ETL reverso com projetos Lakebase
O dimensionamento automático do Lakebase está disponível nas seguintes regiões: us-east-1, us-east-2, us-west-2, eu-central-1, eu-west-1, ap-south-1, ap-southeast-1, ap-southeast-2.
O Lakebase autoscale é a versão mais recente do Lakebase com recursos como autoscale compute, escala-to-zero, branching e instant restore. Para comparação de recursos com o provisionamento do Lakebase, veja escolhendo entre versões.
ETL reverso no Lakebase sincroniza as tabelas Unity Catalog com o Postgres, permitindo que os aplicativos usem diretamente os dados selecionados lakehouse . O lakehouse é otimizado para análises e enriquecimento de dados, enquanto o Lakebase foi projetado para cargas de trabalho operacionais que exigem consultas rápidas e consistência transacional.
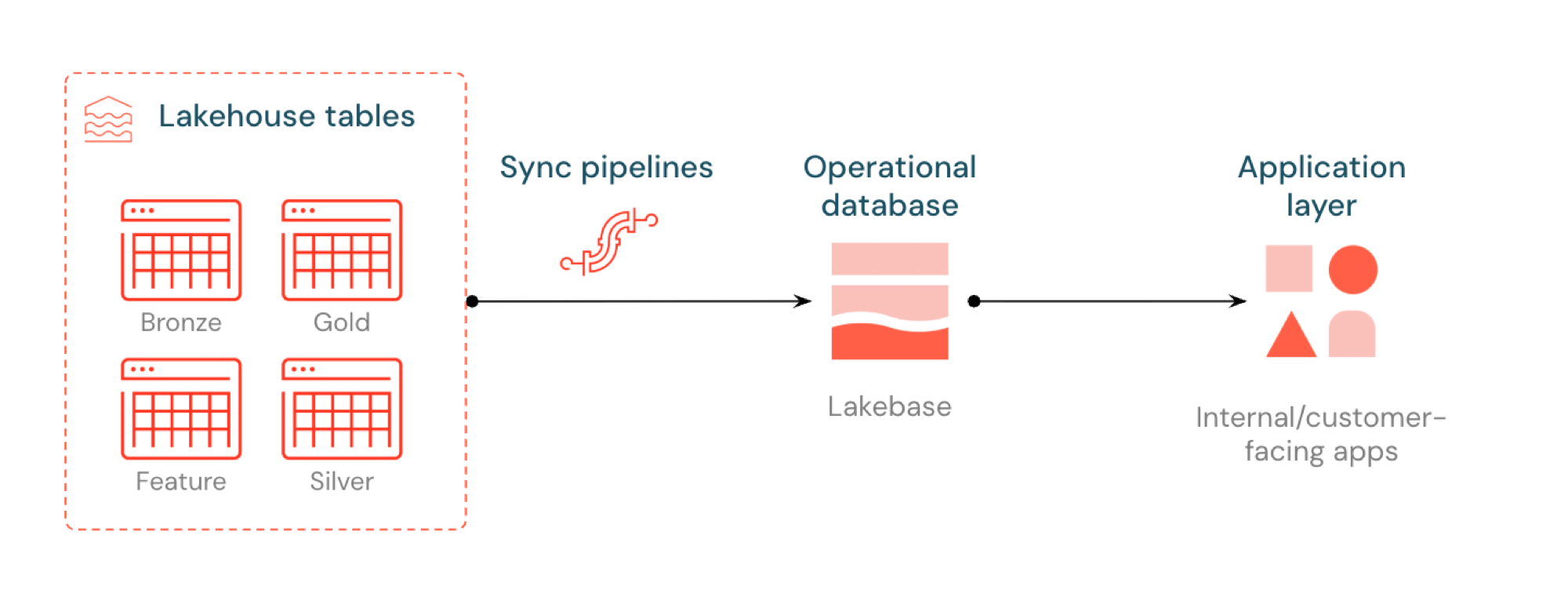
O que é ETL reverso?
ETL reverso permite mover dados de nível analítico do Unity Catalog para o Lakebase Postgres, onde você pode disponibilizá-los para aplicativos que precisam de consultas de baixa latência (menos de 10 ms) e ACID completo. Ele preenche a lacuna entre o armazenamento analítico e os sistemas operacionais, mantendo os dados selecionados utilizáveis em aplicações em tempo real.
