Exportar dados workspace
Esta página fornece uma visão geral das ferramentas e abordagens para exportar dados e configurações do seu workspace Databricks . Você pode exportar workspace Ativo para atender a requisitos compliance , portabilidade de dados, fins de backup ou migração workspace .
Visão geral
O espaço de trabalho Databricks contém uma variedade de recursos, incluindo configuração workspace , gerenciamento de tabelas, objetos AI e ML e dados armazenados no armazenamento cloud . Quando precisar exportar dados workspace , você pode usar uma combinação de ferramentas integradas e APIs para extrair esses dados ativos de forma sistemática.
Os motivos mais comuns para exportar dados workspace incluem:
- Requisitos de conformidade : Cumprir as obrigações de portabilidade de dados previstas em regulamentações como GDPR e o CCPA.
- Backup e recuperação de desastres : Criação de cópias de workspace críticos ativos para garantir a continuidade dos negócios.
- Migração de espaço de trabalho : Transferência do Ativo entre provedores de espaço de trabalho ou cloud .
- Auditoria e arquivamento : Preservação de registros históricos da configuração e dos dados workspace .
Planeje sua exportação
Antes de começar a exportar os dados workspace , crie um inventário dos ativos que você precisa exportar e entenda as dependências entre eles.
Compreender workspace ativo
Seu workspace Databricks contém diversas categorias de ativos que você pode exportar:
- Configuração do espaço de trabalho : Notebook, pastas, repositórios, segredos, usuários, grupos, listas de controle de acesso (ACLs), configurações cluster e definições de tarefas.
- Dados ativos : gerenciamento de tabelas, bancos de dados, arquivos Databricks File System e dados armazenados em armazenamento cloud .
- Computação de recursos : configurações de cluster, políticas e definições pool de instâncias.
- Ativos de AI e ML : experimentos do MLflow, execuções, modelos, tabelas do Feature Store, índices do AI Search e modelos do Unity Catalog.
- ObjetosUnity Catalog : configuração do Metastore, catálogos, esquemas, tabelas, volumes e permissões.
Defina o escopo da sua exportação.
Crie uma lista de verificação dos ativos a serem exportados com base em suas necessidades. Considere estas questões:
- Você precisa exportar todos os ativos ou apenas categorias específicas?
- Existem requisitos compliance ou segurança que determinam qual ativo você deve exportar?
- Você precisa preservar os relacionamentos entre ativos (por exemplo, um Job que faz referência a um Notebook)?
- Você precisa recriar a configuração workspace em outro ambiente?
Planejar o escopo da sua exportação ajuda você a escolher as ferramentas certas e a evitar negligenciar dependências críticas.
Exportar configuração workspace
O Terraform exporter é a principal ferramenta para exportar a configuração workspace . Ele gera arquivos de configuração Terraform que representam seu workspace ativo como código.
Use o exportador Terraform.
O exportador Terraform está integrado ao provedor Terraform Databricks e gera arquivos de configuração Terraform para recursos workspace , incluindo Notebooks, Jobs, clusters, usuários, grupos, segredos e listas de controle de acesso. O exportador deve ser executado separadamente para cada workspace. Consulte o provedor Terraform do Databricks.
Pré-requisitos:
- Terraform instalado em sua máquina
- Autenticação do Databricks configurada
- Privilégios de administrador no workspace que você deseja exportar.
Para exportar o recurso workspace :
-
Veja o vídeo de exemplo para uma demonstração prática do exportador.
-
Baixe e instale o provedor Terraform com a ferramenta de exportação:
Bashwget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|')
unzip -d terraform-provider-databricks terraform-provider-databricks.zip -
Configure a variável de autenticação de ambiente para seu workspace:
Bashexport DATABRICKS_HOST=https://your-workspace-url
export DATABRICKS_TOKEN=your-token -
Execute o exportador para gerar arquivos de configuração Terraform :
Bashterraform-provider-databricks exporter \
-directory ./exported-workspace \
-listing notebooks,jobs,clusters,users,groups,secretsOpções comuns de exportação:
-listing: Especifique os tipos de recursos a serem exportados (separados por vírgulas)-services: Alternativa à listagem para filtrar recursos-directoryDiretório de saída para os arquivos.tfgerados-incremental: execução em modo incremental para migrações em estágios
-
Analise os arquivos
.tfgerados no diretório de saída. O exportador cria um arquivo para cada tipo de recurso.
