Painel de métricas
O painel de métricas na UI do Lakebase fornece gráficos para monitoramento do sistema e métricas do banco de dados. Você pode acessar o painel de métricas na barra lateral do aplicativo Lakebase. As métricas observáveis incluem uso de RAM, uso de CPU, contagem de conexões, tamanho do banco de dados, impasses (deadlocks), operações em linhas, atrasos de replicação, desempenho do cache e tamanho do conjunto de trabalho.
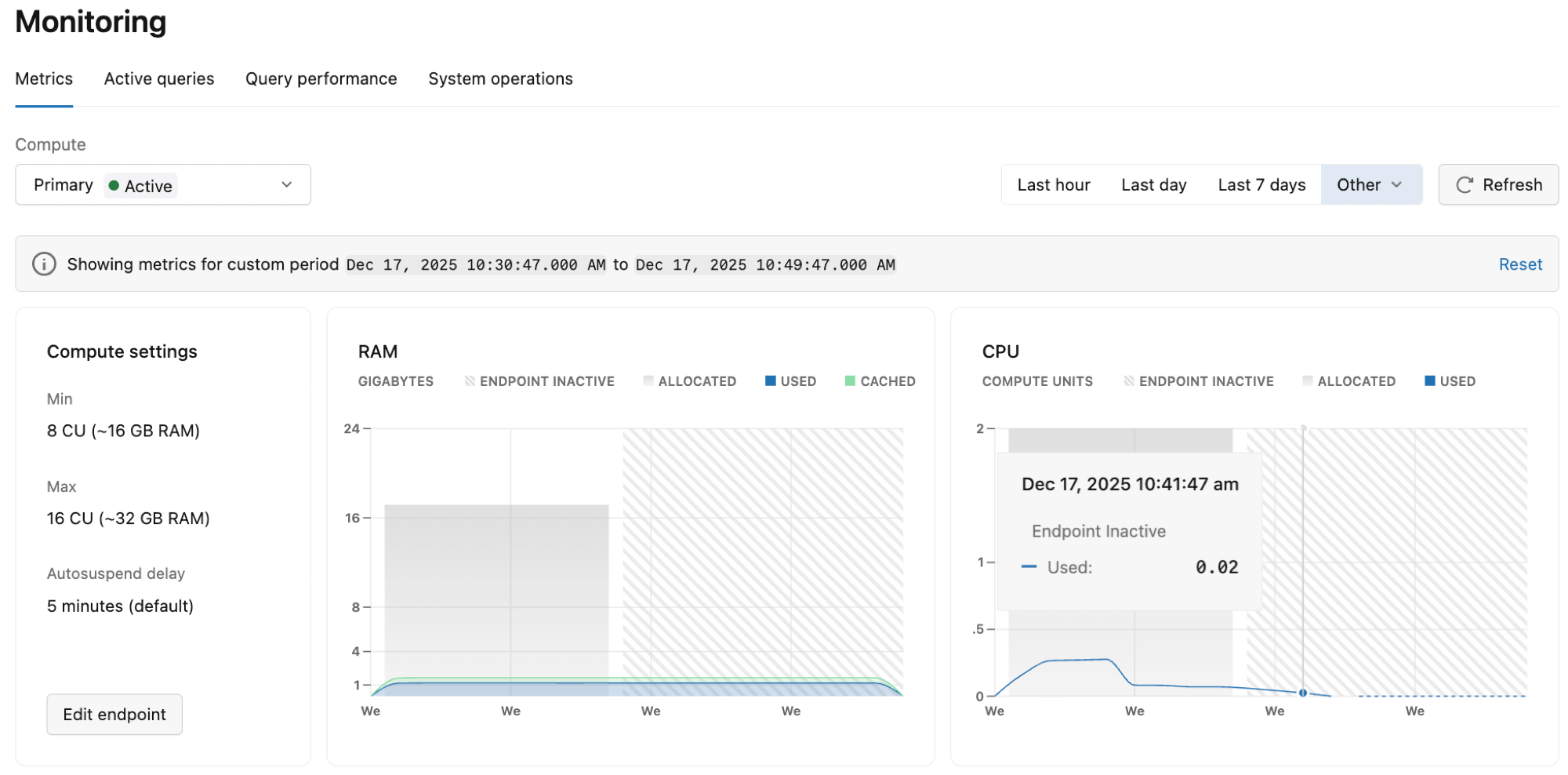
O painel exibe os modelos para o ramo e compute selecionados. Use os menus suspensos para view métricas de um ramo ou compute diferente. Você pode selecionar entre períodos de tempo predefinidos ( Última hora , Último dia , Últimos 7 dias ) ou escolher Outro para opções adicionais ( Últimas 3 horas , Últimas 6 horas , Últimas 12 horas , Últimos 2 dias ou Personalizado ). Use o botão de atualização para atualizar as métricas exibidas.
