Acompanhamento de progresso assíncrono
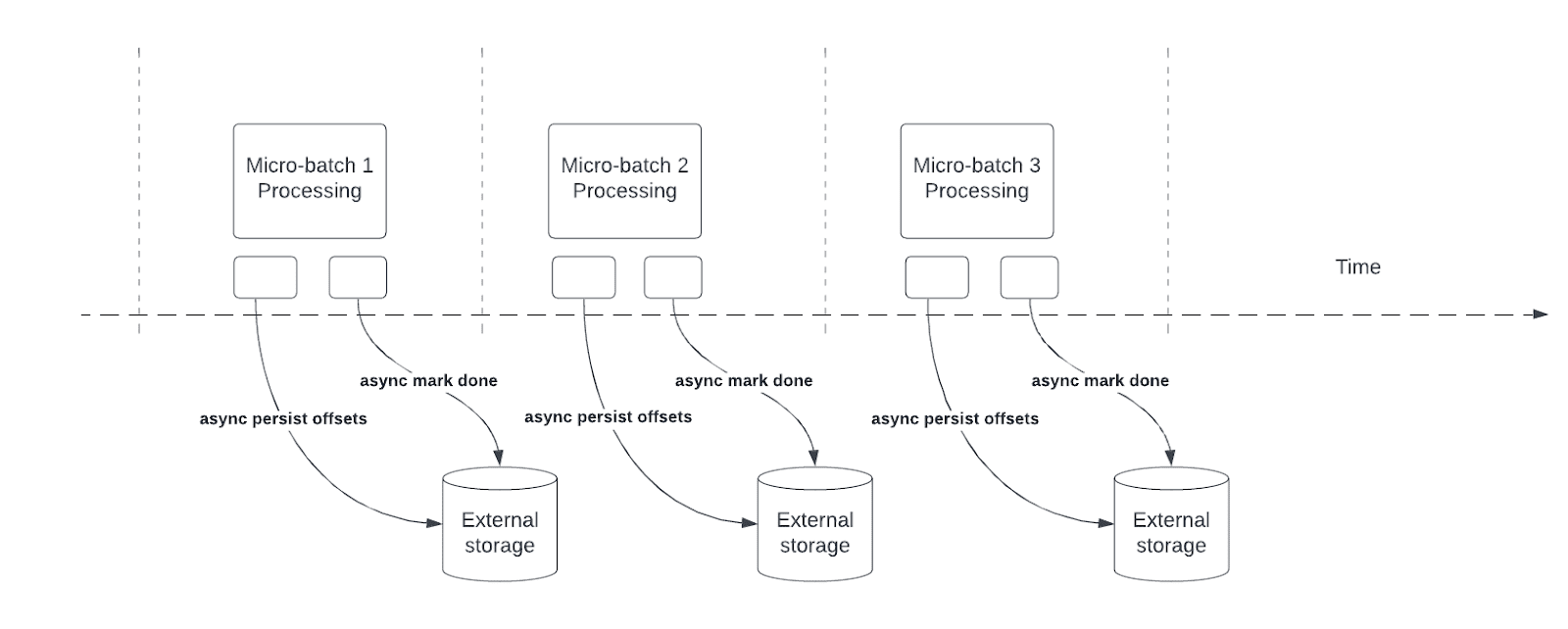
O acompanhamento assíncrono do progresso reduz a latência para o pipeline de transmissão estruturada, permitindo que as consultas atualizem assincronamente o progresso do ponto de verificação e processem os dados em cada microlote.
Durante o processamento da consulta, a transmissão estruturada persiste e gerencia offsets para medir o progresso da consulta em offsetLog e commitLog em cada microlote. Sem acompanhamento assíncrono do progresso, as operações de gerenciamento de deslocamento afetam diretamente a latência de processamento, pois o processamento de dados não pode continuar até que sejam concluídas.
O acompanhamento de progresso assíncrono não é compatível com gatilhos Trigger.once ou Trigger.availableNow . Se ativada, as consultas de transmissão estruturada com Trigger.once ou Trigger.availableNow falham.
Opções de configuração
Opção | Padrão | Descrição |
|---|---|---|
|
| Ativar ou não o acompanhamento de progresso assíncrono. |
|
| O intervalo em milissegundos entre as escritas de offsets e a confirmação de conclusão. |
Habilitar acompanhamento de progresso assíncrono
Para ativar o acompanhamento assíncrono do progresso, defina asyncProgressTrackingEnabled como true:
- Python
- Scala
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Melhore a taxa de transferência com frequência de checkpoint
A frequência de checkpoint default de 1000 milissegundos tem boa taxa de transferência para a maioria das consultas. Quando as operações de gerenciamento de deslocamento ocorrem mais rapidamente do que o acompanhamento de progresso assíncrono consegue processá-las, cria-se um acúmulo de operações de gerenciamento de deslocamento. Para evitar que o acúmulo de tarefas aumente ainda mais, o acompanhamento assíncrono do progresso pode bloquear ou retardar o processamento de dados, potencialmente comprometendo os benefícios esperados em termos de latência.
Nesse cenário, a Databricks recomenda que você aumente o intervalo de checkpoint:
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
O tempo de recuperação em caso de falha aumenta com o intervalo de tempo entre os pontos de verificação. Em caso de falha, um pipeline deve reprocessar todos os dados desde o último ponto de verificação bem-sucedido. Antes de implementar essa alteração em produção, considere a relação entre menor latência durante o processamento normal e o tempo de recuperação em caso de falha.
Desativar acompanhamento de progresso assíncrono
Quando o acompanhamento assíncrono do progresso está ativado, a transmissão não garante o progresso do ponto de verificação para todos os lotes. Você precisa salvar seu progresso antes de poder desativar esse recurso.
Para desligar, siga estes passos:
- Processe pelo menos dois micro-lotes com
asyncProgressTrackingEnableddefinido comotrueeasyncProgressTrackingCheckpointIntervalMsdefinido como0:
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start()
- Interrompa a consulta:
- Python
- Scala
query.stop()
query.stop()
- Desative o acompanhamento assíncrono do progresso e reinicie a consulta:
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
Se você desativar o acompanhamento assíncrono do progresso sem seguir os passos acima, poderá encontrar o seguinte erro:
java.lang.IllegalStateException: batch x doesn't exist
Nos logs do driver, o senhor pode ver o seguinte erro:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitações
- Para coletores Kafka , o acompanhamento de progresso assíncrono suporta apenas pipelines sem estado.
- O acompanhamento de progresso assíncrono não garante o processamento de ponta a ponta exatamente uma vez, porque os intervalos de deslocamento para um lote podem mudar em caso de falha. Algumas plataformas de coleta de dados, como o Kafka, nunca oferecem garantias de entrega "exatamente uma vez".