ger réplicas de leitura
Este guia orienta você na criação e gerenciamento de réplicas de leitura para seus projetos. As réplicas de leitura segregam o trabalho somente leitura das operações do seu banco de dados de produção, com aplicações que variam desde escalonamento horizontal até cargas de trabalho analíticas. Para obter informações detalhadas sobre a arquitetura de réplicas de leitura e casos de uso, consulte Réplicas de leitura.
Entendendo as réplicas de leitura
As réplicas de leitura permitem criar um ou mais servidores de computação somente leitura para qualquer ramificação do seu projeto. Você pode configurar o tamanho compute alocado para cada réplica, e tanto o dimensionamento automático quanto a redução gradual de recursos (escala-to-zero) são suportados, proporcionando controle sobre o uso compute da réplica de leitura.
Os passos para criar, configurar e conectar-se a uma réplica de leitura são os mesmos, independentemente do seu caso de uso.
Na API e nos SDKs, uma réplica de leitura é um endpoint com seu endpoint_type definido como ENDPOINT_TYPE_READ_ONLY.
Apoio regional
O Lakebase permite a criação de réplicas de leitura na mesma região do seu projeto. Réplicas de leitura entre regiões não são suportadas.
sincronização de configurações de cálculo
Para réplicas de leitura do Lakebase, certas configurações do Postgres não devem ter valores inferiores à compute de leitura e gravação do seu dispositivo primário. Por esse motivo, as seguintes configurações no servidor de computação de réplica de leitura são sincronizadas com as configurações no compute primário de leitura e gravação quando o compute de réplica de leitura é iniciado:
max_connectionsmax_prepared_transactionsmax_locks_per_transactionmax_wal_sendersmax_worker_processes
Nenhuma ação do usuário é necessária. As configurações são sincronizadas automaticamente quando você cria uma réplica de leitura. No entanto, se você alterar a configuração de tamanho compute no servidor de compute primário de leitura e gravação, será necessário reiniciar o servidor de computação de réplica de leitura para garantir que as configurações permaneçam sincronizadas. Consulte Solucionar problemas de atraso de replicação para obter mais informações.
Criar e gerenciar réplicas de leitura
Limites
- Máximo de 6 réplicas de leitura por ramificação .
- As réplicas de leitura contam para o limite de 20 instâncias compute ativas simultaneamente em todo o projeto. Consulte os limites do projeto.
Pré-requisitos
- Um projeto da Lakebase. Consulte Criar um projeto.
Criar uma réplica de leitura
Para criar uma réplica de leitura:
- UI
- Python SDK
- Java SDK
- CLI
- curl
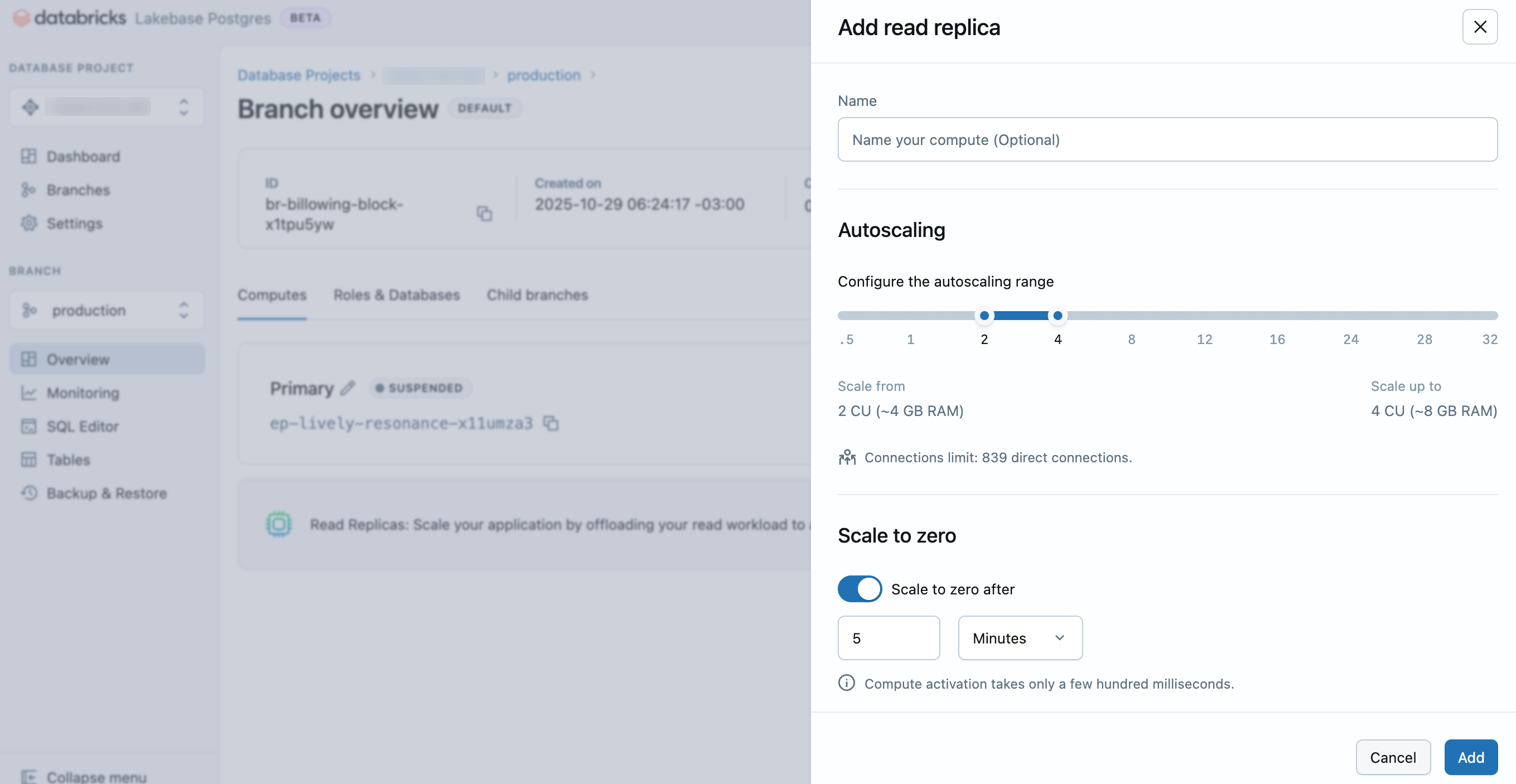
