Arquitetura de armazenamento
Lakebase separa o armazenamento do compute. Os dados do seu banco de dados residem em uma camada de armazenamento distribuída gerenciada pelo Databricks, independente das instâncias de compute que executam suas consultas. O armazenamento persiste e permanece altamente disponível, quer o seu compute esteja em execução, em pausa ou em escalonamento.
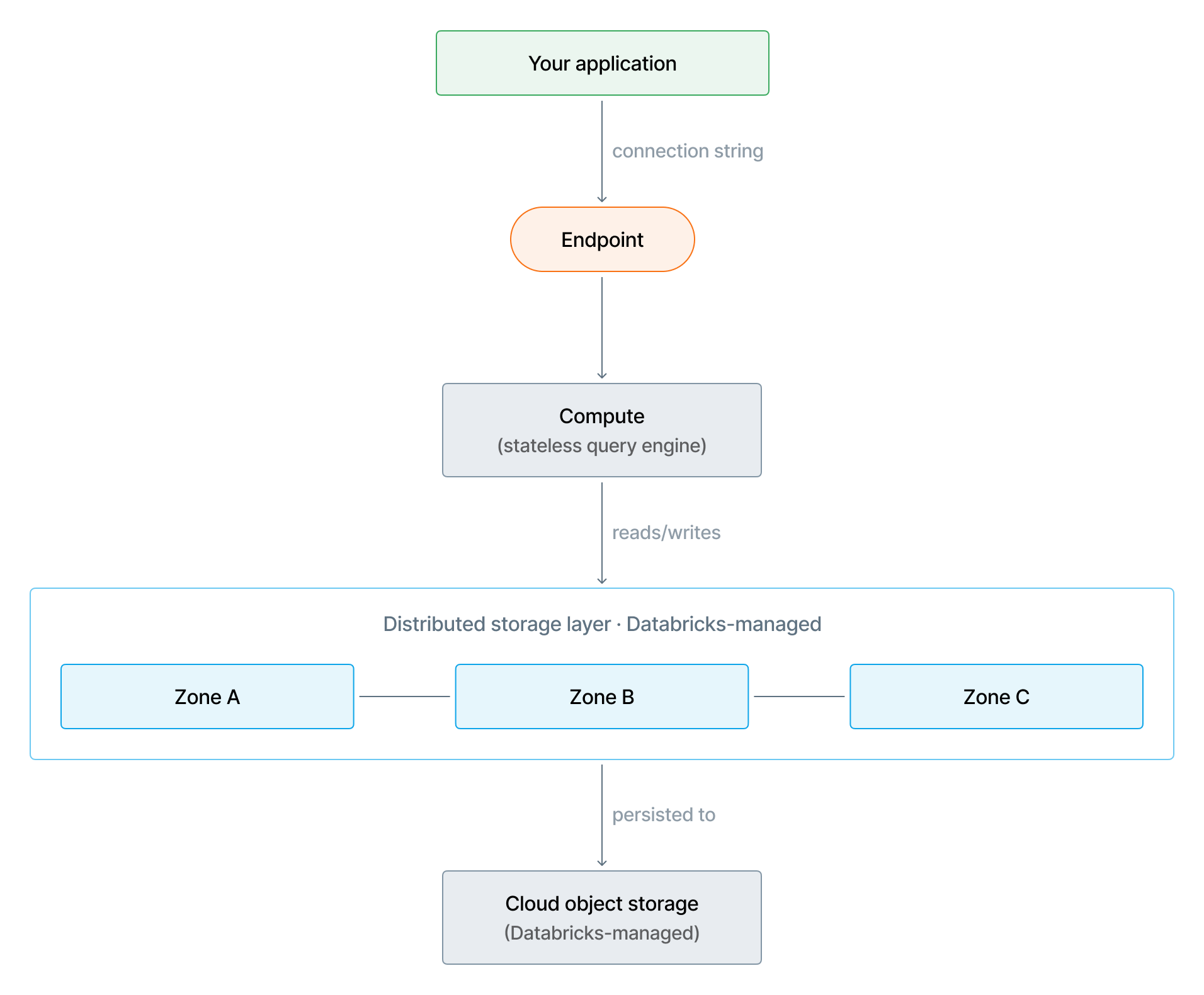
Camada de armazenamento
Lakebase usa uma arquitetura de armazenamento distribuído. Nenhuma máquina individual detém o estado definitivo do seu banco de dados. Os dados também são persistidos no armazenamento de objetos na cloud gerenciado pela Databricks, a base de durabilidade para toda a camada de armazenamento. O armazenamento de objetos em Cloud é projetado para durabilidade extremamente alta e não depende de replicação assíncrona, assim, a durabilidade não é afetada pelo atraso da replicação. Databricks gerencia a configuração de redundância de armazenamento.
Na AWS, o Lakebase persiste dados no Amazon S3 como a camada de armazenamento de objetos em nuvem.
A redundância de armazenamento é independente de compute HA
A redundância e a disponibilidade do armazenamento do Lakebase são gerenciadas pelo Databricks e são independentes da configuração de compute de alta disponibilidade (HA). Ativar ou desativar HA não afeta a redundância de armazenamento.
Alta disponibilidade é um recurso da camada de compute. Pré-provisiona uma instância compute secundária em uma zona de disponibilidade separada para failover automático. Redundância de armazenamento e alta disponibilidade de compute são camadas independentes.
Característica | Redundância de armazenamento | Compute de alta disponibilidade (HA) |
|---|---|---|
Obrigatório | Sim | Não |
Configurável pelo cliente | Não | Sim |
O que ele protege | Durabilidade e disponibilidade dos dados | Capacidade de executar consultas |
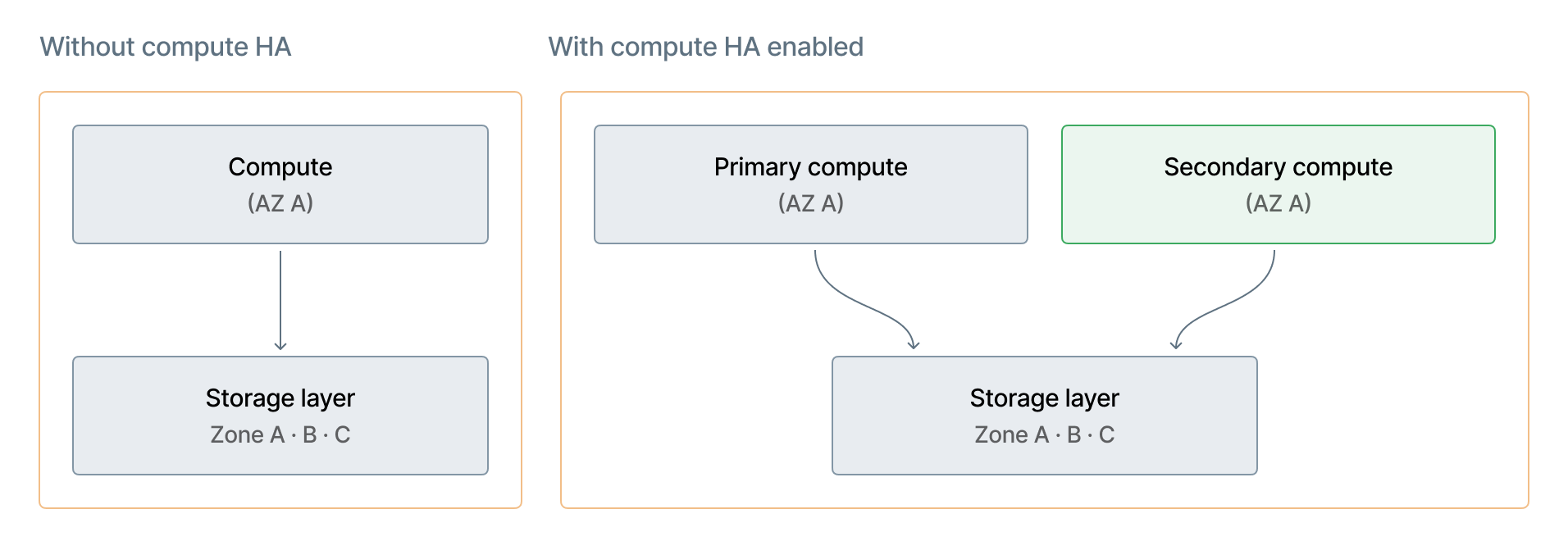
Como a separação de armazenamento permite outros recursos
A separação do armazenamento do compute possibilita vários recursos do Lakebase.
- Perda zero de dados (RPO = 0): Como cada transação confirmada é persistida de forma durável no armazenamento de objetos em cloud antes de ser reconhecida, nenhum dado confirmado é perdido quando o compute falha, reinicia, é dimensionado para zero ou faz failover.
- Ramificações instantâneas: O Lakebase cria ramificações usando copy-on-write em armazenamento compartilhado. O processo não duplica dados.
- Réplicas de leitura: várias instâncias de compute lêem da mesma camada de armazenamento compartilhada. Esta abordagem não requer replicação de dados.
- Dimensionamento para zero: O compute pausa, mas o armazenamento persiste. Os dados estão imediatamente disponíveis quando o compute é retomado.
- Failover rápido: Como o armazenamento é separado do compute, o failover não envolve a movimentação de dados. Lakebase promove uma instância de compute secundária que se conecta ao armazenamento existente.
Informações relacionadas
- Alta disponibilidade: Configure redundância em nível de compute para failover automático entre zonas de disponibilidade. Consulte Alta disponibilidade.
- Gerenciar alta disponibilidade: Ative e configure a configuração de compute de HA no seu endpoint. Consulte Gerenciar alta disponibilidade.
- Branches de banco de dados: Aprenda como branches usam armazenamento copy-on-write para criar ambientes isolados instantâneos. Consulte Branches.
- Réplicas de leitura: Adicione instâncias de compute só de leitura que leem da mesma camada de armazenamento, sem replicação de dados. Consulte Réplicas de leitura.