Entendendo computação inativa
Se os gráficos não exibirem nenhum dado, seu compute pode estar inativo devido à escala para zero.
Quando um compute está inativo, os valores de métricas caem para 0, pois é necessário um compute ativo para reportar dados. Os períodos de inatividade aparecem como um padrão de linhas diagonais no gráfico.
Se o gráfico não exibir dados, tente selecionar um período diferente ou retorne mais tarde após a coleta de mais dados de uso.
BATER
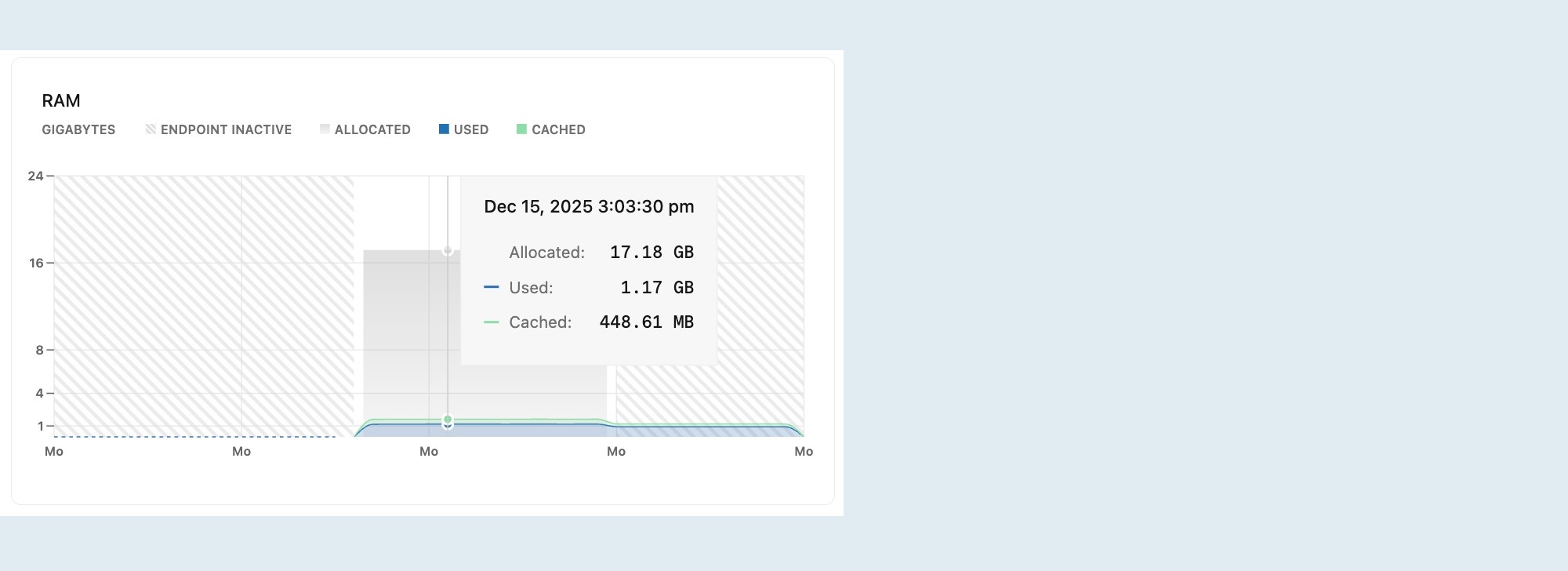
Este gráfico mostra a RAM alocada e sua utilização ao longo do tempo para o compute selecionado.
Inclui as seguintes métricas:
Alocado : A quantidade de RAM alocada.
A memória RAM é alocada de acordo com o tamanho do seu compute ou com a sua configuração de dimensionamento automático . Com o dimensionamento automático, a RAM alocada aumenta e diminui conforme a capacidade compute aumenta ou diminui em resposta à carga. Se a opção "escalar para zero" estiver ativada e seu compute entrar em estado parado após um período de inatividade, a RAM alocada cairá para 0.
Utilizada : A quantidade de RAM utilizada.
O gráfico graficar uma linha mostrando o uso de RAM. Se a conexão atingir regularmente a quantidade máxima de RAM alocada, considere aumentar o tamanho do seu poder compute . Para opções de tamanho compute , consulte dimensionamento de computação.
Em cache : A quantidade de dados armazenados em cache na memória por consultas e operações anteriores.
