentes ambientes, como desenvolvimento, teste, homologação e produção. Cada filial contém seus próprios recursos computacionais, funções e bancos de dados.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Galhos
Os dados residem nas filiais. Cada projeto Lakebase é criado com um ramo raiz chamado production, que não pode ser excluído. Embora seja possível criar ramificações adicionais e designar uma ramificação diferente como ramificação default , a ramificação raiz não pode ser excluída.
Você pode criar ramificações filhas a partir de qualquer ramificação do seu projeto. Ao criar uma ramificação filha, ela herda todos os bancos de dados, funções e dados da ramificação pai no momento da criação. Alterações subsequentes na ramificação principal não se propagam automaticamente para a ramificação filha, permitindo desenvolvimento, teste ou experimentação isolados.
Cada ramificação pode conter vários bancos de dados e funções. Saiba mais: gerenciar agências
calcular
Um compute é um recurso computacional virtualizado que inclui vCPU e memória para executar o Postgres. Ao criar um projeto, um compute primário de leitura/gravação é criado para o branch default do projeto. Cada filial possui um único compute primário de leitura/gravação. Para se conectar a um banco de dados que reside em uma filial, você deve se conectar através do compute leitura/gravação associado à filial.
Além do compute primário de leitura/gravação, você pode adicionar uma ou mais réplicas de leitura (somente leitura) a qualquer ramificação. As réplicas de leitura permitem descarregar cargas de trabalho somente leitura do seu compute principal para casos de uso como escalonamento horizontal de leitura, consultas analíticas e de geração de relatórios, e acesso somente leitura para usuários ou aplicativos. Saiba mais: gerenciar computação, ler réplicas
Funções
Os papéis são papéis do Postgres. É necessário ter uma função para criar e acessar um banco de dados. Uma função pertence a uma filial. Ao criar um projeto, uma função do Postgres é criada automaticamente para sua identidade Databricks (por exemplo, user@databricks.com), que é o proprietário do banco de dados default databricks_postgres . Qualquer função criada na interface do usuário do Lakebase é criada com privilégios databricks_superuser . Existe um limite de 500 funções por filial. Saiba mais: funções gerenciais
Bancos de dados
Um banco de dados é um contêiner para objetos SQL , como esquemas, tabelas, visualizações, funções e índices. No Lakebase, um banco de dados pertence a uma ramificação. O branch default do seu projeto é criado com um banco de dados chamado databricks_postgres. Existe um limite de 500 bases de dados por filial. Saiba mais: gerenciamento de bancos de dados
Esquemas
Todos os bancos de dados no Lakebase são criados com um esquema public , que é o comportamento default para qualquer instância padrão do Postgres. Os objetos SQL são criados no esquema public por default.
Limites do projeto
O Lakebase Postgres impõe os seguintes limites aos projetos:
Recursos | Limite |
|---|---|
Número máximo de operações de computação ativas simultaneamente | 20 |
Número máximo de réplicas de leitura por ramificação | 6 |
Número máximo de filiais por projeto | 500 |
Número máximo de funções do Postgres por branch | 500 |
Número máximo de bancos de dados Postgres por filial | 500 |
Cota de armazenamento do banco de dados (por filial) | 16 TB |
Número máximo de projetos por workspace | 1000 |
Número máximo de ramos protegidos | 1 |
Número máximo de ramos da raiz | 3 |
Número máximo de ramificações não arquivadas | 10 |
Número máximo de instantâneos manuais | 10 |
Período máximo de retenção da história | 30 dias |
Escalada mínima para tempo zero | 60 segundos |
Escalada máxima para tempo zero | 7 dias |
limite compute ativa simultaneamente
O limite de compute ativa simultaneamente restringe a quantidade de cálculos que podem ser executados ao mesmo tempo para evitar o esgotamento de recursos. Esse limite protege contra picos acidentais de recursos, como iniciar muitos pontos de extremidade compute simultaneamente. O limite default é de 20 processos computacionais ativos simultaneamente por projeto.
Importante: O branch default está isento desse limite, garantindo que permaneça disponível em todos os momentos.
Ao ultrapassar o limite, os recursos computacionais adicionais que excedem esse limite permanecem suspensos e você verá um erro ao tentar se conectar a eles. Para resolver isso:
- Suspenda outros processos de computação ativos e tente novamente.
- Se você se deparar com esse erro frequentemente, entre em contato com o Suporte da Databricks para solicitar um aumento de limite.