O exportador Terraform concentra-se na configuração workspace e nos metadados. Não exporta os dados reais armazenados em tabelas ou no sistema de arquivos do Databricks. Você deve exportar os dados separadamente usando as abordagens descritas nas seções a seguir.
Exportar tipos ativos específicos
Para o Ativo que não é totalmente coberto pelo exportador Terraform , use estas abordagens:
- Notebook : faça o download de Notebooks individualmente a partir da interface do usuário workspace ou use a API do espaço de trabalho para exportar Notebooks programaticamente. Consulte Gerenciar objetos workspace.
- Segredos : Por motivos de segurança, os segredos não podem ser exportados diretamente. Você deve recriar manualmente os segredos no ambiente de destino. Documente os nomes e escopos secretos para referência.
- ObjetosMLflow : Utilize a ferramenta mlflow-export-import para exportar experimentos, execuções e modelos. Veja a seçãoML ativo abaixo.
Exportar dados
Os dados do cliente normalmente ficam armazenados na sua account cloud , e não no Databricks. Você não precisa exportar dados que já estão armazenados na sua cloud . No entanto, você precisa exportar os dados armazenados em locais Databricks-gerenciar.
Exportar tabelas
Embora as tabelas � residam no seu armazenamento cloud , elas são armazenadas em uma hierarquia baseada em UUID que pode ser difícil de analisar. Você pode usar o comando DEEP CLONE para reescrever tabelas gerencia como tabelas externas em um local especificado, tornando-as mais fáceis de trabalhar.
Exemplo de comando DEEP CLONE :
CREATE TABLE delta.`s3://path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Para obter um script completo para clonar todas as tabelas em uma lista de catálogos, consulte o script de exemplo abaixo.
Exportar armazenamento default Databricks
Para espaços de trabalho serverless , Databricks oferece armazenamento default , que é uma solução de armazenamento totalmente gerenciada dentro da account Databricks . Os dados armazenados por default devem ser exportados para contêineres de armazenamento de propriedade do cliente antes da exclusão ou desativação workspace . Para obter mais informações sobre espaços de trabalho serverless , consulte Criar um workspace serverless.
Para tabelas no armazenamento default , use DEEP CLONE para gravar dados em um contêiner de armazenamento de propriedade do cliente. Para volumes e arquivos arbitrários, siga os mesmos padrões descritos na seção de exportaçãoDBFS root abaixo.
Exportar raiz do sistema de arquivos Databricks
Para novos fluxos de trabalho, o Databricks recomenda armazenar dados em volumes do Unity Catalog ou Sistema de Arquivos do Workspace em vez do Databricks File System. Esta página documenta a exportação do Sistema de Arquivos Databricks para usuários com dados existentes do Sistema de Arquivos Databricks.
O diretório raiz do sistema de arquivos Databricks é o local de armazenamento legado no bucket de armazenamento do seu workspace , que pode conter ativos de propriedade do cliente, uploads de usuários, scripts de inicialização, bibliotecas e tabelas. Embora o diretório raiz do sistema de arquivos Databricks seja um padrão de armazenamento obsoleto, espaços de trabalho legados ainda podem conter dados armazenados nesse local que precisam ser exportados. Para obter mais informações sobre a arquitetura de armazenamento workspace , consulte Armazenamento do espaço de trabalho.
Exportar bucket raiz do sistema de arquivos Databricks :
Use a AWS CLI para sincronizar os dados do bucket de armazenamento do seu workspace Databricks para o bucket de exportação:
# Export from DBFS root bucket to export bucket
aws s3 sync s3://databricks-workspace-bucket/dbfs/ s3://export-bucket/dbfs-export/
Se o bucket raiz do seu Databricks File System usa criptografia do lado do servidor com AWS KMS, certifique-se de que o bucket de exportação tenha a configuração de criptografia e as permissões adequadas para acessar a key KMS .
