Armazene as alterações do Postgres na lakehouse
O recurso de Feed de Dados de Alterações do Lakebase está em Pré-visualização Pública.
Configure o Lakebase Change Data Feed (CDF) em uma tabela do Postgres e, em seguida, observe as alterações em nível de linha aparecerem na tabela Delta de destino.
Os passos: ① Ativar a captura de alterações → ② Iniciar o feed → ③ Seguir uma linha até a lakehouse → ④ Alterar a linha e observar o fluxo.
Este é um guia de início rápido. Para obter a documentação completa, consulte o Feed de Dados de Alterações do Lakebase.
Antes de começar
- Certifique-se de ter concluído a etapa Obter um banco de dados Postgres. Você precisa de um projeto Lakebase com a tabela de exemplo
playing_with_lakebase. - Um catálogo e esquema do Unity Catalog onde você tem permissão
CREATE TABLE.
o passo 1: Habilitar captura de alterações
O Postgres precisa de dados de linha completos no log de escrita antecipada para que o CDF funcione. Configurar a identidade da réplica como completa instrui o Postgres a registrar o estado antigo e o novo da linha para cada alteração.
No Lakebase SQL Editor, execução:
ALTER TABLE playing_with_lakebase REPLICA IDENTITY FULL;
o passo 2: iniciar o feed
O CDF do Lakebase é configurado no nível do esquema. Todas as tabelas atuais e futuras do esquema de origem são incluídas automaticamente, portanto, você não precisa selecionar tabelas individualmente.
Na sua branch de produção, abra a Visão geral da Branch clicando no nome da branch no breadcrumbs superior e, em seguida, abra a tab Lakebase CDF e clique em Começar . Escolha public como esquema de origem e, em seguida, selecione um catálogo e esquema de destino do Unity Catalog. O Snapshot inicial começa imediatamente, e lb_playing_with_lakebase_history aparece como uma tabela Delta no seu destino.
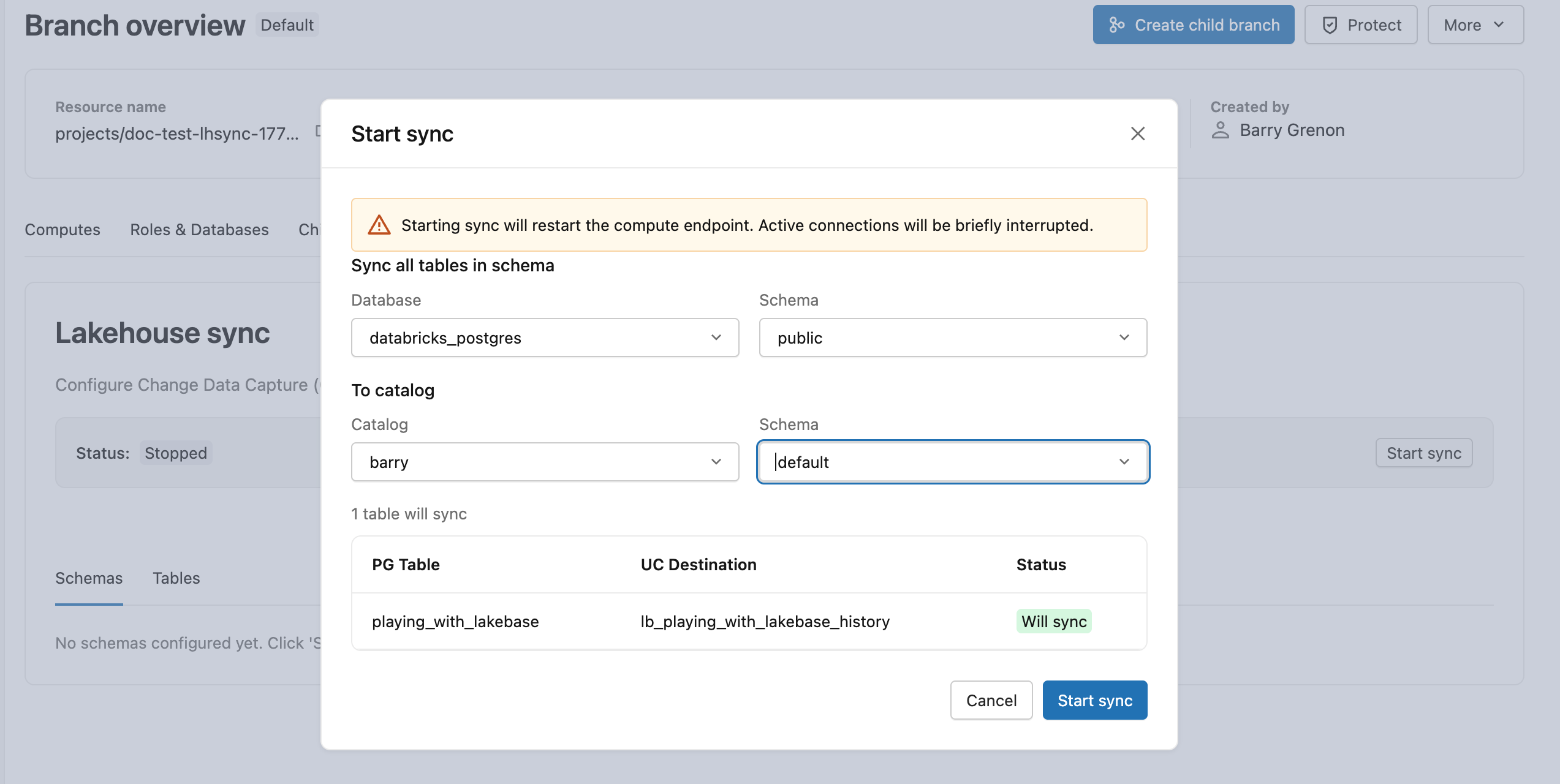
Saiba mais: inicie o feed de dados de alterações
o passo 3: Siga uma fileira até a lakehouse
Selecione uma linha do Lakebase. Observe a linha id=2:
SELECT * FROM playing_with_lakebase WHERE id = 2;