Com o recurso "Escalar para zero" ativado, o processamento computacional é suspenso automaticamente após um período de inatividade, ajudando você a se manter dentro do limite de compute ativo simultaneamente.
cota de armazenamento do banco de dados
Cada ramificação tem uma cota de 16 TB de armazenamento de banco de dados. Esta é uma cota operacional, e não um limite arquitetônico, porque os dados residem no armazenamento de objetos em cloud em vez de em um disco local de provisionamento.
Quando um banco de dados atinge sua cota, o desempenho de gravação diminui, mas você ainda pode descartar ou excluir dados para recuperar espaço. Entre em contato com o suporte da Databricks se precisar de uma cota maior.
Apenas os seus dados reais (tabelas e índices, conforme relatado pelo Postgres) são contabilizados na cota. A história preservada para restauração pontual não funciona.
Disponibilidade regional
Regiões suportadas:
us-east-1(Leste dos EUA - Norte da Virgínia)us-east-2(Leste dos EUA - Ohio)us-west-2(Oeste dos EUA - Oregon)ca-central-1(Canadá - Central)sa-east-1(América do Sul - São Paulo)eu-central-1(Europa - Frankfurt)eu-west-1(Europa - Irlanda)eu-west-2(Europa - Londres)ap-south-1(Ásia-Pacífico - Mumbai)ap-southeast-1(Ásia-Pacífico - Singapura)ap-southeast-2(Ásia-Pacífico - Sydney)ap-northeast-1(Ásia-Pacífico - Tóquio)
Seu projeto Lakebase foi criado na sua região workspace Databricks .
Suporte à versão do Postgres
O Lakebase Postgres autoscale oferece suporte ao Postgres 16, Postgres 17 e Postgres 18. O Postgres 17 é a versão default. Para usar o Postgres 18, selecione-o ao criar um novo projeto.
Criar e gerenciar projetos
Criar um projeto
Você pode criar vários projetos no Lakebase Postgres para manter aplicativos ou clientes totalmente isolados, garantindo uma separação clara de dados e recursos.
Para criar um projeto:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Clique no seletor de aplicativos no canto superior direito para abrir o aplicativo Lakebase.
- Clique em Novo projeto .
- Configure as definições do seu projeto:
- Nome de exibição : Insira um nome para o seu projeto. Você pode usar qualquer caractere, incluindo espaços e caracteres especiais. Os padrões de nomenclatura comuns incluem nomear de acordo com o aplicativo (por exemplo,
My Analytics App) ou o cliente ou tenant que o projeto atende (por exemplo,Acme Corp DB). O nome do recurso é derivado automaticamente do seu nome de exibição e é usado para identificar o projeto em chamadas de API e SDK. A caixa de diálogo mostra o nome do recurso resultante (por exemplo,projects/my-analytics-app) para que você possa verificá-lo antes de criar o projeto. - Versão do Postgres : Selecione a versão do Postgres que deseja usar.
- Política de uso sem servidor (opcional): Selecione uma política de uso serverless para atribuir custos compute serverless a uma política específica. Consulte as políticas de utilização de arquitetura sem servidor.
- Nome de exibição : Insira um nome para o seu projeto. Você pode usar qualquer caractere, incluindo espaços e caracteres especiais. Os padrões de nomenclatura comuns incluem nomear de acordo com o aplicativo (por exemplo,
A caixa de diálogo Criar projeto exibe as opções de configuração do projeto.