- No aplicativo Lakebase, navegue até seu projeto, branch e a tab de computação .
- Clique em Adicionar Réplica de Leitura .
- Insira um nome para sua réplica de leitura, configure as definições compute (intervalo de dimensionamento automático e comportamento de escalonamento para zero) e clique em Adicionar .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType
w = WorkspaceClient()
# Create read replica endpoint (READ_ONLY)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_ONLY,
autoscaling_limit_max_cu=2.0
)
endpoint = Endpoint(spec=endpoint_spec)
result = w.postgres.create_endpoint(
parent="projects/my-project/branches/production",
endpoint=endpoint,
endpoint_id="my-read-replica"
).wait()
print(f"Endpoint created: {result.name}")
print(f"Host: {result.status.hosts.host}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// Create read replica endpoint (READ_ONLY)
EndpointSpec endpointSpec = new EndpointSpec()
.setEndpointType(EndpointType.ENDPOINT_TYPE_READ_ONLY)
.setAutoscalingLimitMaxCu(2.0);
Endpoint endpoint = new Endpoint()
.setSpec(endpointSpec);
Endpoint result = w.postgres().createEndpoint(
new CreateEndpointRequest()
.setParent("projects/my-project/branches/production")
.setEndpoint(endpoint)
.setEndpointId("my-read-replica")
).waitForCompletion();
System.out.println("Endpoint created: " + result.getName());
System.out.println("Host: " + result.getStatus().getHosts().getHost());
# Create a read replica for a branch
databricks postgres create-endpoint projects/my-project/branches/production my-read-replica \
--json '{
"spec": {
"endpoint_type": "ENDPOINT_TYPE_READ_ONLY",
"autoscaling_limit_min_cu": 0.5,
"autoscaling_limit_max_cu": 4.0
}
}'
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints?endpoint_id=my-read-replica" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"endpoint_type": "ENDPOINT_TYPE_READ_ONLY",
"autoscaling_limit_min_cu": 0.5,
"autoscaling_limit_max_cu": 4.0
}
}' | jq
A configuração de tamanho compute determina a capacidade de processamento do seu banco de dados. Saiba mais: gerenciar computação
Sua réplica de leitura é provisionada em poucos segundos e aparece na tab de computação da branch.
ver ler réplicas
Para view as réplicas de leitura de uma ramificação, navegue até o seu projeto no aplicativo Lakebase, selecione uma ramificação na página Ramificações e view a tab Computação , onde todas as instâncias de computação das réplicas de leitura são listadas.
Conecte-se a uma réplica de leitura
A conexão com uma réplica de leitura segue o mesmo processo que a conexão com seu compute primário de leitura e gravação, exceto que você seleciona um compute de réplica de leitura ao obter suas informações de conexão.