Agora encontre a mesma linha na tabela Delta história. Mude para um data warehouse Databricks SQL e execute o seguinte:
SELECT * FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2;
Substitua <catalog> e <schema> pelo destino que você escolheu na etapa 2. Você verá a linha id=2 com os mesmos name e value que no Lakebase, mais colunas extras. O Snapshot inicial gravou cada linha existente no Delta como um evento insert , que é o que essa linha representa.
Essas colunas extras descrevem que tipo de evento cada linha representa (_pg_change_type), quando aconteceu (_timestamp) e as informações de ordenação do Postgres (_pg_lsn, _pg_xid).
Saiba mais: Esquema da tabela de destino | Mapeamento de tipo de dados
Passo 4: Altere a linha e veja o fluxo passar.
De volta ao Editor SQL do Lakebase, atualize a linha id=2:
UPDATE playing_with_lakebase SET value = 55.5 WHERE id = 2;
Aguarde alguns segundos para que a alteração apareça no feed e, em seguida, consulte novamente a tabela de histórico:
SELECT id, value, _pg_change_type, _timestamp
FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2
ORDER BY _pg_lsn DESC;

A linha id=2 agora aparece três vezes: a original insert, uma update_preimage com o valor antigo e uma update_postimage com o novo valor. Cada alteração em uma linha se torna uma nova linha no histórico, garantindo sempre um registro completo de auditoria. As exclusões funcionam da mesma forma, acrescentando uma linha com _pg_change_type = 'delete'.
Saiba mais: Padrões de mudança comuns | Construir um pipeline downstream
Próximos passos
- Crie um pipeline downstream: Transforme a tabela de história em um agregado ativo com uma view materializada, Lakeflow Pipelines ou Structured Streaming.
- execução analítica: Consulte suas tabelas Delta história com Databricks SQL.
- Utilize a camada de bronze: Conecte a mesa de história a uma arquitetura de medalhão.
- Analise os limites de produção: consulte as limitações, a resolução de problemas e o gerenciamento de alterações de esquema.
- Explore o Lakebase: Conceitos básicos | Lakebase