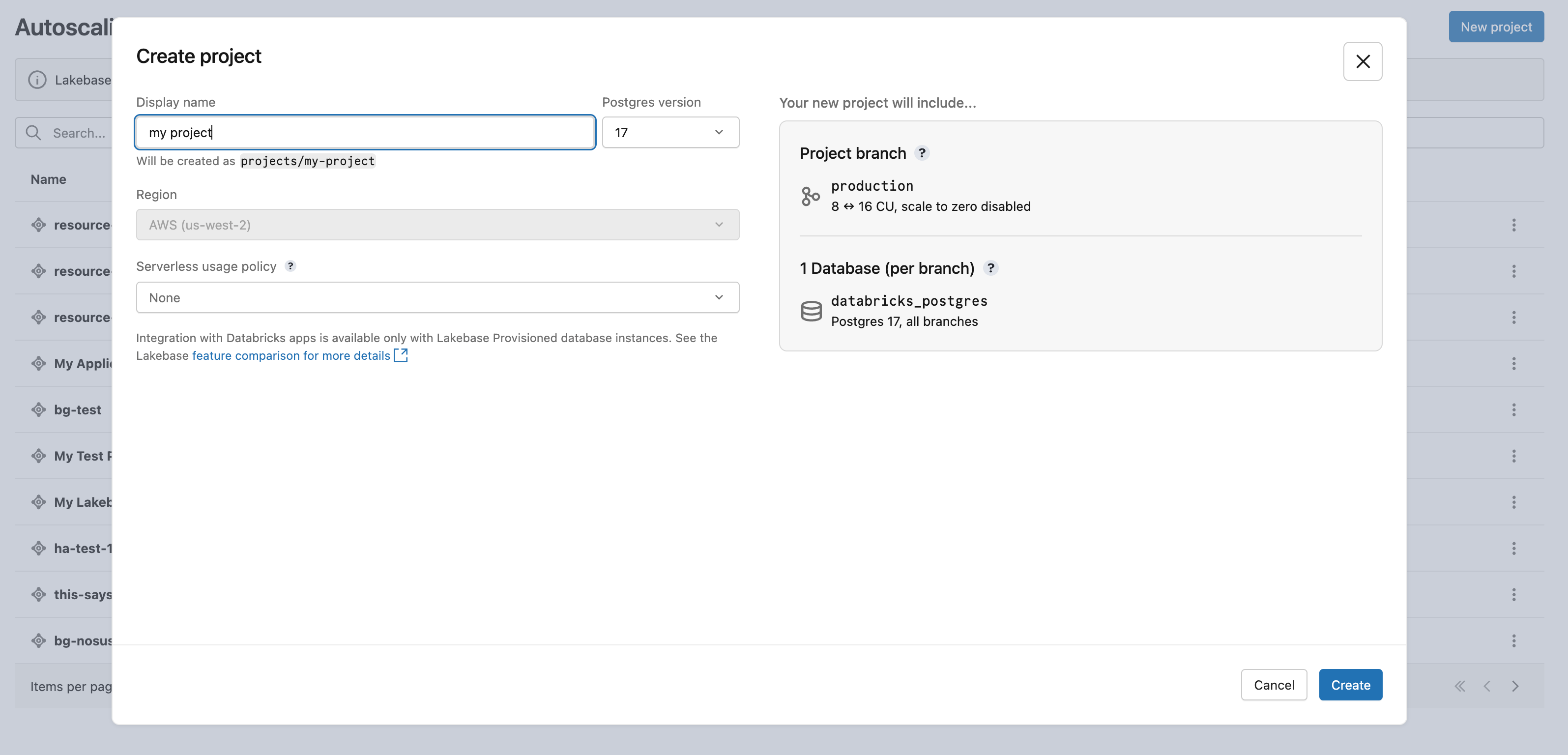
A região do seu projeto Lakebase está definida como a região do seu workspace Databricks e não pode ser modificada.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
Crie um projeto com um ID de projeto personalizado. O project_id é especificado como um parâmetro de consulta e torna-se parte do nome do recurso do projeto (por exemplo, projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
Esta é uma operação de longa duração. A resposta inclui um nome de operação que você pode usar para verificar o status. A operação geralmente é concluída em segundos.
O parâmetro project_id é obrigatório.
Se você estiver criando um projeto com o mesmo ID de um projeto excluído recentemente, observe que os IDs de projetos excluídos são reservados por 7 dias. Para reutilizar o ID imediatamente, exclua permanentemente o projeto original primeiro.
Um novo projeto inclui o seguinte recurso por default:
-
Um único ramo
production(o ramo default ) -
Um único compute primário de leitura e gravação associado à ramificação com as seguintes configurações default :
Ramo
Unidades de computação (UC)
HA
Dimensionamento automático
escalar para zero
production8 - 16 CU
Ao criar um projeto, a ramificação
productioné criada com um compute que tem o recurso de escalação para zero ativado por default , com um tempo limite de inatividade de 24 horas. Você pode ajustar o tempo limite ou desativar a escalação para zero para este compute , se necessário. -
Um banco de dados Postgres (chamado
databricks_postgres) -
Uma função do Postgres para sua identidade do Databricks (por exemplo,
user@databricks.com)
Para alterar as configurações compute de um projeto existente, consulte Configurar configurações do projeto. Para modificar as configurações compute default para novos projetos, consulte "Configurações de computação padrão" em "Configurar configurações do projeto".
Obtenha detalhes do projeto
Obtenha detalhes de um projeto específico.