Como funciona
As tabelas sincronizadas Databricks criam uma cópia gerenciada dos dados do seu Unity Catalog no Lakebase. Ao criar uma tabela sincronizada, você obtém:
- Uma nova tabela Unity Catalog (somente leitura, gerenciada pelo pipeline de sincronização)
- Uma tabela do Postgres no Lakebase (consultável por suas aplicações)
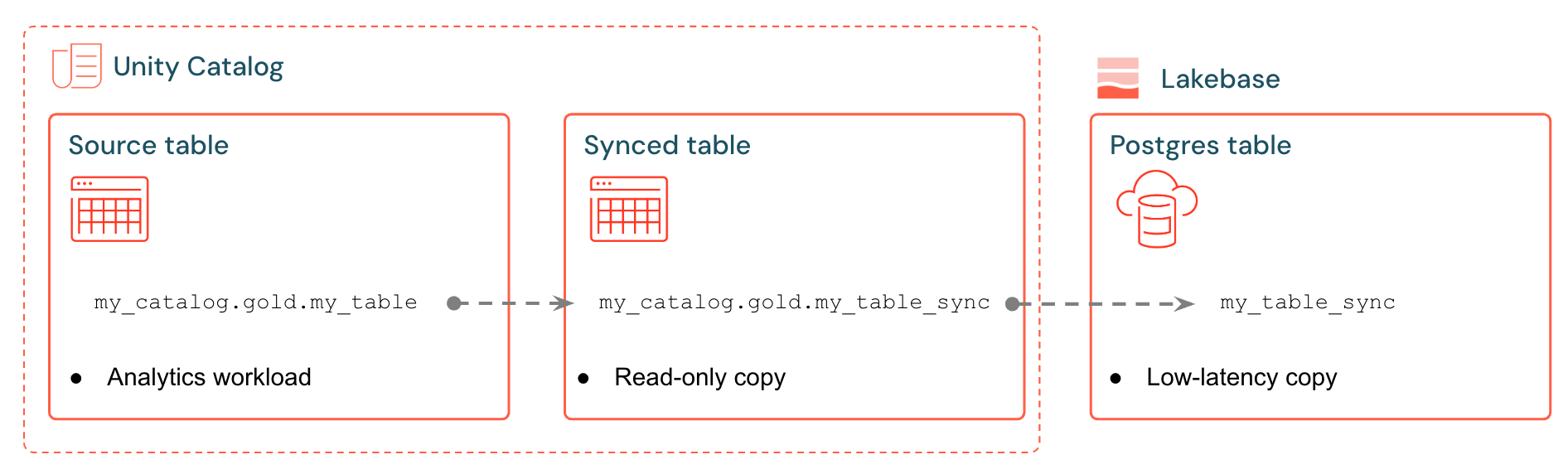
Por exemplo, você pode sincronizar tabelas ouro, recursos projetados ou saídas ML de analytics.gold.user_profiles em uma nova tabela sincronizada analytics.gold.user_profiles_synced. No Postgres, o nome do esquema Unity Catalog torna-se o nome do esquema do Postgres, portanto, isso aparece como "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Os aplicativos se conectam com drivers padrão do Postgres e consultam os dados sincronizados juntamente com seu próprio estado operacional.
Embora seja possível modificar uma tabela sincronizada diretamente no Postgres, Databricks recomenda enfaticamente a execução apenas de consultas de leitura para proteger a integridade dos dados com a fonte. Para operações suportadas em tabelas sincronizadas, consulte Operações suportadas.
O pipeline de sincronização utiliza o pipeline declarativo do LakeFlow Spark para atualizar continuamente tanto a tabela sincronizada Unity Catalog quanto a tabela do Postgres com as alterações da tabela de origem. Cada sincronização pode usar até 16 conexões com seu banco de dados Lakebase.
O Lakebase Postgres suporta até 1.000 conexões simultâneas com garantias transacionais, permitindo que os aplicativos leiam e enriqueçam dados enquanto também lidam com inserções, atualizações e exclusões no mesmo banco de dados.
Modos de sincronização
Escolha o modo de sincronização adequado com base nas necessidades da sua aplicação:
Mode | Descrição | Ideal para | Desempenho |
|---|---|---|---|
Snapshot | Cópia única de todos os dados | Configuração inicial ou análise histórica | 10 vezes mais eficiente se modificar mais de 10% dos dados de origem. |
Acionado | Atualizações programadas que são executadas sob demanda ou em intervalos regulares. | Painéis de controle, atualizados a cada hora/diariamente | Bom equilíbrio entre custo e atraso. Caro se a execução <intervalos de 5min |
Contínuo | tempo real transmissão com segundos de latência | Aplicações em tempo real (custo mais elevado devido à compute dedicada) | Menor latência, maior custo. Intervalos mínimos de 15 segundos |
Os modos Acionado e Contínuo exigem que o Feed de Dados de Alteração (CDF) esteja ativado na sua tabela de origem. Se o CDF não estiver habilitado, você verá um aviso na interface do usuário com o comando ALTER TABLE exato para execução. Para obter mais detalhes sobre o Feed de Dados de Alterações, consulte Usar o feed de dados de alterações do Delta Lake no Databricks.
Exemplos de casos de uso
O ETL reverso com Lakebase oferece suporte a cenários operacionais comuns:
- Mecanismos de personalização que precisam de perfis de usuário atualizados sincronizados com os aplicativos Databricks.
- Aplicações que servem para previsões de modelos ou valores de recursos são computadas na lakehouse
- Painéis de controle voltados para o cliente que exibem KPIs em tempo real.
- Serviço de detecção de fraudes que necessita de pontuações de risco disponíveis para ação imediata.
- Ferramentas de suporte que enriquecem os registros de clientes com dados selecionados da lakehouse
Criar uma tabela sincronizada (interface do usuário)
O fluxo de trabalho da interface do usuário está descrito abaixo.
Pré-requisitos
Você precisa de:
- Um workspace Databricks com o Lakebase ativado.
- Um projeto Lakebase (consulte Criar um projeto).
- Uma tabela do Unity Catalog com dados selecionados.
- Permissões para criar tabelas sincronizadas. Você precisa de USE_SCHEMA e CREATE_TABLE em qualquer esquema que utilizar. As opções de catálogo e esquema no fluxo Criar tabela sincronizada listam apenas os esquemas nos quais sua identidade possui esses privilégios.
Para planejamento de capacidade e compatibilidade de tipos de dados, consulte Tipos de dados e compatibilidade e Planejamento de capacidade.
Passo 1: Selecione sua tabela de origem
Acesse o Catálogo na barra lateral workspace e selecione a tabela Unity Catalog que deseja sincronizar.
Passo 2: Ativar Feed de Dados de Alteração (se necessário)
Se você planeja usar os modos de sincronização acionada ou contínua , sua tabela de origem precisa ter o Feed de Dados de Alteração ativado. Verifique se sua tabela já possui o CDF habilitado ou execute este comando em um editor SQL ou Notebook:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Substitua your_catalog.your_schema.your_table pelo nome real da sua tabela.
o passo 3: Criar tabela sincronizada
Na view de detalhes da tabela, clique em Criar > Tabela sincronizada .
o passo 4: Configurar
Na caixa de diálogo Criar tabela sincronizada :
As listas de catálogo e esquema incluem apenas os esquemas do Unity Catalog nos quais o usuário atual possui privilégios USE_SCHEMA e CREATE_TABLE . Se você não encontrar o esquema esperado, confirme suas permissões com o administrador do catálogo.
- Nome da tabela : Insira um nome para a sua tabela sincronizada (ela será criada no mesmo catálogo e esquema que a sua tabela de origem). Isso cria uma tabela sincronizada Unity Catalog e uma tabela do Postgres que você pode consultar.
- Tipo de banco de dados : Escolha Lakebase serverless (autoscale) .
- Modo de sincronização : Escolha Snapshot , Acionado ou Contínuo , de acordo com suas necessidades (consulte os modos de sincronização acima).
- Configure seu projeto, ramificação e seleções de banco de dados.
- Verifique se a keyprimária está correta (geralmente detectada automaticamente).
Se você selecionou o modo Acionado ou Contínuo e ainda não ativou a opção Alterar Feed de Dados, verá um aviso com o comando exato a ser executado. Para questões de compatibilidade de tipos de dados, consulte Tipos de dados e compatibilidade.
Clique em Criar para criar a tabela sincronizada.
o passo 5: Monitor
Após a criação, monitore a tabela sincronizada no Catálogo . A tab Visão geral mostra o status da sincronização, a configuração, o status pipeline e o registro de data e hora da última sincronização. Use a opção Sincronizar agora para refresh manual.
Tipos de dados e compatibilidade
Os tipos de dados do Unity Catalog são mapeados para os tipos do Postgres ao criar tabelas sincronizadas. Tipos complexos (ARRAY, MAP, STRUCT) são armazenados como JSONB no Postgres.
Tipo de coluna de origem | tipo de coluna do Postgres |
|---|---|
BigInt | BigInt |
binário | BYTEA |
Booleana | Booleana |
Data | Data |
DECIMAL(p,s) | NUMÉRICO |
double | DUPLA PRECISÃO |
Float | REAL |
INT | Integer |
INTERVALO | INTERVALO |
INT PEQUENA | INT PEQUENA |
String | TEXT |
Timestamp | CARIMBO DE DATA E HORA COM FUSO HORÁRIO |
TIMESTAMP_NTZ | CARIMBO DE DATA E HORA SEM FUSO HORÁRIO |
TINYINT | INT PEQUENA |
ARRAY<elementType> | JSONB |
MAPA<tipoDeChave,tipoDeValor> | JSONB |
ESTRUTURA<nomeDoCampo:tipoDoCampo[, ...]> | JSONB |
Os tipos GEOGRAPHY, GEOMETRY, VARIANT e OBJECT não são suportados.
Lidar com caracteres inválidos
Certos caracteres, como bytes nulos (0x00), são permitidos em strings Unity Catalog , colunas ARRAY, MAP ou STRUCT, mas não são suportados em colunas TEXT ou JSONB do Postgres. Isso pode causar falhas de sincronização com erros como:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
par:
-
Higienizar campos de texto : Remover caracteres não suportados antes da sincronização. Para bytes nulos em colunas de strings:
SQLSELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_table -
Converter para BINÁRIO : Para colunas de strings onde a preservação dos bytes brutos é necessária, converta para o tipo BINÁRIO.
Planejamento de capacidade
Ao planejar a implementação do seu ETL reverso, considere os seguintes requisitos de recursos:
- Utilização de conexões : Cada tabela sincronizada utiliza até 16 conexões com o banco de dados Lakebase, que são contabilizadas no limite de conexões da instância.
- Limites de tamanho : O limite total de tamanho dos dados lógicos em todas as tabelas sincronizadas é de 8 TB. As tabelas individuais não têm limites, mas Databricks recomenda não exceder 1 TB para tabelas que precisam ser atualizadas.
- Requisitos de nomenclatura : Os nomes de banco de dados, esquema e tabela podem conter apenas caracteres alfanuméricos e sublinhados (
[A-Za-z0-9_]+). - Evolução do esquema : Somente alterações aditivas de esquema (como a adição de colunas) são suportadas nos modos Acionado e Contínuo.
- Taxa de atualização: Para o dimensionamento automático do Lakebase, o pipeline de sincronização suporta gravações contínuas e acionadas a aproximadamente 150 linhas por segundo por Unidade de Capacidade (UC) e gravações Snapshot a até 2.000 linhas por segundo por UC.
operações permitidas em tabelas sincronizadas no Postgres
A Databricks recomenda que, para evitar sobrescritas acidentais ou inconsistências de dados, sejam realizadas apenas as seguintes operações no Postgres para tabelas sincronizadas:
- Consultas somente leitura
- Criação de índices
- Excluindo a tabela (para liberar espaço após remover a tabela sincronizada do Unity Catalog)
Embora seja possível modificar tabelas sincronizadas no Postgres de outras maneiras, isso interfere no pipeline de sincronização.
Excluir uma tabela sincronizada
Para excluir uma tabela sincronizada, você deve removê-la tanto do Unity Catalog quanto do Postgres:
-
Excluir do Unity Catalog : No Catálogo , encontre sua tabela sincronizada e clique em
 menu e selecione Excluir . Isso interrompe a atualização dos dados, mas mantém a tabela no Postgres.
menu e selecione Excluir . Isso interrompe a atualização dos dados, mas mantém a tabela no Postgres. -
Excluir do Postgres : Conecte-se ao seu banco de dados Lakebase e exclua a tabela para liberar espaço:
SQLDROP TABLE your_database.your_schema.your_table;
Você pode usar o editor SQL ou ferramentas externas para se conectar ao Postgres.
Saber mais
Tarefa | Descrição |
|---|---|
Configure um projeto Lakebase | |
Conheça as opções de conexão para o Lakebase. | |
Torne seus dados do Lakebase visíveis no Unity Catalog para governança unificada e consultas entre fontes de dados. | |
Compreender a governança e as permissões |
Outras opções
Para sincronizar dados com sistemas que não sejam Databricks, consulte as soluções de ETL reverso do Partner Connect, como Census ou Hightouch.