Perfil de consulta
Você pode usar um perfil de consulta para visualizar os detalhes da execução de uma consulta. O perfil da consulta ajuda o senhor a solucionar problemas de gargalos de desempenho durante a execução da consulta. Por exemplo:
- O senhor pode visualizar cada operador de consulta e as métricas relacionadas, como o tempo gasto, o número de linhas processadas, as linhas processadas e o consumo de memória.
- Você pode identificar rapidamente a parte mais lenta da execução de uma consulta e avaliar os impactos das modificações na consulta.
- O senhor pode descobrir e corrigir erros comuns nas instruções do site SQL, como junções explosivas ou varreduras de tabelas completas.
Requisitos
Para view um perfil de consulta, o senhor deve ser o proprietário da consulta ou deve ter pelo menos a permissão CAN MONITOR no site SQL warehouse que executou a consulta.
visualizar um perfil de consulta
O senhor pode acessar view o perfil de consulta do histórico de consultas usando as seguintes etapas:
-
Clique em
 Query History (Histórico de consultas ) na barra lateral.
Query History (Histórico de consultas ) na barra lateral. -
Clique no nome de uma consulta. Um painel de detalhes da consulta aparece no lado direito da tela.
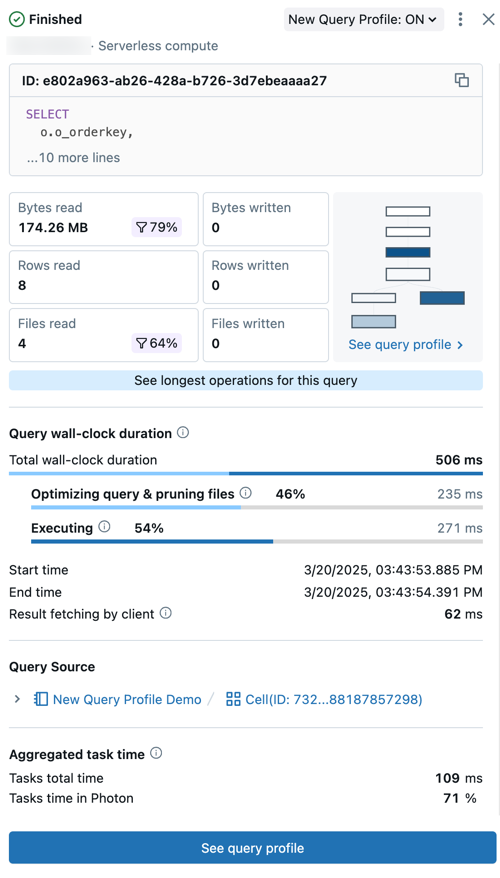
O resumo da consulta inclui:
- Status da consulta: A consulta é marcada com seu status atual: Emfila, em execução, concluída, com falha ou cancelada.
- Detalhes do usuário e compute: Veja o nome de usuário, o tipo de compute e os detalhes do tempo de execução dessa consulta.
- ID: Esse é o identificador universal exclusivo (UUID) associado à execução de determinada consulta.
- Declaração de consulta: esta seção inclui a instrução de consulta completa. Se a consulta for muito longa para ser exibida na visualização, clique em ... more lines (mais linhas ) para view o texto completo.
- Métricas de consulta: As métricas populares para análise de consultas são mostradas sob o texto da consulta. Os ícones de filtro que aparecem com algumas métricas indicam a porcentagem de dados eliminados durante a varredura.
- Consulte perfil de consulta: Uma visualização do gráfico acíclico direcionado (DAG) do perfil de consulta é mostrada neste resumo. Isso pode ser útil para estimar rapidamente a complexidade da consulta e o fluxo de execução. Clique em Ver perfil de consulta para abrir o DAG detalhado.
- Veja os operadores mais longos para esta consulta: Clique nesse botão para abrir o painel Principais operadores . Esse painel mostra os operadores de execução mais longa na consulta.
- Duração do relógio de parede da consulta: O tempo total decorrido entre o início do programar e o final da execução da consulta é fornecido como um resumo. Uma análise detalhada da programação, da otimização de consultas e da poda de arquivos, bem como do tempo de execução, aparece abaixo do resumo.
- Fonte da consulta: clique no nome do objeto listado para acessar a fonte da consulta.
- Tempo de tarefa agregado: visualize o tempo combinado que levou para executar a consulta em todos os núcleos de todos os nós. Ela pode ser significativamente mais longa do que a duração do relógio de parede se várias tarefas forem executadas em paralelo. Ela pode ser mais curta do que a duração do relógio de parede se a tarefa esperar por nós disponíveis.
- Entrada/Saída (IO): exibe detalhes sobre os dados lidos e gravados durante a execução da consulta.