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Clique no seletor de aplicativos no canto superior direito para abrir o aplicativo Lakebase.
- Selecione o seu projeto na lista de projetos para view os detalhes.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
# Get project details
databricks postgres get-project projects/my-project
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
A resposta inclui:
name: Nome do recurso (projects/my-project)statusConfiguração do projeto e estado atual (nome de exibição, versão do pg, etc.)
Nota: O campo spec não é preenchido para operações GET. Todas as propriedades do recurso são retornadas no campo status .
Lista de projetos
Liste todos os projetos em seu workspace.
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Clique no seletor de aplicativos no canto superior direito para abrir o aplicativo Lakebase.
- A lista de projetos exibe todos os projetos aos quais você tem acesso.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
# List all projects
databricks postgres list-projects
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Formato da resposta:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
Configurar as definições do projeto
Após criar um projeto, você pode modificar várias configurações no painel de controle do projeto, acessando Configurações :
Configurações gerais
A página de configurações gerais exibe os seguintes campos:
- Nome de exibição : O nome de exibição editável para o seu projeto.
- Nome do recurso : Somente leitura. O caminho completo do recurso para o seu projeto (formato:
projects/{project_id}). Utilize esse valor em chamadas de API e SDK para identificar o projeto. - UID : Somente leitura. O identificador único gerado pelo sistema para o seu projeto.
- Política de uso sem servidor : Associe uma política de uso serverless ao seu projeto para atribuir os custos compute serverless a uma política específica. Consulte as políticas de utilização de arquitetura sem servidor.
- tagspersonalizadas : Adicione tags key-valor ao seu projeto. As tags são registradas nos registros de uso faturável da sua account (
system.billing.usage) e podem ser usadas para rastrear custos por equipe, projeto ou centro de custo. Consulte tagspersonalizadas. Ao atualizar tags personalizadas usando a API ou a CLI, a nova lista substitui todas as tags existentes.
- UI
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
São operações de longa duração. A resposta inclui um nome de operação que você pode usar para verificar o status.
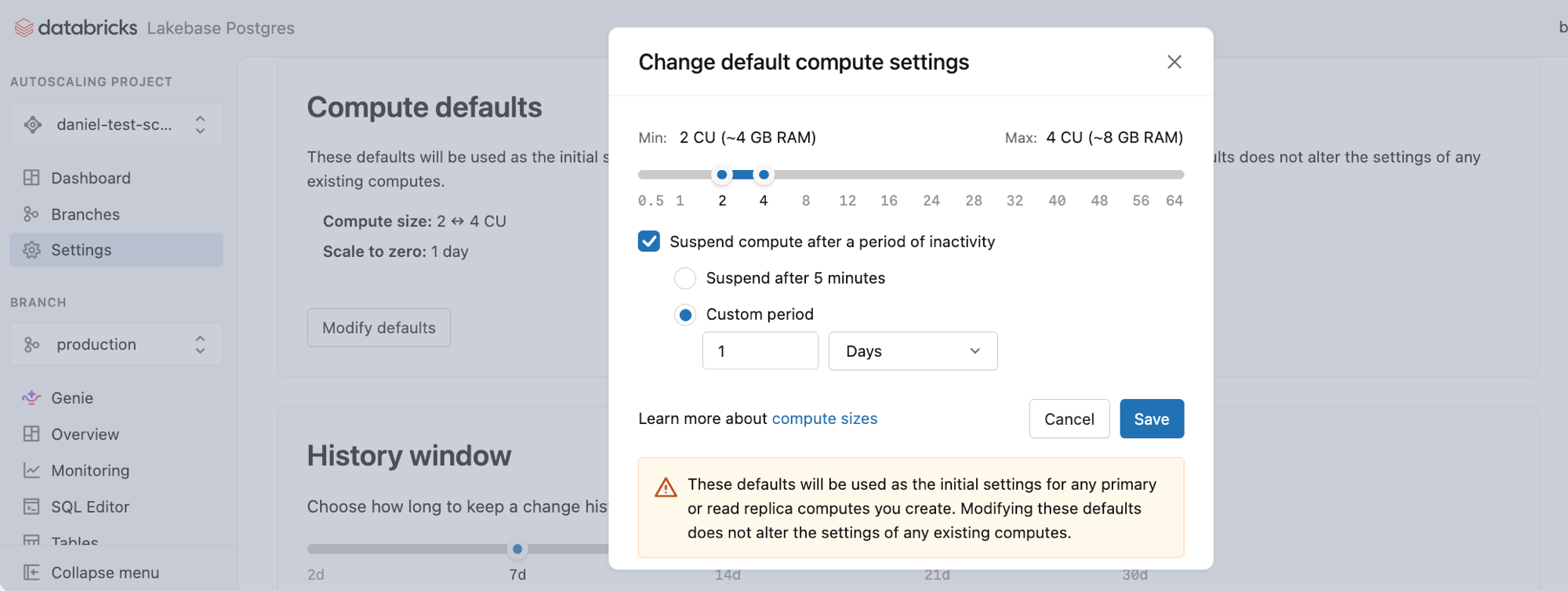
calcular padrão
Essas configurações padrão são usadas como configurações iniciais para qualquer computação primária ou réplica de leitura que você criar. Modificar esses valores padrão não altera as configurações de nenhum computador existente.