CPU
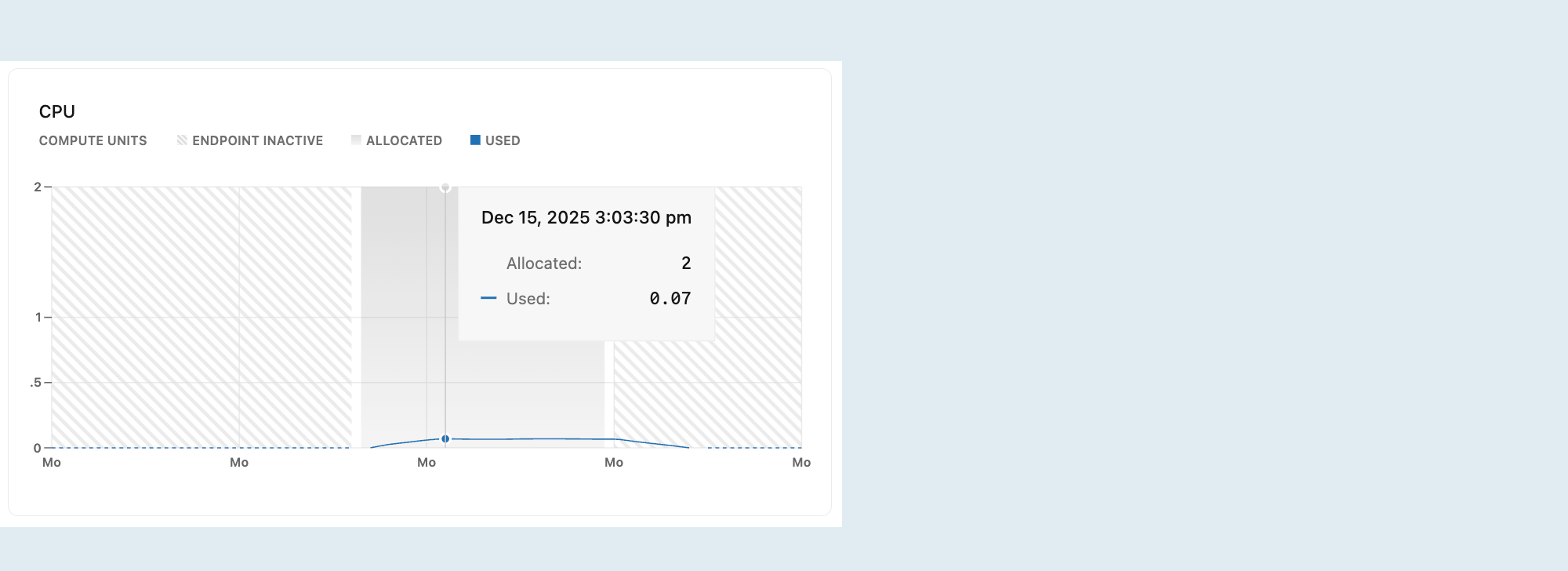
Este gráfico mostra a CPU alocada e sua utilização ao longo do tempo para o compute selecionado.
Alocado : A quantidade de CPU alocada.
A CPU é alocada de acordo com o tamanho do seu compute ou com a sua configuração de escalonamento automático . Com o dimensionamento automático, a CPU alocada aumenta e diminui conforme sua capacidade compute aumenta ou diminui em resposta à carga. Se a opção "escalar para zero" estiver ativada e seu compute entrar em estado "parado" após um período de inatividade, a CPU alocada cairá para 0.
Utilizado : A quantidade de CPU utilizada, em Unidades de Computação (UC).
Se a linha plotada atingir regularmente o limite máximo de CPU alocado, considere aumentar o tamanho do seu poder compute . Para opções de tamanho compute , consulte dimensionamento de computação.
