Visualizações antigas
Este artigo descreve visualizações legadas Databricks . Consulte a seção Visualizações no Databricks Notebook e no editor SQL para obter informações sobre o suporte atual para visualização ao criar visualizações no editor SQL ou em um Notebook. Para obter informações sobre como trabalhar com visualizações em painéis de AI/BI , consulte Tipos de visualizaçãoAI/BI dashboard.
Databricks também oferece suporte nativo a biblioteca de visualização em Python e R e permite que o senhor instale e use biblioteca de terceiros.
Crie uma visualização legada
Para criar uma visualização legada a partir de uma célula de resultados, clique em + e selecione Visualização herdada .
As visualizações legadas suportam um conjunto rico de tipos de gráficos:
Escolha e configure um tipo de gráfico legado
Para escolher um gráfico de barras, clique no ícone do gráfico de barras ![]() :
:

Para escolher outro tipo de gráfico, clique em ![]() à direita do gráfico de barras
à direita do gráfico de barras ![]() e escolha o tipo de gráfico.
e escolha o tipo de gráfico.
Barra de ferramentas de gráficos antigos
Os gráficos de linhas e de barras têm uma barra de ferramentas integrada que suporta um rico conjunto de interações no lado do cliente.
Para configurar um gráfico, clique em graficar Options....
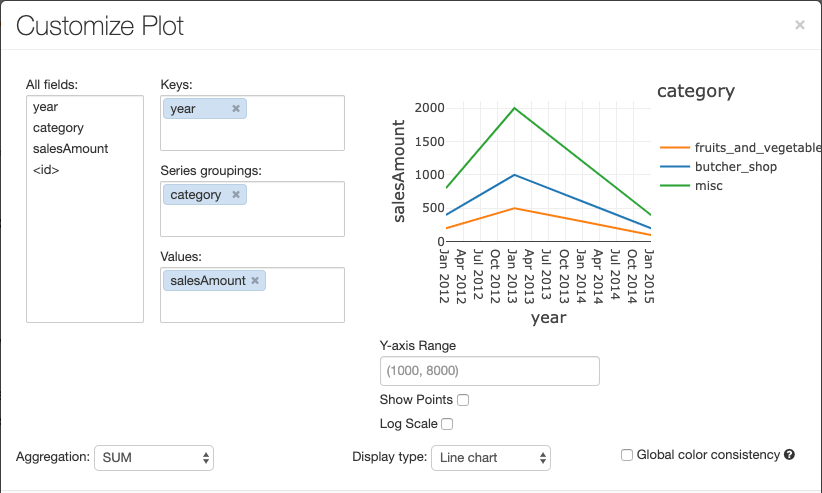
O gráfico de linhas tem algumas opções de gráfico personalizado: definir um intervalo do eixo Y, mostrar e ocultar pontos e exibir o eixo Y com uma escala de log.
Para obter informações sobre tipos de gráficos herdados, consulte:
Consistência de cores em todos os gráficos
O Databricks oferece suporte a dois tipos de consistência de cores em gráficos herdados: conjunto de séries e global.
A consistência de cores do conjunto de séries atribui a mesma cor ao mesmo valor se você tiver séries com a
mesmos valores, mas em ordens diferentes (por exemplo, A = ["Apple", "Orange", "Banana"] e B =
["Orange", "Banana", "Apple"]). Os valores são classificados antes de graficar, de modo que ambas as legendas são classificadas da mesma forma
(["Apple", "Banana", "Orange"]), e os mesmos valores recebem as mesmas cores. No entanto,
se você tiver uma série C = ["Orange", "Banana"], a cor não seria consistente com o conjunto
A porque o conjunto não é o mesmo. O algoritmo de classificação atribuiria a primeira cor a “Banana” em
defina C, mas a segunda cor para “Banana” no conjunto A. Se você quiser que essas séries tenham cores consistentes,
você pode especificar que os gráficos devem ter consistência global de cores.
Na consistência global de cores, cada valor é sempre mapeado para a mesma cor, independentemente dos valores a série tem. Para habilitar isso para cada gráfico, marque a caixa de seleção Consistência global de cores .

Para obter essa consistência, o Databricks faz hashes diretamente de valores para cores. Para evitar colisões (em que dois valores têm exatamente a mesma cor), o hash está em um grande conjunto de cores, que tem o efeito colateral de que cores bonitas ou facilmente distinguíveis não podem ser garantidas; com muitas cores, é provável que algumas tenham uma aparência muito semelhante.