valores padrão:
- tamanho do cálculo: 2 ↔ 4 CU (intervalo de escala automática; ~4–8 GB de RAM)
- Escalar para zero: Ativado por padrão. Suspender compute após um período de inatividade está marcado, com a opção Suspender após 24 horas selecionada.
Clique em Modificar padrão para abrir a caixa de diálogo e alterar esses valores.
Para modificar as configurações de um compute existente, consulte gerenciar compute.
Lakebase Postgres suporta tamanhos de compute de 0,5 CU a 112 CU. O dimensionamento automático está disponível para compute de até 64 CU (0,5, depois incrementos inteiros: 1, 2, 3...64). Maiores computes de tamanho fixo estão disponíveis até 112 CU. Cada Unidade de Capacidade (UC) fornece 2 GB de RAM.
Provisionamento Lakebase vs escalonamento automático : No provisionamento Lakebase, cada unidade de computação alocou aproximadamente 16 GB de RAM. No Lakebase com escalonamento automático, cada Unidade de Computação (CU) aloca 2 GB de RAM. Essa mudança proporciona opções de dimensionamento mais detalhadas e maior controle de custos.
Tamanhos representativos:
Unidades de cálculo | BATER |
|---|---|
0,5 CU | 1 GB |
1 CU | 2 GB |
4 CU | 8 GB |
8 CU | 16 GB |
16 CU | 32 GB |
32 CU | 64 GB |
64 CU | 128 GB |
112 CU | 224 GB |
- Para ativar o dimensionamento automático, defina um intervalo de tamanho compute usando o controle deslizante. O dimensionamento automático ajusta dinamicamente os recursos compute com base na demanda da carga de trabalho. Saiba mais: autodimensionamento
- Ajuste a configuração "escala para zero" para aumentar ou diminuir o tempo de inatividade do compute antes de compute suspensão (de 60 segundos até 7 dias quando ativada). Você também pode desativar o recurso de escalação para zero para um compute sempre ativo. Saiba mais: Reduzir a escala a zero
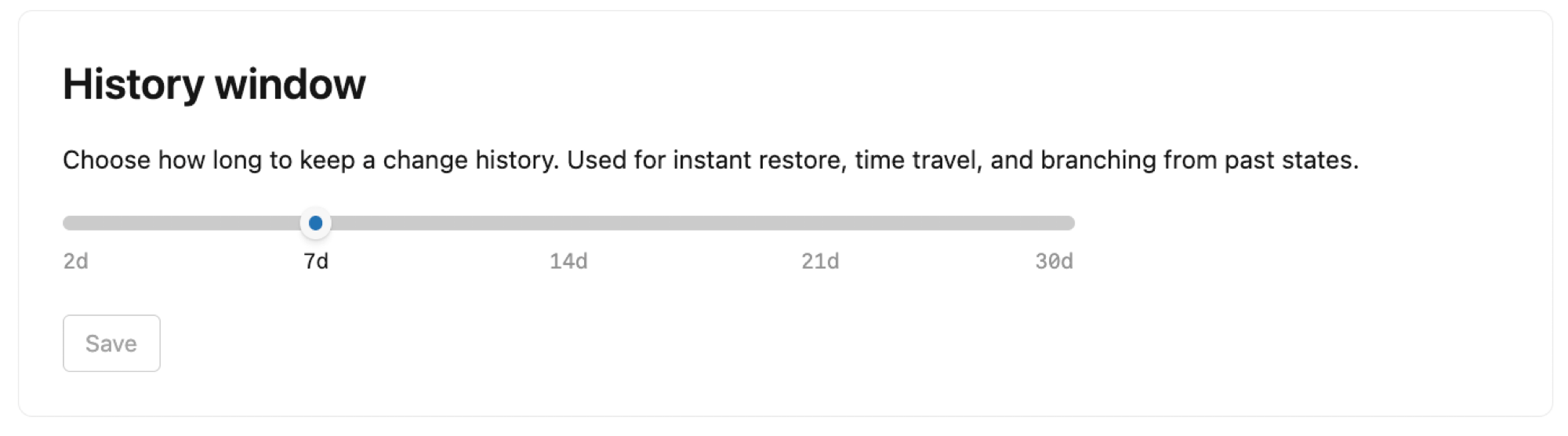
janela de teste
Configure a duração da janela do jogo para o seu projeto. Por default, Lakebase mantém um histórico de alterações para os branches raiz do seu projeto, permitindo a restauração pontual para recuperar dados perdidos, a consulta de dados em um determinado momento para investigar problemas de dados e a ramificação a partir de estados anteriores para o fluxo de trabalho de desenvolvimento.