Contagem de conexões
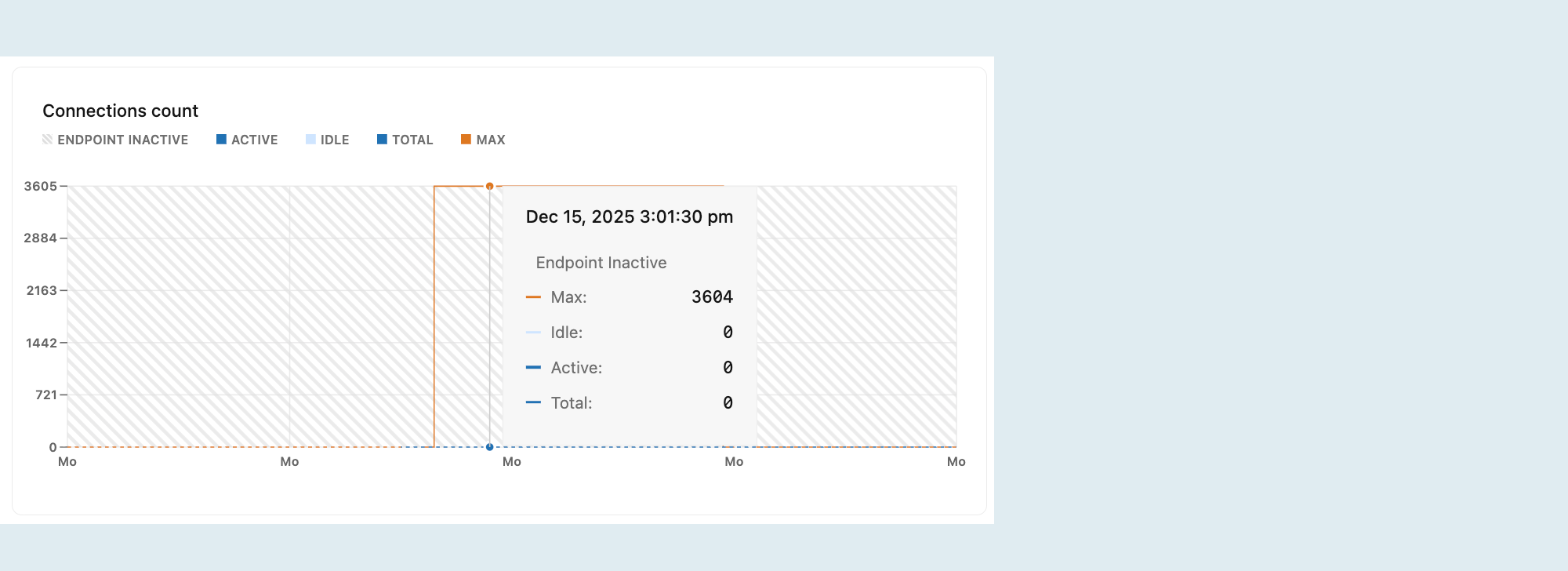
O gráfico de contagem de conexões mostra o número máximo de conexões, o número de conexões parado, o número de conexões ativas e o número total de conexões ao longo do tempo para o compute selecionado.
Ativo : O número de conexões ativas para o compute selecionado.
Monitorar as conexões ativas ajuda você a entender a carga de trabalho do seu banco de dados. Se o número de conexões ativas for consistentemente alto, seu banco de dados pode estar sob carga elevada, o que pode levar a problemas de desempenho, como tempos de resposta lentos para consultas.
parado : O número de conexões Parado para o compute selecionado.
As conexões Parado estão abertas, mas não estão em uso no momento. Embora algumas conexões parado geralmente sejam inofensivas, um grande número delas pode consumir recursos desnecessários, deixando menos espaço para conexões ativas e potencialmente afetando o desempenho. Identificar e fechar conexões parado desnecessárias pode ajudar a liberar recursos.
Total : A soma das conexões ativas e paralelas para o compute selecionado.
Máx .: O número máximo de conexões simultâneas permitidas para o tamanho do seu compute .
A linha Max ajuda você a visualizar o quão perto você está de atingir seu limite de conexão. Quando o número total de suas conexões se aproximar do limite máximo, considere o seguinte:
