Casos de uso
O autoscale Lakebase suporta quatro padrões principais: servir dados lakehouse no Postgres, armazenar alterações do Postgres no lakehouse, executar um backend de aplicação e alimentar agentesAI e ML. Cada padrão utiliza o Postgres juntamente com o Unity Catalog para fornecer ao seu aplicativo um banco de dados de baixa latência que permanece sincronizado com o lakehouse.
Dados de serviço lakehouse
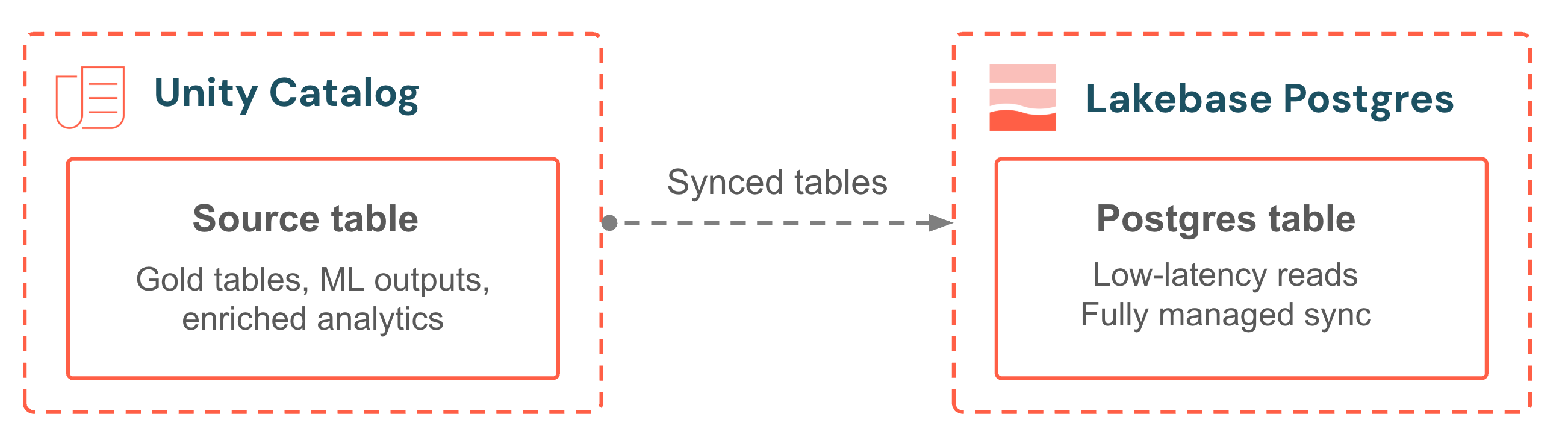
As tabelas sincronizadas trazem os dados do Unity Catalog para o seu banco de dados Lakebase, permitindo leituras transacionais de baixa latência. Selecione uma tabela de origem, escolha um modo de sincronização e o pipeline será totalmente gerenciado. Sem scripts de sincronização, sem orquestração externa, sem Job para monitorar. O modo contínuo mantém os dados a poucos segundos da fonte. O modo acionado equilibra a atualização e o custo com atualizações incrementais programadas. Seu aplicativo sempre fornece as análises mais recentes juntamente com seus próprios dados operacionais.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
Armazene as alterações do Postgres na lakehouse
O recurso de Feed de Dados de Alterações do Lakebase está em Pré-visualização Pública.
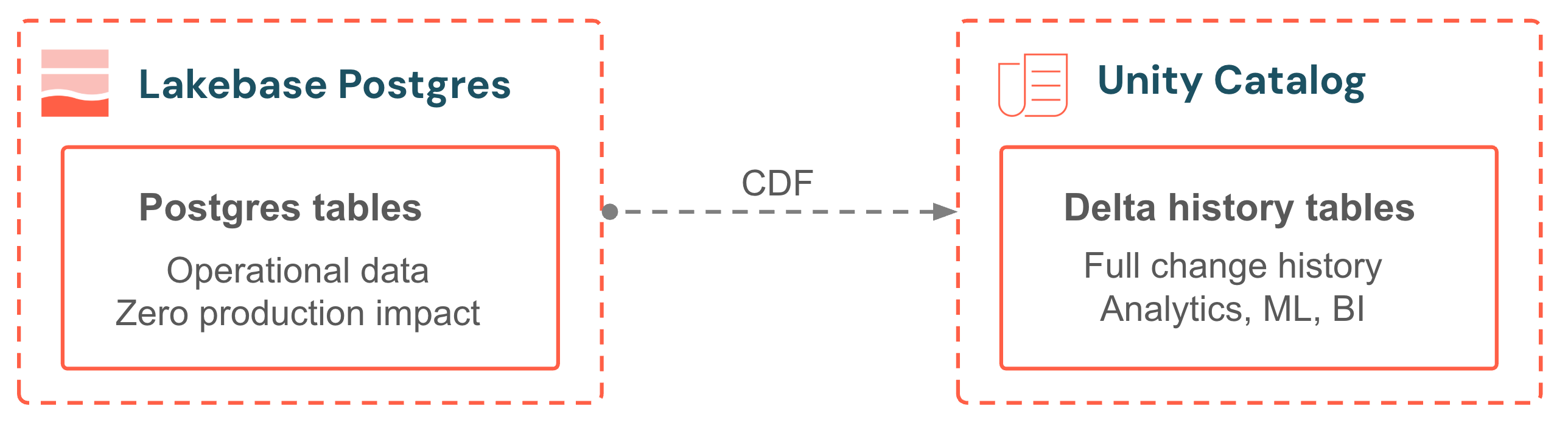
Lakebase Change Data Feed (CDF) armazena as alterações em nível de linha das suas tabelas Postgres como tabelas Delta gerenciadas Unity Catalog . Cada inserção, atualização e exclusão é capturada do log transações (write-ahead log) e gravada como uma nova linha em uma tabela de histórico Delta . Sem ferramentas externas CDC , sem tarefas Spark , sem pipeline para manter. A execução do caminho de captura ocorre em compute independente, portanto, as consultas de produção não são afetadas. A tabela de histórico tem o mesmo formato que Delta Change Data Feed, portanto, as consultas subsequentes de pipeline, visão materializada e auditoria se integram perfeitamente.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
Backend da aplicação
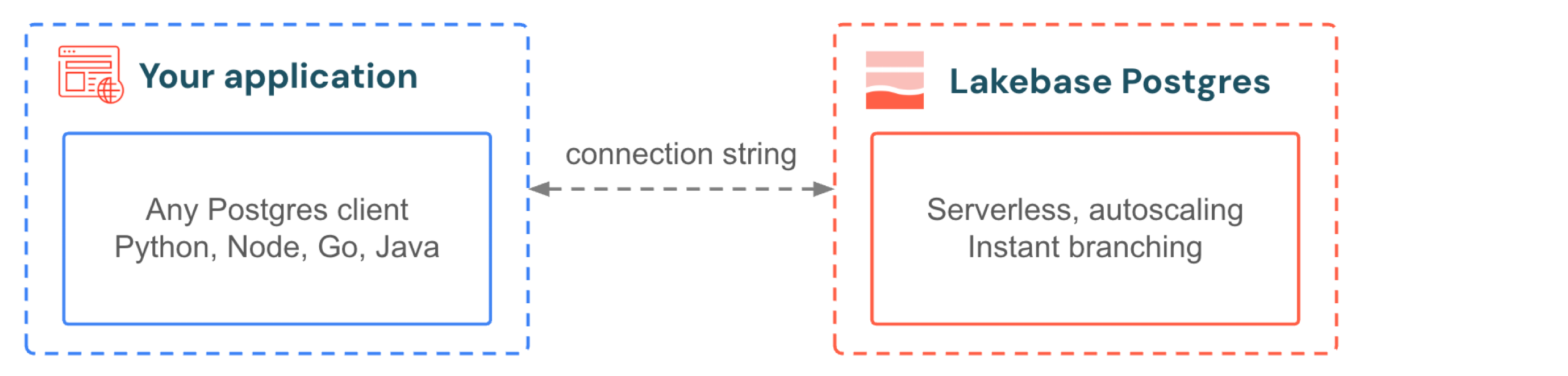
Seu aplicativo se conecta ao Lakebase da mesma forma que se conecta a qualquer banco de dados Postgres. Utilize os drivers e frameworks que você já conhece. Quando seu aplicativo recebe um pico de tráfego, o dimensionamento automático adiciona compute sem interromper as conexões. Quando o tráfego para, o recurso "escala-to-zero" suspende o banco de dados e o reativa em centenas de milissegundos na próxima consulta. Você não faz provisionamento para o pico e não paga pelo paraíso. Para o desenvolvimento, o branching fornece a cada desenvolvedor uma cópia isolada do banco de dados de produção, sem necessidade de preenchimento automático de dados, duplicação de armazenamento ou espera.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
|
AgentesAI e ML
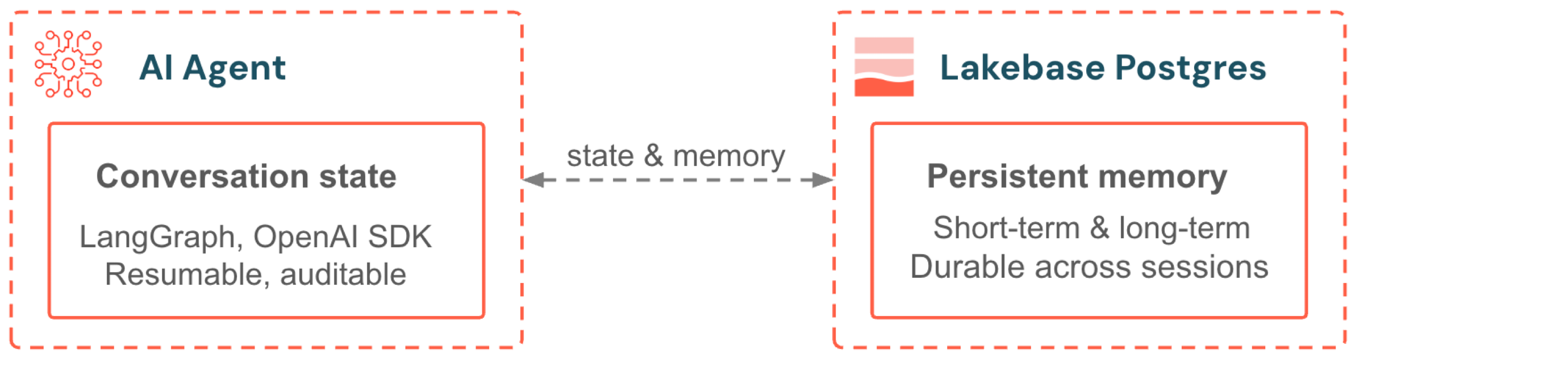
Lakebase serve como backend para a memória do agente AI e Feature Serving. Os agentes criados com LangGraph ou com o SDK de Agentes da OpenAI armazenam o estado da conversa e a memória de longo prazo no Postgres. Modelos atendidos com Mosaic AI acessam dados de recursos por meio de repositório de recursos on-line que são alimentados por autoescala Lakebase . Ambos se beneficiam de escalonamento automático, redução gradual de custos e governança Unity Catalog .
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
|