A exportação de grandes volumes de dados do armazenamento cloud pode acarretar custos significativos de transferência e armazenamento de dados. Antes de iniciar exportações em grande escala, verifique os preços do seu provedor cloud .
Desafios comuns de exportação
Criptografia de bucket:
Se o bucket de armazenamento do seu workspace usa criptografia do lado do servidor, existem várias abordagens:
- Criptografia padrão S3 : S3 criptografa todos os dados por default. Isso é transparente para os usuários, portanto, nenhuma etapa adicional é necessária.
- CriptografiaKMS com AWS- gerenciamento key : AWS gerencia a key, a criptografia e a descriptografia. Nenhum passo adicional é necessário.
- CriptografiaKMS com key KMS personalizada : A criptografia é gerenciada pelo S3, mas você precisa de permissões para acessar a key e ler os dados no bucket. Certifique-se de que você pode acessar a mesma key no bucket de destino e que seu bucket de exportação tenha a configuração de criptografia apropriada.
Segredos:
Por motivos de segurança, os segredos não podem ser exportados diretamente. Ao usar o exportador Terraform com a opção -export-secrets , o exportador gera uma variável em vars.tf com o mesmo nome do segredo. Você deve atualizar manualmente este arquivo com os valores secretos reais ou executar o exportador Terraform com a opção -export-secrets (somente para Databricks-gerenciar secrets).
Exportar AI e ML ativo
Algumas atividades de AI e ML exigem ferramentas e abordagens diferentes para exportação. Os modelos do Unity Catalog são exportados como parte do exportador Terraform.
Objetos MLflow
O MLflow não é contemplado pelo exportador Terraform devido a lacunas na API e dificuldades com a serialização. Para exportar experimentos, execuções, modelos e artefatos MLflow , utilize a ferramenta mlflow-export-import . Esta ferramenta de código aberto oferece uma cobertura quase completa da migração para o MLflow.
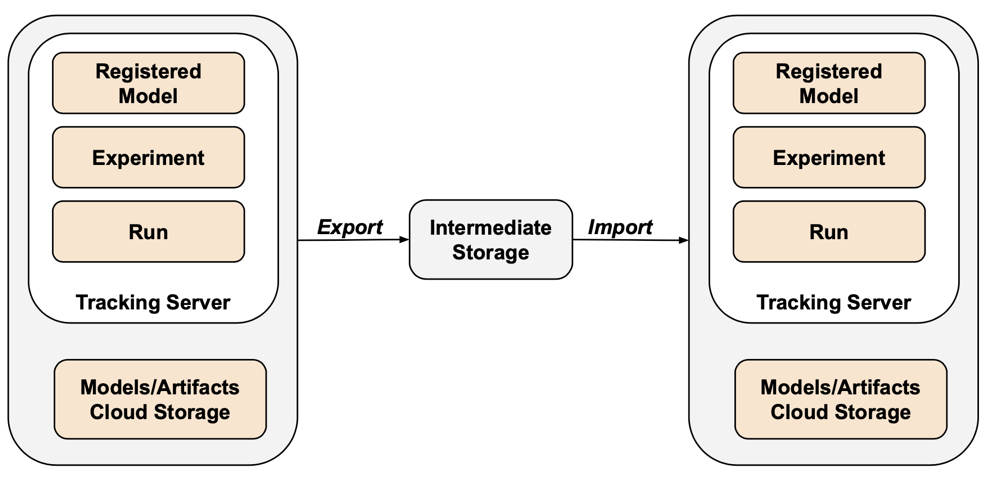
Para cenários que envolvam apenas exportação, você pode armazenar todos os ativos MLflow em um bucket de propriedade do cliente sem precisar realizar a importação ou o passo. Para obter mais informações sobre o gerenciamento MLflow , consulte gerenciar o ciclo de vida do modelo no Unity Catalog.
Feature Store e Pesquisa de AI
Índices de Pesquisa de AI : Os índices de Pesquisa de AI não estão no escopo dos procedimentos de exportação de dados da UE. Se você ainda quiser exportá-los, eles devem ser escritos em uma tabela padrão e depois exportados usando DEEP CLONE.