- Aumentar a capacidade compute permite mais conexões.
- Otimizar o gerenciamento de conexões do seu aplicativo (usando pool de conexões, fechando conexões não utilizadas prontamente e evitando conexões Parado de longa duração).
O limite de conexões é definido pela configuração max_connections do Postgres e é determinado pela sua configuração de tamanho compute . Para obter uma lista completa do número máximo de conexões por tamanho compute , consulte as especificações de computação.
Tamanho do banco de dados
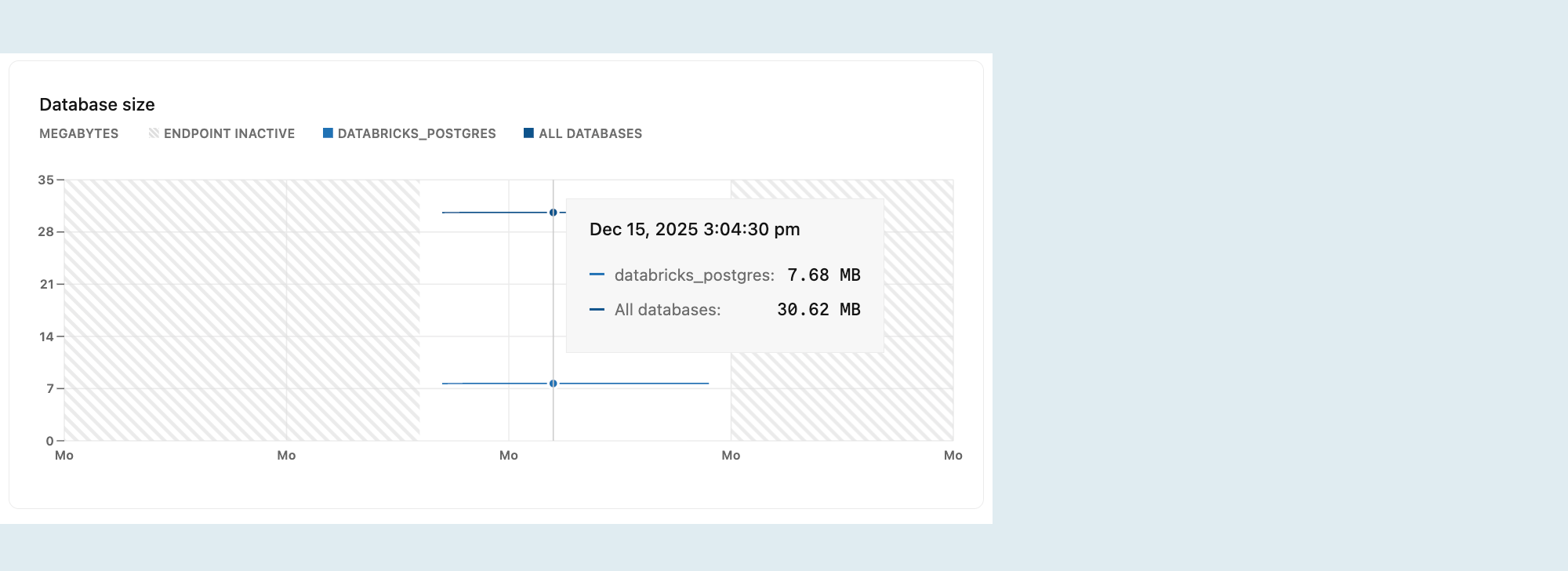
O gráfico de tamanho do banco de dados mostra o tamanho real dos seus dados para o banco de dados selecionado ou para todos os bancos de dados na filial selecionada.
Quando um banco de dados atinge sua cota de armazenamento, o desempenho de gravação diminui.
O tamanho lógico representa o tamanho dos seus dados conforme relatado pelo Postgres, incluindo tabelas e índices.
As especificações de tamanho do banco de dados são exibidas apenas enquanto seu compute estiver ativo. Quando o seu compute é Parado, os valores de tamanho do banco de dados não são relatados e o gráfico mostra zero, mesmo que haja dados presentes.
Impasses
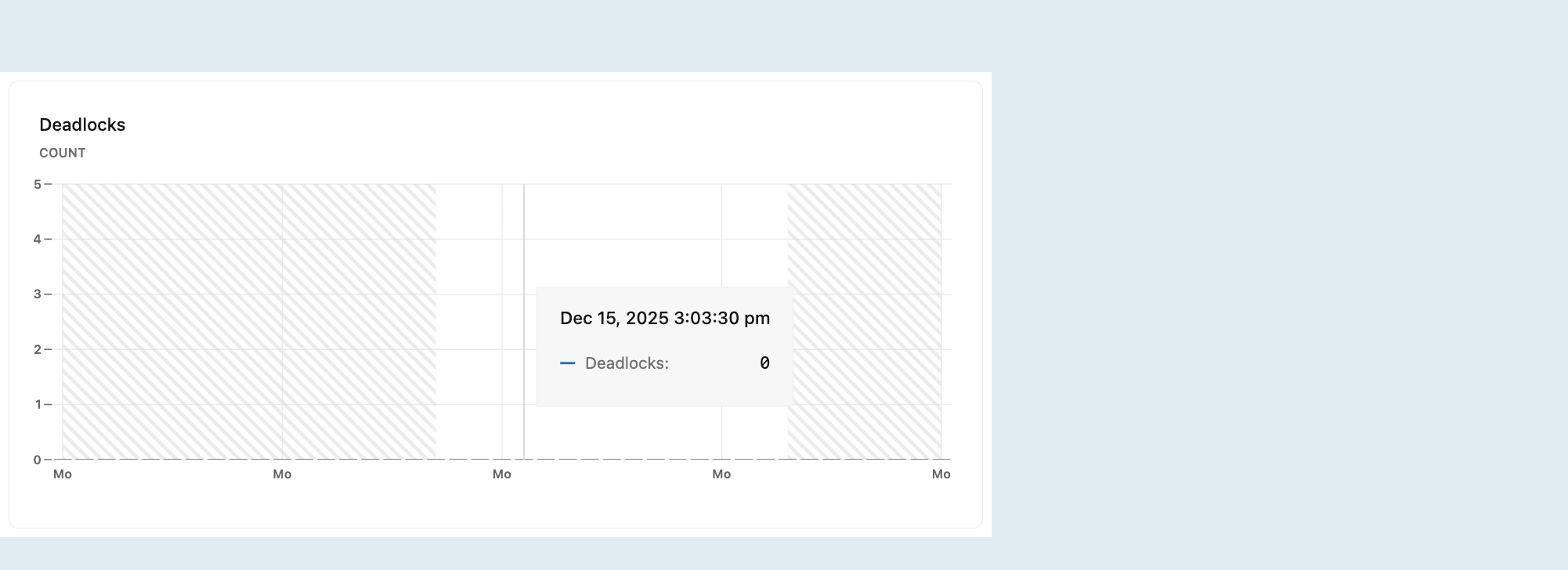
O gráfico de impasses mostra a contagem de impasses ao longo do tempo.
