Read data shared with bearer tokens
This page describes how to read data shared with you using the OpenSharing open sharing protocol with bearer tokens. It includes instructions for reading shared data using the following tools:
In this sharing model, you use a credential file, shared with a member of your team by the data provider, to gain secure read access to shared data. Access persists as long as the credential is valid and the provider continues to share the data. Providers manage credential expiration and rotation. Updates to the data are available in near real time. You can read and make copies of the shared data, but you cannot modify the source data.
If data has been shared with you using Databricks-to-Databricks OpenSharing, you don't need a credential file to access data, and this page doesn't apply to you. Instead, see Read data shared using Databricks-to-Databricks OpenSharing (for recipients).
The following sections describe how to use Apache Spark, pandas, Power BI, and Iceberg clients to access and read shared data using the credential file. For a full list of OpenSharing connectors and information about how to use them, see the OpenSharing open source documentation. If you run into trouble accessing the shared data, contact the data provider.
Before you begin
A member of your team must download the credential file shared by the data provider and use a secure channel to share that file or file location with you. See Get access in the Databricks-to-Open sharing model.
For connector-specific documentation, see the download credentials page.
Iceberg clients: Read shared data
Use external Iceberg clients, such as Snowflake, Trino, Flink, and Spark, to read shared data assets with zero-copy access using the Apache Iceberg REST Catalog API.
Obtain connection credentials
Before you access shared data assets with external Iceberg clients, gather the following credentials:
- The Iceberg REST Catalog endpoint
- A valid Bearer token
- The share name
- (Optional) The namespace or schema name
- (Optional) The table name
The Iceberg REST Catalog endpoint (icebergEndpoint) and Bearer token are found in the credential file shared with you by your data provider. For more information, see Before you begin. The share name, namespace, and table name can be discovered programmatically using OpenSharing APIs.
The icebergEndpoint is found in the credential file and has the format <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
The following examples show how to obtain the additional credentials. Enter the endpoint, Iceberg endpoint, and the Bearer token from the credential file where needed:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
This method always retrieves the most up-to-date list of assets. However, it requires internet access and can be harder to integrate in no-code environments.
Configure Iceberg catalog
After you obtain the necessary connection credentials, configure your client to use the Iceberg REST Catalog endpoints to create and query tables.
-
For each share, create a catalog integration.
SQLUSE ROLE ACCOUNTADMIN;
CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER>
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = '<icebergEndpoint>',
WAREHOUSE = '<share_name>',
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
)
REST_AUTHENTICATION = (
TYPE = BEARER,
BEARER_TOKEN = '<bearerToken>'
)
ENABLED = TRUE; -
Optionally, add
REFRESH_INTERVAL_SECONDSto keep metadata up to date. Set the value based on your catalog update frequency.SQLREFRESH_INTERVAL_SECONDS = 30 -
After the catalog is configured, create a database from the catalog. This automatically creates all schemas and tables in that catalog.
SQLCREATE DATABASE <DATABASE_PLACEHOLDER>
LINKED_CATALOG = (
CATALOG = <CATALOG_PLACEHOLDER>
); -
To confirm that the sharing is successful, query from a table in the database. You should see the shared data from Databricks.
If the result is empty or an error occurs, follow these common troubleshooting steps:
- Double-check the privileges, snapshot generation status, and REST credentials.
- Contact your data provider.
- See the documentation specific to your Iceberg client.
Example: Access shared tables using different Iceberg clients
The following examples show how to access openshared tables using external Iceberg clients, such as Snowflake, Apache Spark, PyIceberg, and REST API, after obtaining your connection credentials. For more on obtaining connection credentials, see Before you begin.
- Snowflake
- Apache Spark
- PyIceberg
- REST API
To read shared data assets in Snowflake, upload the credential file you downloaded and generate the necessary SQL command:
-
From your OpenSharing activation link, click the Snowflake icon.