Visualizações de aprendizado de máquina
Além dos tipos de gráficos padrão, as visualizações herdadas suportam os seguintes parâmetros e resultados de treinamento de aprendizado de máquina:
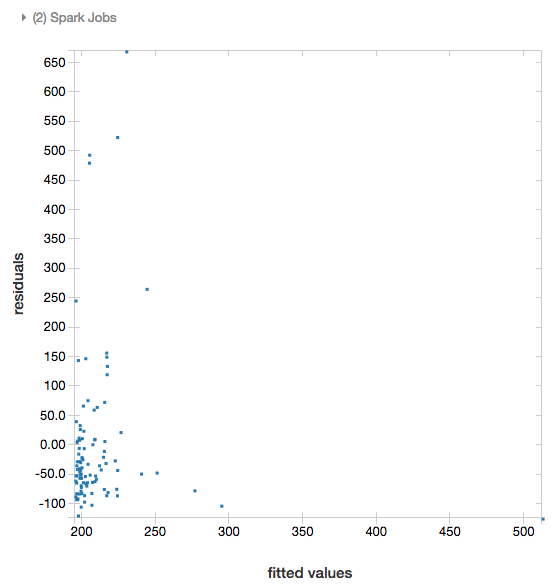
Resíduos
Para regressões lineares e logísticas, o senhor pode apresentar um gráfico de ajuste versus resíduos. Para obter esse gráfico, forneça o modelo e DataFrame.
O exemplo a seguir executa uma regressão linear sobre a população da cidade para dados de preços de venda de casas e, em seguida, exibe os resíduos em relação aos dados ajustados.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
Curvas ROC
Para regressões logísticas, o senhor pode renderizar uma curva ROC. Para obter esse gráfico, forneça o modelo, os dados preparados que são inseridos no método fit e o parâmetro "ROC".
O exemplo a seguir desenvolve um classificador que prevê se um indivíduo ganha\ < =50K ou > 50k por ano com vários atributos do indivíduo. O site Adult dataset deriva de dados do censo e consiste em informações sobre 48842 indivíduos e sua renda anual.
O código de exemplo nesta seção usa codificação one-hot.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
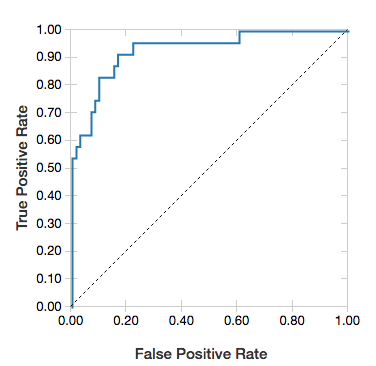
Para exibir os resíduos, omita o parâmetro "ROC":
display(lrModel, preppedDataDF)

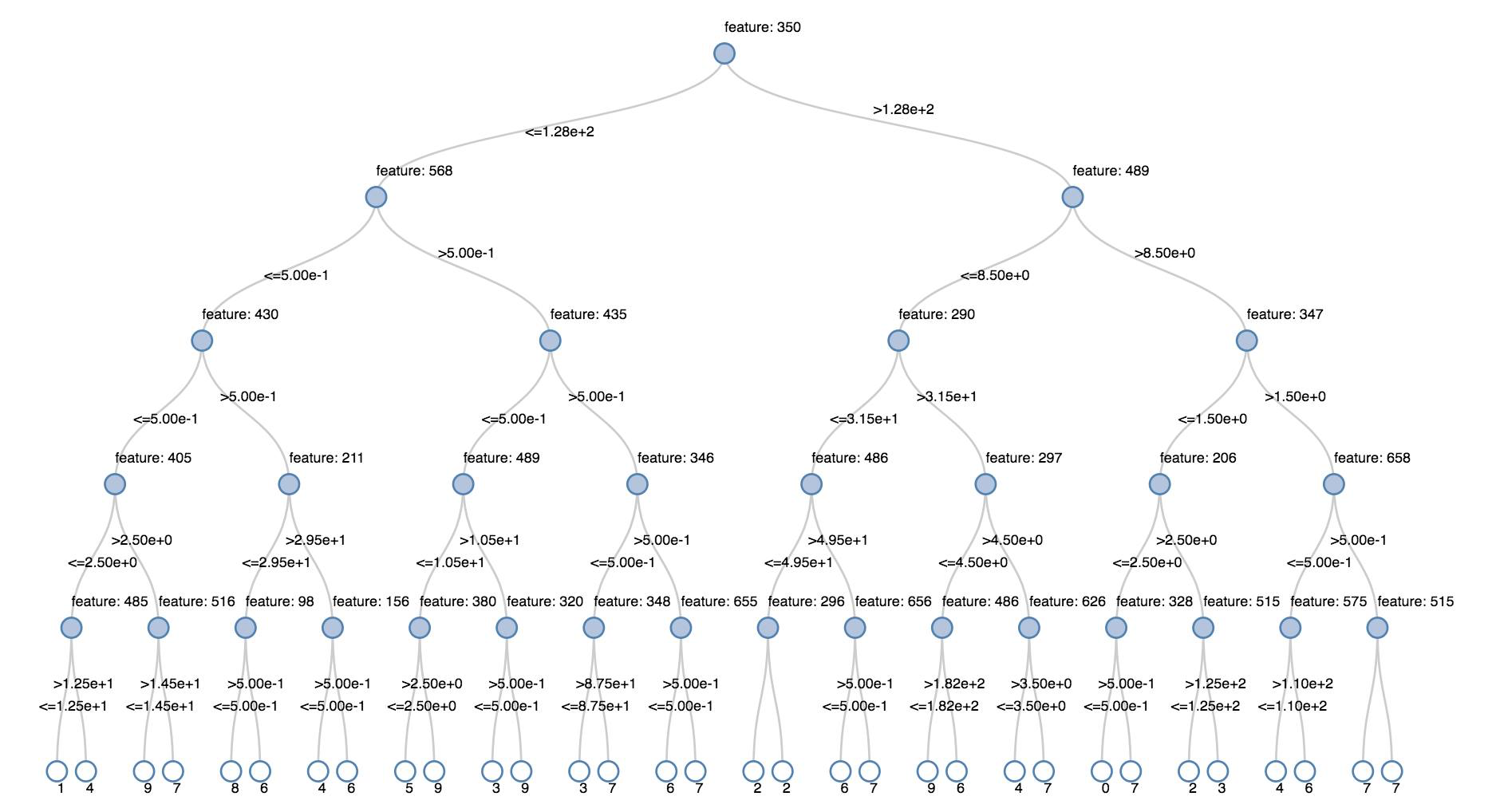
Árvores de decisão
As visualizações antigas oferecem suporte à renderização de uma árvore de decisão.
Para obter essa visualização, forneça o modelo de árvore de decisão.
Os exemplos a seguir treinam uma árvore para reconhecer dígitos (0 a 9) do MNIST dataset de imagens de dígitos manuscritos e, em seguida, exibem a árvore.
- Python
- Scala
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
transmissão estruturada DataFrames
Para visualizar o resultado de uma consulta de transmissão em tempo real, o senhor pode display uma transmissão estruturada DataFrame em Scala e Python.