-
Clique em Ver perfil de consulta . Um painel de detalhes é aberto no lado direito da tela.
Se o perfil de consulta não estiver disponível for exibido, nenhum perfil estará disponível para essa consulta. Um perfil de consulta não está disponível para consultas que são executadas a partir do cache de consultas. Para contornar o cache de consultas, faça uma alteração trivial na consulta, como alterar ou remover o LIMIT.
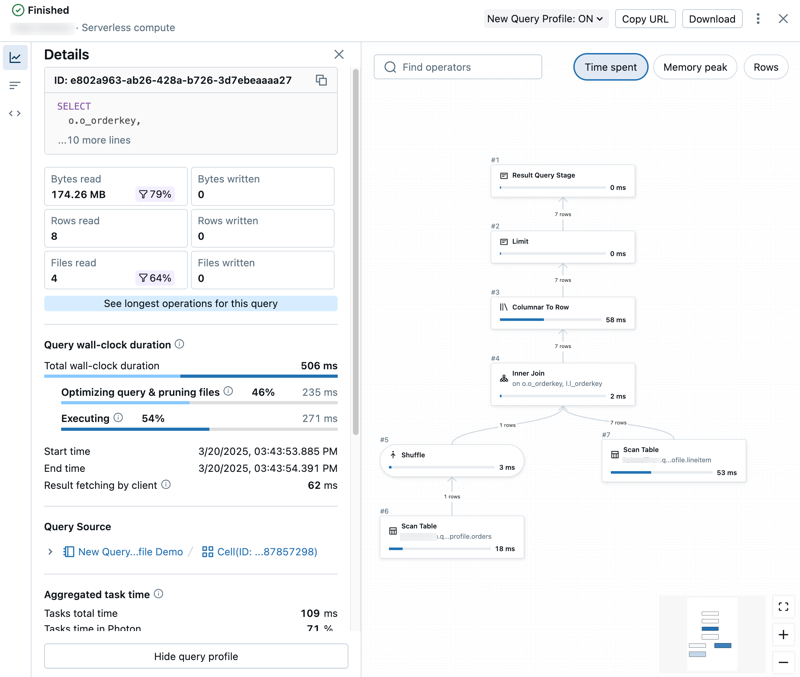
visualizar detalhes do perfil de consulta
O perfil de consulta detalhado inclui métricas resumidas no lado esquerdo do painel e um gráfico view das operadoras no lado direito.
Explorar métricas de consulta
O lado esquerdo do perfil de consulta tem a seguinte guia:
-
 Detalhes : Abre o painel Details (Detalhes ) que mostra as métricas de resumo da consulta.
Detalhes : Abre o painel Details (Detalhes ) que mostra as métricas de resumo da consulta. -
Principais operadores: abre o painel Principais operadores , que mostra os operadores mais caros usados em sua consulta. Isso pode ser útil para identificar oportunidades de otimização.
-
 Texto da consulta: abre o painel de texto da consulta , que mostra o texto completo da consulta.
Texto da consulta: abre o painel de texto da consulta , que mostra o texto completo da consulta.
Algumas operações que não são de fótons são executadas como um grupo e compartilham métricas comuns. Nesse caso, todas as operações têm o mesmo valor que o operador principal para uma determinada métrica.
Explore o DAG
A metade direita do perfil da consulta mostra o gráfico acíclico direcionado (DAG) da consulta. O gráfico view mostra métricas como tempo gasto , pico de memória e linhas . Clique em cada métrica para alterar as métricas de relatório exibidas.
Você pode interagir com o DAG das seguintes formas:
- Use a barra de pesquisa para destacar diferentes operadores ou colunas.
- Aumente ou diminua o zoom e foque em diferentes partes do DAG.
- Clique nos operadores para exibir métricas e descrições detalhadas. Um painel no lado direito do gráfico mostra os detalhes das operações.
Para consultas sobre o Databricks SQL, você também pode enviar um e-mail para view com o perfil da consulta em Spark UI. Clique no menu kebab “ ![]() ” na parte superior da página e, em seguida, clique em “Open in Spark UI ”.
” na parte superior da página e, em seguida, clique em “Open in Spark UI ”.
Em default, as métricas de algumas operações estão ocultas. É improvável que essas operações sejam a causa dos gargalos de desempenho. Para ver as informações de todas as operações e ver as métricas adicionais, clique em ![]() na parte superior da página e, em seguida, clique em Enable verbose mode (Ativar modo detalhado ).
na parte superior da página e, em seguida, clique em Enable verbose mode (Ativar modo detalhado ).
Operações comuns
As operações mais comuns são:
- Escanear : os dados foram lidos de uma fonte de dados e exibidos como linhas.
