Assess performance: Metrics that matter
This article covers measuring the performance of a RAG application for the quality of retrieval, response, and system performance.
Retrieval, response, and performance
With an evaluation set, you can measure the performance of your RAG application across a number of different dimensions, including:
- Retrieval quality: Retrieval metrics assess how successfully your RAG application retrieves relevant supporting data. Precision and recall are two key retrieval metrics.
- Response quality: Response quality metrics assess how well the RAG application responds to a user's request. Response metrics can measure, for instance, if the resulting answer is accurate per the ground-truth, how well-grounded the response was given the retrieved context (for instance, did the LLM hallucinate?), or how safe the response was (in other words, no toxicity).
- System performance (cost & latency): Metrics capture the overall cost and performance of RAG applications. Overall latency and token consumption are examples of chain performance metrics.
It is very important to collect both response and retrieval metrics. A RAG application can respond poorly despite retrieving the correct context; it can also provide good responses based on faulty retrievals. Only by measuring both components can we accurately diagnose and address issues in the application.
Approaches to measuring performance
There are two key approaches to measuring performance across these metrics:
- Deterministic measurement: Cost and latency metrics can be computed deterministically based on the application's outputs. If your evaluation set includes a list of documents that contain the answer to a question, a subset of the retrieval metrics can also be computed deterministically.
- LLM judge-based measurement: In this approach, a separate LLM acts as a judge to evaluate the quality of the RAG application's retrieval and responses. Some LLM judges, such as answer correctness, compare the human-labeled ground truth vs. the app outputs. Other LLM judges, such as groundedness, do not require human-labeled ground truth to assess their app outputs.
For an LLM judge to be effective, it must be tuned to understand the use case. Doing so requires careful attention to understand where the judge does and does not work well, and then tuning the judge to improve it for the failure cases.
Mosaic AI Agent Evaluation provides an out-of-the-box implementation, using hosted LLM judge models, for each metric discussed on this page. Agent Evaluation's documentation discusses the details of how these metrics and judges are implemented and provides capabilities to tune the judges with your data to increase their accuracy
Metrics overview
Below is a summary of the metrics that Databricks recommends for measuring the quality, cost, and latency of your RAG application. These metrics are implemented in Mosaic AI Agent Evaluation.
Dimension | Metric name | Question | Measured by | Needs ground truth? |
|---|---|---|---|---|
Retrieval | chunk_relevance/precision | LLM judge | No | |
Retrieval | document_recall | What % of the ground truth documents are represented in the retrieved chunks? | Deterministic | Yes |
Retrieval | context_sufficiency | Are the retrieved chunks sufficiency to produce the expected response? | LLM Judge | Yes |
Response | correctness | LLM judge | Yes | |
Response | relevance_to_query | LLM judge | No | |
Response | groundedness | LLM judge | No | |
Response | safety | LLM judge | No | |
Cost | total_token_count, total_input_token_count, total_output_token_count | Deterministic | No | |
Latency | latency_seconds | Deterministic | No |
How retrieval metrics work
Retrieval metrics help you understand if your retriever is delivering relevant results. Retrieval metrics are based on precision and recall.
Metric Name | Question Answered | Details |
|---|---|---|
Precision | What % of the retrieved chunks are relevant to the request? | Precision is the proportion of retrieved documents that are actually relevant to the user's request. An LLM judge can be used to assess the relevance of each retrieved chunk to the user's request. |
Recall | What % of the ground truth documents are represented in the retrieved chunks? | Recall is the proportion of the ground truth documents that are represented in the retrieved chunks. This is a measure of the completeness of the results. |
Precision and recall
Below is a quick primer on Precision and recall adapted from the excellent Wikipedia article.
Precision formula
Precision measures “Of the chunks I retrieved, what % of these items are actually relevant to my user's query?” Computing precision does not require knowing all relevant items.
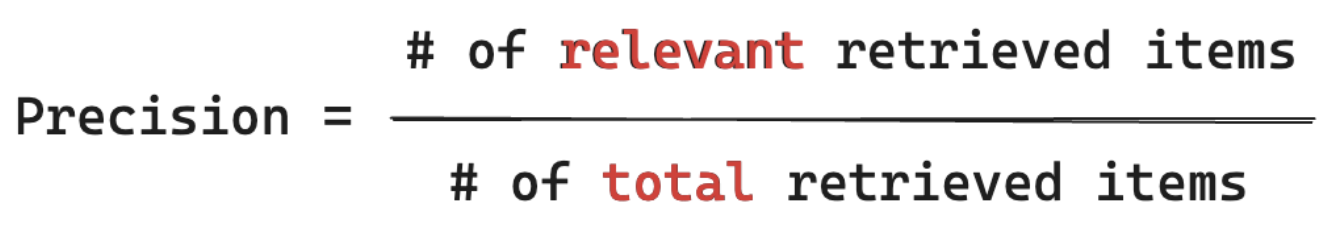
Recall formula
Recall measures “Of ALL the documents that I know are relevant to my user's query, what % did I retrieve a chunk from?” Computing recall requires your ground-truth to contain all relevant items. Items can either be a document or a chunk of a document.
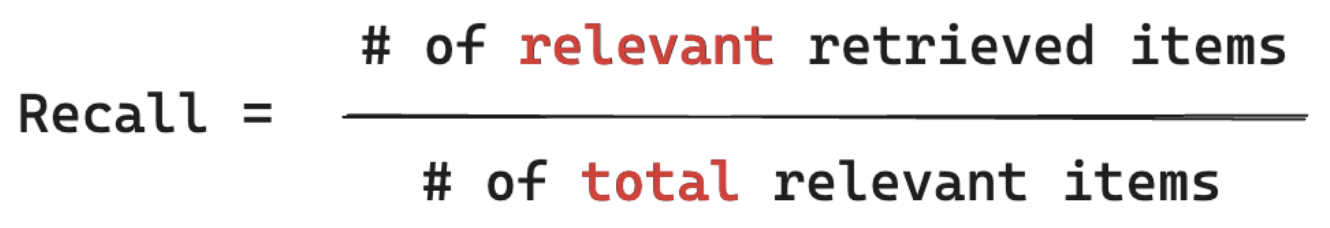
In the example below, two out of the three retrieved results were relevant to the user's query, so the precision was 0.66 (2/3). The retrieved docs included two out of a total of four relevant docs, so the recall was 0.5 (2/4).