-
On the Snowflake integration page, upload the credential file you received from the data provider.
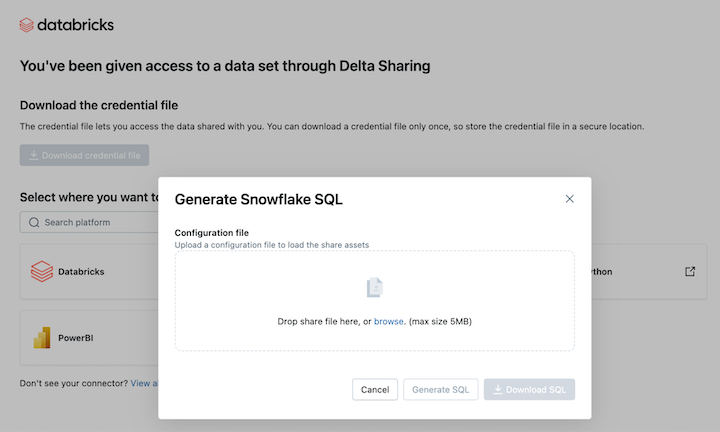
-
After loading the credential, choose the share you want to access in Snowflake.
-
Click Generate SQL after selecting the desired assets.
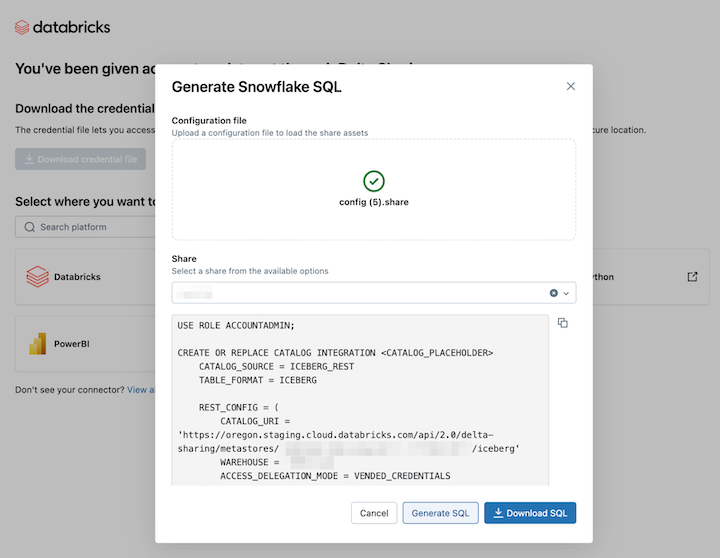
-
Copy and paste the generated SQL into your Snowflake worksheet. Replace
CATALOG_PLACEHOLDERwith the name of the catalog you want to use andDATABASE_PLACEHOLDERwith the name of the database you want to use.
Limitations
Connecting to the Iceberg REST Catalog in Snowflake has the following limitations:
- The metadata file doesn't automatically update with the latest snapshot. You must rely on auto-refresh or manual refreshes.
- R2 is not supported.
- All Iceberg client limitations apply.
To access shared tables using Apache Spark, configure the Iceberg REST Catalog API with the following settings. Replace <spark-catalog-name> with a name for your catalog, and provide your connection credentials:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg is a Python implementation for accessing Iceberg tables without using a JVM. PyIceberg requires pyarrow for table operations such as reading data and inspecting table metadata. Install PyIceberg with the pyarrow extra:
pip install "pyiceberg[pyarrow]"
To access shared tables, add the following catalog configuration to your PyIceberg configuration file:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
Use a REST API call like the following curl example to load a table and retrieve its metadata along with temporary credentials for accessing the data files:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
The response includes the Iceberg table metadata, the S3 location, and temporary AWS credentials that allow your client to read the data files:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Iceberg client limitations
The following limitations apply when querying OpenSharing data from Iceberg clients:
- When listing tables in a namespace, if the namespace contains more than 100 shared views, the response is limited to the first 100 views.