Tabelas da Feature Store : A Feature Store deve ser tratada de forma semelhante aos índices de pesquisa de AI. Usando SQL, selecione os dados relevantes e grave-os em uma tabela padrão e, em seguida, exporte usando DEEP CLONE.
Validar dados exportados
Após exportar os dados workspace , verifique se os trabalhos, usuários, notebooks e outros recursos foram exportados corretamente antes de desativar o ambiente antigo. Utilize a lista de verificação que você criou durante a fase de definição de escopo e planejamento para verificar se tudo o que você esperava exportar foi exportado com sucesso.
Lista de verificação
Utilize esta lista de verificação para confirmar sua exportação:
- Arquivos de configuração gerados : Os arquivos de configuração Terraform são criados para todos os recursos workspace necessários.
- Notebooks exportados : Todos os notebooks foram exportados com seu conteúdo e metadados intactos.
- Tabelas clonadas : as tabelas foram clonadas com sucesso para o local de exportação.
- Arquivos de dados copiados : os dados armazenados na nuvem são copiados integralmente, sem erros.
- ObjetosMLflow exportados : Experimentos, execuções e modelos são exportados juntamente com seus artefatos.
- Permissões documentadas : As listas de controle de acesso e as permissões são registradas na configuração do Terraform.
- Dependências identificadas : Os relacionamentos entre ativos (por exemplo, um Job referenciando um Notebook) são preservados na exportação.
Boas práticas pós-exportação
Os testes de validação e aceitação são amplamente definidos pelos seus requisitos e podem variar bastante. No entanto, estas boas práticas gerais se aplicam:
- Defina um ambiente de teste : Crie um ambiente de teste, seja um Job ou um Notebook, que valide se os segredos, dados, montagens, conectores e outras dependências estão funcionando corretamente no ambiente exportado.
- Comece com ambientes de desenvolvimento : Se a migração for feita em etapas, comece com o ambiente de desenvolvimento e vá progredindo até chegar ao ambiente de produção. Isso permite identificar problemas importantes logo no início e evita impactos na produção.
- Aproveite as pastas do Git : Quando possível, utilize pastas do Git, pois elas residem em um repositório Git externo. Isso evita a exportação manual e garante que o código seja idêntico em todos os ambientes.
- Documente o processo de exportação : registre as ferramentas utilizadas, os comandos executados e quaisquer problemas encontrados.
- Proteja os dados exportados : Garanta que os dados exportados sejam armazenados com segurança e com controles de acesso adequados, especialmente se contiverem informações sensíveis ou de identificação pessoal.
- Manter compliance : Se a exportação for para fins compliance , verifique se ela atende aos requisitos regulamentares e às políticas de retenção.
Exemplos de scripts e automação
Você pode automatizar a exportação workspace usando scripts e tarefas agendadas.
Script de exportação Deep Clone
O seguinte script exporta tabelas gerenciadas Unity Catalog usando DEEP CLONE. Este código deve ser executado no workspace de origem para exportar um determinado catálogo para um bucket intermediário. Atualize as variáveis catalogs_to_copy e dest_bucket .
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Considerações sobre automação
Ao automatizar as exportações:
- Utilizar tarefa agendada : Crie uma tarefa Databricks que execute scripts de exportação em uma programação regular.
- Monitorar tarefa de exportação : configure um alerta para ser notificado caso as exportações falhem ou demorem mais do que o esperado.
- Gerenciar credenciais : Armazene credenciais de armazenamento cloud e tokens API com segurança usando segredos Databricks . Veja Gestão Secreta.
- Exportação de versões : Use carimbos de data/hora ou números de versão nos caminhos de exportação para manter o histórico de exportações.
- Limpe as exportações antigas : Implemente políticas de retenção para excluir exportações antigas e gerenciar os custos de armazenamento.
- Exportações incrementais : Para espaços de trabalho grandes, considere implementar exportações incrementais que exportem apenas os dados alterados desde a última exportação.