- Python
- Scala
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display suporta os seguintes parâmetros opcionais:
streamName: o nome da consulta de transmissão.trigger(Scala) eprocessingTime(Python): define a frequência com que a consulta de transmissão é executada. Se não for especificado, o sistema verificará a disponibilidade de novos dados assim que o processamento anterior for concluído. Para reduzir o custo de produção, a Databricks recomenda que o senhor sempre defina um intervalo de acionamento. O intervalo de acionamento do default é de 500 ms.checkpointLocationLocal onde o sistema grava todas as informações do ponto de verificação. Se não for especificado, o sistema gera automaticamente um local de ponto de verificação temporário no DBFS. Para que a transmissão continue a processar os dados de onde parou, o senhor deve fornecer um local de ponto de verificação. A Databricks recomenda que, na produção, o senhor sempre especifique a opçãocheckpointLocation.
- Python
- Scala
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Para obter mais informações sobre esses parâmetros, consulte Iniciando consultas de transmissão.
FunçãodisplayHTML
Databricks A linguagem de programação Notebook (Python, R e Scala) suporta gráficos HTML usando a função displayHTML; o senhor pode passar para a função qualquer código HTML, CSS ou JavaScript. Essa função oferece suporte a gráficos interativos usando a biblioteca JavaScript, como a D3.
Para ver exemplos de uso de displayHTML, consulte:
O iframe displayHTML é servido a partir do domínio databricksusercontent.com e a sandbox do iframe inclui o atributo allow-same-origin. databricksusercontent.com deve estar acessível em seu navegador. Se estiver atualmente bloqueado pela sua rede corporativa, ele deverá ser adicionado a uma lista de permissões.