Você pode definir a duração da história de 2 a 30 dias, sendo 7 dias o default . Observe que:
- Expandir a janela do jogo aumenta seu espaço de armazenamento.
- A configuração da janela de configuração afeta todas as ramificações do seu projeto.
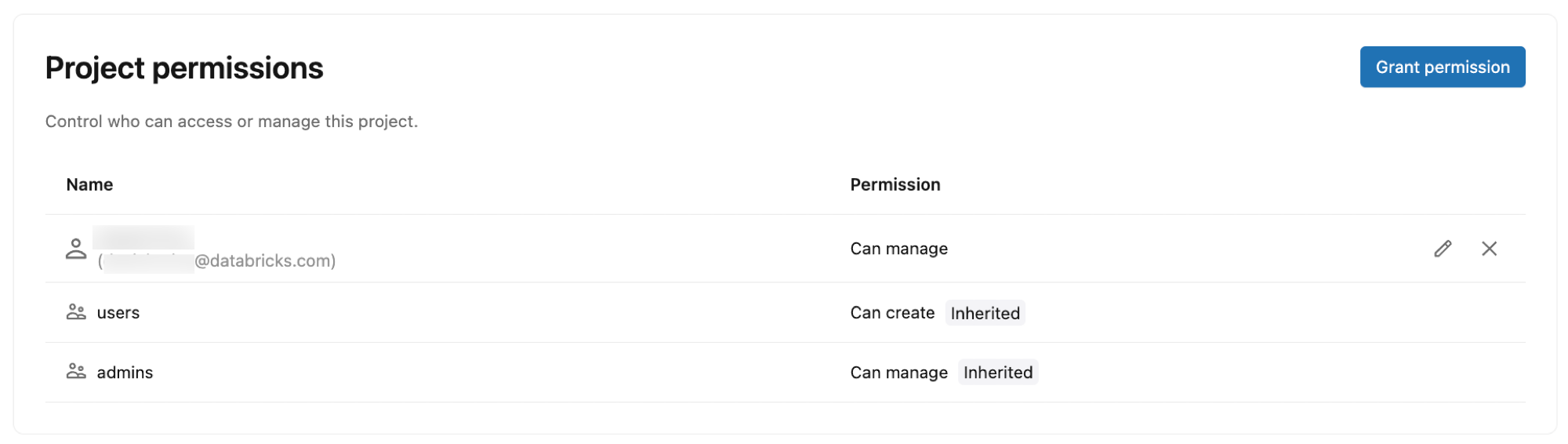
Permissões do projeto
Controle quem pode acessar e gerenciar seu projeto Lakebase concedendo permissões a identidades, grupos e entidades de serviço Databricks . As permissões do projeto determinam quais ações os usuários podem executar dentro do projeto, como criar ramificações, gerenciar recursos computacionais e visualizar detalhes da conexão.
Tipos de permissão:
- PODE CRIAR : visualizar e criar recursos de projeto
- PODE SER USADO : visualizar e usar recursos do projeto (listar, view, conectar e executar determinadas operações em branches) sem criar ou excluir projetos ou branches.
- CAN MANAGE : Controle total sobre a configuração do projeto e os recursos.
permissões padrão:
Ao criar um projeto, as seguintes permissões são atribuídas automaticamente:
- Proprietário do projeto (o usuário que criou o projeto): CAN MANAGE (controle total)
- Usuários do espaço de trabalho : PODEM CRIAR (podem view e criar projetos)
- Administradores do espaço de trabalho : CAN MANAGE (controle total)
Para conceder acesso a outros usuários, consulte Gerenciar permissões do projeto.