Para obter informações de conexão para uma réplica de leitura:
- No aplicativo Lakebase, clique em Conectar no painel do seu projeto.
- Selecione a ramificação, o banco de dados, a função e o recurso compute da réplica de leitura na dropdown de computação e, em seguida, copie as cadeias de conexão fornecidas.
Você pode se conectar usando uma função OAuth do Postgres, da mesma forma que faria com seu compute principal de leitura e gravação.
Operações de escrita não são permitidas em conexões de réplica de leitura. A tentativa de executar operações de escrita resultará em um erro.
Para obter informações completas sobre métodos de autenticação e opções de conexão, consulte Conectar-se ao seu projeto.
Editar uma réplica de leitura
Você pode editar uma réplica de leitura para alterar o tamanho compute ou a configuração de escalonamento para zero.
Para editar uma réplica de leitura:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Acesse tab de computação da sua filial no aplicativo Lakebase.
- Localize a réplica de leitura, clique em Editar , atualize as configurações compute e clique em Salvar .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
# Update read replica size
endpoint_name = "projects/my-project/branches/production/endpoints/my-read-replica"
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_ONLY,
autoscaling_limit_min_cu=1.0,
autoscaling_limit_max_cu=8.0
)
endpoint = Endpoint(name=endpoint_name, spec=endpoint_spec)
update_mask = FieldMask(field_mask=[
"spec.autoscaling_limit_min_cu",
"spec.autoscaling_limit_max_cu"
])
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=endpoint,
update_mask=update_mask
).wait()
print(f"Updated read replica size: {result.status.autoscaling_limit_min_cu}-{result.status.autoscaling_limit_max_cu} CU")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
// Update read replica size
String endpointName = "projects/my-project/branches/production/endpoints/my-read-replica";
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMinCu(1.0)
.setAutoscalingLimitMaxCu(8.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_min_cu")
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
# Update a read replica's autoscaling settings
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-read-replica "spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
--json '{
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}'
# Update a read replica's autoscaling settings
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-read-replica?update_mask=spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-read-replica",
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}' | jq
Saiba mais: gerenciar computação
Excluir uma réplica de leitura
Excluir uma réplica de leitura é uma ação permanente. No entanto, você pode criar rapidamente uma nova réplica de leitura, caso precise.
Para excluir uma réplica de leitura:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Acesse tab de computação da sua filial no aplicativo Lakebase.
- Localize a réplica lida, clique em Editar , Excluir e confirme a exclusão.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete endpoint
w.postgres.delete_endpoint(
name="projects/my-project/branches/production/endpoints/my-read-replica"
).wait()
print("Endpoint deleted")
As operações de exclusão são assíncronas. O método .wait() bloqueia até que a exclusão seja concluída.
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete endpoint
w.postgres().deleteEndpoint(
"projects/my-project/branches/production/endpoints/my-read-replica"
);
System.out.println("Delete initiated");
# Delete a read replica
databricks postgres delete-endpoint projects/my-project/branches/production/endpoints/my-read-replica
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-read-replica" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Resposta:
{
"name": "projects/my-project/branches/production/endpoints/my-read-replica/operations/...",
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Solução de problemas de atraso na replicação
Se suas réplicas de leitura estiverem ficando para trás, siga estes passos do sistema operacional para diagnosticar e resolver o problema:
Verifique o alinhamento da configuração
Caso seja detectado atraso na replicação, verifique se as configurações de computação do servidor primário e da réplica de leitura estão alinhadas. Especificamente, confirme se os seguintes parâmetros correspondem entre o seu compute primário e compute da réplica de leitura:
max_connectionsmax_prepared_transactionsmax_locks_per_transactionmax_wal_sendersmax_worker_processes
Você pode executar a seguinte consulta tanto no seu compute primário de leitura e gravação compute de réplica de leitura usando o editor SQL do Lakebase ou um cliente SQL como psql:
SELECT name, setting
FROM pg_settings
WHERE name IN (
'max_connections',
'max_prepared_transactions',
'max_locks_per_transaction',
'max_wal_senders',
'max_worker_processes'
);
Compare os resultados de ambos os cálculos para identificar quaisquer configurações desalinhadas.
Reiniciar o cálculo da réplica de leitura
Se as configurações não estiverem alinhadas, reinicie o seu servidor de computação de réplica de leitura para atualizar automaticamente as configurações. Acesse tab de computação do seu branch, encontre a réplica de leitura e clique em Editar e, em seguida, em Reiniciar .
Ao aumentar o tamanho do seu compute primário de leitura e gravação, sempre reinicie as réplicas de leitura associadas para garantir que suas configurações permaneçam alinhadas.