Imagens
As colunas contendo tipos de dados de imagem são renderizadas como HTML avançado. O Databricks tenta renderizar miniaturas de imagens para as colunas do site DataFrame que correspondem ao Spark ImageSchema.
A renderização de miniaturas funciona para qualquer imagem lida com sucesso por meio da função spark.read.format('image'). Para valores de imagem gerados por outros meios, o site Databricks suporta a renderização de imagens de 1, 3 ou 4 canais (em que cada canal consiste em um único byte), com as seguintes restrições:
- Imagens de um canal : o campo
modedeve ser igual a 0. Os camposheight,widthenChannelsdevem descrever com precisão os dados da imagem binária no campodata. - Imagens de três canais : o campo
modedeve ser igual a 16.heightOs camposwidth,nChannelse devem descrever com precisão os dados da imagem binária no campodata. O campodatadeve conter dados de pixel em blocos de três bytes, com a ordem de canal(blue, green, red)para cada pixel. - Imagens de quatro canais : o campo
modedeve ser igual a 24.heightOs camposwidth,nChannelse devem descrever com precisão os dados da imagem binária no campodata. O campodatadeve conter dados de pixel em blocos de quatro bytes, com a ordem de canal(blue, green, red, alpha)para cada pixel.
Exemplo
Suponha que você tenha uma pasta contendo algumas imagens:

Se o senhor ler as imagens em um DataFrame e depois exibir o DataFrame, o Databricks renderiza miniaturas das imagens:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualizações em Python
Nesta secção:
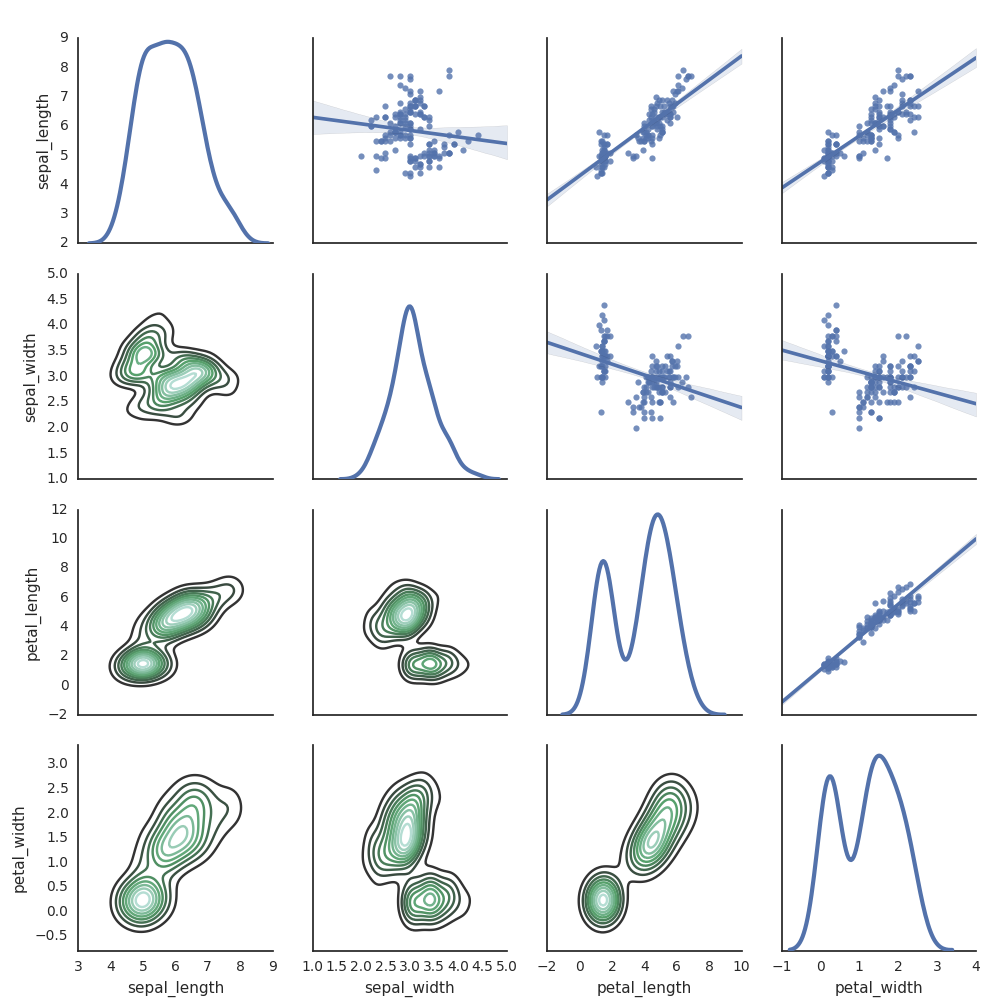
Nascido no mar
O senhor também pode usar outros Python biblioteca para gerar graficar. O site Databricks Runtime inclui a biblioteca de visualização de origem marinha. Para criar um graficar de origem marinha, importe a biblioteca, crie um graficar e passe o graficar para a função display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Outros Python biblioteca
Visualizações em R
Para graficar dados no R, use a função display da seguinte forma:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
O senhor pode usar a função default R graficar.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
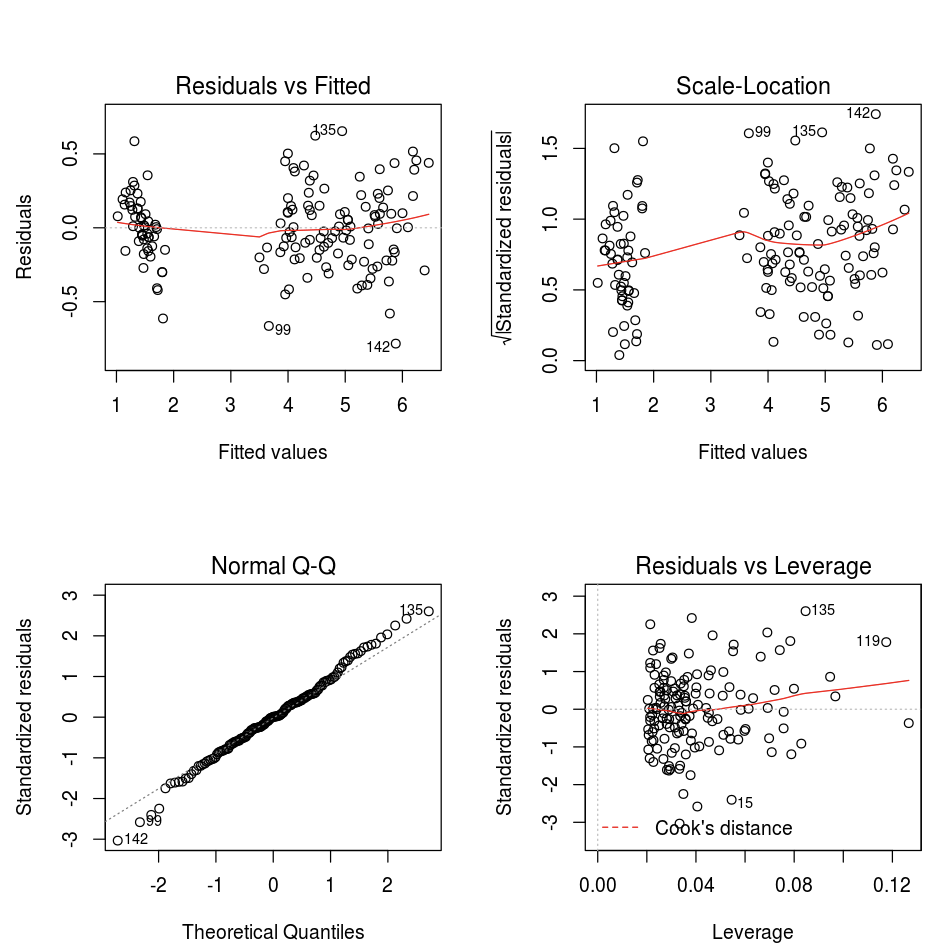
O senhor também pode usar qualquer pacote de visualização do R. O R Notebook captura o gráfico resultante como um .png e o exibe em linha.
