Conecte-se com o analista do Spotfire
Esta documentação foi descontinuada e pode não ser atualizada. O produto, serviço ou tecnologia mencionados neste conteúdo não são mais suportados. Consulte Conectores personalizados para Spotfire.
Este artigo descreve como usar o Spotfire Analista com um cluster Databricks ou um Databricks SQL Warehouse.
Requisitos
-
Um cluster ou SQL warehouse em seu workspace Databricks .
-
Os detalhes de conexão do seu cluster ou SQL warehouse, especificamente o nome do host do servidor , a porta e os valores do caminho HTTP .
-
Um access tokenpessoal Databricks . Para criar um access token pessoal, siga os passos descritos em Criar access tokens pessoal para usuários workspace.
Como prática recomendada de segurança ao autenticar com ferramentas, sistemas, scripts e aplicativos automatizados, a Databricks recomenda o uso de tokens OAuth.
Se você utiliza autenticação access token pessoal, Databricks recomenda o uso de access tokens pessoal pertencentes à entidade de serviço em vez de usuários workspace . Para criar tokens para entidade de serviço, consulte gerenciar tokens para uma entidade de serviço.
os passos para conectar
- No Spotfire Analista, na barra de navegação, clique no ícone de mais ( Arquivos e dados ) e clique em Conectar a .
- Selecione Databricks e clique em Nova conexão .
- Na caixa de diálogo Apache Spark SQL , na tab General , para Server , insira os valores do campo Server hostname e Port da passo 1, separados por dois pontos.
- Em Método de autenticação , selecione Nome de usuário e senha .
- Para o nome de usuário , digite a palavra
token. - Para Password , insira seus access tokens pessoal da passo 1.
- Na tab Avançado , para o modo de transporte Thrift , selecione HTTP .
- Para HTTP Path , insira o valor do campo HTTP Path da passo 1.
- Na tab Geral , clique em Conectar .
- Após estabelecer uma conexão bem-sucedida, na lista Banco de Dados , selecione o banco de dados que deseja usar e clique em OK .
Selecione os dados do Databricks que deseja analisar.
Você seleciona os dados na visualização na caixa de diálogo Conexão .
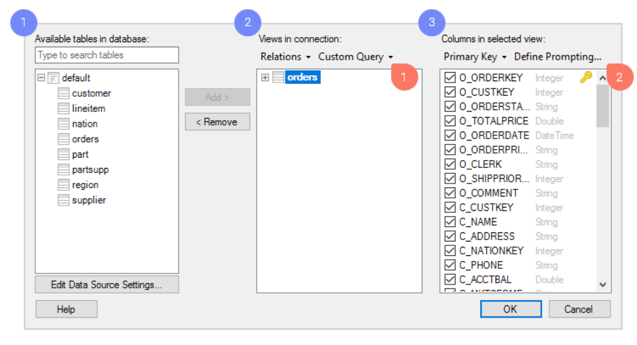
-
Navegue pelas tabelas disponíveis no Databricks.
-
Adicione as tabelas que deseja visualizar; essas serão as tabelas de dados que você analisará no Spotfire.
-
Para cada view, você pode decidir quais colunas deseja incluir. Se você deseja criar uma seleção de dados muito específica e flexível, você tem acesso a uma variedade de ferramentas poderosas nesta caixa de diálogo, tais como:
- Consultas personalizadas. Com consultas personalizadas, você pode selecionar os dados que deseja analisar digitando uma consulta SQL personalizada.
- Instrução. Deixe a seleção de dados a cargo do usuário do seu arquivo de análise. Você configura os prompts com base nas colunas de sua escolha. Em seguida, o usuário final que abrir a análise poderá selecionar a opção para limitar e view apenas os dados relevantes. Por exemplo, o usuário pode selecionar dados dentro de um determinado período de tempo ou para uma região geográfica específica.
-
Clique em OK .
Enviar consultas para o Databricks ou importar dados.
Depois de selecionar os dados que deseja analisar, a passo final é escolher como deseja recuperar os dados do Databricks. Um resumo das tabelas de dados que você está adicionando à sua análise é exibido e você pode clicar em cada tabela para alterar o método de carregamento de dados.