As permissões do projeto e o acesso ao banco de dados são separados.
As permissões do projeto controlam as ações da plataforma Lakebase, enquanto o acesso ao banco de dados é controlado pelas funções do Postgres e suas respectivas permissões. Consulte Criar funções do Postgres e gerenciar permissões de banco de dados.
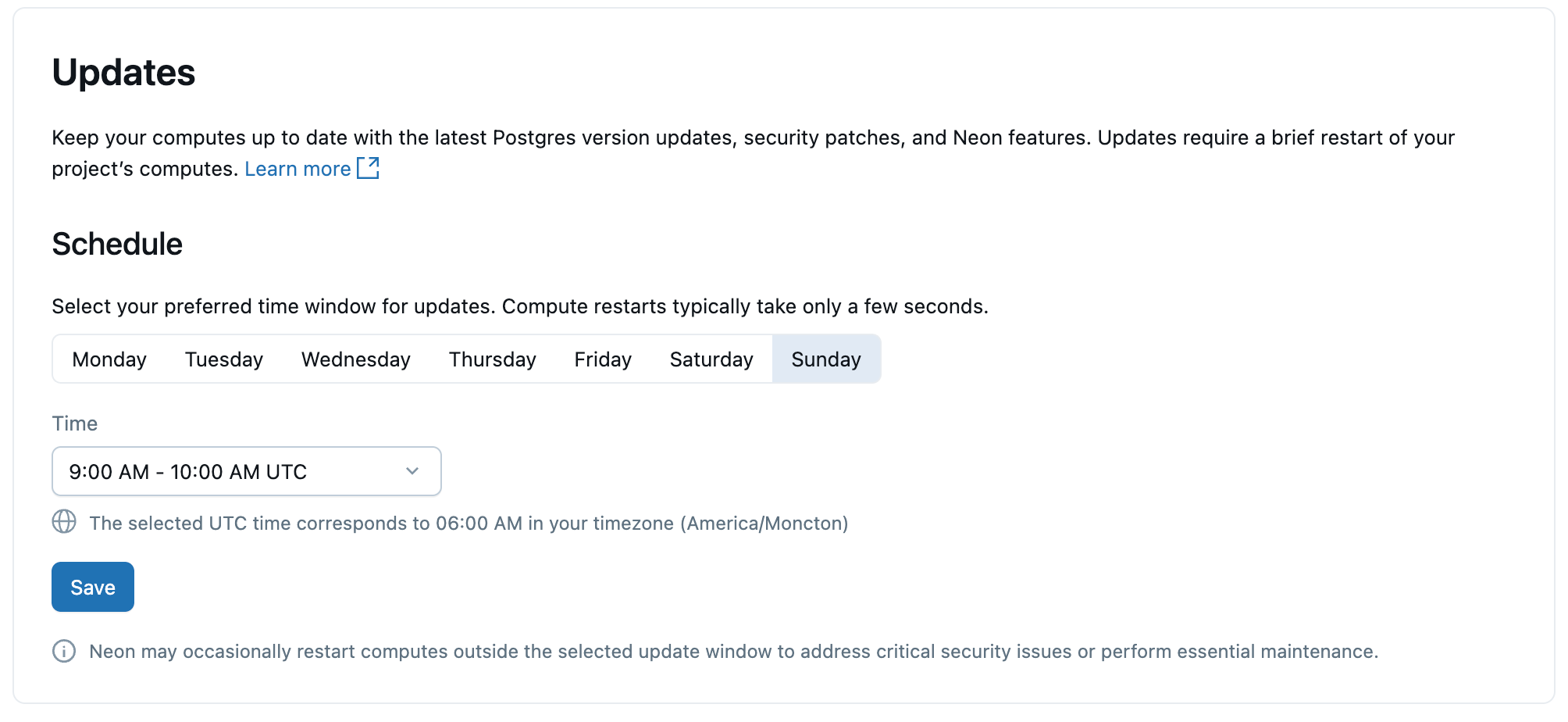
Atualizações
Para manter suas instâncias de computação e Postgres do Lakebase atualizadas, o Lakebase aplica automaticamente atualizações agendadas, que incluem atualizações de versão secundária do Postgres, patches de segurança e recursos da plataforma. As atualizações são aplicadas aos recursos computacionais do seu projeto e exigem uma breve reinicialização compute , que leva alguns segundos.