Apache Spark: Read shared data
Follow these steps to access shared data using Spark 3.x or above.
These instructions assume that you have access to the credential file that was shared by the data provider. See Get access in the Databricks-to-Open sharing model.
Ensure your credential file is accessible by Apache Spark by using an absolute path. The path can refer to a cloud object or Unity Catalog volume.
If you are using Spark on a Databricks workspace that is enabled for Unity Catalog, and you used the import provider UI to import the provider and share, the instructions in this section do not apply to you. You can access shared tables just as you would any other table that is registered in Unity Catalog. You do not need to install the delta-sharing Python connector or provide the path to the credential file. See Import a provider and read shared data in Databricks.
Install the OpenSharing Python and Spark connectors
To access metadata related to the shared data, such as the list of tables shared with you, do the following. This example uses Python.
-
Install the delta-sharing Python connector. For information about Python connector limitations, see OpenSharing Python connector limitations.
Bashpip install delta-sharing -
Install the Apache Spark connector.
List shared tables using Spark
List the tables in the share. In the following example, replace <profile-path> with the location of the credential file.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
The result is an array of tables, along with metadata for each table. The following output shows two tables:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
If the output is empty or doesn't contain the tables you expect, contact the data provider.
Access shared data using Spark
Run the following, replacing these variables:
<profile-path>: the location of the credential file.<share-name>: the value ofshare=for the table.<schema-name>: the value ofschema=for the table.<table-name>: the value ofname=for the table.<version-as-of>: optional. The version of the table to load the data. Only works if the data provider shares the history of the table. Requiresdelta-sharing-spark0.5.0 or above.<timestamp-as-of>: optional. Load the data at the version before or at the given timestamp. Only works if the data provider shares the history of the table. Requiresdelta-sharing-spark0.6.0 or above.
- Python
- Scala
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Access shared change data feed using Spark
If the table history has been shared with you and change data feed (CDF) is enabled on the source table, access the change data feed by running the following, replacing these variables. Requires delta-sharing-spark 0.5.0 or above.
One start parameter must be provided.
<profile-path>: the location of the credential file.<share-name>: the value ofshare=for the table.<schema-name>: the value ofschema=for the table.<table-name>: the value ofname=for the table.<starting-version>: optional. The starting version of the query, inclusive. Specify as a Long.<ending-version>: optional. The ending version of the query, inclusive. If the ending version is not provided, the API uses the latest table version.<starting-timestamp>: optional. The starting timestamp of the query, this is converted to a version created greater or equal to this timestamp. Specify as a string in the formatyyyy-mm-dd hh:mm:ss[.fffffffff].<ending-timestamp>: optional. The ending timestamp of the query, this is converted to a version created earlier or equal to this timestamp. Specify as a string in the formatyyyy-mm-dd hh:mm:ss[.fffffffff]
- Python
- Scala
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
If the output is empty or doesn't contain the data you expect, contact the data provider.
Access a shared table using Spark Structured Streaming
If the table history is shared with you, you can stream read the shared data. Requires delta-sharing-spark 0.6.0 or above.
Supported options:
ignoreDeletes: Ignore transactions that delete data.ignoreChanges: Re-process updates if files were rewritten in the source table due to a data changing operation such asUPDATE,MERGE INTO,DELETE(within partitions), orOVERWRITE. Unchanged rows can still be emitted. Therefore, your downstream consumers should be able to handle duplicates. Deletes are not propagated downstream.ignoreChangessubsumesignoreDeletes. Therefore, if you useignoreChanges, your stream is not disrupted by either deletions or updates to the source table.startingVersion: The shared table version to start from. All table changes starting from this version (inclusive) are read by the streaming source.startingTimestamp: The timestamp to start from. All table changes committed at or after the timestamp (inclusive) are read by the streaming source. Example:"2023-01-01 00:00:00.0".maxFilesPerTrigger: The number of new files to be considered in every micro-batch.maxBytesPerTrigger: The amount of data that gets processed in each micro-batch. This option sets a “soft max”, meaning that a batch processes approximately this amount of data and may process more than the limit in order to make the streaming query move forward in cases when the smallest input unit is larger than this limit.readChangeFeed: Stream read the change data feed of the shared table.
Supported triggers:
Trigger.ProcessingTime: The default trigger, used when no explicit trigger is specified. Data is processed in continuous micro-batches.Trigger.AvailableNow: The query captures the shared table's server-side version at start, processes the backlog as multiple micro-batches that honormaxFilesPerTriggerandmaxVersionsPerRpc, and terminates when the captured version is exhausted. Requiresdelta-sharing-spark1.4.0 or above. Older versions fall back to aTrigger.AvailableNowwrapper that does not respectmaxVersionsPerRpc.Trigger.Once: Deprecated; useTrigger.AvailableNowinstead. Withdelta-sharing-sparkversions below 1.4.0,Trigger.AvailableNowfalls back to a wrapper that does not respectmaxVersionsPerRpc.
Sample Structured Streaming queries
- Python
- Scala
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
See also Structured Streaming concepts.
Read tables with deletion vectors or column mapping enabled
This feature is in Public Preview.
Deletion vectors are a storage optimization feature that your provider can enable on shared Delta tables. See Deletion vectors in Databricks.
Databricks also supports column mapping for Delta tables. See Rename and drop columns with Delta Lake column mapping.
If your provider shared a table with deletion vectors or column mapping enabled, you can read the table using compute that is running delta-sharing-spark 3.1 or above. If you are using Databricks clusters, you can perform batch reads using a cluster running Databricks Runtime 14.1 or above. CDF and streaming queries require Databricks Runtime 14.2 or above.
You can perform batch queries as-is, because they can automatically resolve responseFormat based on the table features of the shared table.
To read a change data feed (CDF) or to perform streaming queries on shared tables with deletion vectors or column mapping enabled, you must set the additional option responseFormat=delta.
The following examples show batch, CDF, and streaming queries:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Read row tracking columns in shared tables
If the data provider has enabled row tracking on a shared table, you can query the row tracking metadata columns using Scala Spark. See Row tracking in Databricks for a list of available columns.
You must set the responseFormat option to delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Only the delta response format is supported for querying row tracking columns in the Spark client. Dump connectors are not supported.
Pandas: Read shared data
Follow these steps to access shared data in pandas 0.25.3 or above.
These instructions assume that you have access to the credential file that was shared by the data provider. See Get access in the Databricks-to-Open sharing model.
If you are using pandas on a Databricks workspace that is enabled for Unity Catalog, and you used the import provider UI to import the provider and share, the instructions in this section do not apply to you. You can access shared tables just as you would any other table that is registered in Unity Catalog. You do not need to install the delta-sharing Python connector or provide the path to the credential file. See Import a provider and read shared data in Databricks.
Install the OpenSharing Python connector
To access metadata related to the shared data, such as the list of tables shared with you, you must install the delta-sharing Python connector. For information about Python connector limitations, see OpenSharing Python connector limitations.
pip install delta-sharing
List shared tables using pandas
To list the tables in the share, run the following, replacing <profile-path>/config.share with the location of the credential file.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
If the output is empty or doesn't contain the tables you expect, contact the data provider.
Access shared data using pandas
To access shared data in pandas using Python, run the following, replacing the variables as follows:
<profile-path>: the location of the credential file.<share-name>: the value ofshare=for the table.<schema-name>: the value ofschema=for the table.<table-name>: the value ofname=for the table.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Access a shared change data feed using pandas
To access the change data feed for a shared table in pandas using Python run the following, replacing the variables as follows. A change data feed may not be available, depending on whether or not the data provider shared the change data feed for the table.