Os impasses ocorrem quando duas ou mais transações se bloqueiam simultaneamente, mantendo recursos necessários para as outras transações, criando um ciclo de dependências que impede o andamento de qualquer transação. Isso pode levar a problemas de desempenho ou erros de aplicação. Para saber mais sobre impasses (deadlocks) no PostgreSQL, consulte a documentação do PostgreSQL sobre impasses.
Linhas
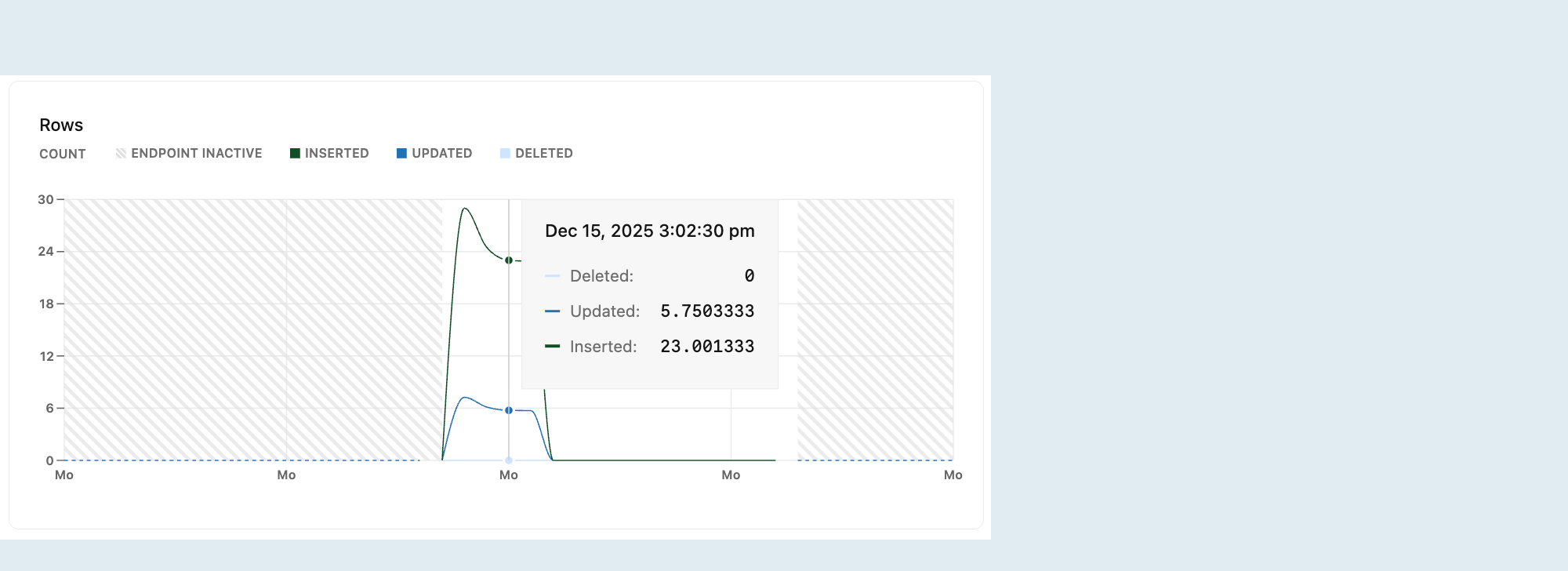
O gráfico de linhas mostra o número de linhas excluídas, atualizadas e inseridas ao longo do tempo. A linha é zerada sempre que o compute é reiniciado.
Acompanhar as linhas inseridas, atualizadas e excluídas ao longo do tempo fornece informações sobre os padrões de atividade do seu banco de dados. Você pode usar esses dados para identificar tendências ou irregularidades, como picos de inserção ou um número incomum de exclusões.
As métricas de linha capturam apenas alterações em nível de linha (INSERT, UPDATE, DELETE) e excluem operações em nível de tabela, como TRUNCATE.
bytes de atraso de replicação
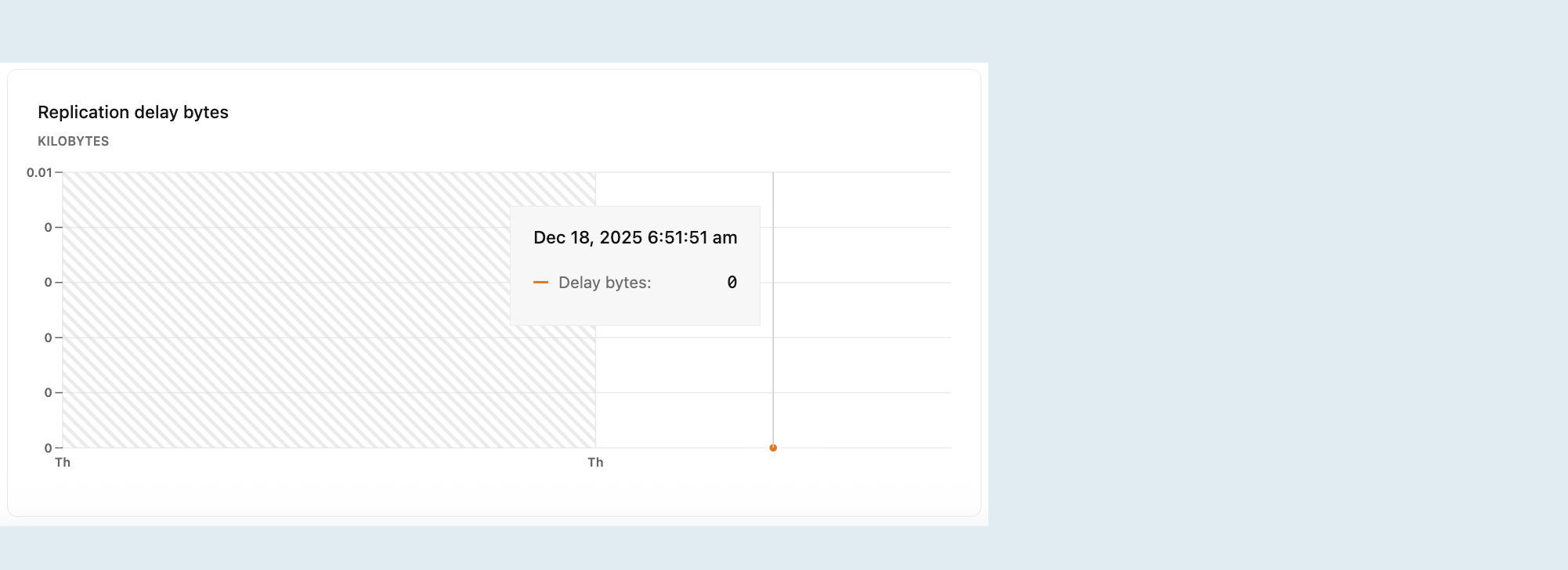
O gráfico "Bytes de atraso de replicação" mostra o tamanho total, em bytes, dos dados enviados do compute primário, mas ainda não aplicados à réplica. Um valor maior indica um acúmulo maior de dados aguardando replicação, o que pode sugerir problemas com a replicação (Taxa de transferência ou disponibilidade de recursos) na réplica.
Este gráfico só fica visível ao selecionar uma réplica compute de leitura no menu suspenso de computação. Para obter mais informações sobre réplicas de leitura, consulte Réplicas de leitura.
Atraso de replicação em segundos
O gráfico "Atraso de replicação em segundos" mostra o atraso, em segundos, entre a última transação confirmada no compute primário e a aplicação dessa transação na réplica. Um valor mais alto sugere que a réplica está atrasada em relação ao servidor primário, possivelmente devido à latência da rede, alta carga de replicação ou restrições de recursos na réplica.
Este gráfico só fica visível ao selecionar uma réplica compute de leitura no menu suspenso de computação. Para obter mais informações sobre réplicas de leitura, consulte Réplicas de leitura.
taxa de acertos do cache de arquivos local
O gráfico da taxa de acertos do cache de arquivos local mostra a porcentagem de solicitações de leitura atendidas pelo cache de arquivos local. Consultas que não são atendidas pelos buffers compartilhados do Postgres ou pelo cache de arquivos local recuperam dados do armazenamento, o que é mais custoso e pode resultar em um desempenho de consulta mais lento.
Para cargas de trabalho OLTP, busque uma taxa de acerto de cache de 99% ou superior. Se a sua taxa for inferior a 99%, o seu conjunto de trabalho pode não caber na memória, resultando num desempenho mais lento. Para melhorar a taxa de acertos do cache, aumente o tamanho do seu poder compute para expandir o cache de arquivos local. A proporção ideal depende da sua carga de trabalho — cargas de trabalho com varreduras sequenciais de tabelas grandes podem ter um desempenho aceitável com uma proporção ligeiramente menor.
:::info Sobre o cache de arquivos local
O cache de arquivos local (LFC, na sigla em inglês) é uma camada de cache que armazena dados acessados frequentemente na memória local do seu compute. Quando os dados são solicitados, o Postgres verifica primeiro os buffers compartilhados, depois o LFC e, por fim, recupera os dados do armazenamento, se necessário. O tamanho do LFC aumenta com o poder computacional do seu compute— ele pode usar até 75% da RAM da sua compute. Por exemplo, um compute com 8 GB de RAM possui um cache de arquivos local de 6 GB. Para um desempenho ideal, dimensione seu compute de forma que seu conjunto de trabalho caiba no cache de arquivos local.
:::
Tamanho do conjunto de trabalho
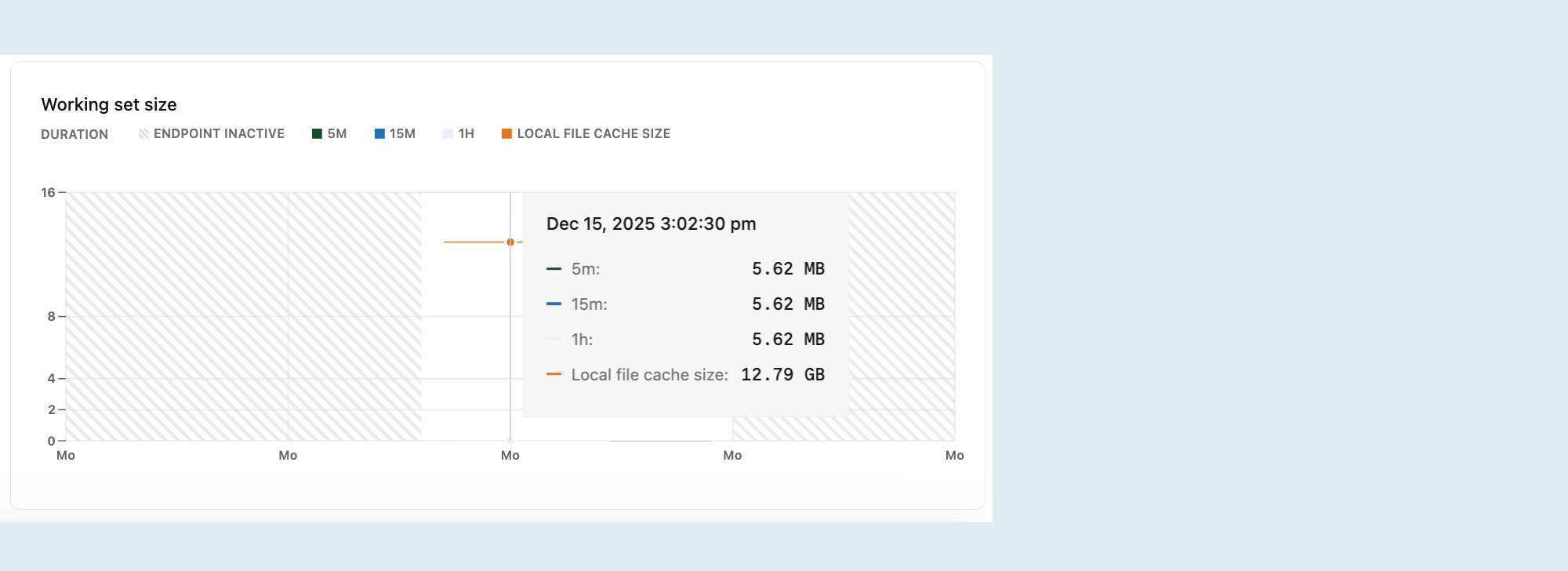
Seu conjunto de trabalho é o tamanho do conjunto distinto de páginas do Postgres (dados de relacionamento e índices) acessadas em um determinado intervalo de tempo. Para um desempenho ideal e latência consistente, dimensione seu compute de forma que o conjunto de trabalho caiba no cache de arquivos local para acesso rápido.
O gráfico de tamanho do conjunto de trabalho visualiza a quantidade de dados acessados (calculada como páginas únicas acessadas × tamanho da página) em um determinado intervalo. O gráfico exibe:
5m (5 minutos) : Os dados acessados nos últimos 5 minutos.
15m (15 minutos) : Os dados acessados nos últimos 15 minutos.
1h (1 hora) : Os dados acessados na última hora.
Tamanho do cache de arquivos local : O tamanho do cache de arquivos local, determinado pelo tamanho do seu compute. Computadores maiores possuem caches maiores.
Para um desempenho ideal, o cache de arquivos local deve ser maior que o tamanho do seu conjunto de trabalho para um determinado intervalo de tempo. Se o tamanho do seu conjunto de trabalho for maior que o tamanho do cache de arquivos local, aumente o tamanho máximo do seu compute para melhorar a taxa de acertos do cache e obter um melhor desempenho. Para opções e especificações de dimensionamento compute , consulte as especificações de computação.
Se o padrão de sua carga de trabalho não mudar muito ao longo do tempo, compare o tamanho do conjunto de trabalho de 1 hora com o tamanho do cache de arquivos local e certifique-se de que o tamanho do conjunto de trabalho seja menor que o tamanho do cache de arquivos local.