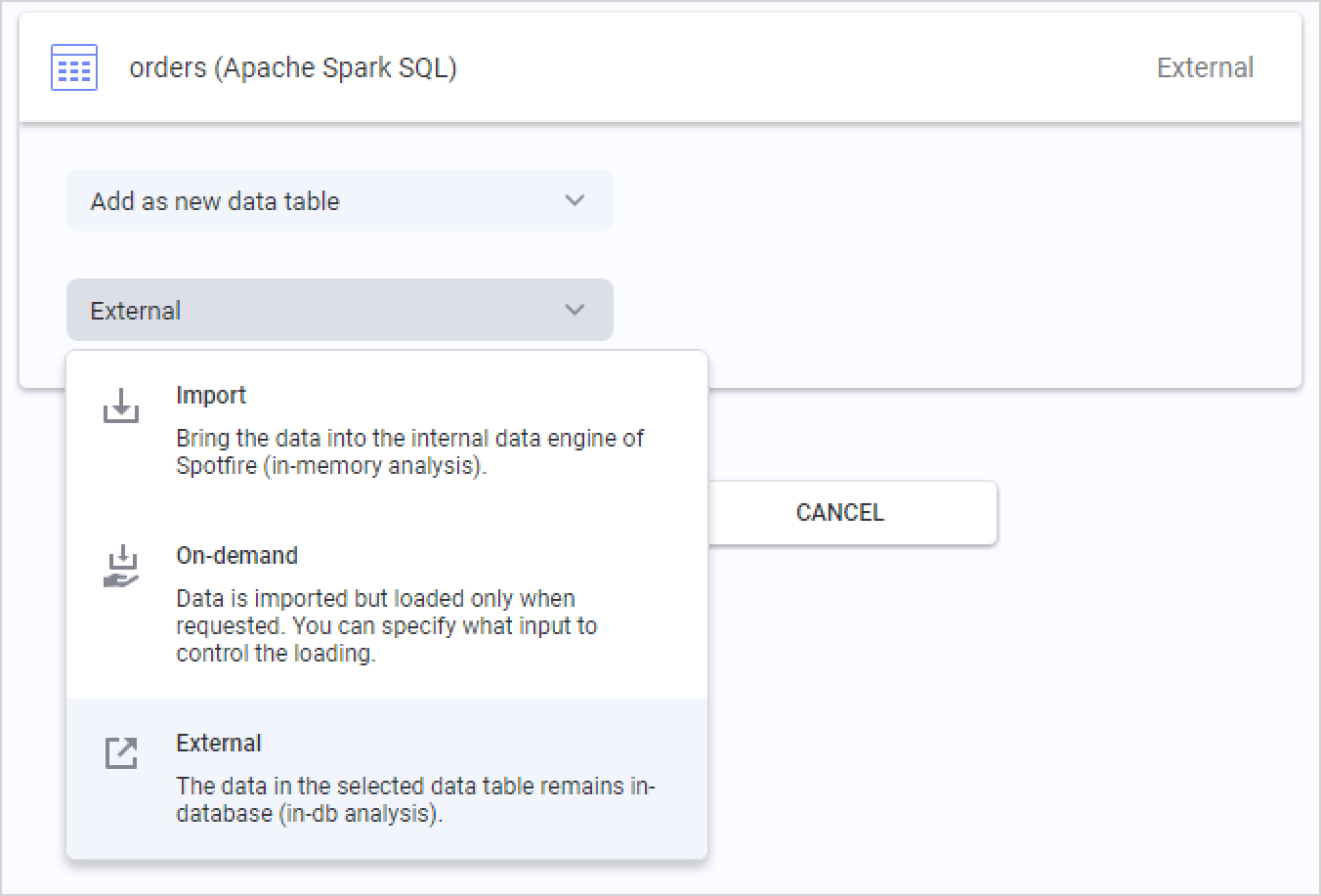
A opção default para Databricks é Externa . Isso significa que a tabela de dados é mantida no banco de dados Databricks, e o Spotfire envia diferentes consultas ao banco de dados para as fatias de dados relevantes, com base nas suas ações na análise.
Você também pode selecionar "Importado " e o Spotfire extrairá toda a tabela de dados antecipadamente, o que permite a análise local na memória. Ao importar tabelas de dados, você também utiliza funções analíticas no mecanismo de dados embutido na memória do TIBCO Spotfire.
A terceira opção é Sob demanda (correspondente a uma cláusula WHERE dinâmica), o que significa que fatias de dados serão extraídas com base nas ações do usuário na análise. Você pode definir os critérios, que podem ser ações como marcar ou filtrar dados, ou alterar propriedades do documento. O carregamento de dados sob demanda também pode ser combinado com tabelas de dados externas .