- junção : As linhas de várias relações foram combinadas (intercaladas) em um único conjunto de linhas.
- União : linhas de várias relações que usam o mesmo esquema foram concatenadas em um único conjunto de linhas.
- Shuffle: os dados foram redistribuídos ou reparticionados. As operações de embaralhamento são caras em relação ao recurso porque movem os dados entre os executores no clustering.
- Hash / Classificação : As linhas foram agrupadas por um key e avaliadas usando uma função agregada, como
SUM,COUNTouMAXem cada grupo. - Filtro : a entrada é filtrada de acordo com um critério, como por meio de uma cláusula
WHERE, e um subconjunto de linhas é retornado.
Percepções de desempenho
Beta
Este recurso está em Beta. Os administradores do espaço de trabalho podem controlar o acesso a esse recurso na página Pré-visualizações . Consulte Gerenciar prévias do Databricks.
Quando as consultas são executadas, a Databricks pode retornar percepções de desempenho que identifiquem oportunidades para melhorar o desempenho das consultas. O perfil de consulta apresenta percepções em dois locais:
- O painel de detalhes da consulta mostra um resumo das percepções mais impactantes, classificadas pelo seu efeito projetado na duração total da tarefa.
- A tab Percepções de desempenho no perfil de query detalhado mostra todos os detalhes para cada percepção.
Para a lista de percepções compatíveis e seus significados, consulte Percepções de desempenho de query.
Otimizar com Genie Code
Quando uma consulta tiver percepções acionáveis, selecione **Otimizar** para abrir o Genie Code. Para uma percepção que exige uma alteração na query, o Genie Code reescreve a query e apresenta as alterações para a sua aprovação. Para uma percepção que envolve alterações de tabela ou de compute, o Genie Code resume as ações recomendadas como texto em linguagem natural.
Para saber mais sobre como trabalhar com o Genie Code, consulte Genie Code.
Compartilhar um perfil de consulta
Para compartilhar um perfil de consulta com outro usuário:
- visualizar o histórico da consulta.
- Clique no nome da consulta.
- Para compartilhar a consulta, você tem duas opções:
- Se o outro usuário tiver a permissão CAN MANAGE na consulta, o senhor poderá compartilhar com ele o URL do perfil da consulta. Clique em Compartilhar . O URL é copiado para sua prancheta.
- Caso contrário, se o outro usuário não tiver a permissão CAN MANAGE ou não for membro do workspace, o senhor poderá download o perfil de consulta como um objeto JSON. Faça o download . O arquivo JSON é baixado em seu sistema local.
Importar um perfil de consulta
Para importar o JSON de um perfil de consulta:
-
visualizar o histórico da consulta.
-
Clique no menu kebab
 no canto superior direito e selecione Import query profile (JSON) .
no canto superior direito e selecione Import query profile (JSON) . -
No navegador de arquivos, selecione o arquivo JSON que foi compartilhado com o senhor e clique em Open (Abrir ). O arquivo JSON é carregado e o perfil de consulta é exibido.
Quando o senhor importa um perfil de consulta, ele é carregado dinamicamente na sessão do navegador e não persiste no site workspace. O senhor precisa reimportá-lo sempre que quiser acessá-lo em view.
-
Para fechar o perfil query importado, clique em X na parte inicio da página.
Acesse o perfil de consulta
Você também pode acessar o perfil de consulta nas seguintes partes da interface do usuário:
-
No editor SQL : Durante e após a execução da consulta, um link próximo à parte inferior da página exibe o tempo decorrido e o número de linhas retornadas. Clique nesse link para abrir o painel de detalhes da consulta . Clique em Ver perfil de consulta .

Se o senhor tiver o novo editor SQL ativado (Public Preview), seu link aparecerá como em um Notebook.
-
A partir de um Notebook : Se o Notebook estiver anexado a um SQL warehouse ou serverless compute, o senhor poderá acessar o perfil da consulta usando o link abaixo da célula que contém a consulta. Clique em Ver desempenho para abrir o histórico de execução. Clique em uma declaração para abrir o painel de detalhes da consulta .

-
Na interface do usuário dos LakeFlow Pipelines : Você pode acessar o histórico de queries e o perfil na tab Query History da interface do usuário do pipeline. Consulte Acessar o histórico de query para pipeline.
-
Na interface do usuário do trabalho : O senhor pode acessar os perfis de consulta para a execução do trabalho no armazém SQL e serverless compute. Para a execução do trabalho em serverless compute, consulte Visualizar detalhes da consulta para a execução do trabalho para saber como view detalhes da consulta na interface do usuário do trabalho.
Próximas etapas
- Saiba mais sobre como acessar métricas de consulta usando o histórico de consultas API
- Saiba mais sobre o histórico de consultas