<starting-version>: optional. The starting version of the query, inclusive.<ending-version>: optional. The ending version of the query, inclusive.<starting-timestamp>: optional. The starting timestamp of the query. This is converted to a version created greater or equal to this timestamp.<ending-timestamp>: optional. The ending timestamp of the query. This is converted to a version created earlier or equal to this timestamp.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
If the output is empty or doesn't contain the data you expect, contact the data provider.
Power BI: Read shared data
The Power BI OpenSharing connector allows you to discover, analyze, and visualize datasets shared with you through the OpenSharing open protocol.
Requirements
- Power BI Desktop 2.99.621.0 or above.
- Access to the credential file that was shared by the data provider. See Get access in the Databricks-to-Open sharing model.
Connect to Databricks
To connect to Databricks using the OpenSharing connector, do the following:
- Open the shared credential file with a text editor to retrieve the endpoint URL and the token.
- Open Power BI Desktop.
- On the Get Data menu, search for OpenSharing.
- Select the connector and click Connect.
- Enter the endpoint URL that you copied from the credentials file into the OpenSharing Server URL field.
- Optionally, in the Advanced Options tab, set a Row Limit for the maximum number of rows that you can download. This is set to 1 million rows by default.
- Click OK.
- For Authentication, copy the token that you retrieved from the credentials file into Bearer Token.
- Click Connect.
Limitations of the Power BI OpenSharing connector
The Power BI OpenSharing Connector has the following limitations:
- The data that the connector loads must fit into the memory of your machine. To manage this requirement, the connector limits the number of imported rows to the Row Limit that you set under the Advanced Options tab in Power BI Desktop.
Tableau: Read shared data
The Tableau OpenSharing connector allows you to discover, analyze, and visualize datasets that are shared with you through the OpenSharing open protocol.
Requirements
- Tableau Desktop and Tableau Server 2024.1 or above
- Access to the credential file that was shared by the data provider. See Get access in the Databricks-to-Open sharing model.
Connect to Databricks
To connect to Databricks using the OpenSharing connector, do the following:
- Go to Tableau Exchange, follow the instructions to download the OpenSharing Connector, and put it in an appropriate desktop folder.
- Open Tableau Desktop.
- On the Connectors page, search for “OpenSharing by Databricks”.
- Select Upload Share file, and choose the credential file that was shared by the provider.
- Click Get Data.
- In the Data Explorer, select the table.
- Optionally add SQL filters or row limits.
- Click Get Table Data.
Limitations
The Tableau OpenSharing Connector has the following limitations:
- The data that the connector loads must fit into the memory of your machine. To manage this requirement, the connector limits the number of imported rows to the row limit that you set in Tableau.
- All columns are returned as type
String. - SQL Filter only works if your OpenSharing server supports predicateHint.
- Deletion vectors are not supported.
- Column mapping is not supported.
OpenSharing Python connector limitations
These limitations are specific to the OpenSharing Python connector:
- The OpenSharing Python connector 1.1.0+ supports snapshot queries on tables with column mapping but CDF queries on tables with column mapping are not supported.
- The OpenSharing Python connector fails CDF queries with
use_delta_format=Trueif the schema changed during the queried version range.
Streaming table limitations
You can only read the current snapshot of a shared streaming table. The following features are not supported for streaming tables in Databricks-to-Open sharing:
- Querying the table's history data
- Querying the table's change data feed (CDF)
- Using the table as a source for Spark Structured Streaming
Materialized view limitations
You can only read the current snapshot of a shared materialized view. Using a materialized view as a source for Spark Structured Streaming is not supported in Databricks-to-Open sharing.
Request a new credential
If your credential activation URL or downloaded credential is lost, corrupted, or compromised, or your credential expires without your provider sending you a new one, contact your provider to request a new credential.
If you're a Databricks recipient who imported the credential as a provider object in Unity Catalog, apply the new credential using the Databricks REST API. See Rotate credentials for open recipients.