As atualizações são aplicadas automaticamente, mas você pode definir um dia e horário preferenciais para que elas sejam realizadas. As reinicializações ocorrem dentro do intervalo de tempo selecionado.
Para obter informações detalhadas sobre atualizações, consulte gerenciar atualizações.
Excluir um projeto
Ao excluir um projeto, ele entra em um estado de exclusão temporária por default e é mantido por 7 dias antes de ser excluído permanentemente. Durante esse período, você pode recuperar o projeto e restaurar todos os seus dados. Consulte Recuperar um projeto excluído. Para ignorar o período de retenção e remover o projeto imediatamente, consulte Excluir um projeto permanentemente.
Enquanto um projeto estiver excluído temporariamente, as tentativas de conexão ou de recuperação de credenciais do banco de dados retornarão erros genéricos (como "endpoint não encontrado" ou "conexão recusada") em vez de um erro indicando que o projeto foi excluído. Se você encontrar esses erros inesperadamente, verifique se o projeto foi excluído temporariamente listando os projetos com show_deleted=true. Consulte Encontrar projetos excluídos temporariamente.
Antes de excluir
A Databricks recomenda excluir todos os catálogos do Unity Catalog e as tabelas sincronizadas associadas antes de excluir o projeto. Caso contrário, tentar view catálogos ou executar consultas SQL que os referenciem resultará em erros.
Se você não for o proprietário das tabelas ou catálogos, deverá reatribuir a propriedade a si mesmo antes de excluí-los.
Somente usuários com permissão CAN MANAGE no projeto Lakebase podem excluí-lo. Consulte as ACLs do projeto e gerencie as permissões do projeto para obter detalhes.
Excluir um projeto
Para excluir um projeto:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Acesse as Configurações do seu projeto no aplicativo Lakebase.
- Na seção Excluir projeto , clique em Excluir e digite o nome do projeto para confirmar a exclusão.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name()}")
Esta é uma operação de longa duração. O projeto e todos os seus recursos (branches, endpoints, bancos de dados, funções, dados) serão excluídos.
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Esta é uma operação de longa duração. O projeto e todos os seus recursos (branches, endpoints, bancos de dados, funções, dados) serão excluídos.
# Delete a project
databricks postgres delete-project projects/my-project
Este comando retorna imediatamente. O projeto e todos os seus recursos serão eliminados.
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Esta é uma operação de longa duração. A resposta inclui um nome de operação que você pode usar para verificar o status da exclusão.
Excluir um projeto permanentemente
Para excluir permanentemente um projeto do Lakebase imediatamente, sem esperar que o período de retenção de exclusão temporária de 7 dias expire:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_project(name="projects/my-project", purge=True)
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.DeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteProject(
new DeleteProjectRequest()
.setName("projects/my-project")
.setPurge(true)
).waitForCompletion();
databricks postgres delete-project projects/my-project --purge
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project?purge=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Recuperar um projeto excluído
Ao excluir um projeto do Lakebase, ele entra em um estado de exclusão temporária e é retido por 7 dias antes de ser excluído permanentemente. Durante esse período, você pode recuperar o projeto e restaurar todos os seus dados.
O que foi restaurado?
A recuperação de um projeto excluído logicamente restaura o seguinte:
- Todas as filiais e seus dados
- Todos os bancos de dados e funções do Postgres
- Todos os endpoints compute e suas configurações
- Configurações do projeto, incluindo compute padrão, restauração das configurações da janela e atualização de preferências.
- Permissões do projeto
Alguns recursos podem exigir reconfiguração após a recuperação. Contate o suporte da Databricks se encontrar problemas após recuperar um projeto.
Encontre projetos excluídos temporariamente
Para listar todos os projetos, incluindo aqueles excluídos temporariamente, use o parâmetro show_deleted . Isso é útil para encontrar o nome do recurso de um projeto que você deseja recuperar.
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for project in w.postgres.list_projects(show_deleted=True):
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
if project.delete_time:
print(f" Deleted: {project.delete_time}")
print(f" Purge time: {project.purge_time}")
databricks postgres list-projects --show-deleted
curl -X GET "$WORKSPACE/api/2.0/postgres/projects?show_deleted=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Recuperar um projeto
Para recuperar um projeto Lakebase excluído temporariamente:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.undelete_project(name="projects/my-project")
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.UndeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().undeleteProject(
new UndeleteProjectRequest().setName("projects/my-project")
).waitForCompletion();
databricks postgres undelete-project projects/my-project
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/undelete" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq