Trabalho falho ou executor removido
Portanto, o senhor está vendo um Job com falha ou um executor removido:
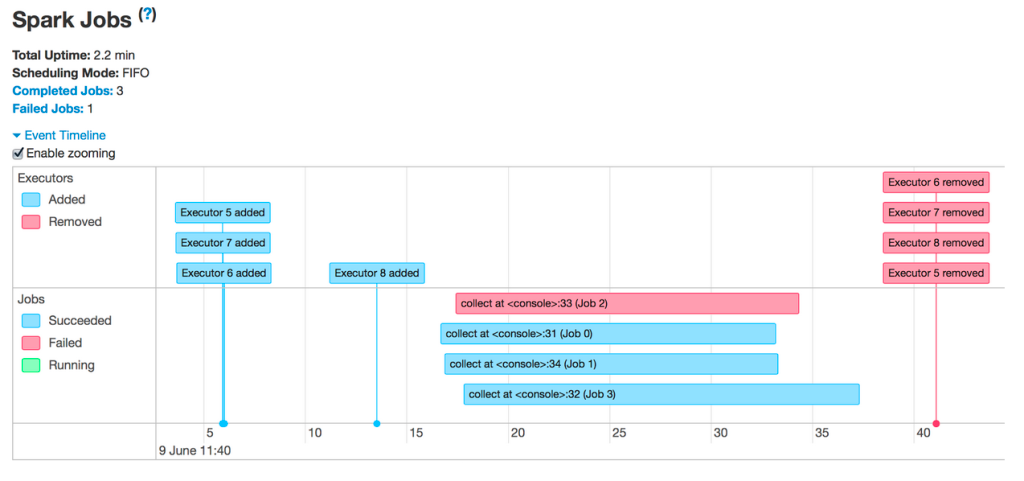
Os motivos mais comuns para a remoção do executor são:
- autoscale : Nesse caso, isso é esperado e não é um erro. Consulte Ativar escala automática.
- Detecte perdas de instâncias : o provedor de nuvem está recuperando suas VMs. Você pode saber mais sobre instâncias Spot aqui.
- O executor está ficando sem memória
Trabalho fracassado
Se o senhor vir algum trabalho com falha, clique nele para acessar suas páginas. Em seguida, role para baixo para ver o estágio de falha e o motivo da falha:
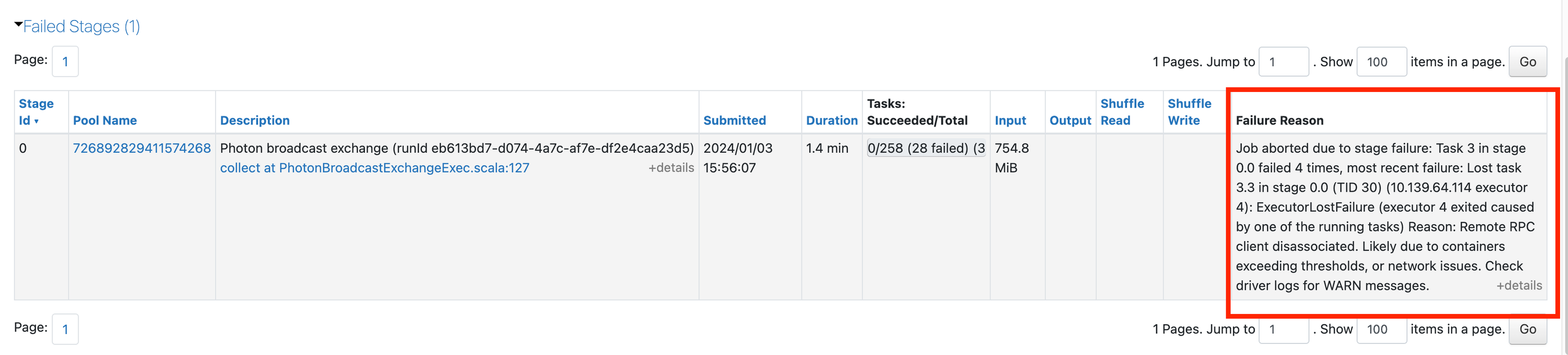
Você pode receber um erro genérico. Clique no link na descrição para ver se você pode obter mais informações:
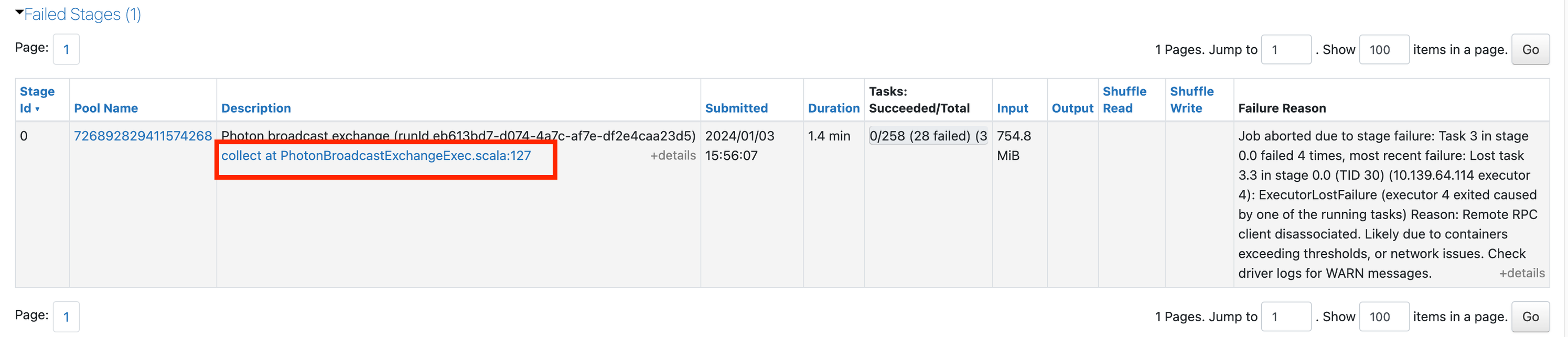
Se o senhor rolar a página para baixo, poderá ver por que cada tarefa falhou. Nesse caso, está ficando claro que há um problema de memória:

Executor falho
Para descobrir por que o executor está falhando, o senhor deve primeiro verificar o compute Event do site log para ver se há alguma explicação para a falha do executor. Por exemplo, é possível que você esteja usando instâncias spot e o provedor de nuvem as esteja recuperando.

Veja se há algum evento que explique a perda do executor. Por exemplo, o senhor pode ver mensagens indicando que o clustering está sendo redimensionado ou que instâncias pontuais estão sendo perdidas.
- Se você estiver usando instâncias spot, consulte Perder instâncias spot.
- Se o seu compute foi redimensionado com a escala automática, isso é esperado e não é um erro. Consulte Saiba mais sobre o redimensionamento de clusters.
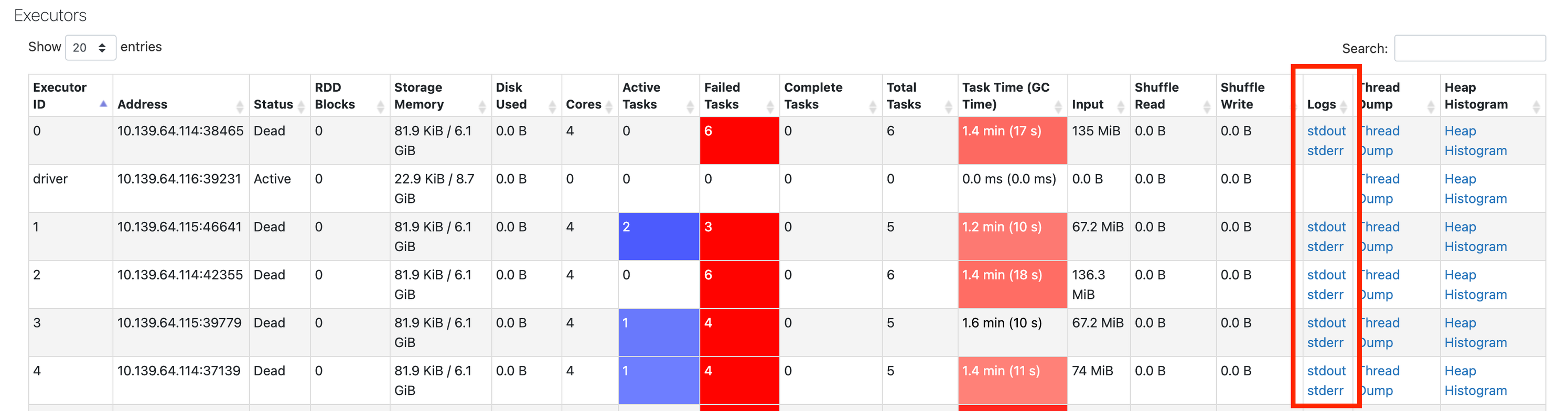
Se o senhor não encontrar nenhuma informação no evento log, volte para o site Spark UI e clique no executor tab:

Aqui o senhor pode obter o logs do executor que falhou:
Próxima etapa
Se você chegou até aqui, a explicação mais provável é um problema de memória. A próxima etapa é investigar os problemas de memória. Consulte Problemas de memória do Spark.