Nesta secção:
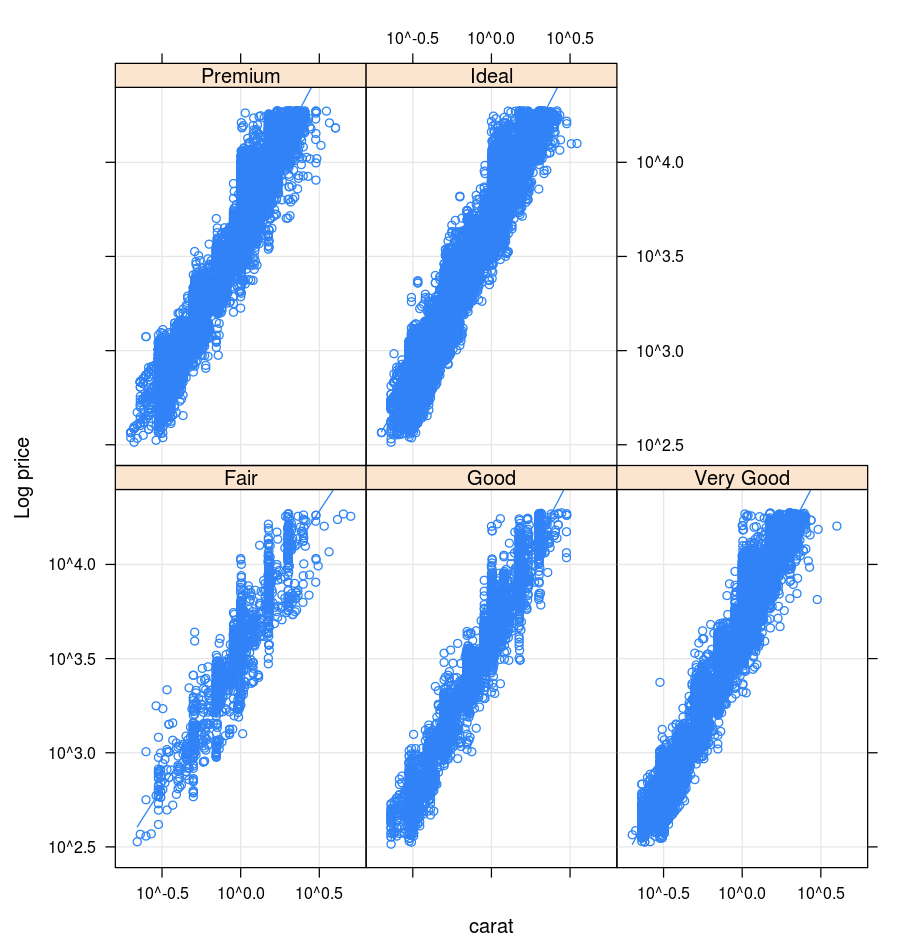
Treliça
O pacote Lattice suporta treliças gráfico-gráficas que exibem uma variável ou a relação entre variáveis, condicionada a uma ou mais outras variáveis.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
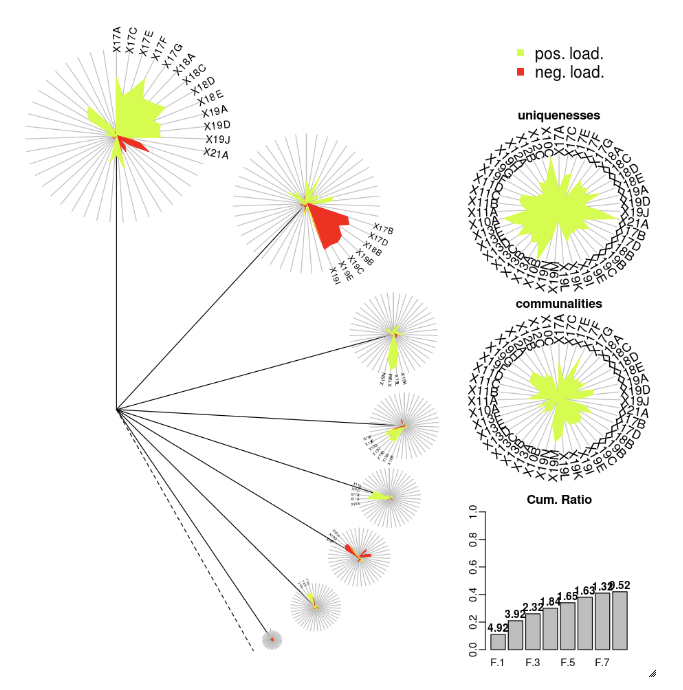
E DEFA
O pacote DandEFA apóia o dandelion graficar.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
O pacote Plotly R se baseia em htmlwidgets para R. Para obter instruções de instalação e um Notebook, consulte htmlwidgets.
Outros R biblioteca
Visualizações em Scala
Para graficar dados em Scala, use a função display da seguinte forma:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Notebook de mergulho profundo para Python e Scala
Para se aprofundar nas visualizações do site Python, consulte o Notebook:
Para se aprofundar nas visualizações do site Scala, consulte o Notebook: